はじめに
NTTドコモクロステック開発部の長谷川です。
この記事はNTTドコモ R&D AdventCalendar2021 18日目の記事です。
本稿では、個人情報の匿名加工コンペティションであるPWSCup2021における取り組みについて紹介します。
PWSCupへのNTTドコモからの参加は今回で二回目になります。
本稿の執筆者とは異なる参加メンバーですが、前回の参加の様子は昨年のアドベントカレンダーにて記載しておりますので、ご興味がありましたら併せてご覧ください。
なお、本コンペティションはテーマに相応しく匿名での参加が可能になっています。我々のチームも「匿工野郎Aチーム」というチーム名で参戦しておりましたが、以降本稿では割り当てられたチーム番号を用いて、自チームをチーム05と呼称します。
目次
PWSCupとは?
PWSCupとは、情報処理学会コンピュータセキュリティ研究会のPrivacy Workshopが主催する、個人情報の匿名加工技術を競うコンペティションです。2015年から開催されており、今年で7回目となります。
昨今では、個人情報を含むビッグデータを分析活用するニーズが高まる一方で、分析データに含まれる個人のプライバシーは保護されることが強く求められています。
データを匿名加工する過程において、個人に紐づく情報を削除することや年齢などの属性情報の粒度を落とすことで、安全性を高めることができます。しかしながら、データを加工することで分析結果の精度が低下するなど、データの有用性が低下する恐れがあります。
このようなデータの有用性と安全性のトレードオフは、大きな課題となっており、解決に向けて様々な研究が行われています。
PWSCupでは、このようなデータ加工におけるトレードオフを両立することを目的に開催されており、有用性が高く最も安全なデータ加工を実施したチームが勝者となります。
