ロードバランサをロードバランスしようぜ!
この記事はロードバランサをロードバランスしてスケールアウトしてメタロードバランサにすることでウハウハしようってものです(意味不明)。
いや、まじめに説明します。。この記事を読まれている方の中にはロードバランサを運用している方も多いと思います。ご存知の通り、ロードバランサってサーバに対して負荷分散することが目的の装置ですが、そのロードバランサ自体だって性能限界はありますし、ある程度のトラフィック量になってきたらロードバランサだってスケールアウトしたくなりますよね。しかもスケールアウトする(一台当たりの性能を上げる「スケールアップ」ではなく、台数を並べて性能を上げる構成方法のこと)ならスタンバイ機なんて考え方もやめて全部アクトとして使いたくなりますよね?この記事ではドコモで導入したスケールアウト方式のご紹介と、その他世の中の巨人たちがどんなスケールアウト方式を導入してきたのかをざっと俯瞰してみようと思います。
自己紹介
何者?
改めてこの記事をお読みいただきありがとうございます。ドコモ サービスデザイン部でspモードのネットワークを担当している川谷です。「spモードって何?」って言われちゃうと悲しくなりますが。。
spモードって何?
実際にご存じない方も多くいらっしゃるので簡単にご紹介すると、スマホ向けのインターネット接続サービスです。え?まだわかりづらい?うむむ。。。プロバイダ、というとわかるかも。皆さんも自宅にインターネット回線を引いている方は、回線(ドコモ光とか)とプロバイダ(ドコモnetとかOCNとか)の両方を契約していますよね?スマートフォンも無線を使う回線の契約(データ通信プラン)とISP契約が存在していて、それがspモードというものです。今、ドコモのスマホ(iPhone含む)をお使いの多くの方々にご利用いただいているサービスで、ユーザは4,000万を超えています(日本一!)。
トラフィックの読めないこんな時代だから
iモード時代とは違うのだよ
iモード時代のモデルはよく垂直統合モデルだったといわれています。これは要するに、ドコモのような携帯会社が端末~ネットワーク~コンテンツまである程度把握していて、今後どんなサービスが増えるのか、新しい端末が出たときにどんな通信がされるのか、といったものを読むことができていました。
時代は変わってiモードケータイがスマホになり、SNSをはじめとする数多くのOTT(Over The Top)事業者が現れ、iモード時代のように今後のトラフィック傾向が読めなくなっています。例えば、とあるゲーム大流行したり、あるサービスがドカンと当たるだけで大きくトラフィックの傾向が変わっちゃったり、なんてことが当たり前に起こるのが今の携帯ネットワークなのです。
こんな時代だから、ある日急にトラフィックが増えたりした場合にはより性能の高い新規機種を採用して検証してリプレースして。。。なんてことはやってられず、性能が足りなくなったらすでに採用していて検証済みの機器を横にもう一台足すことで対応(スケールアウト)したくなるわけです。
なんでロードバランサだけ?
