イントロ
本記事はNTTドコモ R&D Advent Calendar 2021(カレンダー2)の1日目の記事です。
この記事ではあのころのドコモケータイに搭載されていた、T9入力を形態素解析器MeCabを使って再現していきます。
T9入力概要
突然ですが、みなさんはT9入力1という文字入力方式をご存じでしょうか?
T9入力は米国テジック・コミュニケーションズ社が開発した文字列入力方式であり、携帯電話でのテキスト入力を効率的に行う方式として開発されました。
T9入力はそのベースとなったトグル入力(いわゆるケータイ入力)よりも少ない入力回数で単語を入力できます。
例えば、「ドコモ」という単語を入力したい時、トグル入力であれば「た」を5回、「濁点」を1回、「か」を5回、「ま」を5回入力してやっと変換候補に「ドコモ」が表示されます。対してT9入力では「た」「濁点」「か」「ま」を1回ずつ入力することで変換候補に「ドコモ」が表示されます。要は子音(もしくは50音表の行のあ段)を入力することで、そこから想定できる単語を変換候補に表示できる入力方式です。

ちなみにT9入力はもともと英語入力用に開発されましたが、日本でもNECやパナソニックが開発元からライセンスを受け独自に日本語T9に対応したIMEを開発していました。そういったIMEが搭載された端末としてN504iやP901iがドコモから発売されています。2
T9入力は、自分が入社するより前の時代にドコモケータイで一時期活躍していた入力方式ということで、勝手にご縁を感じながらこの記事を書いています。なお、以後特にドコモケータイの話は出てきません。
T9入力の実装
※ここからはあくまで自分が想像するT9の実装です。本家の実装は違うかもしれないことをご了承ください。
ここからT9入力を実装していきます。
T9入力はかな漢字変換の表層系を書き換えるだけで、かな漢字変換と全く同じスキームで再現することができます。
かな漢字変換
T9入力について考える前に日本語かな漢字変換を考えます。現在かな漢字変換で最も広く使われている方式は形態素解析によるかな漢字変換です。
具体的な例を示します。