PWSCupのテーマは毎年変わりますが、今年は糖尿病罹患予測に用いるヘルスケアデータの匿名加工がテーマとなりました。糖尿病は様々な疾患のリスクを高めることが知られており、健康寿命延伸のためにも、罹患予測による予防は非常に重要です。
プライバシーを保護したまま糖尿病罹患に関するデータ分析を実施するため、データから得られる糖尿病予測に重要な傾向を残しつつ、あるレコードが誰のデータかわからないように加工することが求められます。
コンテストの概要は下記の動画から見ることができます。
PWS Cup 2021 ヘルスケアデータ匿名化コンテスト - YouTube
余談ですが、国際的にも安全なデータの利活用には期待が高まっており、昨年には著名な機械学習の国際会議であるNeurIPSにおいてもHide-and-seek privacy challengeというデータの匿名性と有用性をテーマにしたコンペティションが開催されています。
また、こちらのコンペティションでは、これまでのPWSCupへの参加や運営を通じて、匿名加工技術を磨かれてきたNTTチームの皆さんが見事匿名加工タスク1位を獲得するなどの活躍を見せています。
PWSCupのルール
チーム05の戦略を説明する前に、PWSCupのルールについて説明していきます。
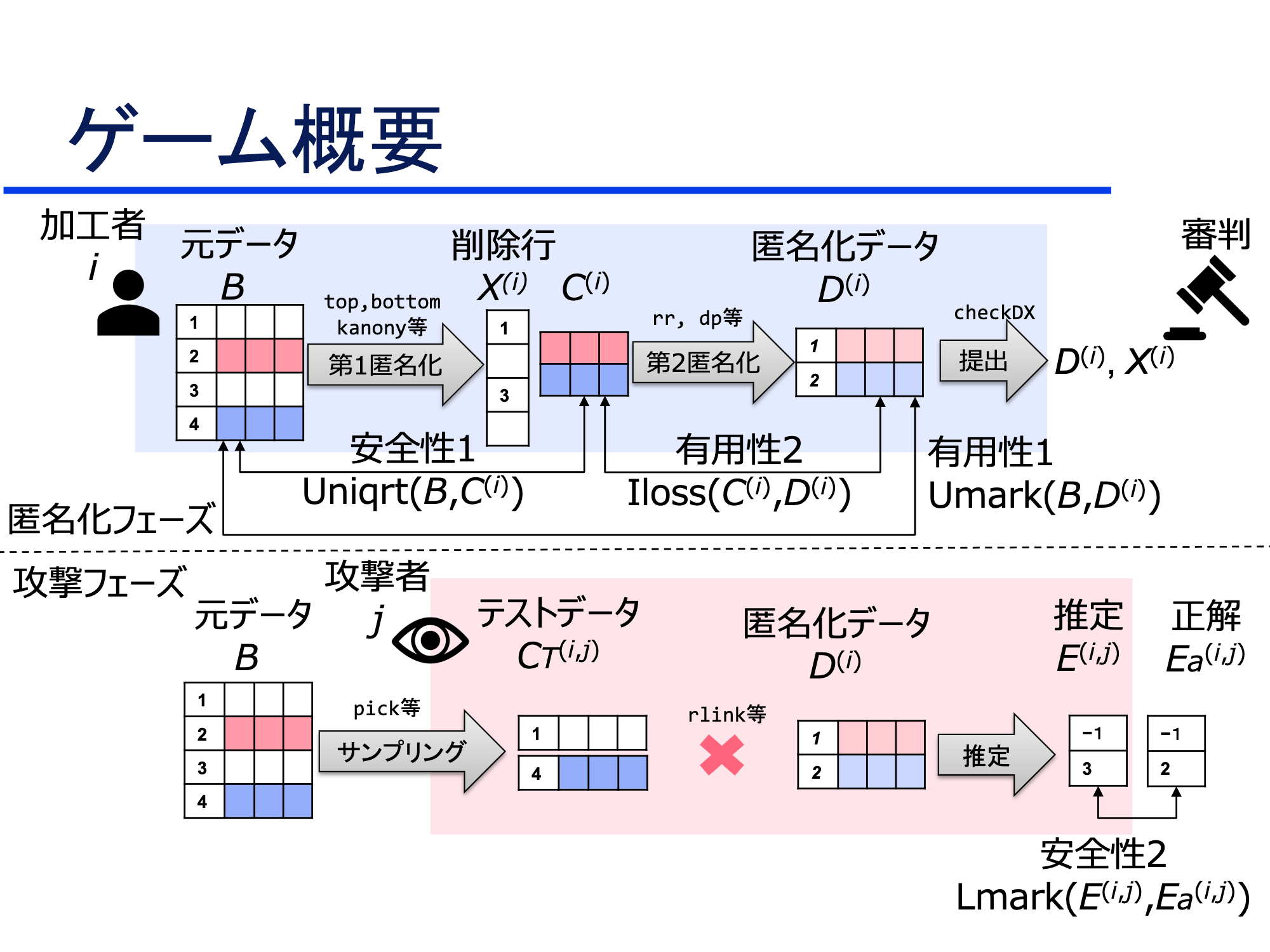
もう少し大まかに書くと下図のようになります。
PWSCupは、参加チーム間で相互に、防御を行うデータの匿名加工フェイズ(図左)と、相手チームデータの再識別を行う攻撃フェイズ(図右)を行う攻防戦形式です。再識別と言う言葉が聞きなれない方も多いかと思います。再識別とは、匿名加工した後のデータと元データを対照し、ある匿名加工レコードが元データにおいてどの(誰の)レコードであったかを推定する攻撃を意味します。
また、予備戦と本戦という形でそれぞれのフェイズを2ラウンド行い、合計順位で総合順位を決定します。
