これはNTTドコモ R&D Advent Calendar 2021の17日目の記事です。
概要
乗換検索のサービスは世の中に数多くあって、どれもとても良くできていますね。
一方で、最短経路とか最安経路とか、すでに決められている基準以外の検索をするには、やっぱり自作するしかありません。
ということで、自作の乗換検索アルゴリズムをPythonで実装してみました。
誰か既にやっているのでは
これを作ろうとしたとき、すでに誰かが作っていて記事化していると思って探しました。
なるほど、もうUI化までされていましたか。
ただしこちらの記事では、↓のような駅間の接続と長さを表す隣接行列がすでに用意されています。
| 発駅\着駅 | 米花 | 古糸 | 奥穂 | 鳥矢 | ・・・ |
|---|---|---|---|---|---|
| 米花 | 0.8 | ||||
| 古糸 | 0.8 | 1.0 | |||
| 奥穂 | 1.0 | 1.2 | |||
| 鳥矢 | 1.2 | ||||
| ・・・ |
しかし今回は、手元にあるデータは↓のようなCSVファイルだけで、隣接行列はありません。
./senku.csv
| line | section | station | operation_kilo |
|---|---|---|---|
| 米花線 | 米花〜杯戸 | 米花 | 0.0 |
| 米花線 | 米花〜杯戸 | 古糸 | 0.8 |
| 米花線 | 米花〜杯戸 | 奥穂 | 1.8 |
| 米花線 | 米花〜杯戸 | 鳥矢 | 3.0 |
| ・・・ | ・・・ | ・・・ | ・・・ |
| 米花線 | 米花〜杯戸 | 杯戸 | 31.2 |
| 米花線 | 米花〜西多摩 | 米花 | 0.0 |
| 米花線 | 米花〜西多摩 | 帝丹 | 1.1 |
| ・・・ | ・・・ | ・・・ | ・・・ |
(lineは路線名、sectionは区間名、stationは駅名、operation_kiloは各路線各区間の始発駅からの営業キロ)
ということで、このCSVを加工する必要があるため、今回はDataFrameの操作をひたすら頑張るところからグラフ構造化、最短経路検索までやっていきたいと思います。
作ったもの
地上鉄道や地下鉄の出発駅から到着駅までの経路を検索するアルゴリズム。
経路中の営業キロの合計が最小になるような経路検索ができます。
実装
それでは実装してみます。
↓が大まかなプログラムのフローです。
- 鉄道路線データを整形する
- 駅をノード、各駅区間の営業キロを重みとしたエッジで構成されるグラフを作る
- 入力された発駅と着駅を結ぶ経路で、経由するエッジの重みの和が最小となるものを計算する
- 計算された経路を出力する
事前に下記をインポートしておきます。
import os
import pandas as pd
import numpy as np
from scipy.sparse import csr_matrix
from scipy.sparse.csgraph import dijkstra
鉄道路線データを整形
今回与えられたデータが(路線名,区間名,駅名,始発駅からの営業キロ)で構成されたもので、鉄道ネットワークを構成するためには(発駅名,着駅名,発駅と着駅間の営業キロ)に変換したいものです。
そこで同じテーブルをもうひとつ用意し、1行下げて横に並べることで発駅と着駅を対応させました。
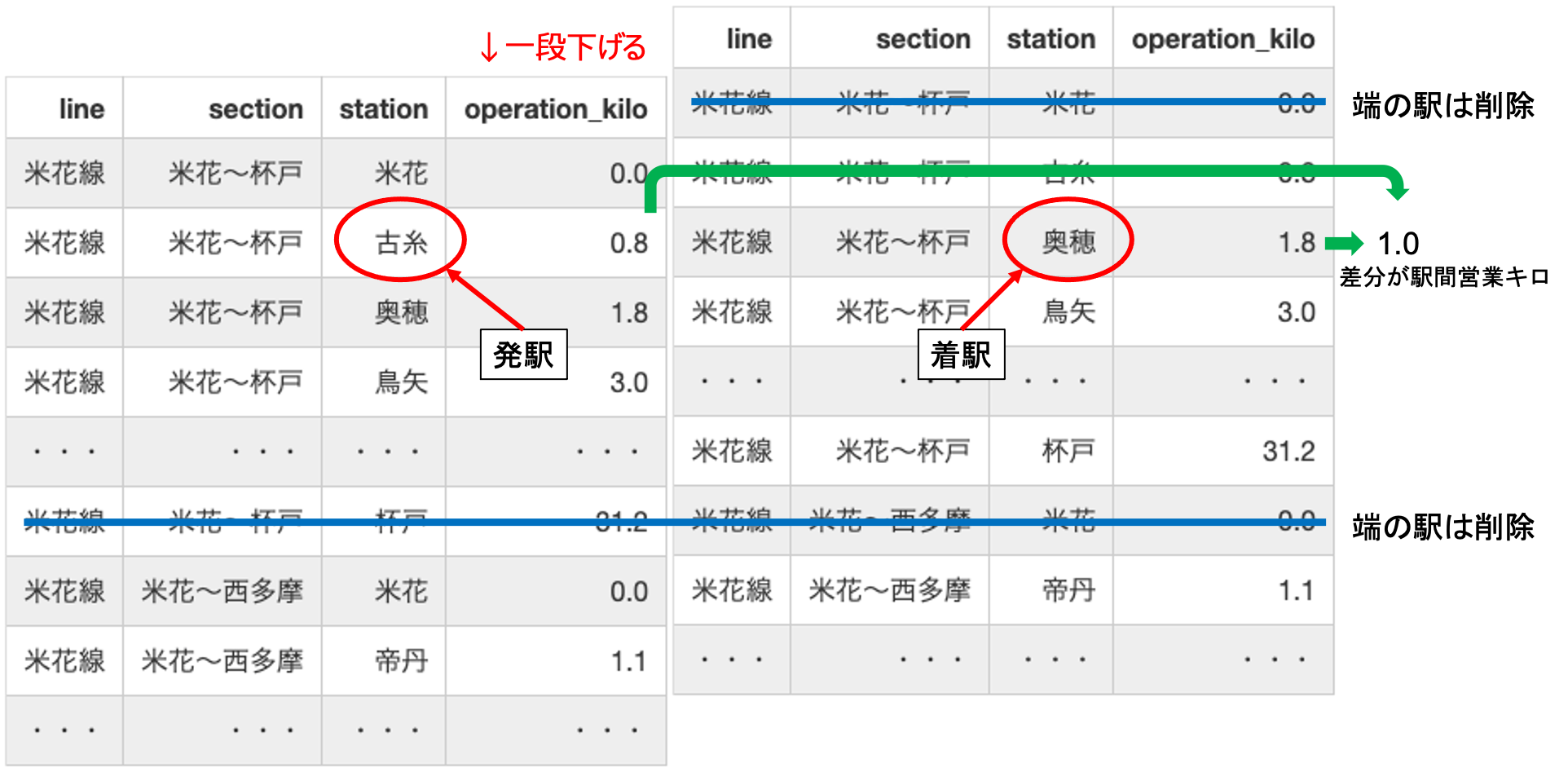
↑このような感じをめざします。
# 鉄道路線データの読み込み
senku_df = pd.read_csv(os.path.join('.','senku.csv'))
# 同一路線、同一区間における各駅の順番の番号を振る
senku_df['station_num'] = senku_df.groupby(['line','section']).cumcount()