例として「うつくしいはな」を変換する場合、この文の構成要素としてありえる形態素をかな漢字変換辞書からすべて列挙します。かな漢字変換が完了するまではどこが分節の切れ目かわからないため、とにかくあり得るものをすべて列挙します。例の場合では、0文字目から始まる「卯」「打つ」「美しい」、1文字目から始まる「津」「尽くし」……が列挙されます。
これを文頭から文末につながるグラフ構造に落とし込むと図1のようになります。
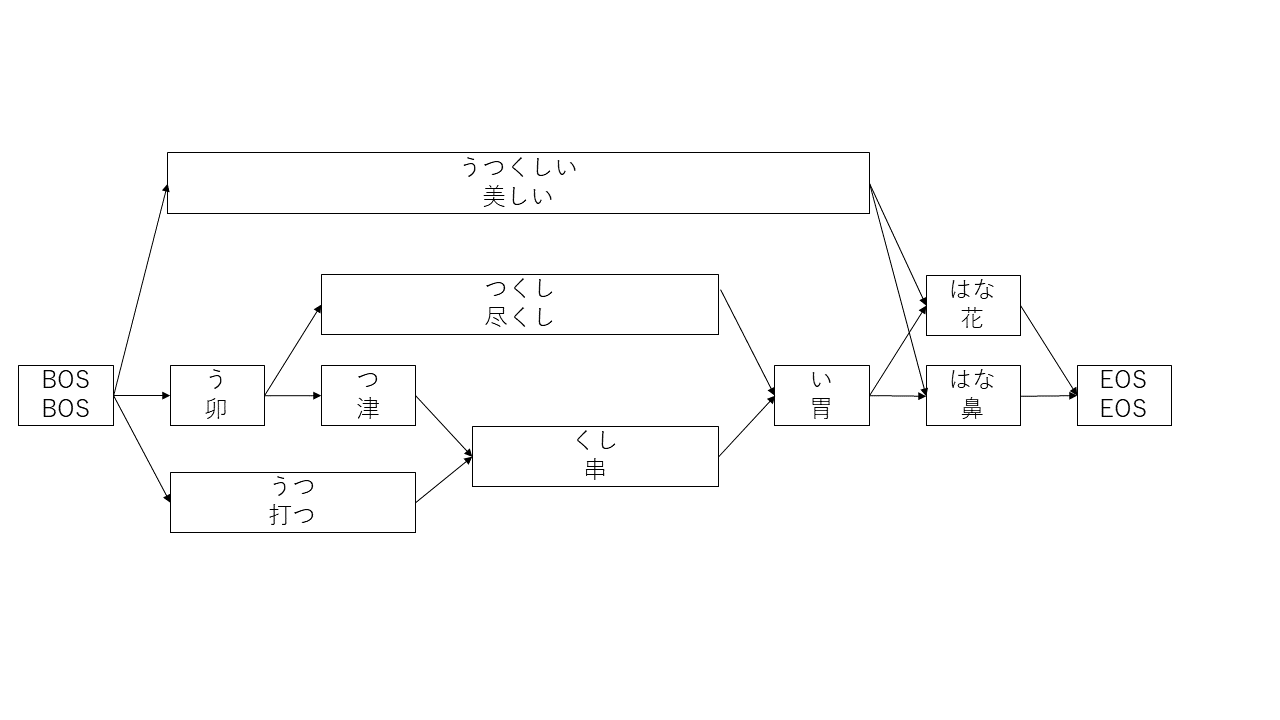
図1.かな漢字変換用のラティス
(※図1は列挙できる形態素をかなり省略したイメージです)
BOS(文頭)からEOS(文末)までのパスが複数考えられるグラフを作ることができました。この有向非巡回グラフのことをNLPでは特にラティスと呼んだりします。
かな漢字変換では、各形態素が文章に出現しやすさを表す生起コスト、品詞同士の接続の自然さを表す連接コストを使い、文頭から文末に向かうまでに最小のコストで通れるパスを見つけることで変換結果を出力します。
図1内で生起コスト、連接コストは省略されています。
生起コストについて例をあげると3、「花」の生起コストは5,702であり、「鼻」の生起コストは6,425です。どちらのハナでも変換できる場合には、文章中に出現しやすい(コストのかからない)「花」が優先されることを示しています。
また、連接コストについて例を上げると、「美しい-花(形容詞-名詞)」の連接コストは193であり、「尽くし/胃(動詞・連用形-名詞)」の連接コストは1,473です。これは「形容詞-名詞」の接続の方が「動詞・連用形-名詞」よりも自然な接続であることを示します。
このようにして図1のBOSからEOSまでに至る生起コストと連接コストを足し込むと、「美しい/花」のコスト総和は12,382、「打つ串胃鼻」のコスト総和は33,241です。
すべての取りうるパスのコストを計算し、コストが最小になる「美しい/花」がベストの解として出力されます。4
このような処理を経ることでかな漢字変換を実現することができます。5
T9入力
先ほどのかな漢字変換ではラティスを作るとき、文の構成要素としてありえる形態素を列挙しました。
