前回の記事「Pendulum-v0とChainerRLで深層強化学習の比較メモ」で最も良い性能を出したPPO(Proximal Policy Optimization)について,最適化手法との組み合わせを試してみたのでメモ.
動機
PPOの原論文ではAdamが推奨されている.
しかし,こういう議論を見かけた.
Using Adam Optimizer in PPO and similar off-policy optimization procedures
実験を報告する論文もある.
Henderson+ (2018) "Where Did My Optimum Go?: An Empirical Analysis of Gradient Descent Optimization in Policy Gradient Methods"

(図は上記論文のFigure 1.より引用)
論文いわく,PPOで学習率を変えたときの最適化手法ごとの性能変化がこれらしい.では,学習率などを最適化手法が提案する推奨値にして比較するときはどうなるのか?
実験
実験環境
- CPU : Intel Core i7-8700CPU @ 3.20Hz x 12
- メモリ : 32GB
- グラボ: GeForce RTX2080Ti 11GB
パラメータ等
環境はPendulum-v0.
parser.add_argument('--gpu', type=int, default=0)
parser.add_argument('--env', type=str, default='Pendulum-v0')
parser.add_argument('--arch', type=str, default='FFGaussian',
choices=('FFSoftmax', 'FFMellowmax',
'FFGaussian'))
parser.add_argument('--bound-mean', action='store_true')
parser.add_argument('--seed', type=int, default=0,
help='Random seed [0, 2 ** 32)')
parser.add_argument('--outdir', type=str, default='results_adam',
help='Directory path to save output files.'
' If it does not exist, it will be created.')
parser.add_argument('--steps', type=int, default=10 ** 6)
parser.add_argument('--eval-interval', type=int, default=10000)