# ソートしておく
senku_df = senku_df.sort_values(['line','section','station_num']).reset_index(drop=True)
| line | section | station | operation_kilo | station_num |
|---|---|---|---|---|
| 米花線 | 米花〜杯戸 | 米花 | 0.0 | 0 |
| 米花線 | 米花〜杯戸 | 古糸 | 0.8 | 1 |
| 米花線 | 米花〜杯戸 | 奥穂 | 1.8 | 2 |
| 米花線 | 米花〜杯戸 | 鳥矢 | 3.0 | 3 |
| ・・・ | ・・・ | ・・・ | ・・・ | ・・・ |
| 米花線 | 米花〜杯戸 | 杯戸 | 31.2 | 18 |
| 米花線 | 米花〜西多摩 | 米花 | 0.0 | 0 |
| 米花線 | 米花〜西多摩 | 帝丹 | 1.1 | 1 |
| ・・・ | ・・・ | ・・・ | ・・・ | ・・・ |
# senku_dfを着駅、行を1つ下へずらしたものを発駅として横方向へ結合
senku_df = pd.concat([
senku_df.add_prefix('pre_').shift().copy(),
senku_df.add_prefix('next_').copy()
],axis=1)
# 各区間の端っこを削除
senku_df = senku_df[senku_df['next_station_num']!=0]
# 隣り合う駅間の営業キロを付加
senku_df['operation_kilo'] = senku_df['next_operation_kilo'] - senku_df['pre_operation_kilo']
# データを整える
senku_df = senku_df[['pre_line','pre_section','pre_station','next_station','operation_kilo']]
senku_df = senku_df.rename(columns={'pre_line':'line','pre_section':'section'})
# 上り下り両方向へ対応させます
senku_df = pd.concat([
senku_df.copy(),
senku_df.rename(columns={'next_station':'pre_station','pre_station':'next_station'}).copy()
],axis=0,sort=False).drop_duplicates()
| line | section | pre_station | next_station | operation_kilo |
|---|---|---|---|---|
| 米花線 | 米花〜杯戸 | 米花 | 古糸 | 0.8 |
| 米花線 | 米花〜杯戸 | 古糸 | 奥穂 | 1.0 |
| 米花線 | 米花〜杯戸 | 奥穂 | 鳥矢 | 1.2 |
| ・・・ | ・・・ | ・・・ | ・・・ | ・・・ |
これで、一通り整形は完了です。
ただし、同一の駅間を複数の路線が通っていたり、急行緩行があったりの問題があるので、そこも手を加えておきます。
# 今回は、路線の区別はしないで計算します
# 複数の路線が同一駅間を持つ場合は、最も営業キロが少ないものをその駅間の営業キロとします
senku_df = pd.concat([
senku_df.groupby(['pre_station','next_station'])['operation_kilo'].min(),
senku_df.groupby(['pre_station','next_station'])['line'].agg(lambda x: '|'.join(set(x)))
],axis=1).reset_index()
# 急行と緩行がある場合、急行が有利になるように各駅間ごとにペナルティを付加します
senku_df['operation_kilo'] = senku_df['operation_kilo'] + 0.1