列挙の際には読み(かなだけの文字列)と変換結果(漢字を含む文字列)の対応で作りましたが、なにも日本語として厳密に対応していないといけないわけではありません。例えば「せんたっき-洗濯機」や「くりすます-十二月二十四日」という読みと変換結果が正確な日本語として対応していない例を登録しても問題はないということです。これは、読みが正確に対応しているかどうかと、ラティスでコストが最小になるパスを発見する処理は全く無関係であり、処理自体は問題なく実行できるからです。
このように日本語を解析する必要のあるかな漢字変換(形態素解析)にも関わらず、厳密な日本語でなくともアルゴリズム的な処理を問題なく実行できることを指して「形態素解析器は日本語を知らない」などと言ったりします。
話が少々脇にそれましたが、先程の話をT9入力に応用します。
すなわち、変換結果として出したい文字列の変換前の文字を、よみがなでなくT9の入力文字列で辞書に登録することでT9入力を実現することができます。例えば「だかま→ドコモ」「かわなたは→こんにちは」「あたかさあ→美しい」のような形です。
先程の「うつくしいはな」の変換の例を再度考えます。T9入力では「美しい花」と入力したい場合「あたかさあはな」の入力を変換します。その時に構築されるラティスは図2のようになります。
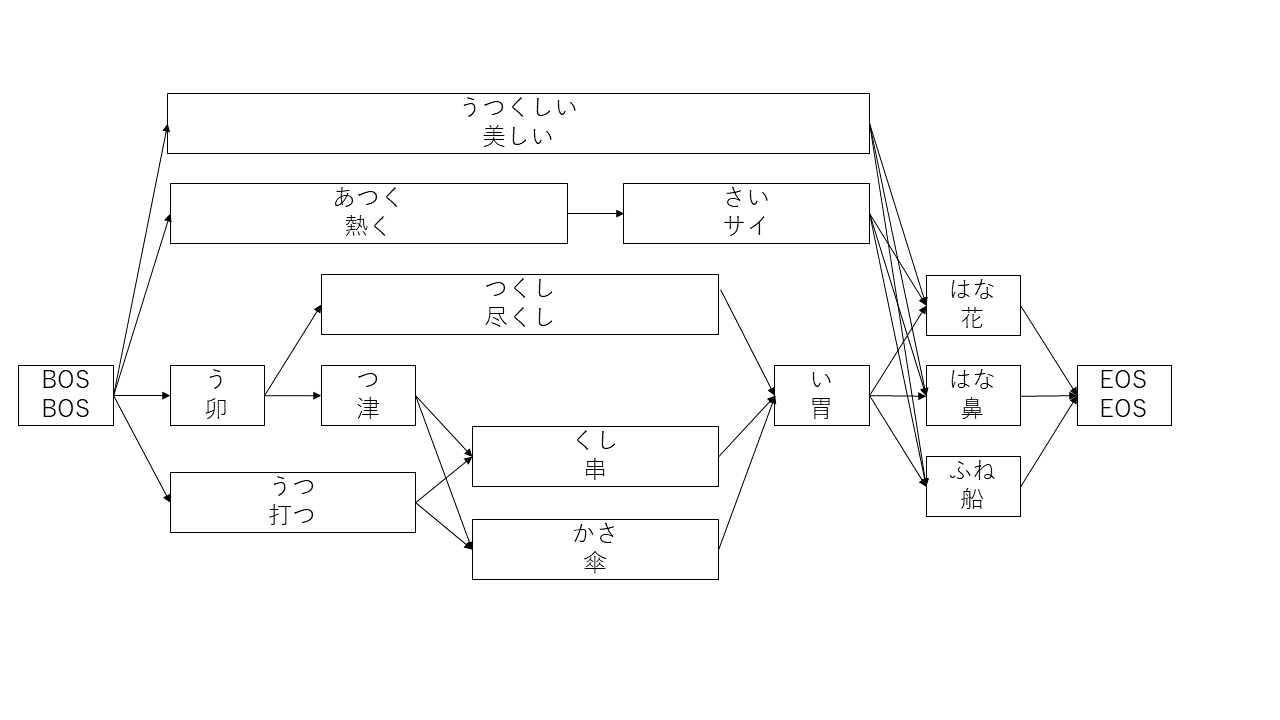
図2.T9入力のラティス
図2では図1と比べて構成する形態素の量が増えました。T9入力では1文字につき約5倍の変換候補が考えられるためです。それでも変換で実行される処理は通常のかな漢字変換となんら変わりありません。それぞれの形態素の生起コストと隣接コストから「美しい花」のコスト総和は12,382, 「熱くサイ船」のコスト総和は20,481と計算することができます。
その結果コストが最小になる「美しい/花」をベストの解として出力できます。
T9入力もかな漢字変換と全く同じスキームで実現できることを確認できました。
MeCabで実現する
では実際に上に挙げたT9入力の実装を実現するためにはどうすればよいでしょうか?
