不思議なメガネをかけるとそこにはバーチャルな嫁※1が。そんなマンガやアニメのようなこともHoloLensによって現実に近づいてきました。この記事ではバーチャルな嫁と会話するためのステップを説明します。
※1 一般社会におけるエージェントや秘書と読み替えてください。
注意点 2017/5現在ではHoloLensのOS(Windows10)の言語設定はen-USから変更できないため、本記事における嫁との会話は英語になります。
完成イメージ
対話デモその1(Qiita埋め込み用の投稿です) pic.twitter.com/1pkznyAaDE
— decchi (@decchi) 2017年5月6日
想定読者レベル
HoloToolkit-Unityを使ったHoloLensアプリを作成し、デプロイしたことがある。
環境
OS:Windows 10
Unity:5.6.0f3
HoloToolkit-Unity:1.5.6
会話するためのステップ
嫁との会話にいたるステップは大まかに以下の通りです。
- 音声認識で音声をテキストに変換する。
- 対話サービスに発話内容を送信する。
- 音声合成で対話サービスからの応答を音声に変換する。
イメージにするとこんな感じですね。
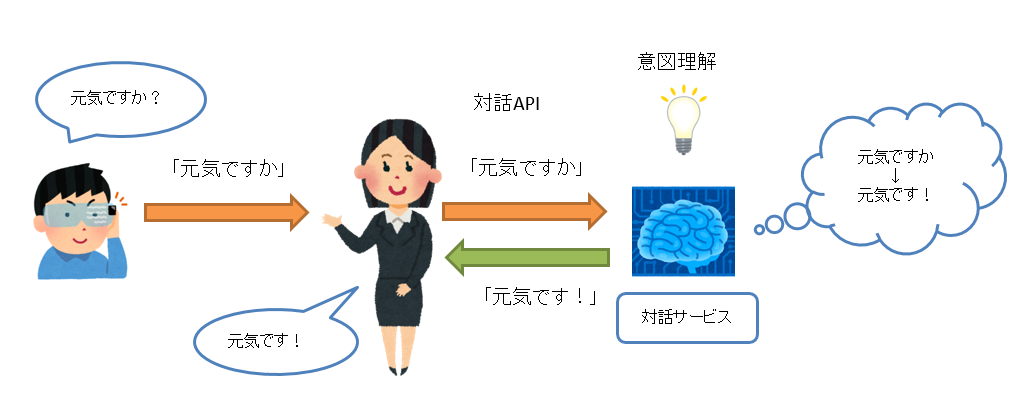
音声認識で音声をテキストに変換する(Speech to Text)
HoloLensで動くアプリケーションはUWPなので、UnityのAPIであるUnityEngine.Windows.Speech.DictationRecognizerを使って簡単に音声認識(Speech to Text)を実装することができます。
DictationRecognizerは音声の入力を検知すると以下の4種類のイベントを実行します。
| イベント名 | イベントの説明 |
|---|---|
| DictationResult | DictationRecognizerによる音声の聞き取りが完了した際に実行されます。実行のタイミングは入力からワンテンポ遅れますが、文章として成立するように補正がかかります。 |
| DictationHypothesis | 音声を発音している間継続的に実行されます。認識した文章は最初は聞き取った音声のままですが、聞き取りが進むと徐々に読める文章になります |
| DictationComplete | DictationRecognizerが止まった場合(後述)に実行されます |
| DictationError | エラーが起きた場合に実行されます。 |
実装
DictationRecognizerにはMicrophoneとInternet Clientの権限が必要なので、下図のようにして設定します。
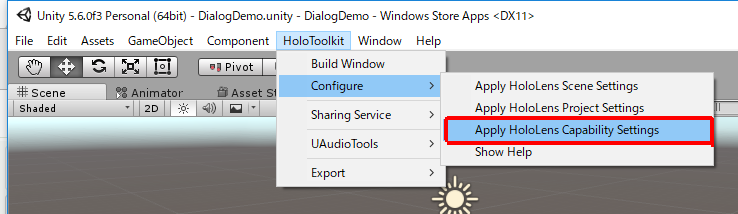
MicrophoneとInternet Clientにチェックを入れてApply
実装コードの例は以下の通りです。簡単ですね。
using HoloToolkit.Unity;
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.UI;
using UnityEngine.Windows.Speech;
public class DialogDemo : Singleton<DialogDemo>
{
public Text inputTextField;
public DictationRecognizer m_DictationRecognizer;
void Start () {
m_DictationRecognizer = new DictationRecognizer();
//DictationResultのイベントを登録
m_DictationRecognizer.DictationResult += (text, confidence) =>
{
//音声認識した文章はtextで受け取れます。