- 匿名加工フェイズ:安全性や有用性の条件を満たした上で、自チームのデータが再識別されないように削除や加工を施します。
- 攻撃フェイズ:相手チームが加工したデータを分析し、それぞれのレコードが誰なのかを特定します。
データ加工や匿名加工技術に馴染みがない、という参加者でも、匿名加工・攻撃それぞれの代表的な手法について運営からサンプルコードが提供されているため、気軽に取り組むことができます!毎年7月頃に募集がかかり、8月から9月で攻防戦の実施、10月末のコンピュータセキュリティシンポジウムで結果発表が行われますので、ご興味があれば参加してみてください。
では、もう少し詳しく今回のコンテストのルールについてご紹介します。
まず、今回のコンテストで利用する用語を下記のように定義します。
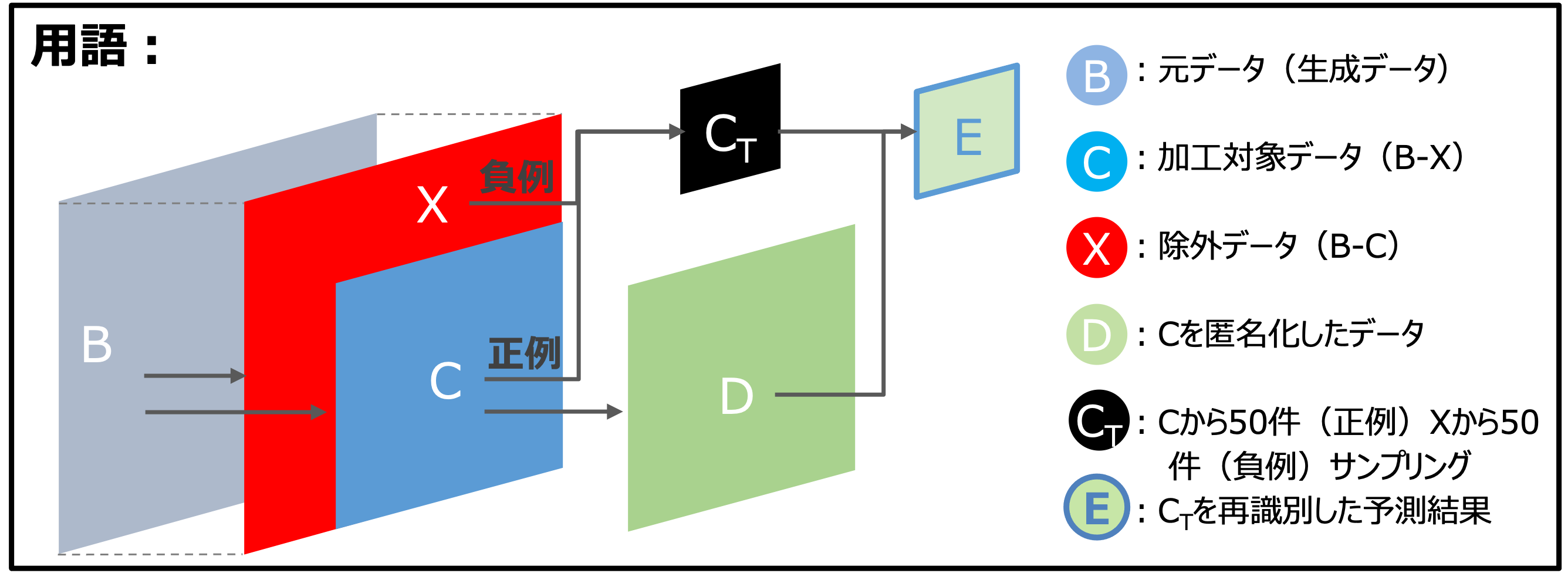
匿名加工フェイズ概要
匿名加工※とは、特定の個人が識別できないように個人情報を加工することを意味します。
PWSCupの匿名加工フェイズでは、参加者は与えられたデータセットBから匿名加工データDを作成します。
利用データの詳細は後ほど説明しますが、一人一人のデータが行になっている個票形式(Excelの表のようなもの)をイメージしてください。
(※注:PWSCupにおける匿名加工フェイズでの加工技法は、個人情報保護法やそのガイドラインにおける匿名加工技法とは厳密には一致しない可能性があります。)
匿名加工フェイズはデータ削除とデータ加工の二段階で構成されます。
- まず元データBから削除するデータXを決定し、残りのデータを加工対象データCとします。
- 加工対象データCを再識別されないように加工し匿名加工データDを作成します。
ここで、匿名加工後のデータが有用性を失わないよう、それぞれのデータは次にあげる基準を満たす必要があります。よって、個々のレコードは再識別されないように加工しつつ、データ全体としては元データと同様の統計的な性質を保ったまま加工しなければなりません。
