本記事はNTTドコモR&Dアドベントカレンダー2021の最終日(25日目)の記事です。
NTTドコモ サービスイノベーション部 ビッグデータ担当 新入社員の小澤です。
学生時代は、機械学習分野の研究に取り組んでいましたがドコモでは、膨大な通信に関するデータの加工を担うデータエンジニア的な業務に携わっております。ドコモではリアルタイムでお客様から得られるビッグデータを処理する必要があるため、サーバへの負荷を分散させるためにロードバランサを利用することが重要になります。そこで、ロードバランサの基礎から関連する技術、Google、Facebook、GitHubが開発したロードバランサのOSSについてまとめてみようと思います。
ロードバランサとは
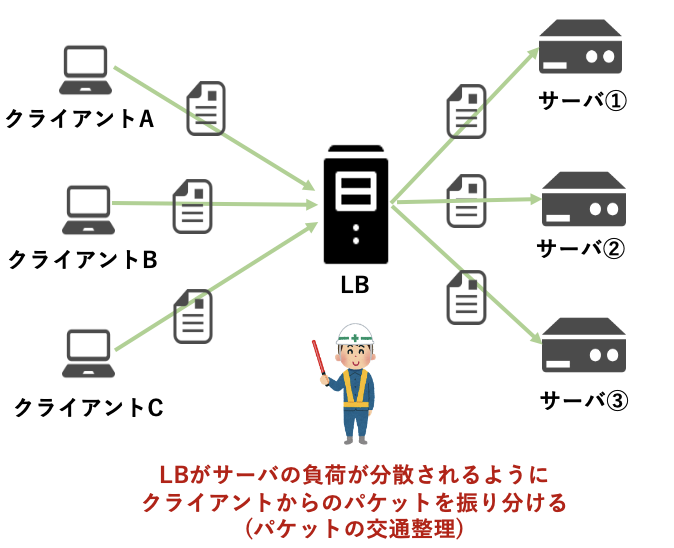
**ロードバランサ(LB)とは、ラウンドロビンなどの何らかのアルゴリズムを用いてサーバへの負荷が分散されるように、パケットを振り分けてくれる装置のことを指します。**簡単に言うと、パケットの交通整理を担ってくれる機能です。サーバに対して大量のパケットが送られてくる場合に、なくてはならない機能です。
L4ロードバランサ
**OSI参照モデルにおける第4層(=トランスポート層)の情報を確認して、パケットを振り分けます。**IPアドレスとポート番号を利用してTCP、UDPパケットを振り分けます。シンプルな仕組みであるため、その分高速です。AWSの機能に当てはめると、NLBが該当します。
IPパケットから得られる5つの情報、いわゆる5tupleと呼ばれる以下の情報を用います。
- 送信元IPアドレス(Source IP)
- 送信元ポート番号(Source Port)
- 送信先IPアドレス(Destination IP)
- 送信先ポート番号(Destination Port)
- プロトコル(Protocol)
L7ロードバランサ
**OSI参照モデルにおける第7層(=アプリケーション層)の情報を確認して、パケットを振り分けます。HTTPのヘッダ等の中身を確認して、L4LBよりも高度なパケットの振り分けが可能です。**例えば、ブラウザやHTTPメソッド、URLを識別子とした振り分けが可能です。ただし、HTTPSなどの暗号化された通信の内容を復号化して、ヘッダの中身を確認する(TLSの終端をLBにする)必要があるため、CPUへの負荷が高まるため、L4ロードバランサと比較し、振り分けにおけるパフォーマンスは低下してしまいます。AWSの機能に当てはめると、ALBが該当します。
ステートフルなLB VS ステートレスなLB
①ステートフルなLB: 「状態を保持する」という意味#####