inputTextField.text = text;
};
//Dictationを開始
m_DictationRecognizer.Start();
}
void Update () {
}
}
音声認識が止まってしまう場合
音声認識を実装し、テストをしていると不意に音声認識がされなくなります。
この原因の多くは音声入力が一定期間ないと音声認識が止まってしまうことが原因と思われます。
この一定期間はDictationRecognizer.InitialSilenceTimeoutSecondsの値(デフォルト5秒)で決まっています。
この対策としては音声認識が止まった場合はDictationCompleteイベントがDictationCompletionCause.TimeoutExceededの
パラメータで実行されるので、この状態になったら再起動等のハンドリングをするという手があります。
コードは以下です。
m_DictationRecognizer.DictationComplete += (completionCause) =>
{
if (completionCause == DictationCompletionCause.TimeoutExceeded)
{
//音声認識を起動。
m_DictationRecognizer.Start();
}else
{
//その他止まった原因に応じてハンドリング
}
};
対話サービスに発話内容を送信する。
音声を文章に変換できたら対話サービスに送信します。
送信に使うプロトコルは利用する対話サービスによりますが、例えばapi.ai(https://api.ai) の場合はRESTful APIでJSON形式のデータをやりとりできます。
対話サービスの市場は変化が早いので、何を使うか迷ってしますね。
対話のシナリオを作成するのはそれなりに労力がかかるので、気になるものを少し触ってみていけそうか判断するとよいと思います。
対話サービスについては少し前の情報になりますが、下記の記事にまとめられているので、何を使うか決まっていない方は参照してみてください。
http://qiita.com/shiraco/items/eca5d0a6fc7fe6fb0f37
多くの対話サービスは機械学習による自然言語処理の成果を取り入れているので、対話サービスに登録した例文に対して入力された文章が少しブレていても意図を認識してくれます。これによって膨大な量のキーワードを入力することなく、少しの例文で自然な対話をすることができます。
例としてapi.aiと通信する処理を先ほどの音声認識の後に追加すると以下のようになります。
using HoloToolkit.Unity;
using System;
using System.Collections;
using System.Collections.Generic;
using System.Text;
using UnityEngine;
using UnityEngine.Networking;
using UnityEngine.UI;
using UnityEngine.Windows.Speech;
public class DialogDemo : Singleton<DialogDemo>
{
public Text inputTextField;
public Text answerTextField;
public DictationRecognizer m_DictationRecognizer;
private string URL = "https://api.api.ai/v1/query?v=20150910";
string str1 = "{\"query\":\"";
string str2 = "\",\"lang\":\"en\",\"sessionId\":\"123456789\"}";//sessionIdは適当です。
// Use this for initialization
void Start () {