parser.add_argument('--eval-n-runs', type=int, default=10)
parser.add_argument('--reward-scale-factor', type=float, default=1e-2)
parser.add_argument('--standardize-advantages', action='store_true')
parser.add_argument('--render', action='store_true', default=False)
parser.add_argument('--lr', type=float, default=3e-4)
parser.add_argument('--weight-decay', type=float, default=0.0)
parser.add_argument('--demo', action='store_true', default=False)
parser.add_argument('--load', type=str, default='')
parser.add_argument('--logger-level', type=int, default=logging.DEBUG)
parser.add_argument('--monitor', action='store_true')
parser.add_argument('--update-interval', type=int, default=2048)
parser.add_argument('--batchsize', type=int, default=64)
parser.add_argument('--epochs', type=int, default=10)
parser.add_argument('--entropy-coef', type=float, default=0.0)
最適化手法は,引数を何も取らない形(=Chainerデフォルトの値になる)を使った.
結果
結果(100移動平均)のグラフがこちら.
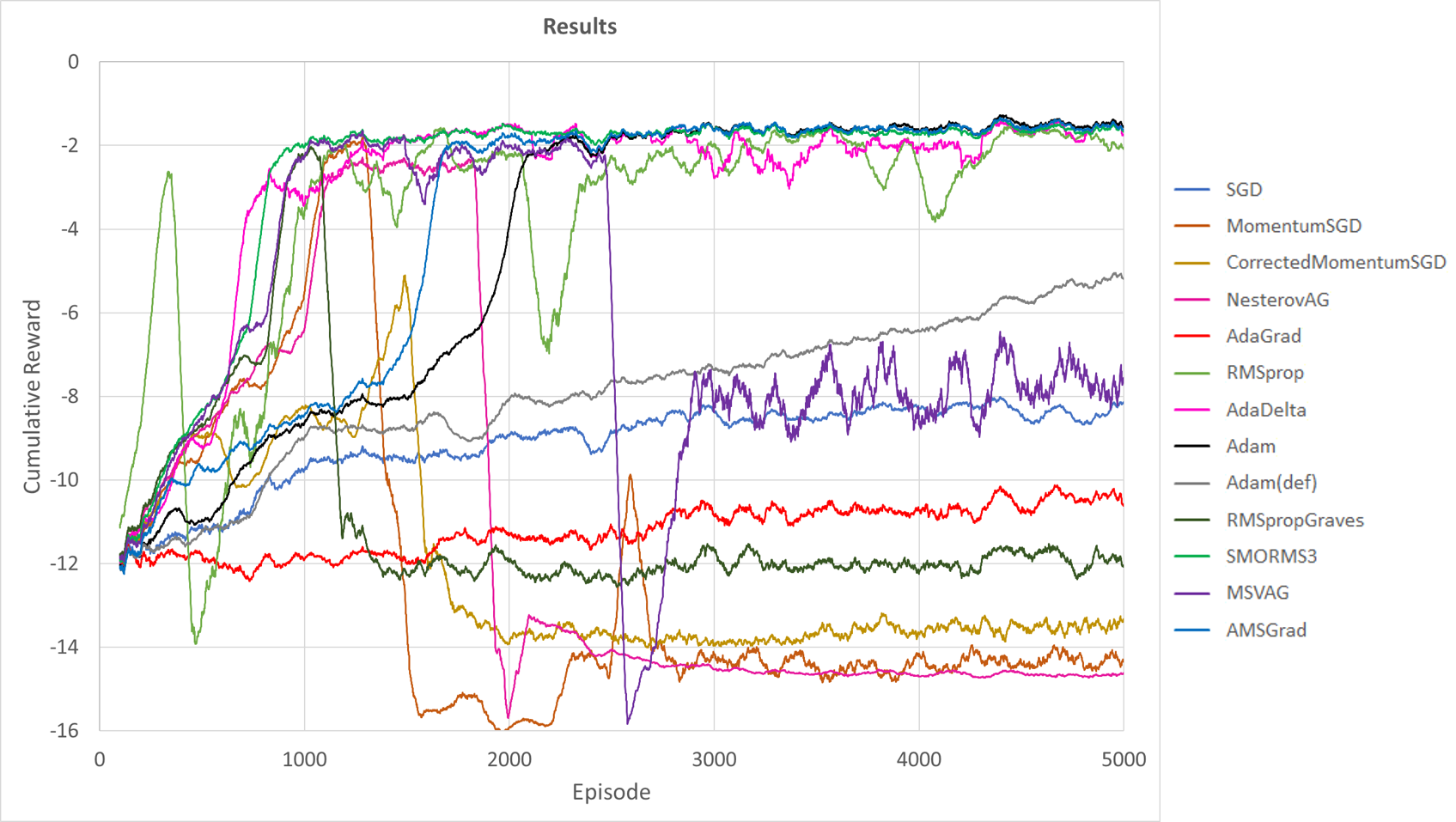
見にくいので分解したものも示す.
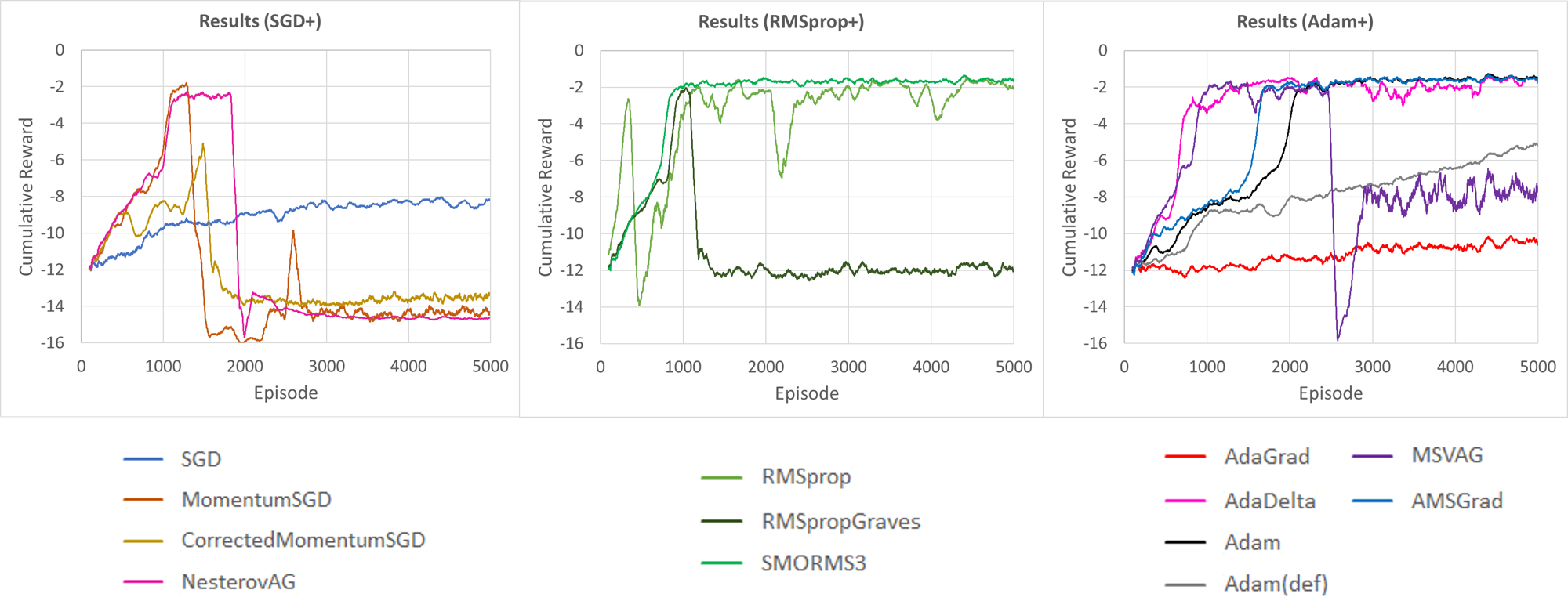
「SGDとその改良系」,「RMSpropとその改良系」,「Adamその他」に分けたグラフ.(Adam(def)が論文におけるデフォルトのパラメータ).
意外と違って驚き.SMORMS3がかなりよい感じである.
まとめ
例によって1試行しかしてないけれど,最適化手法の選び方で割と変わるってことがわかりました.なんか泥沼の気配しかしない