**ステートフルなLBの場合、LB側でパケットにおけるコネクションの情報を保持することになります。つまり、パケット毎に、どのサーバへ送信されたのかについての情報を保持することになります。コネクションの情報を保持するため、同一のセッションの場合は同一のサーバへ接続させることが可能です。**例えば、Webサイト上で入力フォームを用いて情報を登録する際には入力した内容に矛盾がなく、情報を修正したい際にも自分が入力した情報に対して修正が可能ですよね。これは、同一サーバで処理されるからこそ可能なことです。LBがコネクションの情報を保持する手法は複数ありますが、膨大なパケットが送り付けられてくる場合、LB側でコネクションの情報を管理することができなくなり、新たなパケットを受け付けられなくなってしまう問題があります。GoogleやFacebookでは、世界中から大量なアクセスが生じるため、負荷分散の機能に加えてコネクションの情報を保持するステートフルなLBでは、パケットを処理することが困難です。更にLB自体をスケールアウトしたい場合は、複数のLB間でコネクションの情報を同期しておく必要があります。したがって、LBの負担が大きくなってしまいます。また、ステートフルなLBの場合、転送先サーバは送信元のLBに返答の必要がありますが、スケールアウトすると、どのLBに返答すべきなのかが分からなくなってしまい、コネクションが遮断されてしまう可能性があります。そこで、GoogleやFacebookをはじめとする大量のアクセスが生じる企業では、LB側でコネクションの情報を保持しないステートレスなロードバランサを用いることができないかと考え始めます。
②ステートレスなLB: 「状態を保持しない」という意味#####
**ステートレスなLBの場合、LB側でコネクションの情報は保持しません。したがって、ステートフルなLBよりもLBの負担が軽減されることになります。しかし、TCPパケットが送信されてきて、ラウンドロビンやコネクション転送先サーバの数やCPU使用率を確認してLBがパケットを転送する場合、通信毎に別のサーバに転送されてしまいます。**これでは、クライアントがコネクションを張っていなかった別のサーバへ転送してしまい、コネクションが途切れてしまう可能性があります。UDPパケットの場合は、転送先のサーバを変更してもコネクションは途切れませんが、パケットを複数回に分割して送信している場合はパケットの損失が生じてしまいます。
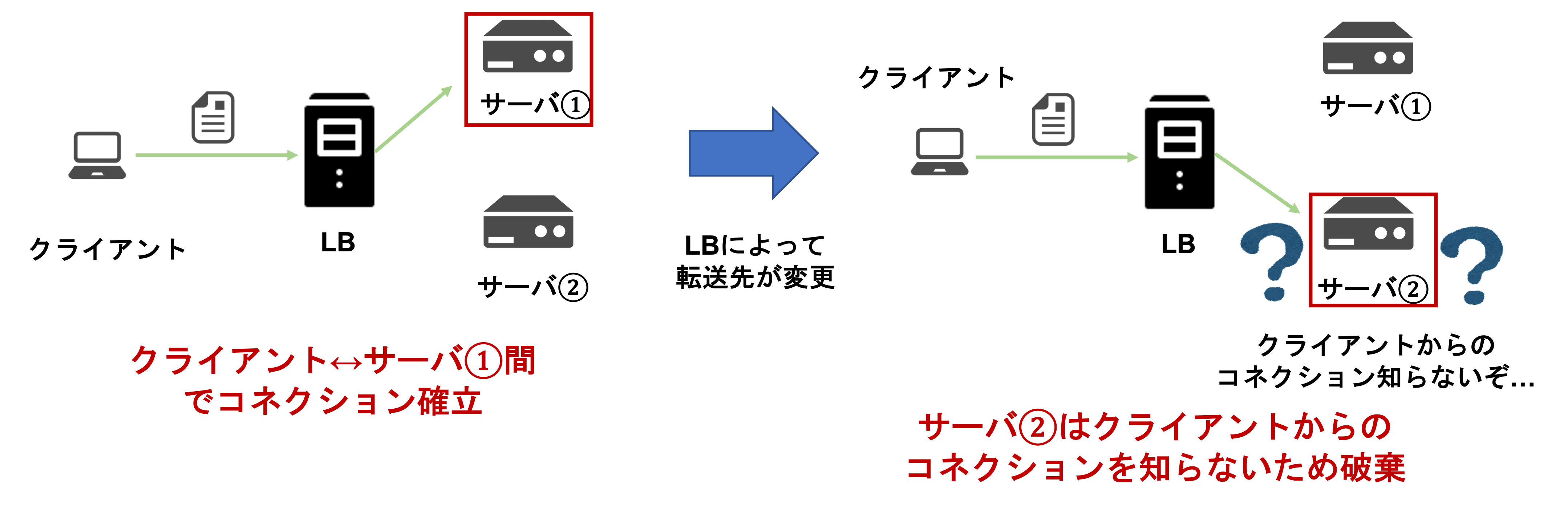
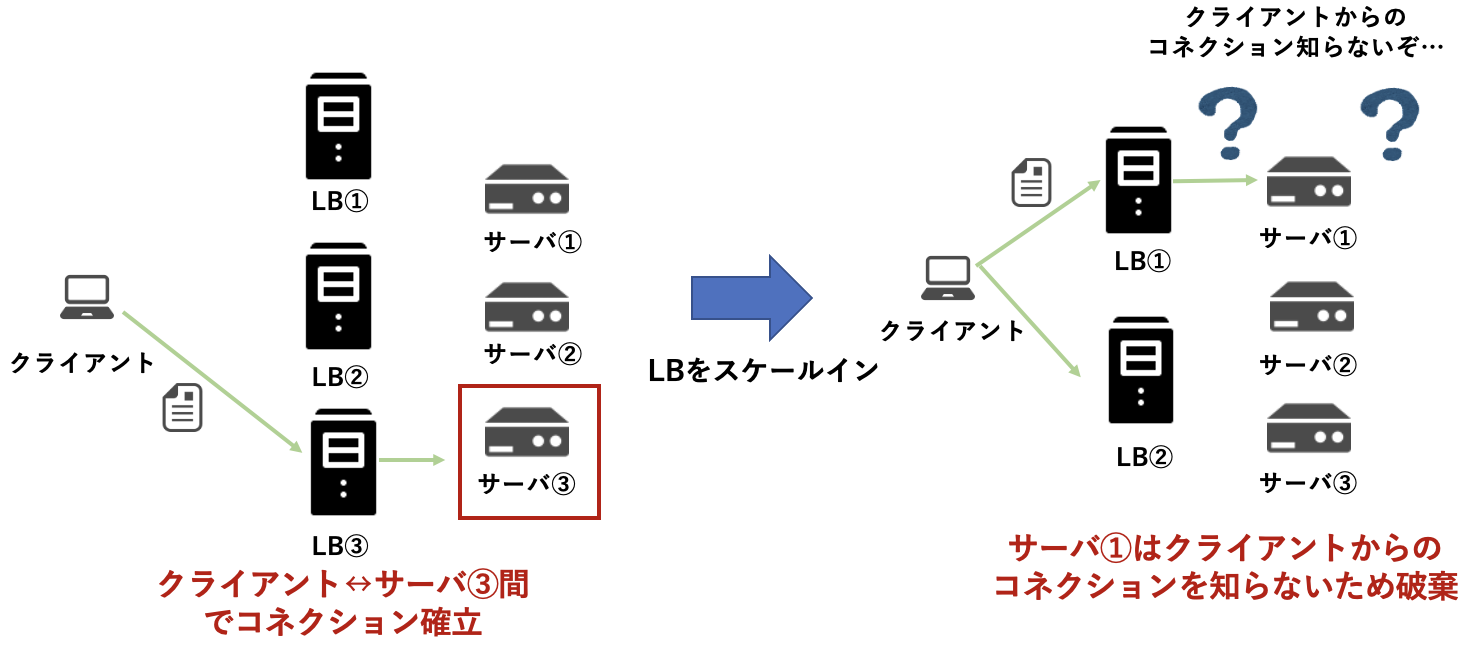
ステートフルなLB & ステートレスなLBに共通する問題