m_DictationRecognizer = new DictationRecognizer();
m_DictationRecognizer.DictationResult += (text, confidence) =>
{
inputTextField.text = text;
//通信するためのメソッドはCoroutineで呼び出します。
StartCoroutine(GetReply(URL, str1 + text + str2));
};
m_DictationRecognizer.Start();
}
IEnumerator GetReply(string url, string bodyJsonString)
{
var request = new UnityWebRequest(url, "POST");
byte[] bodyRaw = Encoding.UTF8.GetBytes(bodyJsonString);
request.uploadHandler = (UploadHandler)new UploadHandlerRaw(bodyRaw);
request.downloadHandler = (DownloadHandler)new DownloadHandlerBuffer();
request.SetRequestHeader("Content-Type", "application/json");
request.SetRequestHeader("Authorization", "Bearer ここに作成したagentのaccess tokenを入力");
yield return request.Send();
//ResposeのJSON形式の文字列を扱いやすい形式に変換
ApiaiJson respose = JsonUtility.FromJson<ApiaiJson>(request.downloadHandler.text);
//返答の文字列を取得
answerTextField.text = respose.result.fulfillment.speech;
}
// Update is called once per frame
void Update () {
}
// 以下JSON変換のための構造体
[Serializable]
public class ApiaiJson
{
public string id;
public string timestamp;
public string lang;
public ApiaiJsonResult result;
public string sessionId;
}
[Serializable]
public class ApiaiJsonResult
{
public string source;
public string resolvedQuery;
public string action;
public bool actionIncomplete;
public ApiaiJsonFulfillment fulfillment;
public float score;
}
[Serializable]
public class ApiaiJsonFulfillment
{
public string speech;
}
}
音声合成で対話サービスからの応答を音声に変換する(Text to Speech)
対話システムから応答が戻ってきたら、返答の文章を音声合成してキャラクターに発話させます。
音声合成はHolokit-UnityにTextToSpeechManagerがあるので簡単に利用することができます。
今回は例としてユニティちゃんにしゃべってもらいます。
※ビルド時にユニティちゃんに付属するスクリプトがエラーになりますが、使わないので削除しても大丈夫です。
実装
ユニティちゃんをHierarchyビューに配置したらAudio SourceとTextToSpeechManagerをAdd Componentします。