まず簡単に思いつく実現方法は、既存のかな漢字変換器に単語登録でT9の辞書を追加するやり方です。
しかし、既存のかな漢字変換器への単語登録は内部的に保持している生起コストや品詞などのカスタマイズ性にとぼしい問題があります。また、変換器が内部に持つシステム辞書を無効化する手立てがないため、システム辞書に低いコストで登録された形態素が優先的に変換結果に出てしまう可能性があります。
こういった問題をクリアするために、今回は表題のもう1つのテーマである形態素解析器MeCabを使ってT9入力によるかな漢字変換を実現します。散々前フリをしていましたとおり、かな漢字変換器は形態素解析器を用いることで実現することができます。そして、MeCabは形態素解析器であり、システム内部には辞書の類いを一切持っていません。外部の辞書から入力分に対応できる単語をlookupし、ラティスを組んで最短コストのパスを探すということのみかMeCabの行える仕事です。すなわち、MeCabにT9入力に対応した辞書を与えて解析してもらえれば、T9入力によるかな漢字変換を実現できます。
というわけでMeCabでT9入力を再現してみましょう。
辞書を作成する
まずT9入力に必要な辞書を作成します。
今回は簡単のため、既存のかな漢字変換器であるmecab-skkservに付属のIPA辞書を元にして辞書を作成します。
(ここからの手順はnkfコマンドとMeCabのセットアップがすでに完了している前提で進めます)
curl -O http://chasen.org/~taku/software/mecab-skkserv/mecab-skkserv-0.03.tar.gz
tar zxvf mecab-skkserv-0.03.tar.gz
cd mecab-skkserv-0.03/
mecab-skkservの辞書ファイルdic.csvは文字コードeuc-jpで作られています。
このファイルをpythonのeuc_jpコーデックで読ませようとすると、なぜかUnicodeDecodeErrorで落ちてしまうため、事前にnkfでutf-8に変換しておきます。
nkf -w --overwrite dic.csv
ここらで試しにどんな単語がdic.csvに登録されているか確認してみましょう。
$ head -179732 dic.csv | tail
いぬ,670,1250,2514,犬
けん,683,1263,2835,犬
いぬかき,670,1250,4000,犬かき
いぬぞり,670,1250,4000,犬ぞり
いぬがうら,678,1258,3384,犬ケ浦
いぬがたけ,673,1253,2923,犬ケ岳
いぬがくびざき,673,1253,2923,犬ケ首崎
いぬがじょうやま,673,1253,2923,犬ケ丈山
いぬがじょーやま,673,1253,2923,犬ケ丈山
いぬがさき,673,1253,2923,犬ケ岬
登録エントリは左から順に表層系、左文脈id、右文脈id、生起コスト、変換結果となっています。
左文脈idと右文脈idは連接コストの計算に使うために必要な情報です。図1、2のラティスを構成するために必要なミニマムな情報が辞書に登録されていることがよく分かるかと思います。
また表層系は言い換えればかな漢字変換を使う際の変換前文字列です。ということでこの部分をT9入力の入力文の形に変換して辞書に登録してT9入力を実現します。1行目の「犬」は「あな」と登録してやればよいでしょう。
変換に使うスクリプトを以下に示します。
if __name__ == '__main__':
dic = {}
with open("table") as f:
for line in f:
key, kana_all = line.rstrip().split(" ")
dic.update({kana: key for kana in kana_all})
tr = str.maketrans(dic)
with open("dic.csv") as f, open("t9.csv", "w") as out:
for line in tqdm(list(f)):
rows = line.rstrip().split(',')
if len(rows) != 5:
continue
rows[0] = rows[0].translate(tr)
print(','.join(rows), file=out)
スクリプト中で使う外部ファイルtableの内容は以下の通りです。T9入力の子音母音対応を記載しています。
あ あいうえおぁぃぅぇぉ
か かきくけこ
が がぎぐげご
さ さしすせそ
ざ ざじずぜぞ