トラフィックが読めなくて困るのってこの記事で取り上げているロードバランサだけの問題じゃないんじゃないの?って思われたあなた、鋭い!先の読めないトラフィックに影響を受ける機器は当然ロードバランサ以外にもいます。ただ、全部が全部ではないけどおおむねやり方が決まっていて、それで何とか対処しているって感じですね。
| 対象機器 | 性能が足りない時の対処 |
|---|---|
| サーバ | 横に並べれば、ロードバランサが負荷分散してくれる。 |
| ストレージ | 容量はとりあえず玉(ディスク)を追加していく。筐体がおなか一杯になってしまった場合は筐体ごとスケールアウト。負荷分散は、簡単じゃない場合もあるけど基本的にアクセスされるデータを筐体や玉単位で分散するようにして何とか頑張っている。 |
| スイッチ/ルータ | シャーシ型など巨大なものをスケールアップしていくこともできるし、スイッチ/ルータは基本的に通信経路でしかないので、経路を分ければスケールアウトも可能 |
| スイッチ以外のL2機器/L1機器 | IPSやDPIなどなど。これらはLink AggregationやPort Channelで複数のケーブルを束ねて、そのケーブルの中間に挟み込むことでスケールアウトができる。ただ、その機器がステートフル(後述)の場合にはもう一工夫必要なんですが、本題ではないのでこの記事では省略。。 |
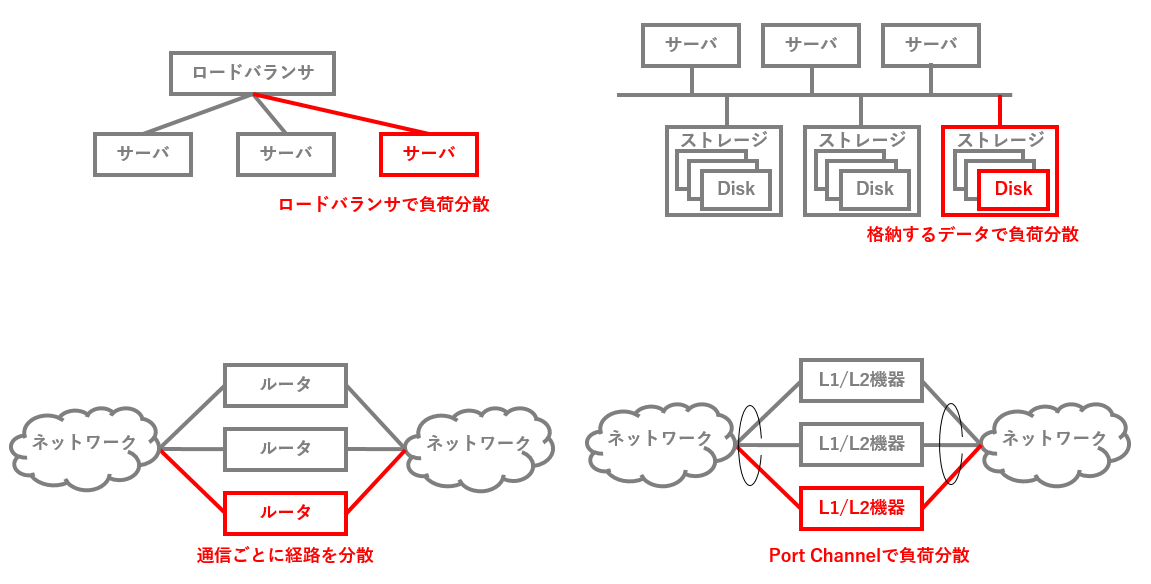
一方、ロードバランサはなぜ上の図表のようにうまくいかないのか。次にその話を書いていきます。
ロードバランサのスケールアウトは難しい!
ステートフルって?
わざわざこの記事を執筆している理由ですが、ロードバランサのスケールアウトは難しいんです。一番の理由は、ロードバランサはステートフルだからです。大事なことなので赤字にしましたw
ステートフルってどういうこと?というと、通信の要求と応答が同じ機器(ロードバランサ)を通らなければならないことを意味しています。ネットワークを流れる多くの通信は要求とそれに対する応答があります。例えばこのQiitaの記事を見るときは、「このURLの記事のデータをおくれ!」って要求するとそれに対する応答が戻ってきて、結果的にこの記事を読んでいる読者のパソコンに記事が表示されます。図示するとこんな感じ。赤い線が要求、青い線が応答を表しています。

なんでロードバランサはステートフルなの?