TextToSpeechManagerのAudio Sourceには先ほど追加したAudio Sourceを設定します。設定した結果は以下の通りです。
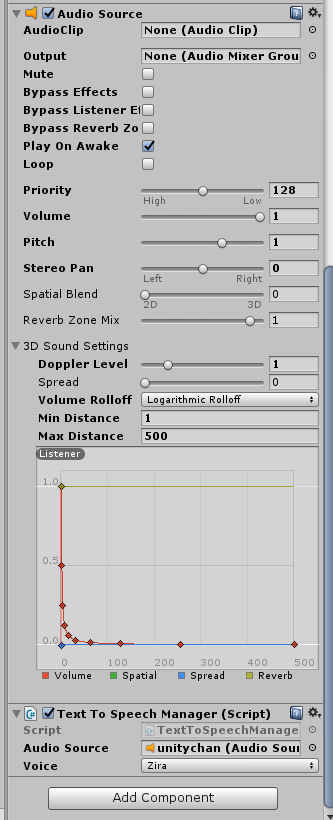
あとは対話サービスから取得した返答内容を以下のようにして音声に出力します。(一部抜粋)
public class DialogDemo : Singleton<DialogDemo>
{
//ユニティちゃんに追加したTextToSpeechManagerのインスタンスを保持するためのフィールドを追加
public TextToSpeechManager textToSpeech;
//中略
IEnumerator GetReply(string url, string bodyJsonString)
{
//中略
answerTextField.text = respose.result.fulfillment.speech;
//SpeakTextで発話。"."を発話してしまうので、置換しておく
textToSpeech.SpeakText(respose.result.fulfillment.speech.Replace(".", " "));
}
追加はたったの2行!簡単ですね。
これで対話自体は完成ですが、口が動かないので違和感がありますね。
より実在感を出すためにリップシンクを追加します。
リップシンクの実装については凹みさんのブログで詳しく説明されているので、参照してください。
http://tips.hecomi.com/entry/2016/02/16/202634
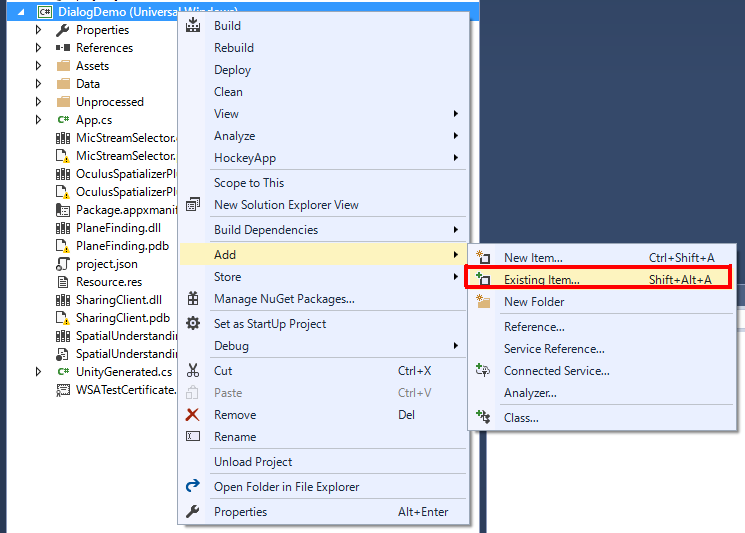
ここがハマりどころなのですが、出来上がったプロジェクトをUWPとして出力してデプロイしてもリップシンクしてくれません。原因はOVRLipSync.dllがコピーされていないからなのですが、なぜかはわかりません。とりあえず以下の手順で手動で追加し、解決します。
- Assets\Plugins\x86にあるOVRLipSync.dllをコピーする。
- ビルド時に出力したフォルダ内にあるプロジェクト名のフォルダ(同じ階層にOculusSpatializerPlugin.dllがあるはず)にOVRLipSync.dllをペースト
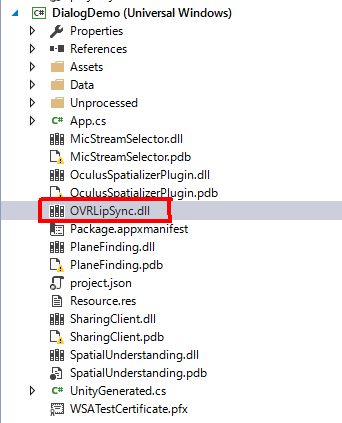
- UWPビルドのためのプロジェクトのソリューションファイル(.sln)を開き、プロジェクトにOVRLipSync.dllを追加(下図参照)
最終的に以下のようになっていればOKです。
あとはビルド、デプロイすれば完成です!
UXの向上
無事に嫁と対話できるようになりましたが、音声認識を使う上でのユーザーのUX向上のために以下の点は盛り込んでおいたほうが良いです。
- 音声認識の状態は表示する。(発話しているのに反応しないと非常に不快になる)
- 認識された音声は表示する。(発話内容が正しく認識されているかわからないと非常に不安になる)
私はこういうUIを作ってみました。(BillboardとTagalongをアタッチしてBodyLockedなUIです)

さらなるUXの向上
対話とは本質的には関係ないですが、以下の改善を加えると会話が楽しくなります。
- 会話している間はキャラクターの目線を合わせる。
- 話している内容に応じてキャラクターの表情を変える。
このあたりの実装は後日記事にしていこうと思います。
以上の改善を取り入れたら以下のようになります。
対話デモその2(Qiita埋め込み用の投稿です) pic.twitter.com/Sax83ZZuPW
— decchi (@decchi) 2017年5月6日
おわりに
今はまだアメリカンな嫁ですが、きっとすぐに日本語を理解してくれるようになるでしょう。実装は簡単なので音声対話を是非試してみてください。音声対話のUIはこれから流行ると思いますよ!