匿名加工データが満たすべき基準について
| 指標 | 概要 | 閾値 | |
|---|---|---|---|
| Uniqrt | 安全性指標 | 加工対象データCのユニークなレコード割合 | 1/2以下 |
| Iloss | 有用性指標 | 加工対象データCから匿名加工データDを作成する過程での情報変更(連続値の増減やカテゴリ値の置換) | 4以下 |
| Umark(比率) | 有用性指標 | 元データBと匿名加工データDでの糖尿病罹患/非罹患に対する他の属性の変化割合 | 0.05以下 |
| Umark(相関関係) | 有用性指標 | 元データBと匿名加工データDの各属性間の相関係数の変化割合 | 0.1以下 |
| Umark(オッズ比) | 有用性指標 | ロジスティック回帰を利用した罹患予測に対する各属性(説明変数)のオッズ比変化割合 | 0.1以下 |
説明が難しくなってしまいましたが、大まかに言えば元データと匿名加工後のデータで、属性の割合や属性間の相関関係を崩さないように加工することが求められているとご理解いただければ良いと思います。
今回のコンペティションではこの基準が難しかったのか、有用性指標をクリアするための調整に苦労したとコメントしていたチームが多かった印象です。
攻撃フェイズ概要
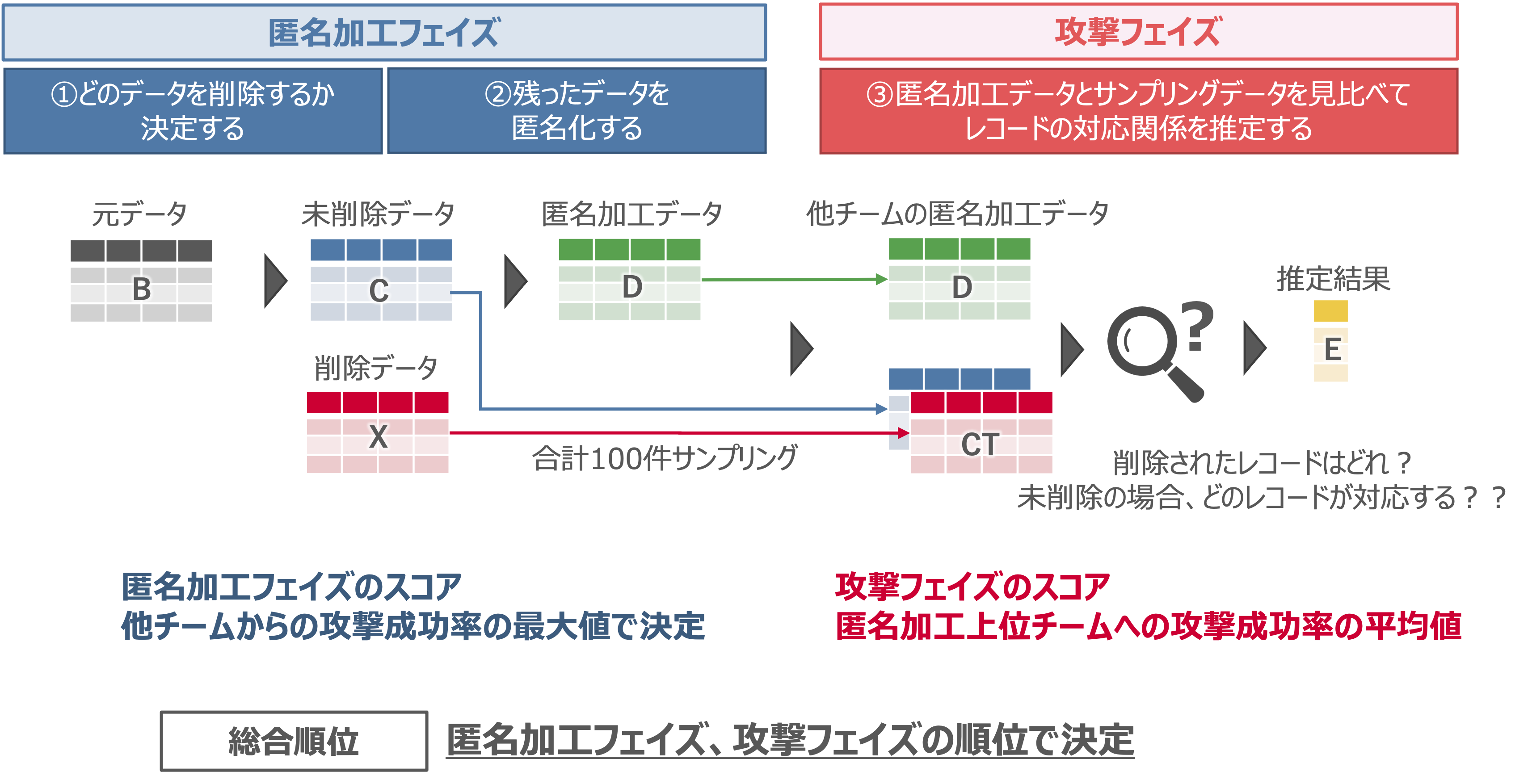
攻撃フェイズでは、他チームが作成した匿名加工データDと、加工対象データCおよび削除データXからサンプリングされたデータCTが与えられます。CTの全てのレコードについて、次の二つの推定を行います。
- 各レコードが、匿名加工データDの作成過程で削除されたデータXか否かを推定する。
- 削除されていない、つまり加工対象データCからサンプリングされたデータである場合、匿名加工データDのどの行が対応するか推定する。