**ステートフルなLBとステートレスなLBに共通する問題は、LBをスケールインした場合に、異なるLBにパケットが送信され、クライアントがコネクションを張っていなかった別のサーバにパケットを転送してしまい、コネクションが途切れてしまう可能性があることです。**そもそも、ステートレスなLBの場合は、通信毎に別のサーバに転送されてしまいますが。。。ステートフルなLBの場合は、複数のLB間でコネクションの情報を同期すれば解決できるのではないかと考えるかもしれません。しかし、大量のクライアントからのアクセスが生じる場合、複数のLB間でコネクションの情報をリアルタイムで同期することは難しく、LB側の負担も大きくなってしまい現実的ではありません。
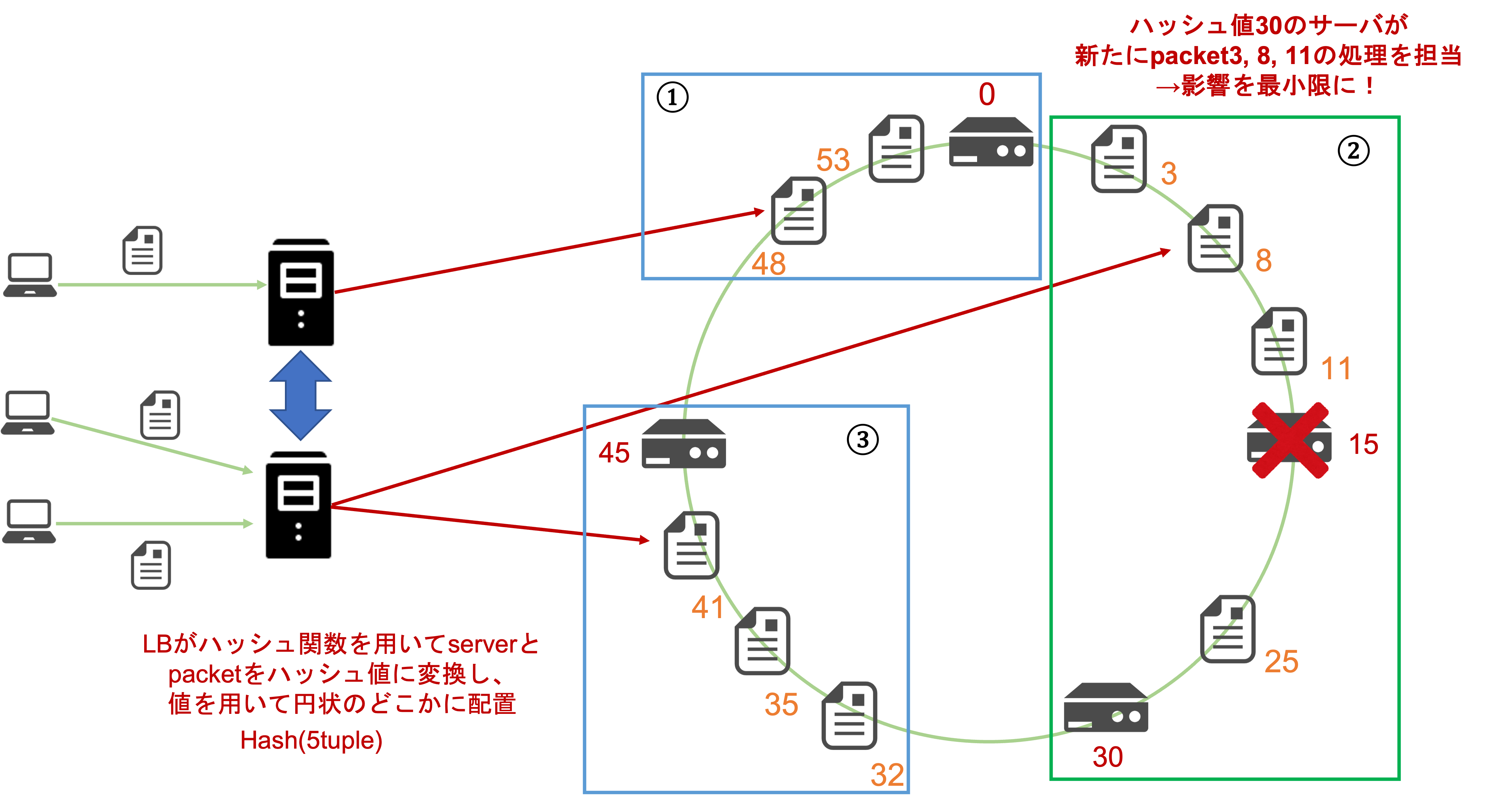
Consistent Hashing
**Consistent Hashingとは、ハッシュテーブルアルゴリズムの一種です。5tupleを用いて算出したハッシュ値をベースとして転送先のサーバを決定します。つまり、異なるLBにパケットが送信されても同一クライアントからの送信であれば、同一のサーバに転送されるため、事実上、複数のLB間で転送先が同期している状態になります。これによってLB自体をスケールイン、スケールアウトをした際に生じた問題を解決できますね。ステートフル、ステートレスなLBに関わらず同一コネクションに対する転送先サーバは一貫しているのです。**ステートレスなLBでの問題は、通信毎に別のサーバに転送されてしまい、コネクションが途切れてしまう可能性がありましたが、Consistent Hashingを用いることによって、この問題は解決されます。
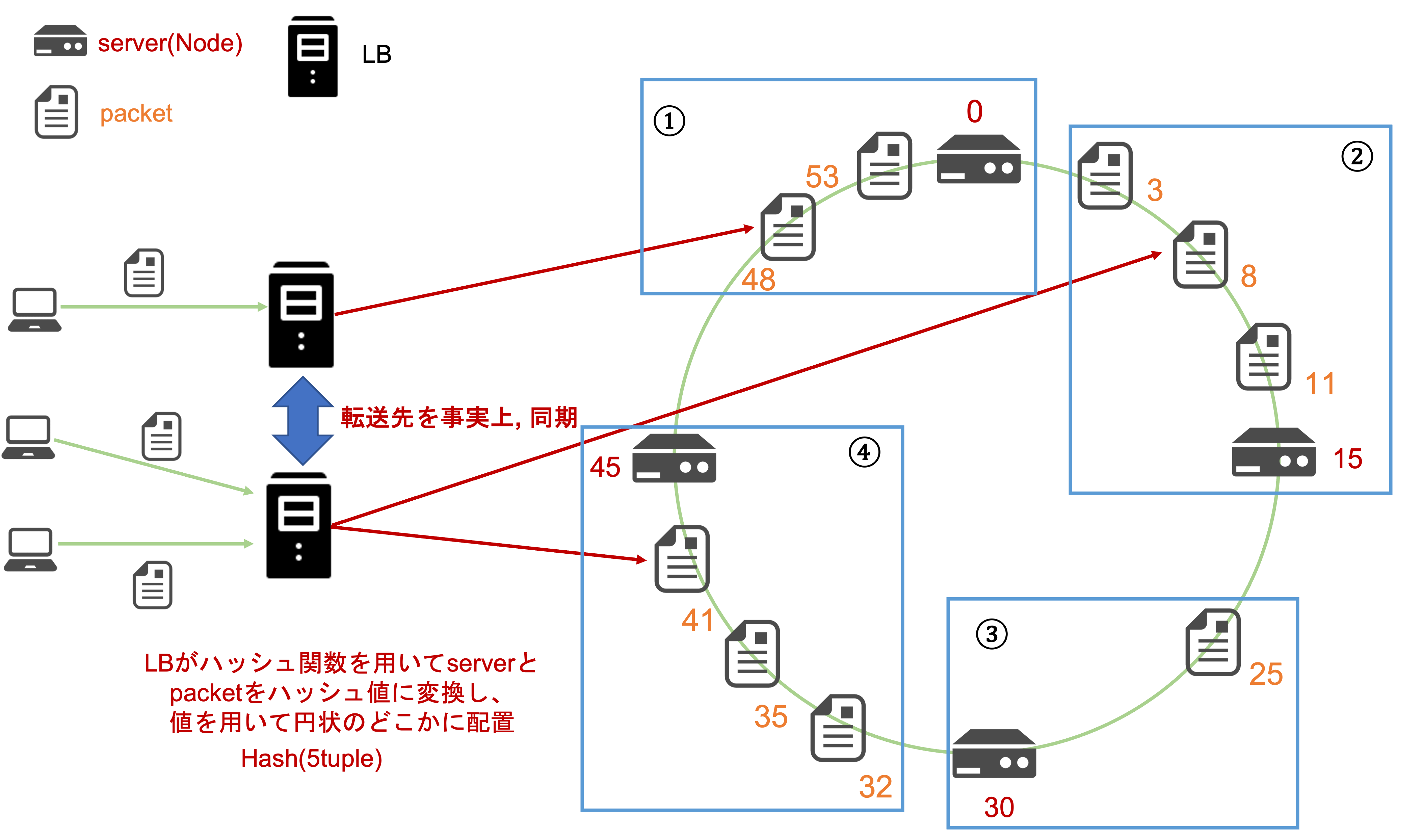
ステートレスなLBにおいても、転送先のサーバ群がスケールアウト、スケールインした場合も可能な限り同じサーバに転送しようとします。ステートレスなLBの場合は、既存のコネクションの情報をLBで保持しません。したがって、転送先サーバがスケールアウト、またはスケールインした場合は転送先の更新に伴い、その影響範囲が大きくなる可能性もあり、多くの既存のコネクションが途切れてしまう可能性がありました。しかし、この問題については影響を最小限にとどめることが可能です。以下の図のように、1台のサーバ(ハッシュ値:15)をスケールインした場合、ハッシュ値3、8、11の転送先サーバはハッシュ値15から30のサーバに変更されます。したがって、パケット送受信におけるコネクションが途切れてしまいます。しかし、その影響は3つのパケットのみに限定されます。スケールアウトした際にも既存のパケットにおけるコネクションを限定させることが可能です。このように、ステートレスなLBにおいてConsistent Hashingを用いることでスケールイン、スケールアウトの際に既存のコネクションに対する影響を抑え、コネクションの損失を最小限にとどめることが可能です。
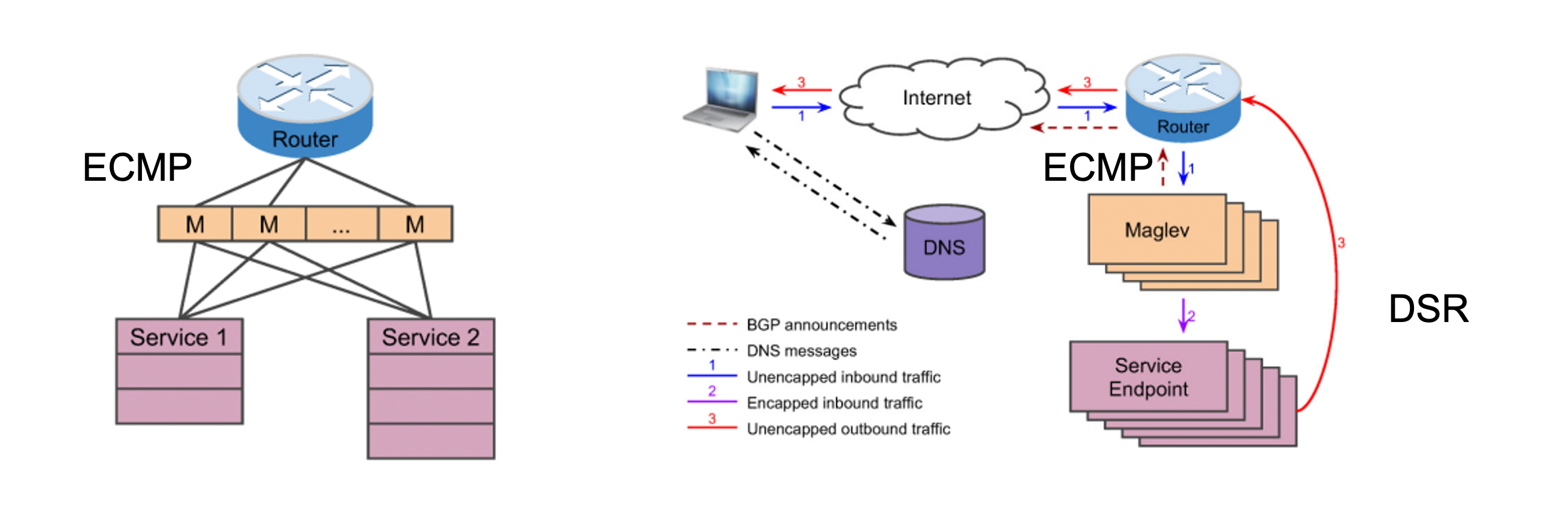
Google: Maglev