理由はいくつかありますが、spモードのロードバランサがステートフルになっている一番の理由は公開鍵暗号方式の暗号化/復号化をロードバランサで行っているからです。公開鍵暗号方式についてはこの記事の本題から外れるので細かくは書きませんが、要するに公開鍵暗号方式では一時的な暗号鍵(ephemeral key)を通信相手同士で共有するのですがその鍵をあるロードバランサとスマホの間で共有した後に、他のロードバランサ経由で通信するとそのロードバランサは同じ鍵を持っていないので暗号化/復号化ができない、というのが理由です。公開鍵暗号方式について詳しく知りたい方はWikipediaのディッフィー・ヘルマン鍵交換の記事[1]などを読んでくださいませ。
なんでステートフルだと難しいの?
ロードバランサがステートフルだとスケールアウトが難しい理由を簡単に説明します。ステートフルとは、通信の要求と応答が同じ機器を通らなければならないこと、と説明しました。例えば下の図を見てください。

赤い線の矢印が要求の通信です。図では2台のロードバランサを並べていますが、例として要求の通信が左のロードバランサを経由した場合を図示しています。このように要求の通信を複数のロードバランサにいい感じで負荷分散する方法はいくつかありますが、主なものとしてはDNSラウンドロビン[2]やper-flow ECMP[3]があります。これらも本題ではないのと紙面の都合上説明を省略しますが、興味のある方はググって検索エンジンやWikipedia等で探してみてください。
さて問題は応答の通信です。要求の通信はDNSラウンドロビンやper-flow ECMPでうまく負荷分散できたとして、応答の通信をどうやったら要求通信と同じロードバランサ(左のロードバランサ)に返せるでしょうか。例えば図の青い線のように要求と異なる右のロードバランサに応答を返してしまうと、ロードバランサはステートフルなため通信は成立しません。応答を返すのはサーバですが、サーバは要求の通信がどのロードバランサから送られてきたのかを知りません。サーバあくまでも端末のIPアドレスを宛先として、ルーティングテーブルに従って応答パケットを返すだけです。なので何らか要求通信が経由したロードバランサに応答を返す工夫が必要になります。
ポイントをまとめると、以下の2点が難しさを生んでいるポイントです。
- ロードバランサはステートフルなので要求の通信と応答の通信が同じロードバランサを通さなければならない
- サーバはどのロードバランサ経由で要求の通信が届いたのか知らないので、端末のIPアドレスを宛先としたルーティングになる(どれか一つ固定されたのロードバランサに応答を返してしまう)
以降は、これまで巨人たちがどのような工夫でこの問題を潜り抜けて来たのか、その中でドコモがspモードで採用した方式についての解説をしていきます。
ロードバランサのスケールアウト方式
前述のとおり、ロードバランサはステートフルなのでどうやって要求と応答を同じロードバランサを通すかという点です。これに対して巨人たちは大きく2つのアプローチをとってきました。それは
- ロードバランサをステートレスにしてしまえ!
- 何らかの方法で要求通信と同じロードバランサに応答を返せ!
のいずれかです。ドコモがspモードで採用した方法は後者です。巨人たちの多くは(筆者の川谷が調べた限り)前者を採用してきました。順に解説します。
ロードバランサをステートレスにすりゃいいんじゃね?