以降、前者をメンバシップ推定、後者をレコードリンケージもしくは再識別と表現します。
-
メンバシップ推定:元データに特定のレコードが含まれているか否かを推定する攻撃です。
昨今では、公開された学習済みの機械学習モデルにデータを入力することで、学習データを推定する研究なども行われています。 -
レコードリンケージ(再識別):匿名加工されたレコードが元データのどのレコードなのかを推定する攻撃です。
一般的には複数の公開情報を組み合わせて該当する人物を特定する攻撃を意味します。
以降、一般的な機械学習における分類問題と同様に、サンプリングデータCTに対するメンバシップ推定の結果が、加工対象データCに含まれる場合を正例、削除データXに含まれる場合を負例と定義します。
各フェイズのスコアについて
攻撃フェイズ及び匿名加工フェイズのスコアは、それぞれの相手チームに対して、サンプリングされたデータCTをどのくらい正解できたのかで決まり、下記の3つの指標の積で定義されます。
攻撃スコア = Recall ✖️ Precision ✖️ Topk
互いに作成した匿名加工データに対してこのスコアを算出し、匿名加工フェイズおよび攻撃フェイズの順位を決定します。
-
匿名加工フェイズでは、他チームから受けた最大の攻撃スコアが自チームのスコアとなり、より低い(安全性が高い)スコアを獲得したチームが勝利となります。
-
攻撃フェイズでは、匿名加工フェイズの上位3チームに対する平均攻撃スコアが自チームのスコアとなり、より高いスコアを獲得したチームが勝利となります。
ここで重要なのは、攻撃フェイズにおいては堅牢な匿名加工を施したチームへの攻撃のみが対象であるという点です。
| 指標 | 種類 | 概要 |
|---|---|---|
| Recall | メンバシップ推定 | 正しく正例と推定したレコード数/実際の正例レコード数 |