Googleが開発したMaglevというLBについて紹介します。以下にMaglevの論文[2]より引用した、概要図を添付します。**MaglevはECMPを用いてパケットが送られてきて、Consistent Hashingを応用しているMaglev Hashingを用いたステートレスなLBです。**まず、ルータはECMP(Equal Cost Multipath)によってMaglev(LB)にパケットを均一に送信します。ここで、ECMPとはパケットを送信する際に同じコストのルートが存在した場合に、パケットを分割して送信する手法のことを指します。
次にMaglev Hashingのアルゴリズムと計算例について示します。以下にMaglevの論文[2]より引用したMaglev Hashingのアルゴリズムの図を示します。

実際に上記のアルゴリズムを用いて動作を計算してみます。ここで、offsetとskipは以下のように定義します。B0, B1, B2はLBの転送先のサーバ(realサーバ)です。ハッシュ値は0から6の7通りとするため、M=7になります。
| B0 | B1 | B2 |
|---|---|---|
| 3 | 0 | 3 |
| 4 | 2 | 1 |
上記の表とM=7よりサーバ毎のpermutationの値は以下のように算出します。
permutation[i] = (offset + i * skip) % 7
算出した結果は以下の表のようになります。
| B0 | B1 | B2 | |
|---|---|---|---|
| 0 | 3 | 0 | 3 |
| 1 | 0 | 2 | 4 |
| 2 | 4 | 4 | 5 |
| 3 | 1 | 6 | 6 |
| 4 | 5 | 1 | 0 |
| 5 | 2 | 3 | 1 |
| 6 | 6 | 5 | 2 |
上記の表より、Maglev Hashingを用いてハッシュ値に対応するLBの転送先のサーバを決定していきます。その過程を以下の図に示します。①B0の列を見ます。entry[3]の初期値より、ハッシュ値3は空き(-1)なのでentry[3]は0(B0)が担当します。次に、B1の列を見ると、ハッシュ値0は空きのため、1(B1)が担当します。②B2の列を見るとハッシュ値3は割り当て済みのため、次の行に進みます。ハッシュ値4は空きのため、2(B2)が担当します。③B0のターンに戻ってきました。ハッシュ値0, 4は割り当て済みのため、2行進みます。ハッシュ値1は空きのため、0(B0)が担当します。このような流れでハッシュ値に対応するサーバ(B0-B2)の割り当て先を決定します。
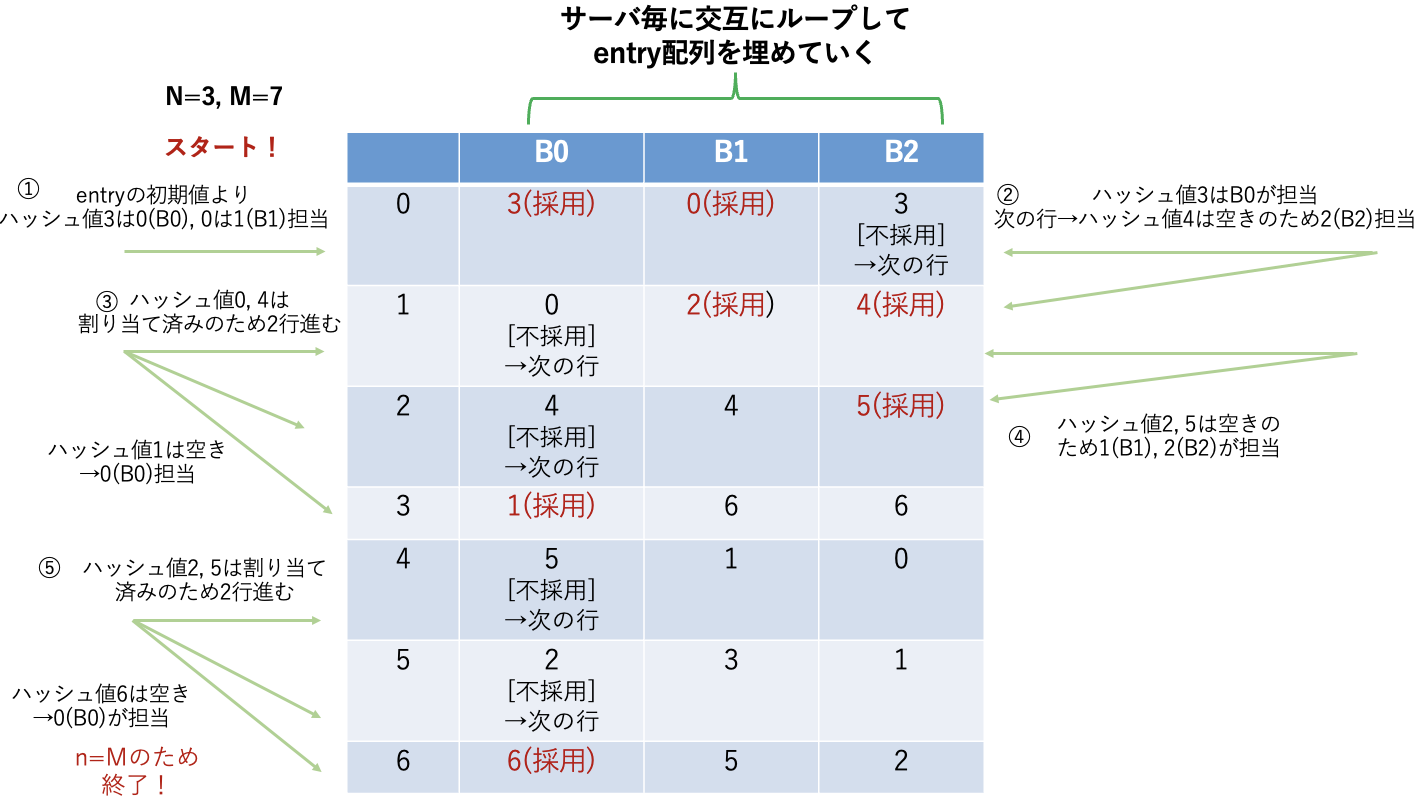
ハッシュ値に対応するサーバの担当一覧は以下の表のような結果になります。論文中に登場するLookup Tableのことを指します。この結果より、Maglev Hashingによってサーバの負荷が分散されていることが確認できます。
| ハッシュ値 | 転送先サーバ |