また、世の中には溜池山王と国会議事堂前、有楽町と日比谷のような駅名は違えど徒歩で乗り換えることができる駅があります。
このままでは、本来は日比谷駅から永田町駅へ行くのに、
- 日比谷→国会議事堂前(千代田線)
- 国会議事堂前→溜池山王(乗り換え)
- 溜池山王→永田町(南北線)
で済むところが
- 日比谷→大手町(千代田線)
- 大手町→飯田橋(東西線)
- 飯田橋→永田町(南北線)
というようにかなり遠回りになってしまいます。
このように地理的にはほぼ同じ場所に位置していて、徒歩での乗り換えが簡単な駅同士でも、駅名が異なっていてそれらを直接結ぶ路線もない場合には回り道をして経路を検索してしまいます。
それを防ぐために、このような駅同士の間を結ぶエッジを加えてあげます。
(今回は東京付近のみ。全国を網羅してるリストが欲しい。)
# 近接する駅同士で、同一駅とみなせる駅間の営業キロを0.1として繋いであげる
close_station_set_list = [
{'馬喰町','馬喰横山','東日本橋'},
{'上野広小路','上野御徒町','御徒町','仲御徒町'},
{'春日','後楽園'},
{'国会議事堂前','溜池山王'},
{'京橋','宝町'},
{'秋葉原','岩本町'},
{'浜松町','大門'},
{'有楽町','日比谷'},
{'原宿','明治神宮前'},
]
for station_set in close_station_set_list:
for pre_station in station_set:
for next_station in station_set-{pre_station}:
senku_df = senku_df.append({
'pre_station': pre_station,
'next_station': next_station,
'operation_kilo': 0.1,
'line':'徒歩'
}, ignore_index=True)
鉄道ネットワークのグラフを作る
次に上で作ったDataFrameをグラフ化します。ここはscipyのcsr_matrixを使ってすんなりとできました。
↑このような感じです。
# 出現する駅を重複のないlist化をして、各駅に対してIDを振る
# 後述するグラフ化に用いる関数でこの処理が必要
station_list = list(set(senku_df['pre_station'])|set(senku_df['next_station']))
senku_df['pre_station_id'] = senku_df['pre_station'].map(lambda x: station_list.index(x))
senku_df['next_station_id'] = senku_df['next_station'].map(lambda x: station_list.index(x))
# [始点ノード(駅)ID, 終点ノード(駅)ID, 始点と終点を結ぶエッジの重み(営業キロ)]を列とするnumpy配列を用意し、下記のようにcsr_matrixに渡してあげるとグラフが完成する。
n_node = len(station_list)
edge = np.array(senku_df[['pre_station_id','next_station_id','operation_kilo']], dtype=np.int64).T
graph = csr_matrix((edge[2], (edge[:2])), (n_node, n_node))
最短経路を計算する
最後に実際に最短経路を求めます。
出発駅をstart_station、到着駅をgoal_stationとして入力したときに、経由駅とそれぞれの駅間にどの路線を使うのかを出力します。
# 発駅と着駅を入力
start_station = '上野'
goal_station = '四ツ谷'