ロードバランサのスケールアウトが難しい理由の一つが、ロードバランサがステートフルであるということを書きました。じゃあ、トンデモな考え方として「ステートレスにしてしまえばいいやん」というものです。これはGoogleやFacebookなどでも採用されているようですが[4]、基本的な方法はDirect Server Return(DSR)[5]と呼ばれるものです。
DSRはその名の通り、サーバから端末に直接応答を返してしまおうというもの。この手法ではロードバランサはもはやステートレスなので、そもそも応答をロードバランサ経由で返す必要はなく、ロードバランサをバイパスして直接応答を返す構成が採用されています。

DSRではロードバランサはステートレスなので要求を受け付けたロードバランサではなく直接端末に応答を返せばよく、前述の問題はなくなります。GoogleのMagrev[6]なんかが有名ですね。ただしこの方式もバラ色ではありません。そもそもロードバランサをステートフルにしたくなる理由の一つにロードバランサでの暗号化/復号化がありました。最近のロードバランサは暗号化のための専用チップを積んでおり、高速に暗号化/復号化が可能ですが、DSRではこの恩恵が受けられず、サーバで暗号化/復号化を行わなければならなくなります。それに加え、例えばIPS/IDSのようなセキュリティ装置をロードバランサとサーバの間に配置して悪意のある通信からサーバを守る、みたいなことができなくなります。なぜならDSRではサーバが暗号化/復号化を行うことになるため、ロードバランサとサーバの間の通信は暗号化されたまま。間にはさんだセキュリティ装置で通信の内容が悪意のあるものなのか判定できなくなってしまうからです。
何とか要求と同じロードバランサに応答を返せないかあがいてみる
では、ロードバランサをステートフルなまま活用しつつ要求が通過したロードバランサと同じロードバランサに応答を返す方法はないでしょうか。ここで2つアイデアがあります。それが次の2つです。
- ロードバランサとサーバを括り付ける方法
- Source IP NATをする方法
ロードバランサとサーバを括り付ける
前者はもともとspモードで採用していた方法です。1台のサーバの応答の返却先ロードバランサが2つ以上あるからどのロードバランサに応答を返せばよいのか困ることになります。そこで、ロードバランサとサーバの関係を1:Nにして(DSRやspモードで採用したSSRではN:M)、サーバから見ると応答を返却するロードバランサを1つに固定してしまいます(下図左)。これで応答を返却するロードバランサを特定する課題は解決しました。ただこの場合の問題として、ロードバランサを増設/減設するたびにサーバのリバランスが必要になってしまいます。図で言うと、あとから一番右のロードバランサを追加した場合、このロードバランサに対応するサーバが居ないためサーバを増設するなり、すでに並んでいる4台のサーバを何台かこちらのロードバランサに回さなければならなくなります。実際にはサーバの台数はロードバランサの台数よりずっと多いので、せっかくロードバランサが簡単にスケールアウトできるようになってもこれでは意味がありません。
Source IP NATする
もう一つ、私が以前一緒に研究していた同僚が思いついたんですがロードバランサでSourec IP NATする、という方法があります。(下図右)。なぜこれで解決するかというと、サーバからすると要求を受け付けた際の送信元IPアドレスがロードバランサごとに異なるので、応答を返すときにはそのIPアドレスにルーティングすることが可能となるからです。下図で言うと、左右のロードバランサで異なるIPアドレス(IP1とIP2)にSource IP NATを行うため、要求を受信したサーバはそのIPアドレスに応答を返せばよい、ということになります。この方法はデメリットは少ないですが、送信元IPアドレスが書き変わってしまっているため、送信元IPアドレスを用いたセキュリティ対策や、送信元IPアドレスを活用した認証が行えないなどのデメリットがあります。

ついに勝利の瞬間が!Statefule Server Routing(SSR)の発案
これまで続けてきた、ステートフルなロードバランサに対してどうやって要求と応答を同じロードバランサに返すか、という戦いにおいて、我々にようやく勝利が訪れます。(ぱぁぁぁぁ
前述のとおり、要求を受け付けたサーバは要求のパケットがどのロードバランサを経由したのか知らず、端末のIPアドレスを宛先としたルーティングによって応答を返却します。これを何とか要求パケットの中から要求の経由したロードバランサの痕跡を見つけだし覚えておき、応答をそのロードバランサにルーティングできたら。。
痕跡あるやん!送信元MACアドレスがあるやん!