|---|---|
| 0 | B1 |
| 1 | B0 |
| 2 | B1 |
| 3 | B0 |
| 4 | B2 |
| 5 | B2 |
| 6 | B0 |
では、サーバB1に障害が発生した場合はどうでしょうか。
サーバ毎のpermutationの値は以下のようになります。
| B0 | B2 | |
|---|---|---|
| 0 | 3 | 3 |
| 1 | 0 | 4 |
| 2 | 4 | 5 |
| 3 | 1 | 6 |
| 4 | 5 | 0 |
| 5 | 2 | 1 |
| 6 | 6 | 2 |
| 上記の表と、説明したアルゴリズムを用いるとハッシュ値に対応するLBの転送先のサーバは以下のように変化します。Maglev Hashingの元となるConsistent Hashingとの違いは、転送先のサーバに障害が発生した場合でも負荷を均一化できることです。Consistent Hashingでは転送先のサーバが可能な限り変化しないようすることが可能でした。しかし、このままでは特定のサーバに負荷が集中してダウンしてしまう可能性があります。Google Maglevでは特定の転送先サーバに障害が発生しても、ハッシュ値に対応する転送先サーバが変更する影響を小さくしつつ、負荷の均一化も実現されました。 | ||
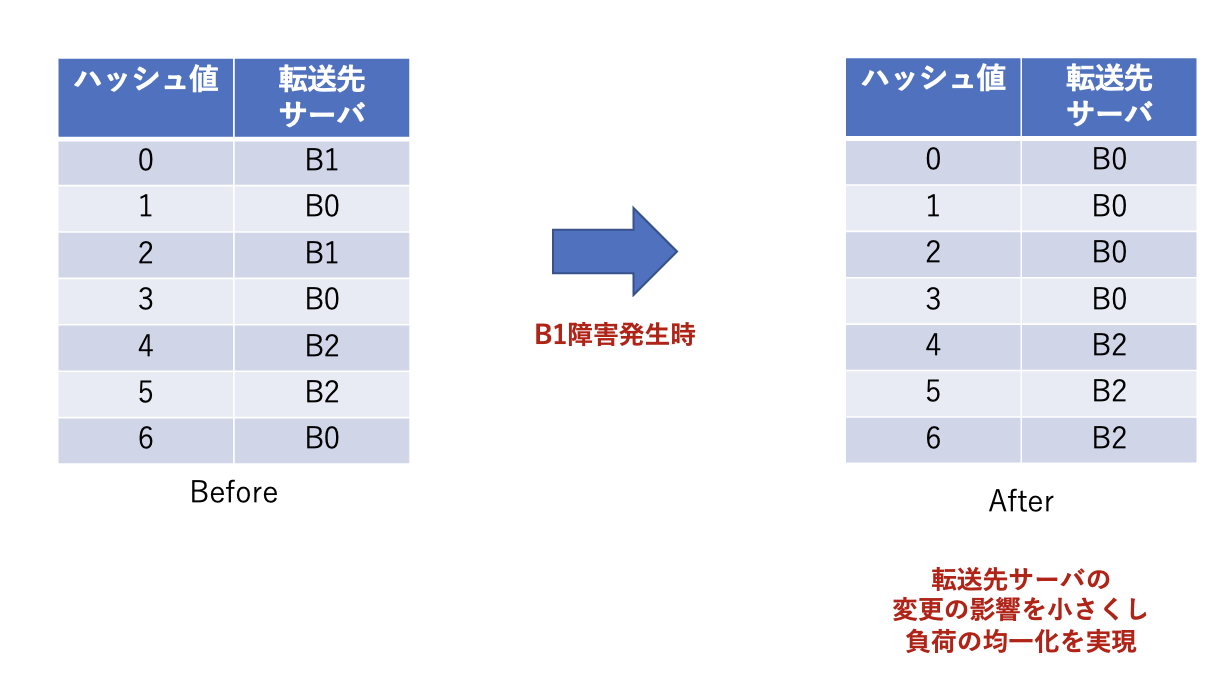 |
Facebook: Katran
Facebookが開発したLBである「Katran」についての概要を説明します。アルゴリズム全体の流れについて、GoogoleのMaglevと大きく異なる訳ではありません。類似している点も多いと考えられます。KatranはL4LBとL7LBの組み合わせによって構成されますが、まずL4LB(shiv部)について以下の図[5]に、処理の流れを説明します。
- クライアントからパケットを受信します
- パケット送信先のVIPが存在するかを確認します(VIP:LBのIPのことを指し、このIPに接続することによってL7LBに接続する機能があるかを②で確認)
- Katran(shiv部)はセッションテーブルを作成する機能を持つ。②でVIP宛のパケットであることを確認後、セッションテーブルを参照して、転送先のサーバは同一になるようセットします。
- セッションテーブルに存在しない、新たなパケットの場合は5tupleを用いてハッシュ値を算出し、転送先サーバを決定します。
- 3, 4で決定したL7LBに転送することを確定します。
- 確定情報に基づき、セッションテーブルを更新します。
- パケットをカプセル化(VIP宛に送信してきましたが、宛先がL7LBであることを教えてあげます。パケットに必要情報を付与してあげることです。)して、L7LBに転送します。
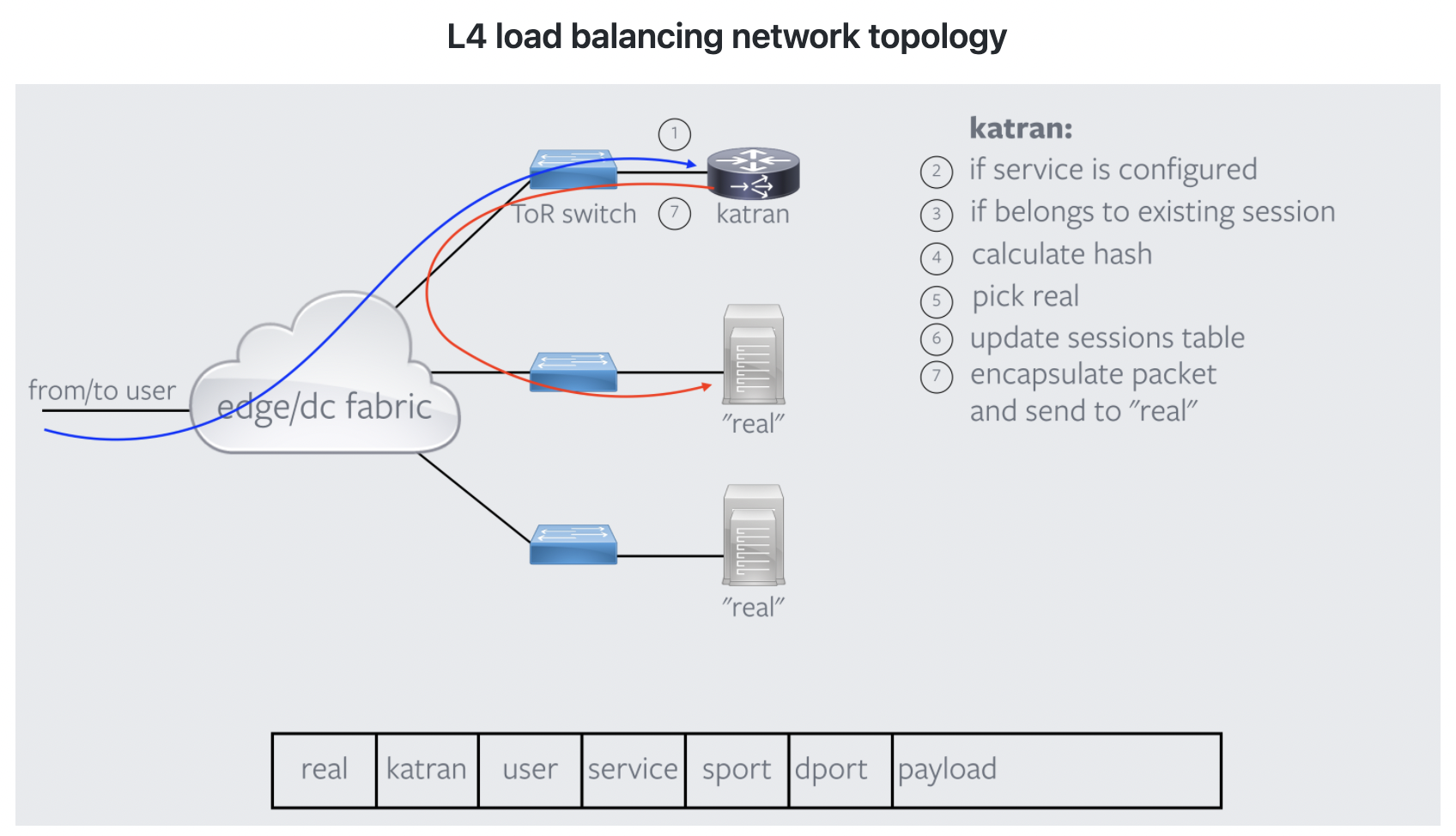