# 今回はダイクストラ法を使って求めます
# こちら↓を参考にさせていただきました
# https://kawap23.hatenablog.com/entry/2019/09/10/194816
distance_mat, processors = dijkstra(
graph,
directed=True,
indices=station_list.index(goal_station),
return_predecessors=True
)
processorsは配列になっていて、終点に向かうときの各ノードの次にステップするノードのIDを示しています。
tmp_node = station_list.index(start_station)
print(start_station)
while processors[tmp_node]>=0:
tmp_df = senku_df[(senku_df['pre_station_id']==tmp_node)&(senku_df['next_station_id']==processors[tmp_node])].iloc[0]
print('\t->',tmp_df['line'])
tmp_node = processors[tmp_node]
print(station_list[tmp_node])
これで完成です。
出力結果
- 上野→四ツ谷
上野
-> 山手線|京浜東北・根岸線
御徒町
-> 山手線|京浜東北・根岸線
秋葉原
-> 総武本線
御茶ノ水
-> 総武本線
水道橋
-> 総武本線
飯田橋
-> 総武本線
市ケ谷
-> 総武本線
四ツ谷
よさそうです。
- 上野→新宿
上野
-> 山手線|京浜東北・根岸線
御徒町
-> 山手線|京浜東北・根岸線
秋葉原
-> 総武本線
御茶ノ水
-> 総武本線
水道橋
-> 総武本線
飯田橋
-> メトロ有楽町線|総武本線|メトロ南北線
市ケ谷
-> 総武本線|メトロ南北線
四ツ谷
-> 総武本線
信濃町
-> 総武本線
代々木
-> 都営大江戸線|総武本線|山手線
新宿
山手線1本で行くよりも総武線を乗り継いだ方が営業キロ的には短いのですね。
- 上野→水戸
上野
-> 山手線|京浜東北・根岸線
御徒町
-> 山手線|京浜東北・根岸線
秋葉原
-> 総武本線
浅草橋
-> 総武本線
両国
-> 都営大江戸線
森下
-> 名古屋鉄道瀬戸線
大曽根
-> 名古屋鉄道瀬戸線
矢田
-> 名古屋鉄道瀬戸線
守山自衛隊前
-> 名古屋鉄道瀬戸線
瓢箪山
-> 近鉄奈良線
枚岡
-> 近鉄奈良線
額田
-> 水郡線
南酒出
-> 水郡線
上菅谷
-> 水郡線
中菅谷
-> 水郡線
下菅谷
-> 水郡線
後台
-> 水郡線
常陸津田
-> 水郡線
常陸青柳
-> 水郡線
水戸
なるほど、常磐線1本かと思いましたが、名鉄と近鉄を乗り継いだ方が近いみたいですね。
改善が必要
もちろん上野→水戸の検索結果はバグで、東京と茨城の間に愛知と大阪はありません。
調べてみると、森下駅は東京と愛知と福岡、瓢箪山駅は愛知と大阪、額田駅は大阪と茨城に存在していて、同じ駅名を持つ駅同士の間でワープして検索してしまうということが起こっているようです。
純粋に常磐線1本で行くよりも、愛知の森下駅にワープして愛知の瓢箪山駅へ向かい、大阪の瓢箪山駅へワープして大阪の額田駅へ向かい、また茨城の額田駅へワープした方がショートカットになる、ということでしょうか。
このバグは、同じ駅名を持つ駅同士がちゃんと識別できるようにグラフを作ることで解消できると思います。
今回はこのバグの解消までは記しませんが、将来的には直したいですね。
おわりに
この経路検索プログラムの作成を通じて、経路検索が非常に複雑な仕組みで動いているということが実感できました。
このように、普段我々が日常的に使っているものは、大変な苦労の上に成り立っているものがほとんどなのかなと思います。
これからは何を使うときも、感謝の気持ちを持ってありがたく使っていきたいです。
また、機会がありましたら他のものも自作していきたいと思います。
それでは、お読みいただきありがとうございました。