物体検知
物体認識タスクの共通事項として、入力は「画像」である。
物体認識では出力において4つの認識タスクがある。
「分類」「物体検知」「意味領域分割」「個体領域分割」の4つである。

《物体検知における評価指標について》
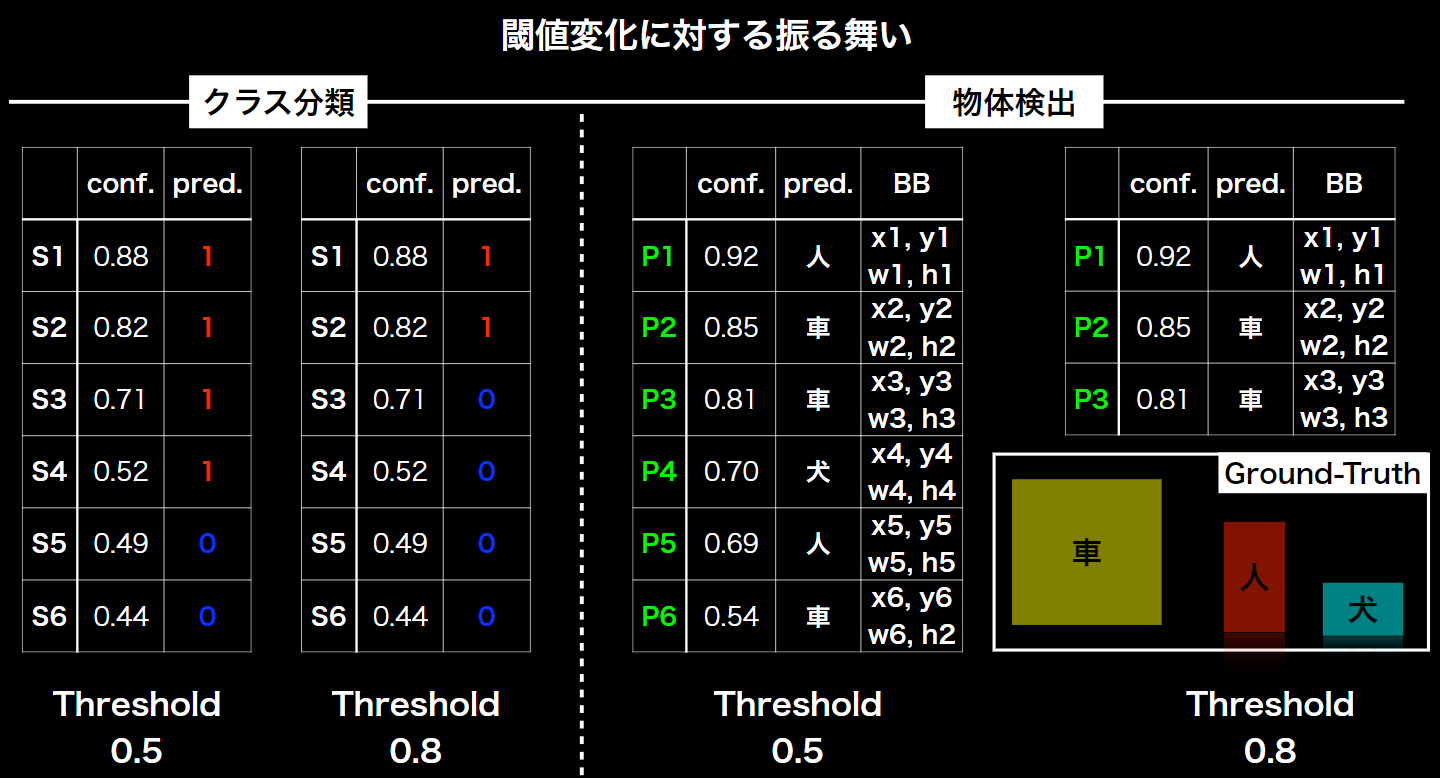
前提:物体検出は、指定した閾値(Threshold)以下の検出物はそもそもの検出データとして含めない。(限りなく低い閾値の検出物も表示してしまうと、無数に検出されてしまう恐れがあるため)
よって、下記図のように、クラス分類と違い、閾値を変化されることで、検出されるデータの数が6個から3個へと変化している。
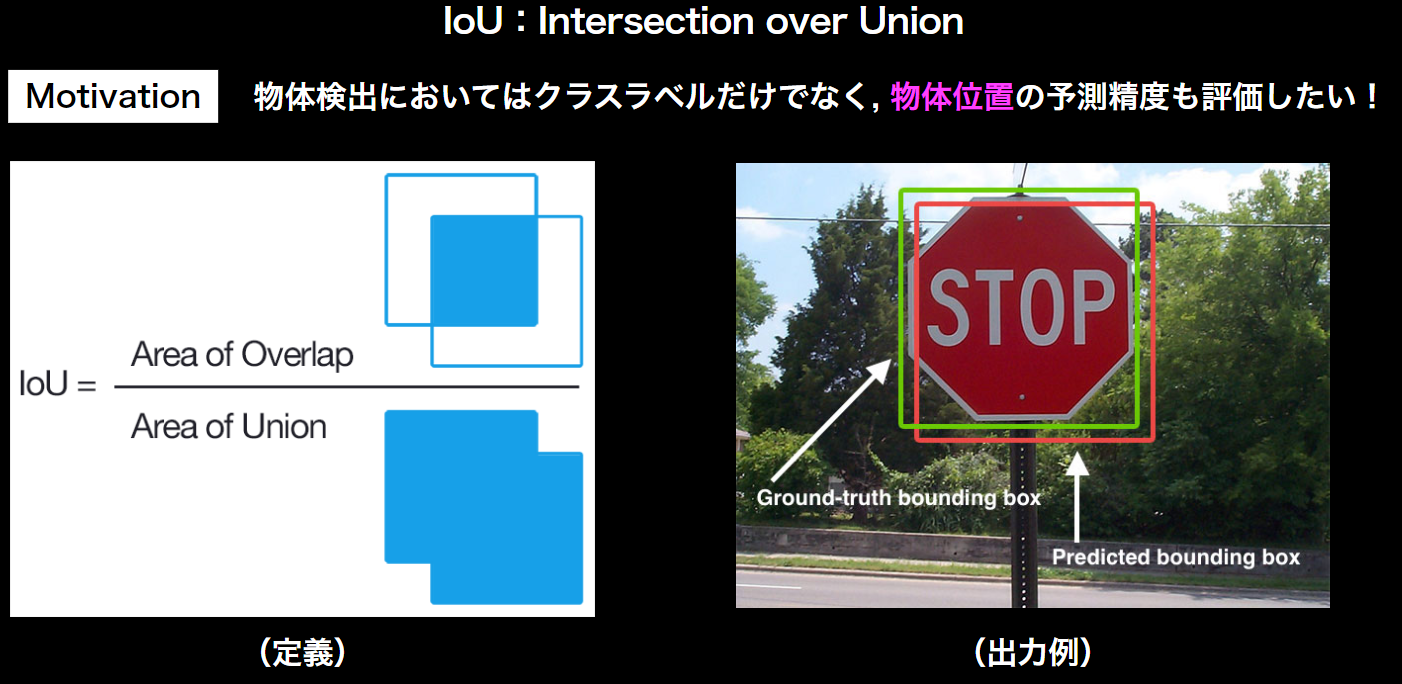
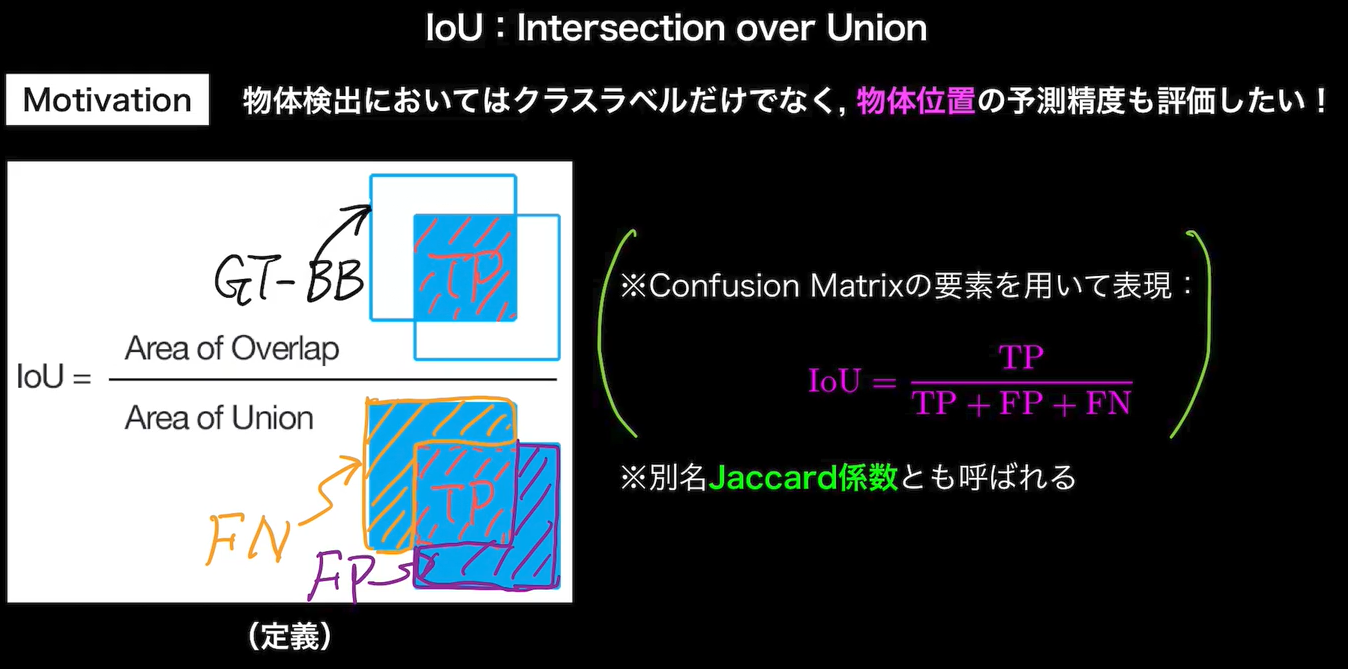