Google Maglevではセッションテーブルを持たずに5tupleを用いてハッシュ値を算出して、転送先サーバを決定していましたね。Facebook Katranではセッションテーブルに情報を持たせることで、ハッシュの計算有無を決定するようです。セッションテーブルを持たせることによるメリットは、ハッシュ値を計算し直す場合に(ハッシュの計算式を変更し、転送先サーバを決定する場合)既存のコネクションが遮断されてしまう問題を防ぐことが可能です。また、KatranのL4LB部分(shiv部)についてはXDPで実装されます。XDPの概要については次に説明します。
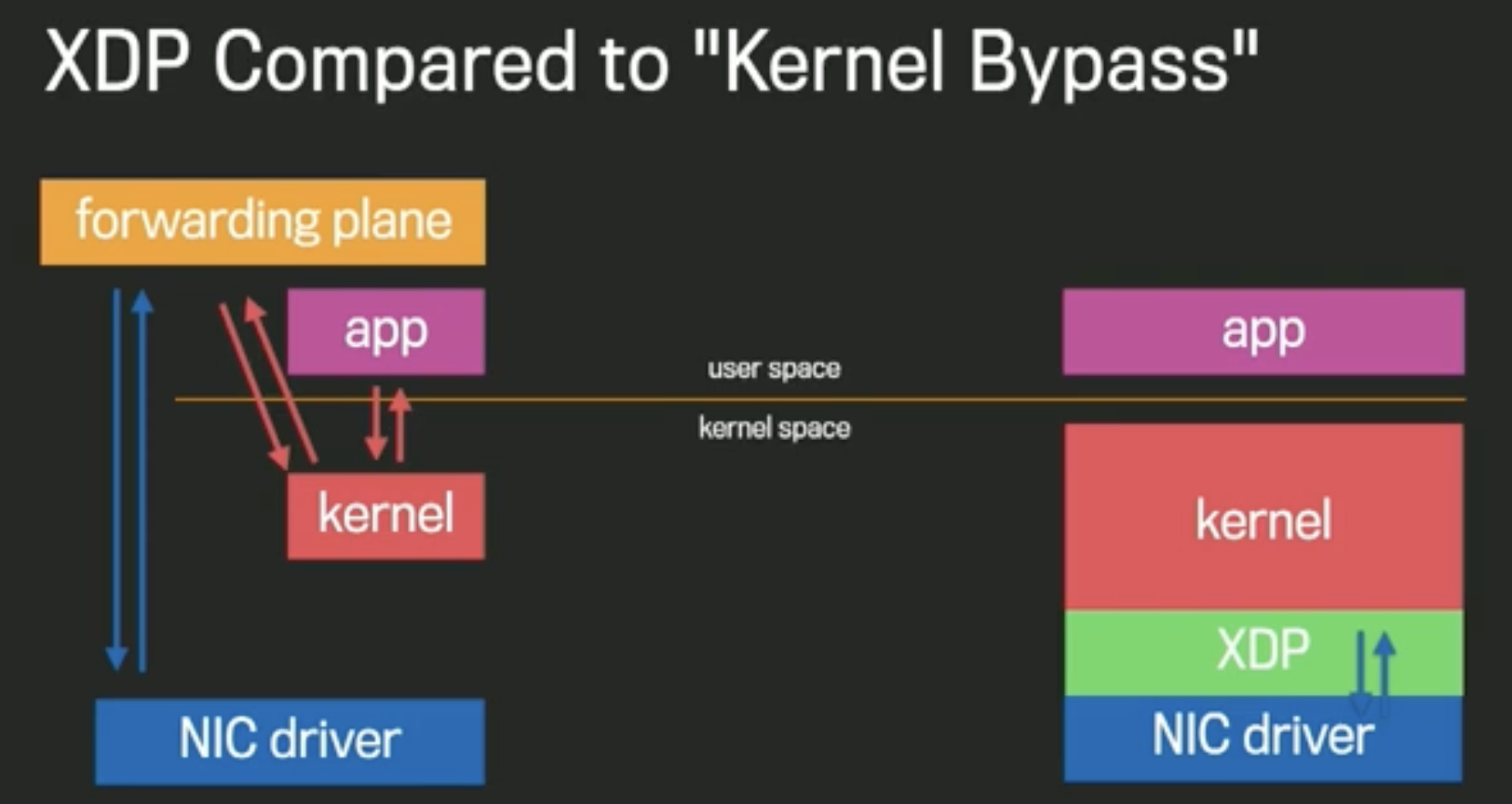
**XDP(eXpress Data Path)とは、Linuxカーネル自身が用意する高速パケット処理基盤のことを指します。以下の図[4]に示すように、XDPはカーネル空間上のNICドライバの最も近い部分に位置し、ユーザ空間で作成したプログラムをカーネル空間上で実行することで転送先サーバにパケットを送信します。**従来では、ユーザ空間上で作成したプログラムからNICを叩いてパケットを転送する必要がありました。ユーザ空間からNICを叩くよりも、同一空間に存在するXDPで叩く方がパケットの転送が高速に実現できるのは一目瞭然ですね。したがって、XDPによって高速にパケットを転送できることが可能になったのです。Katranでは、L4LBをXDP上で実装し、L7LBへパケットを転送します。
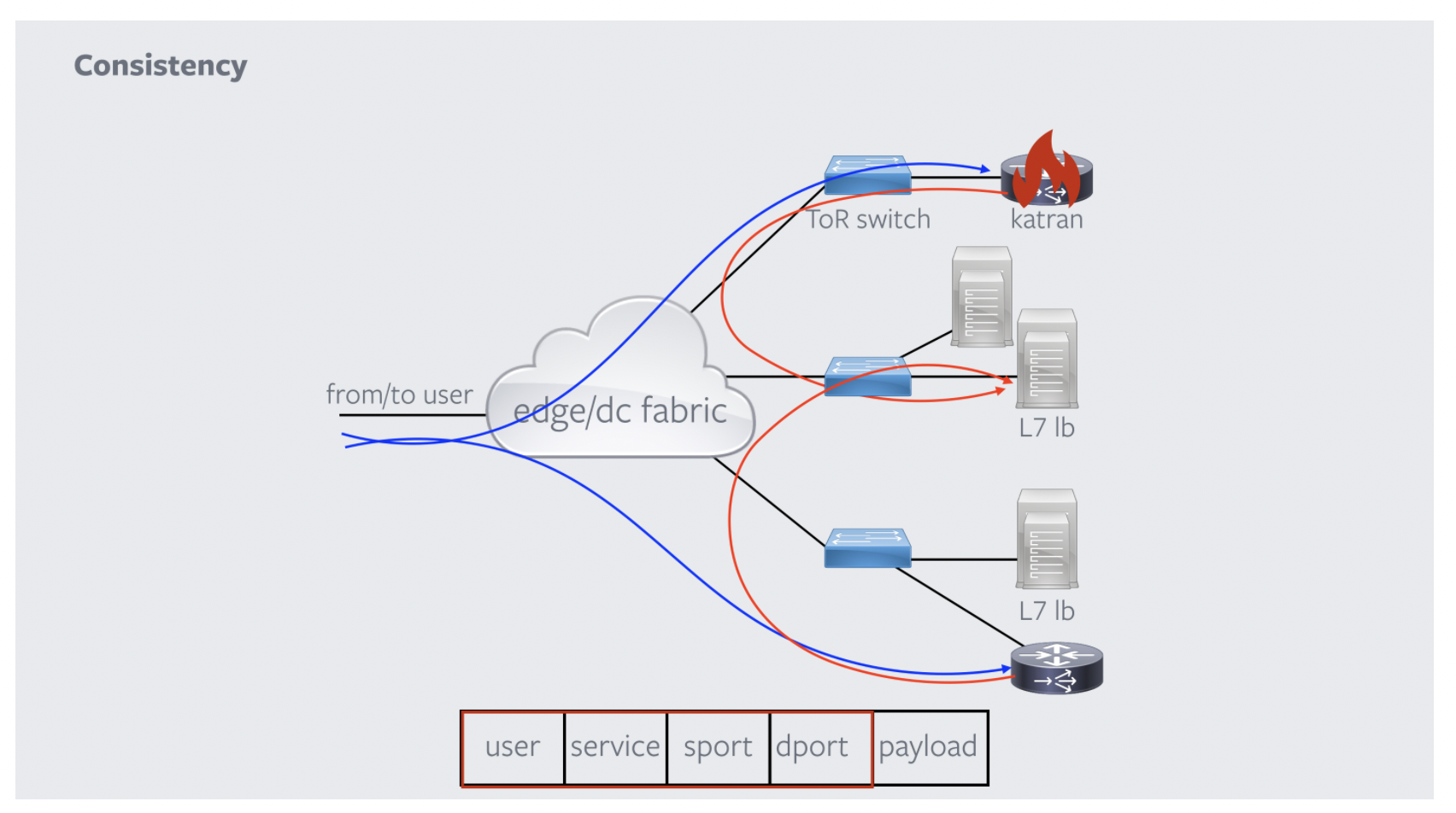
最後に、Katranの障害発生時と全体像について説明します。ここで、どのKatranがクライアントからのパケットの転送を担当したとしても同一のサーバに転送されます。なぜなら5tupleを用いて算出したハッシュ値によって転送先を決定するためです。これは、GoogleのMaglevと同じですね。Katran(shiv部)で障害が発生したとしても、同一クライアントからのパケットは同一サーバに転送されるのです。最後にKatranによってパケットを振り分ける全体の流れを説明します。まず、クライアントからパケットを受信し、Katran(shiv部)がハッシュテーブルの参照、またはハッシュ値を算出してL7LBに転送します。その後、L7LB部分でProxygenというFacebookが公開したC++が記述されているフレームワークを用いてHTTPSを終端(SSL終端)してパケットをサーバへ転送します。L7LBでSSL終端することでクライアントと転送先サーバで暗号化されている通信の内容を確認することができ、内容に応じて複数のサーバにパケットを転送することが可能です。proxygenについて細かな説明は致しませんが、GitHubにコードが存在しますので、興味のある方は参考文献よりご確認ください!