| Precsicion | メンバシップ推定 | 正しく正例と推定したレコード数/正例と予測したレコード数 |
| Topk | 再識別 | 再識別の正解数/実際の正例レコード数 |
| また、Topkについては再識別候補として3行まで候補となるレコードを回答することができます。 |
利用するデータについて
糖尿病罹患予測データとして、CDC(米国疾病対策センタ)が取得しているNHANESというデータセットの一部を利用しました。
このデータセットには4190人の糖尿病罹患有無を含む10属性(年齢や性別、BMIや身体活動量など)のデータが含まれています。
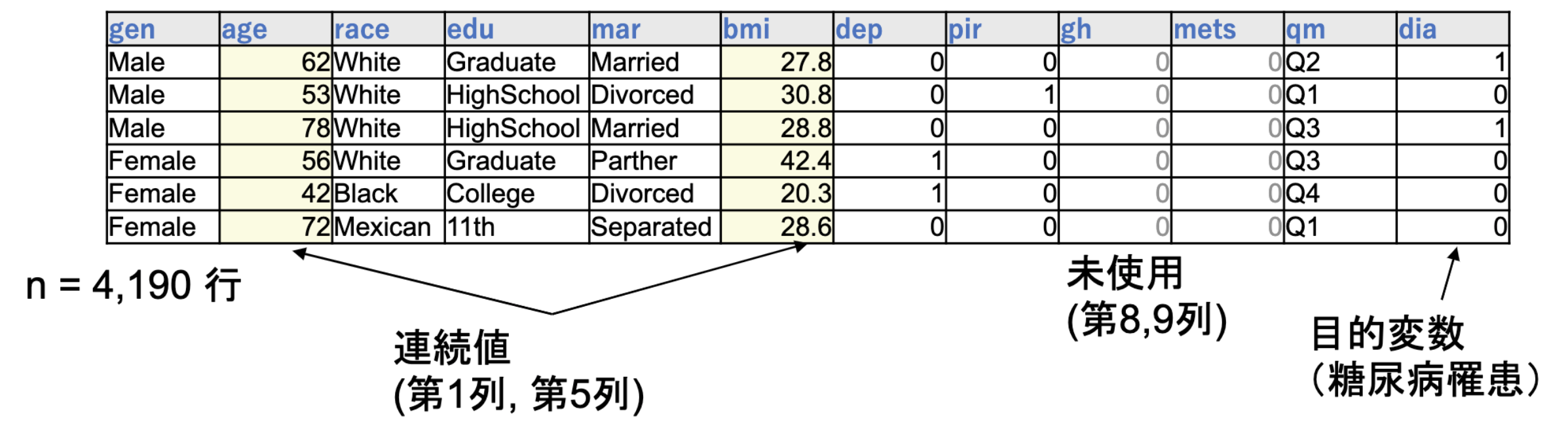
(PWSCup2021 コンテストルール説明資料より引用)
余談ですが、このデータを利用して糖尿病の罹患予測ができるかという点については、Zhaoらの先行研究において有用性が報告されています。
下図は横軸に身体活動量(METS)、縦軸に糖尿病への罹患リスク(オッズ比)を示し、運動の多寡と糖尿病罹患の関係について可視化したグラフ(実線がオッズ比、破線は95%信頼区間)です。全く運動をしていない状態を基準に、低強度の運動でも罹患リスクは大きく減少し、その後身体活動レベルが上昇するにつれて緩やかに減少しています。
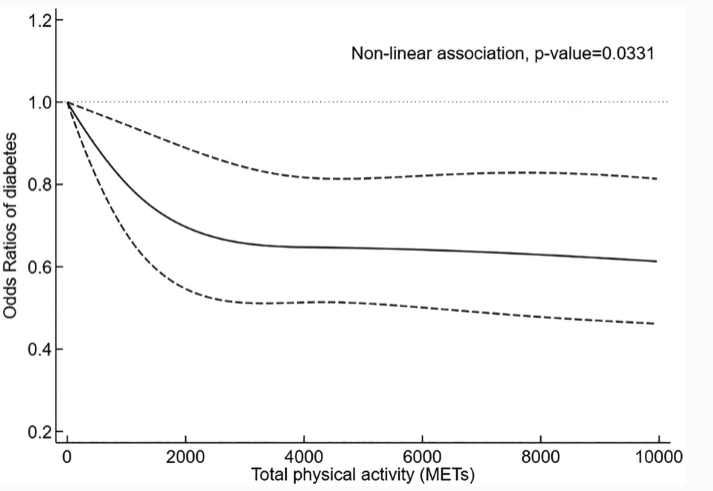
(Zhao, F., Wu, W., Feng, X. et al. Physical Activity Levels and Diabetes Prevalence in US Adults: Findings from NHANES 2015–2016. Diabetes Ther 11, 1303–1316 (2020). https://doi.org/10.1007/s13300-020-00817-xより引用)
