普段はインフラとかをやっているはずなんです。
外字とは
ユーザーまたはメーカーが独自に作成して登録した文字。
ユーザー定義文字とも呼ぶ。
JISコード表に含まれていない、異字体や記号などを利用したい場合に作成する。
Windows 98などでは、付属する外字エディターで外字を作成し、登録できる。
ざっくり言うと、「文字コードで表現できないので、独自に拡張した文字」のこと。
いつ使うのよ
多くは人名・地名でのマイナー漢字。
あと「㌢㍍」よろしく独自記号を使いたいなんて場合にも使われるけど、これは今回の話の対象外です。
人名における外字の具体例
マイナー漢字
漢字はJISの規格で第1~第4水準に分類されます。
このうち第3水準、第4水準の漢字はShift_JISの文字コードで定義されていないものが多い。
そういった漢字を使用する際に、外字として登録しているケース。
※ 実際に遭遇した例としては、「㐂」とか「昱」とか。
※ 「第2水準だけど、その文字が見つからないから外字で登録した」ってケースも割とあります。
あと別の例として、中国語でのみ使われる漢字なんてのも。
異体字
有名なのは「高」に対する「髙(はしごだか)」みたいな。
これはかなり種類が多く、例えば「辺」の異体字だと

と収拾つかないくらい存在するわけで。
で、表示できない異体字を外字として登録しているケース。
外字を運用する上での問題点
要は「ユーザ独自で定義するもの」なので、各々ばらばらに登録・管理していると
- 同じ文字コードなのに違う文字が出る
- 特定のPCでしか文字が表示されない
といった問題が発生します。
これを解消するべく、外字を管理・配布するサーバもあったりするくらい。
それ本当に外字でないといけないの?
ようやく本題。
このうち第3水準、第4水準の漢字はShift_JISの文字コードで定義されていないケースが多く、それらを使用する際に外字を登録していました。
と書いたんですが、システムで使用する文字コードがUTF-8の場合、「外字で取り扱わなければいけない漢字」はほとんど存在しません。
マイナー漢字(第3・第4水準漢字)
Unicodeにおいては、全て定義済みです。
中国語の漢字についても同様に定義されているので、使用可能です。
異体字
これもUnicodeにおいては定義されているものの、少し定義の仕方が違います。
通常の文字を表すコードに加え、IVSというセレクタの値を用いて異体字を区別しています。
具体的な例は
あたりを読むと分かりやすいかと。
例外
現(2017年12月)時点ではまだ、文字コードが割り当てられてない文字が存在します。
とは言えこれらも含め、2017年度末(2018年3月末)で全文字の符号化が完了する予定となっています。

( http://mojikiban.ipa.go.jp/1309.html 「符号化状況」より引用 )
2018年度中には、対応フォントで取り扱えるようになるのではないでしょうか。
入力の仕方
普通に変換できるケースもありますが、そうではない場合や読みが分からない場合。
1. 探す
http://mojikiban.ipa.go.jp/search/
で探す。
※ 画数は「10-12」のような範囲指定が可能なので、多少探しやすいかと。
2. 見つけたらコピー
例えば「萩」の異体字を探していた場合
ちゃんと「コピペフィールド」が用意されているので、コピー
3. ペースト
以下PowerPointでペーストした例。
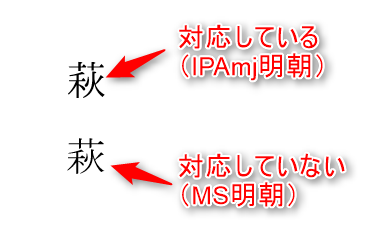
フォントがIVSに対応していない場合、文字コード部のみで判定される。
エディタによっては

てな感じで、後ろに変な記号が入ったりする。この部分がIVS。
ブラウザにも同様にペーストできるんですが。
入力フォーム部分、表示部分ともIVS対応フォントで表示するようCSSで指定しておかないと、ちゃんと入力されているか非常に判断しづらい。
※ 見た目には普通の「萩」が入力されているようにしか見えない。
IVSに対応したフォント
上記例のIPAmj明朝がおそらくもっとも有名かと。
他のフォントを使用したい場合は
https://citpc.jp/product_font.html
あたりで探していただくのがよいかと思われます。
それでも困るケース
というわけで、UTF-8で統一されている環境だったら困らない状況は割と整っています。
しかしそれでも困るケースはあるわけで
- 深遠な理由でShift_JISで出力しなきゃいけない
- もっともこの場合は第3水準・第4水準もわりかしアウト
- 対応したフォントを使えない
- IPAも把握していない謎の文字を使っている
なんてケースはカバーしようがないです。
BOM使えば解決するケースもあるにはある
ただし、WindowsとExcel、およびCSVの話であれば回避できるケースがあります。
ExcelでCSVファイルをそのまま(それこそダブルクリックとかで)開いて使用する場合、
- Shift_JISのCSVファイル: 文字化けしない
- UTF-8のCSVファイル: 文字化けする
という問題にぶち当たるんですが。
BOM(Byte Order Mark)付きのUTF-8であれば、そのままExcelで開いても文字化けしなかったりします。
要件などもろもろクリアになるのであれば、BOM付UTF-8を使うという選択肢もなくはないです。
※ とは言え、BOM付きUTF-8であまりいい思い出がないのも事実ですが。。。
というわけで
「それ本当に外字ですか?」とクライアントに聞ける環境は、わりかし整っているというお話でした。
- データ移行で正しくマッピングしてあげなきゃいけない
- そもそも該当する文字を探すのが大変
- どこかでShift_JISが必須なもんでやっぱり導入できない
なんて話もあったりなかったりしますが、まあそれはそれ。
まとめ
自分の投稿のタグがばらばらすぎて、何屋さんなんだろうと思います。