GLB: GitHub’s open source load balancer
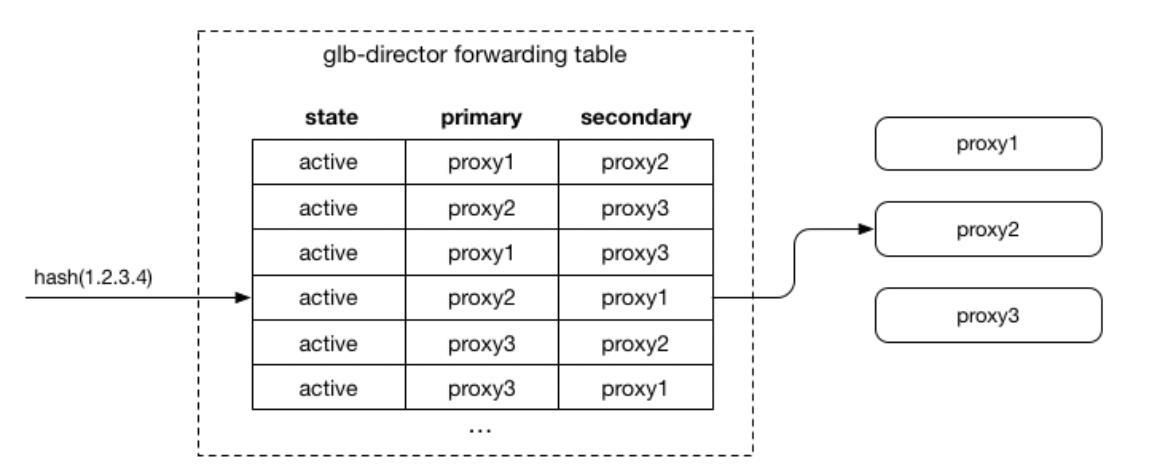
GitHubが開発したLBである「GLB: GitHub’s open source load balancer」の概要を概要を説明します。GLBでは、LBの転送先であるproxyに着目しています。転送先であるproxyは必ずしも使用可能な状態とは限らず、スタンバイによる準備中の場合、パケットを受信できずに破棄してしまう可能性があります。**GLBでは、プライマリとセカンダリのproxyを設定することによって、クライアントのパケットを冗長性を持たせて処理することが可能です。**GLBでは、以下の図[12]に示すようにproxyに対してGLB(LVS)が転送先を決定します。GLBはLinux Virtual Server(LVS)のようなソフトウェアベースのLBです。LVSとはLinuxサーバをLBの機能として動作させるソフトウェアのことです。これは、今までに紹介したLB全てが当てはまりますね。さて、GLBでは、プライマリとセカンダリのproxyを決定するとのことでしたが、この機能が存在しない場合はどうなってしまうのでしょうか。以下の図[12]で緑枠で囲まれた部分に着目してください。LVSまたはproxyに障害が発生し、同時に復旧させた場合を考えます。LVSに障害発生前のプロセスが残ったままの状態であると、復旧直後proxyにパケットを送信します。しかし、proxyが動作している状態であるものの、復旧直後であることからパケットを受信できる準備ができれおらずパケットが破棄されてしまう可能性があるようです。GLBでは、このようなことを防ぐために、図中のglb-directorによって、プライマリproxyにパケットを送り、破棄されたり異常が生じた場合はセカンダリproxyにパケットを送信するようです。
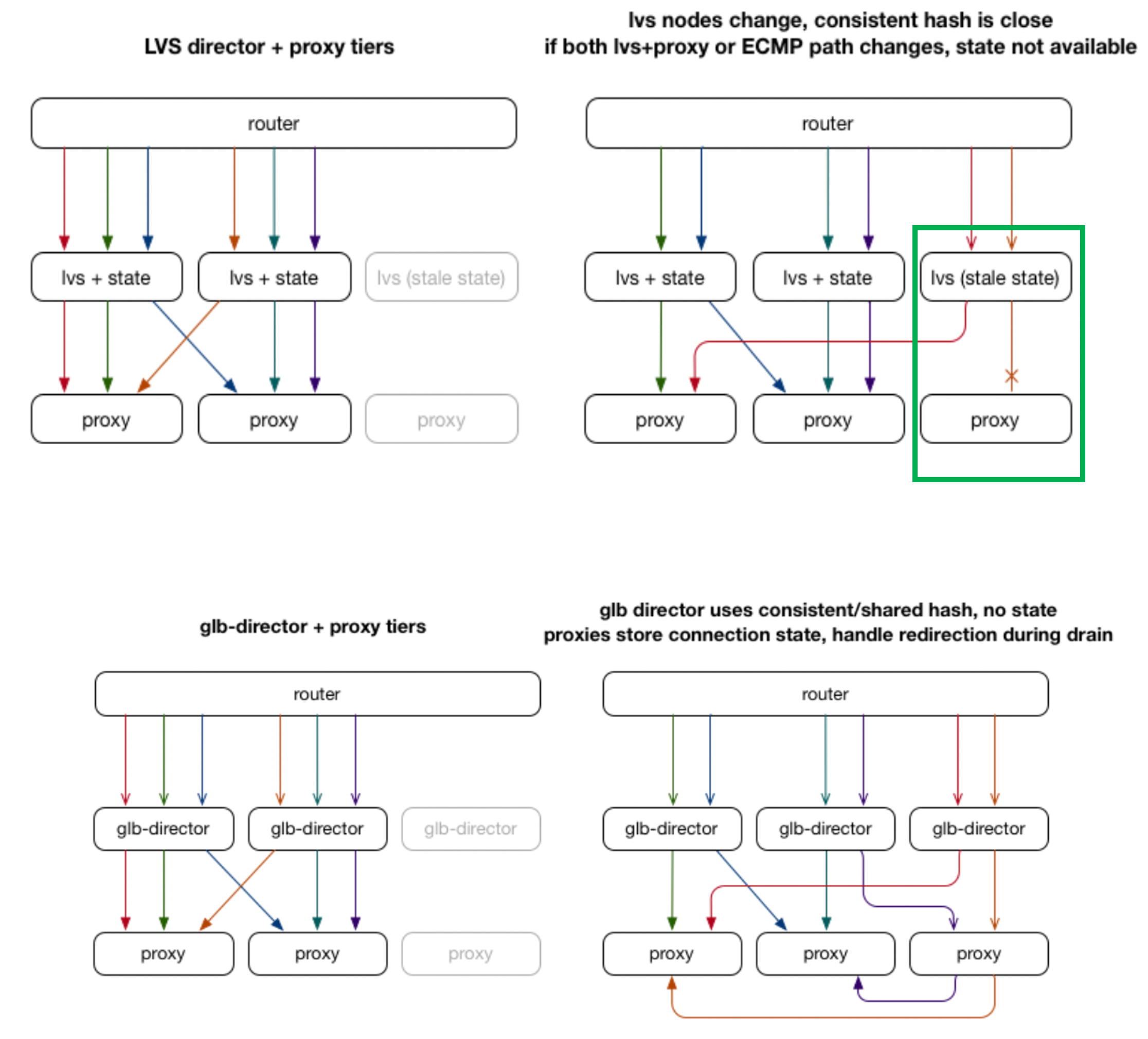
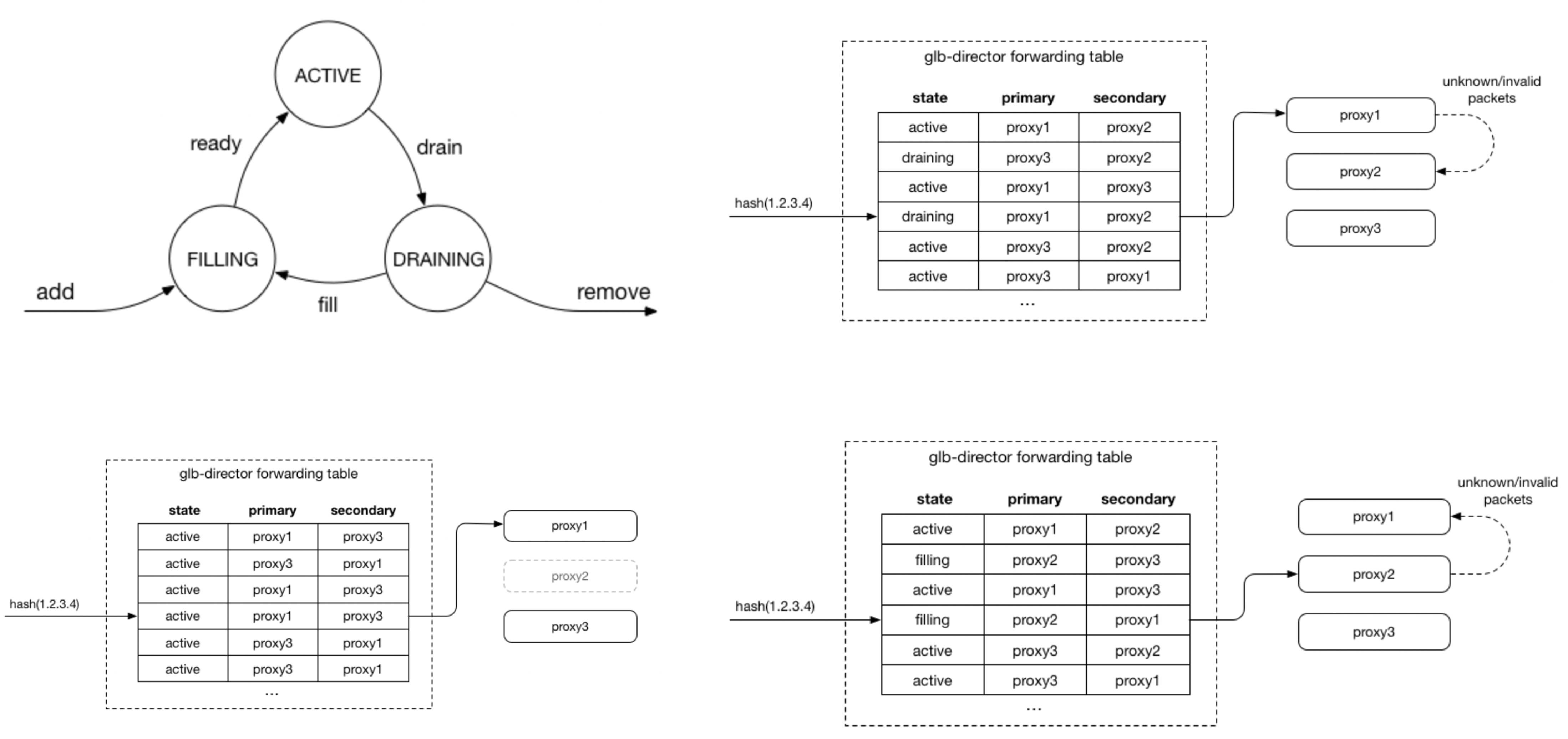
続いて、glb-direcorがプライマリとセカンダリのproxyを決定する方法について説明します。その方法とは、図[12]に示すように、今までたくさん登場してきたハッシュ値の算出によって決定します。プライマリとセカンダリのproxyのセットをハッシュ値で決定することになります。新しいproxyが追加される場合は、一部の行のプライマリをセカンダリにし、新しく追加されるproxyをプライマリにします。一方で、プライマリのproxyが削除される場合は、セカンダリをプライマリに変更し、セカンダリを新たに設定する必要があります。
また、以下の図[12]に示すようにproxyは3つの状態を持ち遷移していきます。ACTIVEは動作可能状態、DRAININGは異常が生じている状態、FILLINGはproxyは動作しているが準備している状態になります。glb-directorでは、ハッシュ値に応じた2つのproxyに加えてプライマリのproxyの状態も保持します。プライマリのproxyがACTIVEの場合はパケットはそのまま送られます。プライマリのproxyの状態がFILLINGまたは、DRAININGの場合はパケットがセカンダリのproxyに送られることになります。GLBでは、このような流れでプライマリとセカンダリのproxyを設定することによって、クライアントのパケットを冗長性を持たせて処理することが可能です。
まとめ
本記事では、LBの基礎から問題点、問題解決のための技術をいくつかの技術について紹介してみました。特にConsistent HashingやMaglev Hashingについてはアルゴリズム自体はシンプルであるものの、上手く負荷分散ができていて面白いですよね。今回紹介したLBに共通していたことは、ハッシュ値を算出して、転送先のサーバを決定していることでした。同一クライアントからのパケットは同一のサーバに転送されること、LB間でのコネクションの同期が事実上実現可能、転送先サーバに障害が発生してもコネクションに対する影響を小さくできる等のメリットは、多くの企業やサービスにとって大きな利点なのかもしれませんね。本記事は、LBの知識が乏しい新入社員なりの視点で記事を紹介したため、分かりにくい説明になってしまったかもしれません。記事の執筆を通じて以前にもLBに興味を持てたと感じております。記事の執筆をきっかけでLBに興味を持ち、分散処理系の技術についても非常に興味深い分野ですので主体的に調査をしてみようと思います。NTTドコモでは、膨大なお客様のデータをリアルタイムで処理する必要があるため、今回紹介した技術は非常に重要になります。1年目で技術力が、まだまだ乏しいので、LBをはじめとする多様な知識を身につけて、NTTドコモのお客様に新価値を提供できる人材になりたいです!!
