松尾研究室のGCIデータサイエンティスト育成講座
をやってみたところ、解答が無かったので、自分で作ってみました。
間違えていたらすみません、教えて頂けると嬉しいです
<練習問題 1>
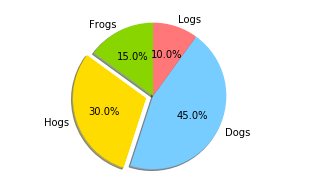
以前扱った学生のデータ(student-mat.csv)を使って、学校を選んだ理由(reason)を円グラフ化して、それぞれの割合を出してください。
import matplotlib.pyplot as plt
math_data=pd.read_csv("student-mat.csv",sep=";")
uniques=math_data["reason"].unique()
values=math_data["reason"].value_counts()
plt.figure(figsize=(5,3),facecolor="white")
sizes=[]
for i in range(len(uniques)):
sizes.append(values[uniques[i]])
colors = ['yellowgreen', 'gold', 'lightskyblue', 'lightcoral']
explode = (0, 0.1, 0, 0)
plt.pie(sizes, explode=explode, labels=uniques, colors=colors,
autopct='%1.1f%%', shadow=True, startangle=90)
plt.axis('equal')
<練習問題 2>
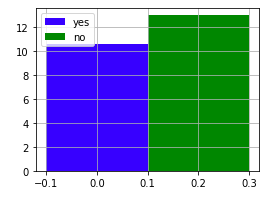
上記と同じデータで、higher - 高い教育を受けたいかどうか(binary: yes or no)を軸にして、それぞれの数学の最終成績G3の平均値を棒グラフで表示してください。ここから何か推測できることはありますか?
import matplotlib.pyplot as plt
import numpy as np
plt.figure(figsize=(4,3),facecolor="white")
X = 0
# グラフの幅
w=0.2
yes_data=math_data[math_data["higher"]=="yes"]["G3"].mean()
no_data=math_data[math_data["higher"]=="no"]["G3"]
plt.bar(X, yes_data, color='b', width=w, label='yes', align="center")
plt.bar(X + w, no_data, color='g', width=w, label="no", align="center")
# 凡例を最適な位置に配置
plt.legend(loc="best")
plt.grid(True)
<練習問題 3>
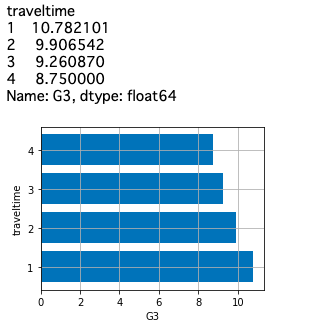
上記と同じデータで、通学時間(traveltime)を軸にして、それぞれの数学の最終成績G3の平均値を横棒グラフで表示してください。何か推測できることはありますか?
# 画像の大きさとバッグカラーの設定
plt.figure(figsize=(4,3),facecolor="white")
g3_grades=math_data.groupby("traveltime")["G3"].mean()
X = g3_grades.keys()
plt.barh(X,math_data.groupby("traveltime")["G3"].mean(), align="center")
plt.ylabel("traveltime")
plt.xlabel("G3")
plt.grid(True)
7.3 総合問題
7.3.1 時系列データ分析
ここでは、本章で身に付けたpandasやscipyなどを使って、時系列データついて扱っていきましょう。
(1)(データの取得と確認)下記のサイトより、dow_jones_index.zipをダウンロードし、中にあるdow_jones_index.dataを使って、データを読み込み、はじめの5行を表示してください。またデータのそれぞれのカラム情報等を見て、nullなどがあるか確認してください。
(2)(データの加工)カラムのopen、high、low、close等のデータは数字の前に$マークが付いているため、これを取り除いてください。また、日時をdate型で読み込んでいない場合は、date型に変換しましょう。
(3)カラムのcloseについて、各stockごとの要約統計量を算出してください。
(4)カラムのcloseについて、各stockの相関を算出する相関行列を出してください。また、seabornのheatmapを使って、相関行列のヒートマップを描いてみましょう。(ヒント:pandasのcorr()を使います。)
(5)(4)で算出した相関行列の中で一番相関係数が高いstockの組み合わせを抽出してください。さらに、その中でもっとも相関係数が高いペアを抜き出し、それぞれの時系列グラフを書いてください。
(6) pandasのrollingとwindow関数(窓関数)を使って、上記で使った各stockごとに、closeの過去5期(5週間)移動平均時系列データを計算してください。
(7) pandasのshift()を使って、上記で使った各stockごとに、closeの前期(1週前)との比の対数時系列データを計算してください。さらに、この中で、一番ボラティリティ(標準偏差)が一番大きいstockと小さいstockを抜き出し、その対数変化率グラフを書いてください。
import seaborn as sns
# (1),(2)
A=pd.read_csv("dow_jones_index.csv",sep=",")
A["high"]=A["high"].map(lambda x: float(x.split("$")[1]))
A["low"]=A["low"].map(lambda x: float(x.split("$")[1]))
A["open"]=A["open"].map(lambda x: float(x.split("$")[1]))
A["close"]=A["close"].map(lambda x: float(x.split("$")[1]))
from datetime import datetime as dt
A["date"] = A["date"].map(lambda x: dt.strptime(x, '%m/%d/%Y'))
# (3)
A.groupby("stock").close.describe()
# (4)
A_1=A.groupby("stock").close.apply(list)
df=pd.DataFrame()
key=A_1.keys()
list_df = pd.DataFrame()
for i in range(len(key)):
tmp_se = pd.Series(A_1[key[i]])
list_df = list_df.append( tmp_se,ignore_index=True )
list_df.index=key
list_df=list_df.T
list_df.corr()
import seaborn as sns
sns.set(style="white")
sns.heatmap(list_df.corr(),annot = False)
plt.show()
# (5)
corrs=list_df.corr()
max_value=max(corrs[corrs<1].max(1))
corrs[corrs==max_value]