ロードバランサから要求パケットが送られてくる際、そのパケットのL2ヘッダの送信元MACアドレスにはロードバランサのMACアドレスがセットされます(ロードバランサがL3で動作している場合)。そのMACアドレスを覚えておいて、応答をそのMACアドレス宛に送る(ルーティング)することで解決できることに気づきました。
じゃあ、どうやって送信元MACアドレスを覚えておいて、応答をそのMACアドレスにルーティングするのか。。?一般的なOSではそんなルーティングはしません。そこで、カーネルに近いレイヤでパケットをいじることで実現を試みてみました。
実装編!カーネルモジュールで頑張ってみた
カーネルに近いレイヤで!ならカーネルモジュールでしょ。ということでまずカーネルモジュールでの実装を試してみました。(ここまでがっつりCのコードを書いたのは学生の時以来かも。。w)カーネルモジュールでパケットを直接操作するために、netfilter[7]を使っています。netfilterはiptablesのカーネル側の実装だと思ってもらえれば。
コードを全部載せるとすごい量なので一部だけ。。下のコードでは、TCPのSYNパケットを受け取った時にセッションレコードをテーブルに記録して、そこに応答を返却すべきMACアドレスを学習させています。最後にNF_ACCEPTを返していますが、これは、SSRではパケットの受信時はその中から送信元MACを盗み見ているだけでそれ以外に余計なことはしないので単純にパケットを受け入れていることを意味します。
これだけでも結構なコード量だったのでデバッグコードや本質的じゃないコードはバシバシ割愛しています。実際にはデバッグコードや、SYN以外のパケットが到着した場合にセッションレコードのTTLを更新するなど、いくつか周辺的な処理も必要になります。なお、セッションレコードはハッシュテーブルを使いました。
unsigned int receive_hook(
void *priv,
struct sk_buff *skb,
const struct nf_hook_state *state) {
int result;
int create_record;
int reset_connection;
connection_handler_context *context;
connection_handler_condition *condition;
session_table *table;
struct ethhdr *eth_header;
struct iphdr *ip_header;
struct tcphdr *tcp_header;
struct icmphdr *icmp_header;
unsigned char *source_port;
create_record = 1;
context = (connection_handler_context *)priv;
condition = context->condition;
// パケットのヘッダを取り出す
ip_header = (struct iphdr *)skb_network_header(skb);
if (ip_header->daddr == condition->server_ip_address) {
eth_header = (struct ethhdr *)skb_mac_header(skb);
switch (ip_header->protocol) {
case 6: // TCP
tcp_header = (struct tcphdr *)skb_transport_header(skb);
source_port = (unsigned char *)&tcp_header->source;
// SYNパケットならセッションレコードを作成
if (tcp_header->syn != 1 || tcp_header->ack != 0) {
create_record = 0;
}
break;
default:
// TCP以外の場合は省略
}
// セッションテーブルを取得
table = context->table;
if (create_record) {
// 新しいセッションレコードを追加
result = add_record(table,
unsigned char *)&ip_header->saddr,
source_port,
unsigned char)ip_header->protocol,
unsigned char *)eth_header->h_source);
else {
// セッションレコードのTTLを延ばしたり、FINやRSTならセッションレコードを消したり。
}
}
return NF_ACCEPT;
}
続いてパケットの送信。同一のTCPコネクションを識別する方法として、応答の送信先IPアドレス、ポート、プロトコル番号からセッションレコードを検索しています。で、取得したセッションレコードには先ほど記録した要求の通過したロードバランサのMACアドレスが入っているので、そのMACアドレス宛にRAWパケットとして応答を送信しています。実際に応答パケットを送信している実態はrewrite_dest_mac_and_send()です。実装は割愛していますが、要するにL2ヘッダの送信先MACを書き換えて、dev_queue_xmit()で送信しているだけです。