参考文献
[1] LINEの独自LBaaSを支えるソフトウェアエンジニアリング -日本語版-, LINE, https://www.youtube.com/watch?v=C19dDq--OqA
[2] Maglev: A Fast and Reliable Software Network Load Balancer, Google Inc, https://static.googleusercontent.com/media/research.google.com/ja//pubs/archive/44824.pdf
[3] Consistent Hashing (コンシステントハッシュ法), https://christina04.hatenablog.com/entry/consistent-hashing
[4] Networking @ Scale 2018 - Katran Layer 4 Load Balancing at Facebook Engineering, Facebook, https://www.youtube.com/watch?v=da9Qw7v5qLM&t=145s
[5] facebookincubator/katran: A high performance layer 4 load balancer, https://github.com/facebookincubator/katran
[6] Facebookはレイヤ4ロードバランサをIPVS(LVS)からXDPベースのものに乗り換えつつある, yunazuno.log, https://yunazuno.hatenablog.com/entry/2017/05/10/090410
[7] 【インターンレポート】ネットワークノードのパケット処理の高速化について, LINE, https://engineering.linecorp.com/ja/blog/intern2019-report-infra/
[8] Linuxカーネルの新機能 XDP (eXpress Data Path) を触ってみる, yunazuno.log, https://yunazuno.hatenablog.com/entry/2016/10/11/090245
[9] eXpress Data Path (XDP) の概要とLINEにおける利活用 / Brief summary of XDP and use-case at LINE, LINE, https://speakerdeck.com/yunazuno/brief-summary-of-xdp-and-use-case-at-line?slide=6
[10] facebookの13億ユーザーを支えるロードバランサーの話, stanaka's blog, https://blog.stanaka.org/entry/2015/12/16/130316
[11] Proxygen: Facebook's C++ HTTP Libraries - GitHub, https://github.com/facebook/proxygen
[12] GLB: GitHub’s open source load balancer, Theo Julienne, https://github.blog/2018-08-08-glb-director-open-source-load-balancer/
[13] GitHubがオープンソースのソフトウェアロードバランサー「GLB Director」を公開, Gigazine, https://gigazine.net/news/20180809-github-load-balancing-director/