目的
KaggleやSignateなどの分析コンペでは、初動の速さが重要となるため、
よく使うJupyter Notebook系のテンプレートを整理して初動を速くする。
随時更新。
変更
2020.5.25 乱数設定変更 (関数化)
2020.7.5 優先度を追加, 優先度順に並び替え
2020.7.5 pandas backend 'plotly'追加
2020.10.21 pandasの分布変換:正規化(minmax), 標準化(norm), boxcox, rankgauss
目次
優先度:◎必須 〇必要 △状況に応じて
- importテンプレート:◎
- 乱数シードの固定:◎
- Pandasメモリ削減:〇
- Pandas最大表示数:〇
- ライブラリの自動ロード:〇
- データリード:△
- 性能プロファイル (%%time / %lprun):△
- matplotlib日本語化 (簡単):△
- pandas backend 'plotly' △
10.分布変換 (正規化, 標準化など) 〇 ※書き途中
1.importテンプレート
優先度:◎
notebook上での動作を想定。
必ず使う乱数設定と、グラフ表示系のインポート。
import pandas as pd
import numpy as np
import pandas_profiling as pdp
import lightgbm as lgb
import random
from numba import jit
import matplotlib.pyplot as plt
import matplotlib
from matplotlib.dates import DateFormatter
%matplotlib inline
import seaborn as sns
def seed_everything(seed):
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
if "tr" in sys.modules:
tf.random.set_seed(seed)
seed_everything(28)
# 最大表示行数の指定(ここでは50行を指定)
pd.set_option('display.max_rows', 100)
pd.set_option('display.max_columns', 50)
%load_ext autoreload
%autoreload 2
import os
# windows
if os.name == 'nt':
path = '../input/data/'
import japanize_matplotlib
sns.set(font="IPAexGothic")
elif os.name == 'posix':
# Kaggle
if 'KAGGLE_DATA_PROXY_TOKEN' in os.environ.keys():
path = '/kaggle/input/'
# Google Colab
else:
from google.colab import drive
drive.mount('/content/drive')
!ls drive/My\ Drive/'Colab Notebooks'/xxx # xxx 書き換える
path = "./drive/My Drive/Colab Notebooks/xxx/input/data/" # xxx 書き換える
# セッションの残り時間の確認
!cat /proc/uptime | awk '{print $1 /60 /60 /24 "days (" $1 / 60 / 60 "h)"}'
print(os.name)
print(path)
2. 乱数シードの固定
優先度:◎
乱数のシードを固定しないと、予測結果などが毎回変わってしまい効果がわかりにくくなるので、固定。
乱数に関わるモジュールの設定
import numpy as np
import random
import os
def seed_everything(seed):
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
if "tr" in sys.modules:
tf.random.set_seed(seed)
乱数に関わるLightGBMのパラメータ
lgb_params = {
'random_state':28,
'bagging_fraction_seed':28,
'feature_fraction_seed':28,
'data_random_seed':28,
'seed':28
}
3. Pandasメモリ削減
優先度:〇
データフレームの数値の範囲から、型を自動設定。限られたメモリで、何千万フレームなどのビッグデータを使うときに必要になる。
参考 by @gemartin
https://www.kaggle.com/gemartin/load-data-reduce-memory-usage
# Original code from https://www.kaggle.com/gemartin/load-data-reduce-memory-usage by @gemartin
# Modified to support timestamp type, categorical type
# Modified to add option to use float16 or not. feather format does not support float16.
from pandas.api.types import is_datetime64_any_dtype as is_datetime
from pandas.api.types import is_categorical_dtype
def reduce_mem_usage(df, use_float16=False):
""" iterate through all the columns of a dataframe and modify the data type
to reduce memory usage.