plt.plot(range(len(list_df["CSCO"])),list_df["CSCO"])
plt.plot(range(len(list_df["MSFT"])),list_df["MSFT"])
# (6)
N=5 #N期を決定
AA=(list_df["AA"].rolling(N).sum()/N).dropna()
print(AA) #N期のデータ、株式"AA"
# (7)
stds=[]
np.log(AA/AA.shift()).std()
for i in range(len(key)):
ABC=(list_df[key[i]].rolling(N).sum()/N).dropna()
stds.append(np.log(ABC/ABC.shift()).std())
stds=np.array(stds)
print(stds[np.argmax(stds)],stds[np.argmin(stds)])
i=np.argmax(stds)
ABC=(list_df[key[i]].rolling(N).sum()/N).dropna()
np.log(ABC/ABC.shift())
plt.plot(range(len(np.log(ABC/ABC.shift()))),np.log(ABC/ABC.shift()))
i=np.argmin(stds)
ABC=(list_df[key[i]].rolling(N).sum()/N).dropna()
np.log(ABC/ABC.shift())
plt.plot(range(len(np.log(ABC/ABC.shift()))),np.log(ABC/ABC.shift()))
7.3.2 マーケティング分析
次は、マーケティング分析でよく扱われる購買データです。一般ユーザーとは異なる法人の購買データですが、分析する軸は基本的に同じです。
(1)下記のURLよりデータをpandasで読み込んでください(件数50万以上のデータで比較的大きいため、少し時間がかかります。)
http://archive.ics.uci.edu/ml/machine-learning-databases/00352/Online%20Retail.xlsx"
(ヒント)pd.ExcelFileを使って、シートを.parse('Online Retail')で指定してください。
また、今回の分析対象は、CustomerIDにデータが入っているレコードのみ対象にするため、そのための処理をしてください。さらに、カラムのInvoiceNoには数字の前にCがあるものはキャンセルのため、このデータを取り除いてください。他にもデータとして取り除く必要なものがあれば、適宜処理してください。以下、このデータをベースに分析していきます。
(2)このデータのカラムには、購買日時や商品名、数量、回数、購買者のIDなどがあります。ここで、購買者(CustomerID)のユニーク数、バスケット数(InvoiceNoのユニーク数)、商品の種類(StockCodeベースとDescriptionベースのユニーク数)を求めてください。
(3)このデータのカラムには、Countryがあります。このカラムを軸に、それぞれの国の購買合計金額(単位あたりの金額×数量の合計)を求め、降順にならべて、上位5つの国の結果を表示してください。
(4)上の上位5つの国について、それぞれの国の商品売り上げ(合計金額)の月別の時系列推移をグラフにしてください。ここで、グラフは分けて表示してください。
(5)上の上位5つの国について、それぞれの国における商品の売り上げTOP5の商品を抽出してください。また、それらを国ごとに円グラフにしてください。なお、商品は「Description」ベースで集計してください。
import pandas as pd
# (1)
excel =pd.ExcelFile('Online Retail.xlsx')
df = pd.DataFrame()
sheetdf = excel.parse('Online Retail')
A=sheetdf
B=A.index[A["CustomerID"].isnull()]
A=A.drop(B)
BA=A["InvoiceNo"].str.startswith('C')
BA=BA.fillna(False)
BA=A.index[BA]
A=A.drop(BA)
"""
(2)このデータのカラムには、購買日時や商品名、数量、回数、購買者のIDなどがあります。ここで、購買者(CustomerID)のユニーク数、
バスケット数(InvoiceNoのユニーク数)、商品の種類(StockCodeベースとDescriptionベースのユニーク数)を求めてください。
"""
print(A["InvoiceNo"].describe())
A["CustomerID"]=A["CustomerID"].map(lambda x: int(float(x)))
print("CustomerIDのユニーク数:",len(A["CustomerID"].unique()))
print("StockCodeのユニーク数:",len(A["StockCode"].unique()))
print("Descriptionのユニーク数:",len(A["Description"].unique()))
"""
(3)このデータのカラムには、Countryがあります。このカラムを軸に、それぞれの国の購買合計金額(単位あたりの金額×数量の合計)を求め、
降順にならべて、上位5つの国の結果を表示してください。
"""
Each_country=A.groupby("Country")["UnitPrice"].sum().map(lambda x : int(x))
Each_country.sort_values(ascending=False)[:5]
"""
(4)上の上位5つの国について、それぞれの国の商品売り上げ(合計金額)の月別の時系列推移をグラフにしてください。ここで、グラフは分けて表示してください。
"""
for i in range(len(Each_country_name)):
A["Date"]=A[A["Country"]==Each_country_name[i]]["InvoiceDate"].map(lambda x:"{}-{}".format(x.year,x.month))
import matplotlib.pyplot as plt
plt.figure(figsize=(20,15))
for i in range(len(Each_country_name)):
ax=plt.subplot(5,1,i+1)
prices=A[A["Country"]==Each_country_name[i]].groupby("Date")["UnitPrice"].sum()
ax.plot(prices.keys(), prices)
plt.title("{}".format(Each_country_name[i]),size=20)
"""
(5)上の上位5つの国について、それぞれの国における商品の売り上げTOP5の商品を抽出してください。
また、それらを国ごとに円グラフにしてください。なお、商品は「Description」ベースで集計してください。
"""
for i in range(len(Each_country_name)):
items=A[A["Country"]==Each_country_name[i]]["Description"].value_counts()[:5]
print("{}のTOP5:".format(Each_country_name[i]))
for k in range(5):
print("TOP{}".format(k+1),items.keys()[k])