チーム05の戦略
ここからはチーム05の戦略についてご説明します。
匿名加工フェイズ戦略
一般的な匿名加工技法として、例えば個人に紐づくIDの削除や、住所の詳細部分の削除、代表値の置き換えなどの方法が知られています。
データ分析の観点では下表のような加工方法を組み合わせて行われることが一般的です。
| 手法 | 概要 |
|---|---|
| トップ/ボトムコーディング | 身長200cmを180cm以上に置き換えるように大きい/小さい値を持つ属性をまとめる。 |
| ミクロアグリゲーション | 複数のレコードをグルーピングしてグループの代表値で属性値を置き換える。 |
| スワップ | 特定の属性値をレコード間で置き換える。 |
| k匿名化 | データに特定の属性や属性の組み合わせがkレコード以上存在するように加工する |
| ノイズ付加 | 特定の属性値にノイズを与える |
チーム05では予備戦の匿名加工フェイズにおいて、上記の匿名加工方法等を組み合わせて匿名化データDを作成しました。
具体的には、攻撃フェイズでの再識別が容易そうな特異なレコードを、元データBから削除し、残ったデータにノイズを付与する、という方針です。しかしながら、他チームから上手く再識別されてしまい、結果は悲しいものとなりました。
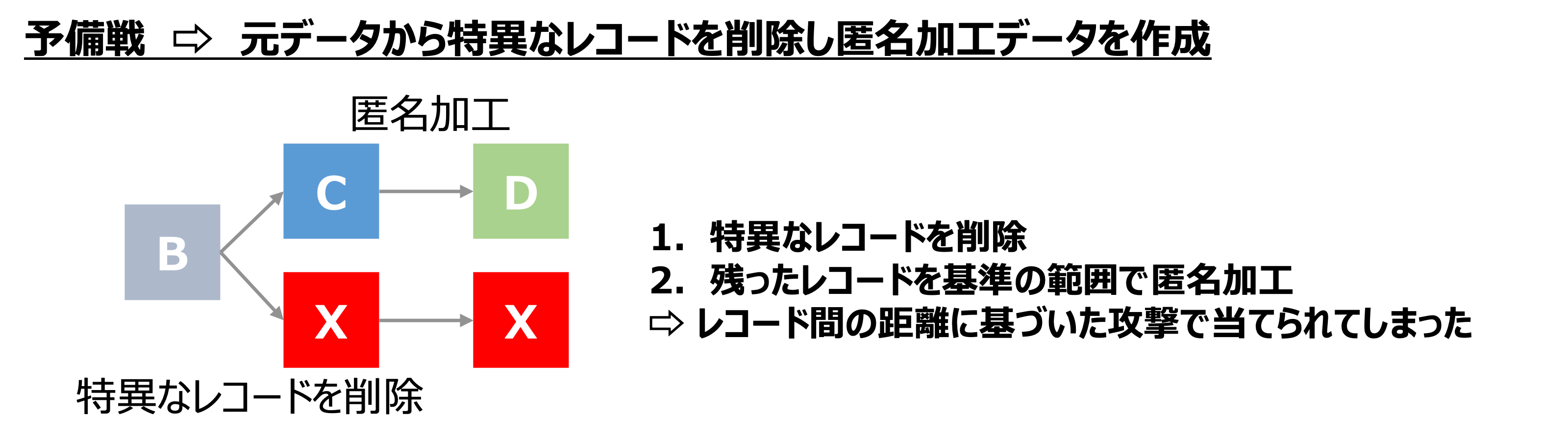
そこで、本戦の匿名加工フェイズでは既存の匿名加工技法を利用するのではなく、別なアプローチを取ることにしました。アイディアは、削除データXで加工対象データCを偽装し、匿名加工データDを作成することです。

相手チームの攻撃戦略を考えた場合、基本的にはレコード間の距離(類似性)を指標にメンバシップ推定と再識別攻撃を行ってくることが想定されます。