"""
start_mem = df.memory_usage().sum() / 1024**2
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
if is_datetime(df[col]) or is_categorical_dtype(df[col]):
# skip datetime type or categorical type
continue
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if use_float16 and c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
4. Pandas最大表示数
優先度:〇
pandasのDataFrameを表示すると、ある行数/列数以降、省略表示(...)になってしまう。
最大表示数を設定して、省略を制御する。
# 最大表示行数の指定(ここでは50行を指定)
pd.set_option('display.max_rows', 100)
pd.set_option('display.max_columns', 50)
5.ライブラリの自動ロード
優先度:〇
ライブラリを変更した場合でも、実行時に自動ロードしてくれる。
%load_ext autoreload
%autoreload 2
参考
https://qiita.com/Accent/items/f6bb4d4b7adf268662f4
6.データリード プラットフォーム別
優先度:△
import os
# windows
if os.name == 'nt':
#xxx
elif os.name == 'posix':
# Kaggle
if 'KAGGLE_DATA_PROXY_TOKEN' in os.environ.keys():
#xxx
# Google Colab
else:
#xxx
print(os.name)
7.性能プロフィル
高速化したい場合は、まずボトルネックを見つけることが重要。
JupyterなどのNotebookでの使用を想定。
簡単:セル内の処理時間を知りたい場合は、%%timeが便利。
詳細:各行の詳細処理時間を知りたい場合は、%lprunが便利。
7.1 %%time
優先度:△
セルの先頭jにつけること。
セル全体の実行時間を表示してくれる。
%%time
def func(num):
sum = 0
for i in range(num):
sum += i
return sum
out = func(10000)
7.2 %lprun
行ごとに、実行時間を出力してくれる。%%prunはモジュール単位のため、わかりにくい場合があるが。%lprunは行ごとでよりわかりやすい。
以下、3ステップ。
Step0. インストール
Step1. ロード
Step2. 実行
Step0 インストール
インストール済ならスキップ。
Google Coab、Kaggleクラウド用コマンド
!pip install line_profiler
Step1 ロード
%load_ext line_profiler
Step2 実行
def func(num):
sum = 0
for i in range(num):
sum += i
return sum
%lprun -f func out = func(10000)
8.matplotlib日本語化 (簡単)
優先度:△
Google Colabなど、クラウドプラットフォームを使っている場合、システムを変更が難しい場合がある。自動で、日本語のフォント事、パッケージをインストールしてくれるので比較的楽。
注意点は、seabornはimport時に、fontも設定してしまうので、最後にsns.setを実行すること。
import seaborn as sns
!pip install japanize_matplotlib ### インストール
import japanize_matplotlib
sns.set(font="IPAexGothic") ### 必ず、最後に実行
9.pandas backend 'plotyly'
優先度:△
Cufflinksを使って、plotlyを呼び出すラッパー。
plotlyとは、インタラクティブにグラフを扱うことができるライブラリ。
通常、plotlyを使うには、呪文のような設定をたくさん書かなければいけないが、Cufflinksを使うことで、いつものようにpandasでグラフを書くように表示できる。
「pd.options.plotting.backend = "plotly"」一行、書けば良い。
参考
https://plotly.com/python/pandas-backend/
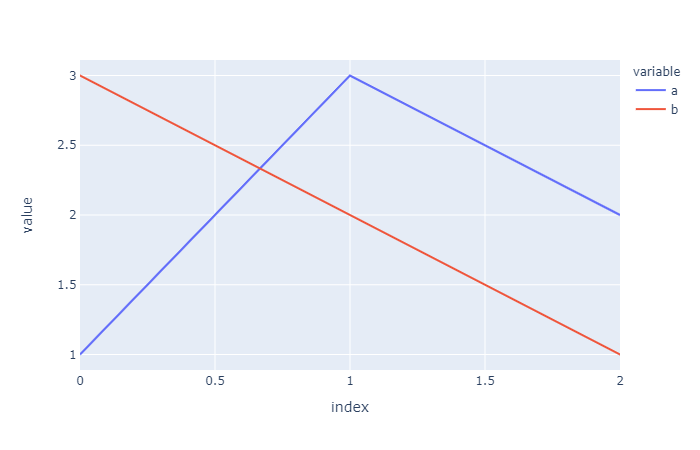
import pandas as pd
pd.options.plotting.backend = "plotly"
df = pd.DataFrame(dict(a=[1,3,2], b=[3,2,1]))
fig = df.plot()
fig.show()
10. 分布変換 (pandas)
優先度:〇
RandomForestやLightgbm, Xgboostなどツリー系はあまり気にする必要がないが
NeuralNetやDeepLearning, 重回帰など標準化などによって、スケールが異なる特徴量を合わせる必要がある。最小最大を使う正規化は、外れ値に影響を受けやすいので、わからなければ標準化が無難
RankGaussは、分布を無理やり正規分布に近づける。正規分布を仮定しているNearalNetなどによく効く。
正規化(minmax), 標準化(norm), boxcox, rankgauss
※書き途中