物体検知では、予測したBounding Box(BB)と真値としての(BB)の重なりで、精度を評価。
入力1枚で見るPrecision/Recall

※Recallの分子の0は、FN(False Negative:真値は正だが、負と予測したもの)が無いため。
クラス単位でみるPrecision/Recall

※Recallの分子の1は、FNとして、画像4(Pic4)の人を検出できていないため、1となっている。
SSD(Single Shot Detector)
1ショット検出器を意味する。
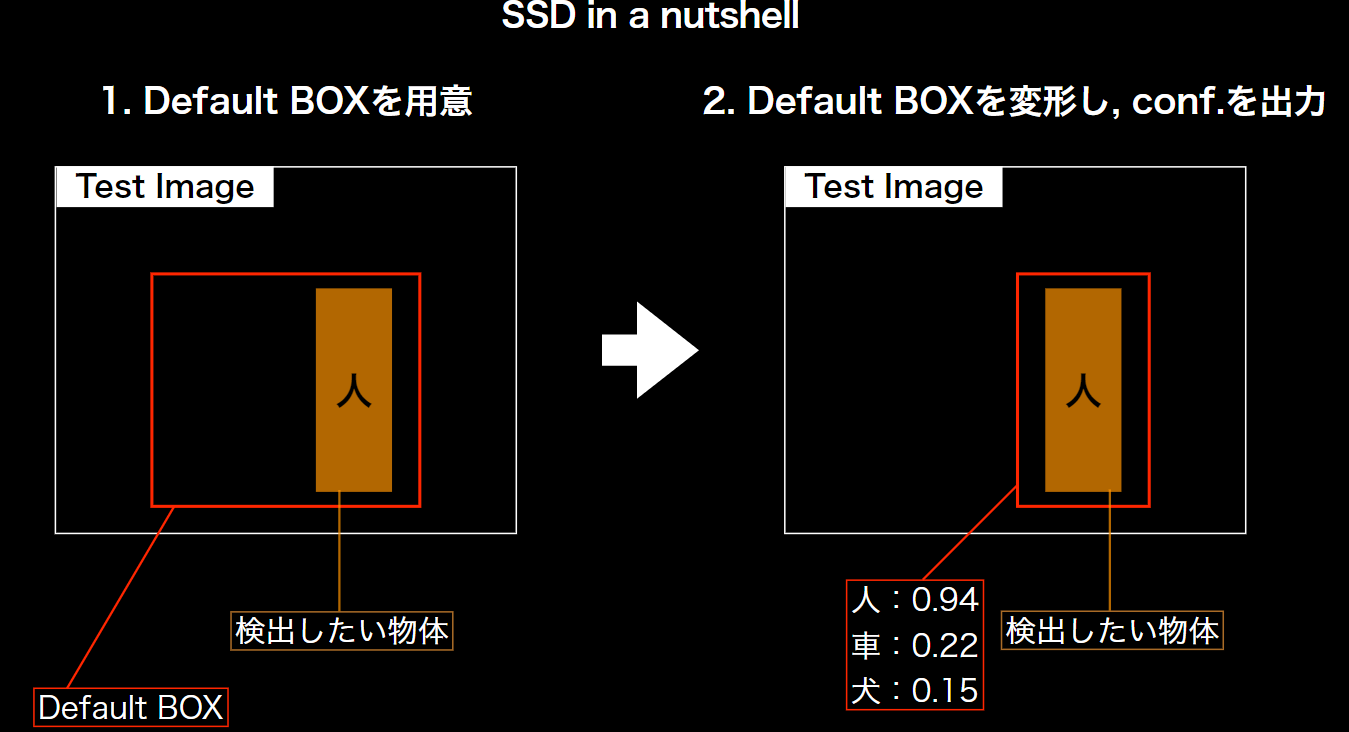
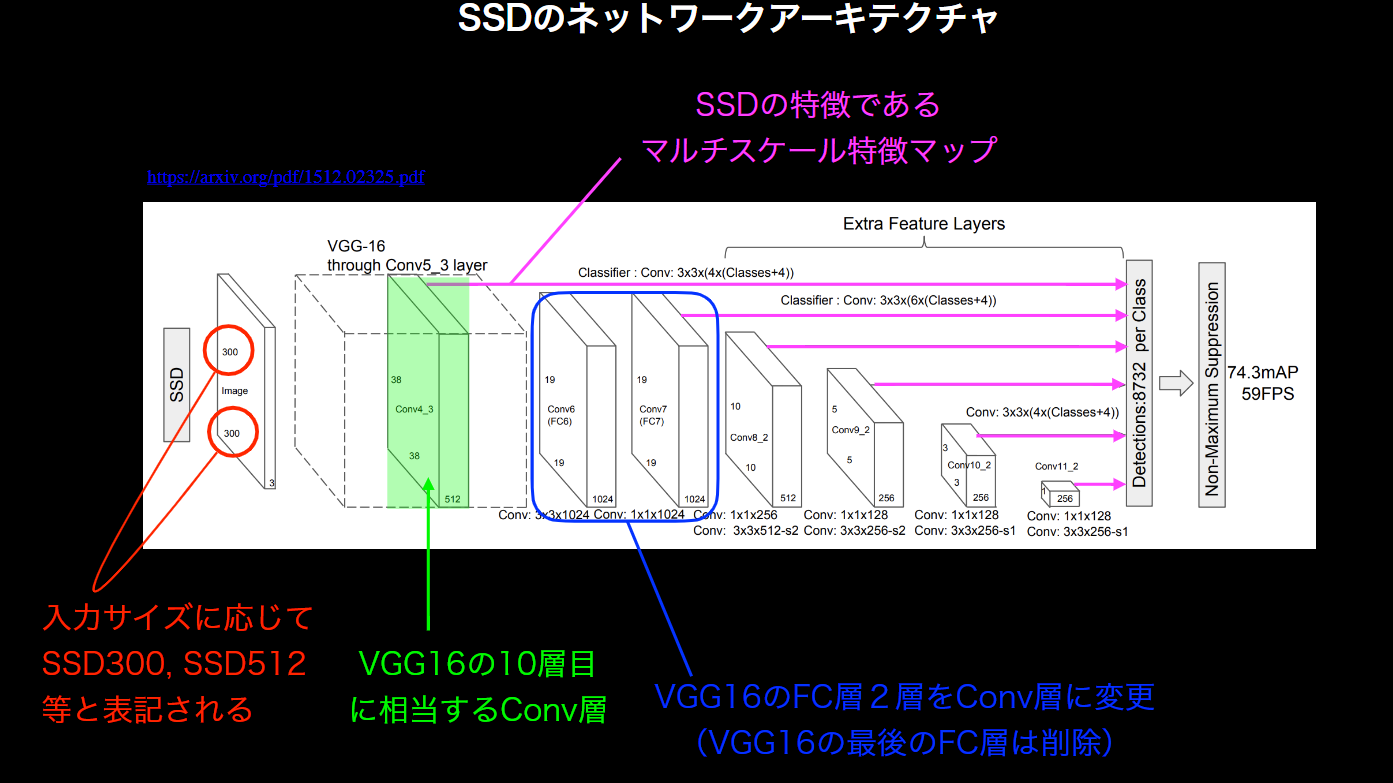
【実装例】
from utils.ssd_model import SSD
import torch
# SSD300の設定
ssd_cfg = {