NF_STOLENはnetfilterに対して「このパケットのことは忘れろ」と教えるコードです。SSRが自分で応答パケットを送信するので、カーネルにはnetfilter経由で「このパケットは良しなにやっておくから気にしないでね~」と教えてあげてるわけです。
unsigned int send_hook(
void *priv,
struct sk_buff *skb,
const struct nf_hook_state *state) {
connection_handler_context *context;
connection_handler_condition *condition;
struct iphdr *ip_header;
context = (connection_handler_context *)priv;
condition = context->condition;
ip_header = (struct iphdr *)skb_network_header(skb);
if (ip_header->saddr == condition->server_ip_address) {
int result;
int remove_record;
session_table *table;
struct tcphdr *tcp_header;
struct icmphdr *icmp_header;
struct ethhdr *eth_header;
unsigned char *dest_port;
unsigned char return_mac_address[MAC_ADDRESS_LENGTH];
remove_record = 0;
// 送信する応答パケットのヘッダを読み取る
eth_header = (struct ethhdr *)skb_mac_header(skb);
switch (ip_header->protocol) {
case 6: // TCP
tcp_header = (struct tcphdr *)skb_transport_header(skb);
dest_port = (unsigned char *)&tcp_header->dest;
if (tcp_header->fin == 1 || tcp_header->rst == 1) {
// FINやRSTだった場合はセッションレコードを削除する。
remove_record = 1;
}
break;
default:
return NF_ACCEPT;
}
table = context->table;
// 応答の送信先IPアドレス、ポート、プロトコル番号でセッションレコードをテーブルから検索
result = get_record(table,
(unsigned char *)&ip_header->daddr,
dest_port,
(unsigned char)ip_header->protocol,
return_mac_address,
remove_record);
if (result != 0) {
// 送信パケットの宛先MACアドレスを書き換えてRAWパケットとして送信する。
result = rewrite_dest_mac_and_send(skb, return_mac_address);
if (result == 1) {
return NF_STOLEN;
}
}
else {
return NF_DROP;
}
}
return NF_ACCEPT;
}
上のコードは一部なのでもちろんこれだけでは動きませんが、上のコードを使ってSSRを実装し、無事に期待する動作をすることが確認できました。ふぅ。。
その他の方法
今回はカーネルモジュールとしてnetfilterを使って実装する例を紹介しましたが、他にもnetfilterのサブプロジェクトとして開発されているlibnetfilter_queue[8]を使い、ユーザランドアプリケーションとして実装する方法。プログラムレスでiptablesのCONNMARK extension[9]を使う方法などがあります。今回は紙面の都合上細かくは書きませんが、何を隠そう全部実装して動くことは確認済みですw それぞれ以下のようなデメリットがあり、個人的にはカーネルモジュールでの実装がオススメ
- ユーザランドプログラム
想像に難くないですが、重いです。オーバーヘッドが大きいので相当チューニングしないと性能が出ませんでした。特にパケットを処理するスレッド周りで苦労します。 - CONNMARK extension
あらかじめロードバランサのMACアドレスをサーバに教え込ませる必要が出てきます。機器故障で交換するたびにMACが変わったり。。。なんてことを回避するために仮想MACを使うなど、いろいろと面倒なことが出てきますが、実現性はあるのと性能面ではユーザランドアプリケーションよりは有利です。
そしてどうなったか
spモードのネットワークでもロードバランサをスケールアウトできるようになりました。
いや、それはわかっとる。。この章では、スケールアウトができるとより具体的に何がうれしいの?って話を解説してこの記事を終わりにしようと思います。
スケールアウト!