た たちつてとっ
だ だぢづでど
な なにぬねの
は はひふふへほ
ば ばびぶべぼ
ぱ ぱぴぷぺぽ
ま まみむめも
や やゆよゃゅょ
ら らりるれろ
わ わをん
ではconvert.pyを実行して、T9入力用の辞書を作成しましょう。特にエラーなくスクリプトが終了すれば、カレントディレクトリにt9.csvが出力されます。
python convert.py
最後にMeCabで利用できるようcsvファイルをビルドすれば辞書の完成です。
(mecab-skkserv-0.03は少し古いMeCab用の辞書構成になっており、dicrcにcost-factorの記載がありません。そのため下に示すようにechoでdicrcへの追記も行ってください。)
echo "cost-factor = 800" >> dicrc
`mecab-config --libexecdir`/mecab-dict-index -f utf-8 -c utf-8
なおコマンドオプションの-c utf8はセットアップ済みMeCabが利用する文字コードを指定するオプションです。utf-8以外でMeCabをセットアップしている場合はここの部分を書き換えて辞書をビルドしてください。
実行する
それでは正しく変換できるか実行してみましょう。以下のコマンドでmecabを起動します。
mecab -d . -F "%f[0]" -E "\n"
まずは散々例に出していた「美しい花」、「あたかさあはな」と入力して変換できるでしょうか。
$ mecab -d . -F "%f[0]" -E "\n"
あたかさあはな
美しい花
うまく変換できましたね。
他にかな漢字変換のHello, world!である「私の名前は中野です(わたさななまあはなかなださ)」はうまく変換できるでしょうか?
$ mecab -d . -F "%f[0]" -E "\n"
わたさななまあはなかなださ
私の名前はなきのです
こちらはうまく変換できませんでした。
「なき/の」の品詞がなにか見えていないのでなぜこの変換結果が優先されるかは分かりません。
T9入力では取りうる変換結果の組み合わせが大きく($O(5^{|L|})$で) 増えてしまう ため、変換の性能が多少犠牲になってしまうのはある種仕方ない点でもあります。
まとめ
本記事では「かな漢字変換」は「形態素解析」のスキームで実現でき、「T9入力」も「かな漢字変換」と同じスキームで実現できるため、「T9入力」は「形態素解析」で実現できるという三段論法を長々説明した後、形態素解析器MeCabで実際にT9入力を再現する方法を紹介しました。
記事内ではかな漢字変換と言いながらも、1-bestの変換結果を出す方法のみに注力しました。MeCabのN-bestを使えばもう少し色々な変換結果が見えて面白いかもしれません。
また、本記事の発展としては以下のようなものが考えられます
- かな漢字変換の枠を超えてIMEとしての実現を考える(MeCabの制約付き解析など利用)
- 入力のユーザインタフェースの方も作り込む(今はひらがなの文字列を普通にローマ字入力で入れないといけない)
- neologd辞書でリッチな変換を実現する
- 既存辞書を用いず、辞書の学習から行う
かな漢字変換周りの実現は色々なアイディアが湧いてきてとてもおもしろいですね。
皆さんもぜひ思いついたアイディアを手を動かして実現してみてください。
参考文献
- [書籍] 日本語入力を支える技術 ~変わり続けるコンピュータと言葉の世界 (WEB+DB PRESS plus)
- [書籍] 形態素解析の理論と実装 (実践・自然言語処理シリーズ)
- https://ja.wikipedia.org/wiki/T9
- https://www.itmedia.co.jp/mobile/0102/06/t9.html
-
https://k-tai.watch.impress.co.jp/cda/article/mobile_catchup/9965.html ↩
-
例示した生起コスト、連接コストは全てmecab-skkserv-0.03付属のIPA辞書のものです ↩
-
実際にはコストが最小となるパスを求めるのに、すべてのパスのスコアを計算する必要はありません。動的計画法の一種であるビタビアルゴリズムを用いることで、高速にベストなパスを求めることができます。詳しくは参考文献の書籍をご覧ください。 ↩
-
ここで説明した2-gramマルコフモデルもあくまで数あるかな漢字変換手法の1つであり全てではありません。例としてMS-IMEでは上位の変換結果を言語モデルで再度評価した上で最終的な提示候補を決定しているそうです。 ↩