'num_classes': 2, # 背景クラスを含めた合計クラス数
'input_size': 300, # 画像の入力サイズ
'bbox_aspect_num': [4, 6, 6, 6, 4, 4], # 出力するDBoxのアスペクト比の種類
'feature_maps': [38, 19, 10, 5, 3, 1], # 各sourceの画像サイズ
'steps': [8, 16, 32, 64, 100, 300], # DBOXの大きさを決める
'min_sizes': [21, 45, 99, 153, 207, 261], # DBOXの大きさを決める
'max_sizes': [45, 99, 153, 207, 261, 315], # DBOXの大きさを決める
'aspect_ratios': [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
}
# SSDネットワークモデル
net = SSD(phase="train", cfg=ssd_cfg)
# SSDの初期の重みを設定
vgg_weights = torch.load('./weights/vgg16_reducedfc.pth')
net.vgg.load_state_dict(vgg_weights)
セグメンテ-ション
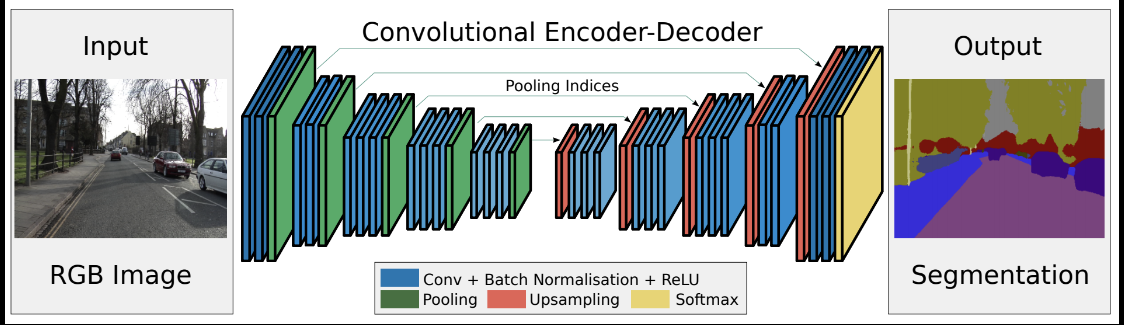
セマンティックセグメンテーションとは、R-CNNのようなバウンディングボックスを出すのではなく、より、詳細な領域分割を得るモデル。すなわち、物体認識においては領域分割を詳細に行うことが必要となる。入力画像のどの位置に物体が存在するのかを画素単位で指定することができれば認識精度も向上すると予想される。
セグメンテーションを実現するネットワークとして、完全畳み込みネットワーク(FCN:Fully Convolution Network)がある。文字通り、全ての層が畳み込み層になっている。通常のCNNは、出力層のユニット数が識別すべきカテゴリー数であった。一方、FCNでは入力画像の画素数だけ出力層が必要になる。すなわち、各画素がそれぞれどのカテゴリーに属するのかを出力する必要があるため、出力層には縦画素数×横画素数×カテゴリー数の出力ニューロンが用意される。
CNNでは畳み込み演算によって、上位層では下位層に比べて受容野が大きくなり、その影響で画像サイズは小さく(あるいは粗く)なる。そのため、最終出力層に入力層と同じ解像度の画素数を得るためには、畳み込みと反対方向の解像度を細かくする工夫が必要となる。
⇒これを解決する1つの方法が「アンサンプリング」と呼ばれる方法で、下位のプーリング層の情報を用いて詳細な解像度を得ることができる。