もともとの目的だったので当然といえば当然ですがロードバランサのスケールアウトが可能になります。SSR以外の方式で存在していたデメリットについてみてみましょう。
| # | SSR以外に存在したデメリット | SSRだと? |
|---|---|---|
| 1 | 暗号化/復号化のロードバランサへのオフロード | SSRでは要求/応答通信の対称通信を実現しているのでロードバランサに暗号化/復号化をさせることが可能です |
| 2 | サーバのリバランスが必要 | SSRはサーバが自動的に要求通信の到着元ロードバランサにパケットを返却してくれるのでリバランスは不要です。というかロードバランサを足したり引いたり交換した時にもルーティング変更が一切不要になってます |
| 3 | Source IP NATにより送信元IPアドレスが変わってしまう | SSRではSource IP NATはしないのでこの問題は起きません |
じゃあ、SSRは最強で他の選択肢はナンセンス!?というとそうでもありません。SSRは応答通信もロードバランサ経由で通信させているため、ロードバランサに帯域や負荷をかけます。一方DSRは応答通信がロードバランサをバイパスするのでこれが起こりません。一般的に、要求通信よりも応答通信の方がデータ量が大きいので、状況によってはこのメリットの方が勝る場合もあると思います。
さてここで密林さんのElastic Load Balancer(ELB)[10]の一覧を見てみましょう。上のメリデメ表と、SSLオフロード、ソースIPの保持、などの項目を見比べてみると、ELBのどの選択肢がどの実装により実現されているのか想像が膨らんじゃいますねw
All Activeにしようぜ
スケールアウトができるということは、Acitve/Stanbyの冗長構成ではなく、Active/ActiveやActive/Active/ActiveのようなAll Active構成が取れます。これは、「SSRは要求の通信が経由したロードバランサに応答を返す」という動作をしているため、ロードバランサがいくら増えたり(故障等により)減ったりしても自動的に応答の返却先から除外される、という特性によるものです。Active/Stanbyでは普段Stanbyの1台が遊んでいるのに対し、All Active構成では全台のロードバランサが仕事をしていて、ピーキーなイベントトラフィックなどに対する耐性が高いことを意味します。
可用性を高めてみようぜ!
超ミッションクリティカルなシステムではActive/Stanbyの2重冗長では可用性が足らず4重冗長やそれ以上が求められる場合があります。SSRを使ったスケールアウト構成では基本的に任意の台数の冗長構成を組むことができるので、例えば
- (Active/Stanby) x 2、x 3... x N
- Active/Active/Active ... x N
のような様々な冗長構成を柔軟に取れるようになります。All Activeにしようぜ!とか言っておきながらなぜActive/Stanby x N構成なんか書いているかというと、ロードバランサは機種によってTCPやSSLのセッションをActive/Stanbyで引き継げるものがあるため、瞬断、再接続すら許されないようなシステムにおいてはActive/Stanby構成を複数並べることで超高可用性を実現することができます。

ロードバランサのプール化!?
サーバの仮想化ではサーバをプール化し、故障時や性能不測の際にプールからサーバを払い出してさっと組み込むことができたりします。同じように、ロードバランサもサービス1用、サービス2用、プール用と分け、必要に応じてプールからサービス1やサービス2に払い出す、といったことが可能になります。
終わりに
この記事ではspモードで導入したSSRというロードバランサをスケールアウトするための技術について紹介しました。まだ導入後まもなく、記事の後半で書いたような応用例はこれから、というところ。それらも今後導入を進められた際にはどこかでご紹介できたらと思っています。
今回、このSSRを考案して導入するにあたりいろいろと文献を調べましたが大規模データセンターシステムに関するこういった工夫についての記事、論文はやはりGAFAMばかり。。そんな中、この記事がキャリアだってちょっとはこういうトリッキーな工夫をすることもあるんだよって知ってもらう機会になれば幸いです。最後に、本記事に興味を持って読んでいただいた皆様、ありがとうございました。
参考文献
[1] ディフィー・ヘルマン鍵共有, Wikipedia, リンク
[2] DNSラウンドロビン, Wikipedia, リンク
[3] ECMP Flow-Based Forwarding, Juniper Networks., リンク
[4] ロードバランサのアーキテクチャいろいろ, yunazuno, リンク
[5] DSR (Direct Server Return), ネットワークエンジニアとして,リンク
[6] Maglev: A Fast and Reliable Software Network Load Balancer, Google Inc., リンク
[7] The netfilter.org project, The Netfilter's webmasters, リンク
[8] The netfilter.org "libnetfilter_queue" project, The Netfilter's webmasters, リンク
[9] Man page of iptables-extensions, リンク
[10] Elastic Load Balancing の特徴, AWS, リンク