匿名加工データDを作成する過程において、加工対象データCを削除データXで置き換えるような加工ができれば、再識別を行う際に相手チームが正例(つまり未削除の加工対象データC)と判定したレコードが、実際には削除レコードXだった、という偽陽性の不正解を誘発することができます。
実装方針
さて、戦略は決まりましたが、実現するには前述の有用性指標を満たすように、加工対象データCを削除データXで置き換え、もしくは近似するように実装する必要があります。
また、加工対象データCから匿名加工データDを加工する過程においては、データセット全体の有用性指標を達成することに加えて、各レコードで変更可能な情報にも上限があります。(本戦の閾値設定では、年齢などの連続値は4以下、カテゴリ値の置き換えも合計4つまで)
この実装における課題に対して、我々のチームでは元データBをクラスタリングする手法を用いました。クラスタリングを行うことで、類似するレコードで構成されたクラスタ群を作成します。クラスタ内でレコードの置き換えや削除を行うことで、有用性指標を満たしつつ匿名加工データDと削除データXに類似レコードを残すことを実現しました。
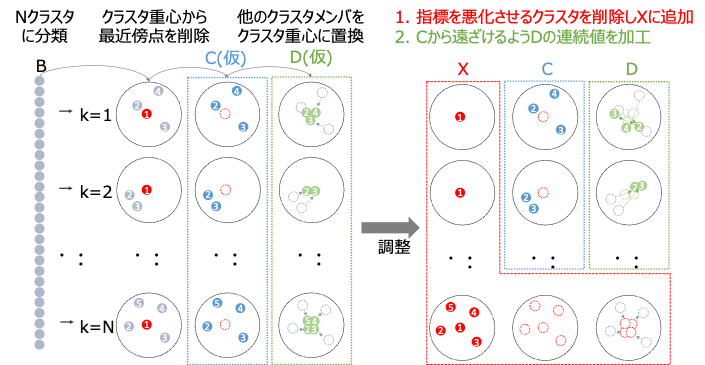
具体的な匿名加工手順
具体的な加工手順は下記の通りです。
- 元データBをKmeans法を用いてクラスタリング
- 各クラスタの代表値(重心)レコードで各クラスタメンバのレコードを置換しB'を作成
- BとB'で有用性指標(Iloss)を計算し、基準を満たさないレコードを削除(※)
- 各クラスタの代表値(重心)の最近傍レコードを削除
- クラスタ毎の採用/不採用に焼きなまし法を実施し、有用性指標(Umark)を満たすように採用するクラスタを決定
- 連続値が元データBと距離が遠くなるようにヒューリスティックに調整し完成
(※注:有用性基準を満たすように全てのレコードをクラスタに割り当てることができれば、ここでの削除は不要ですが、そのような割り当てが難しく、一部基準を満たさないレコードを削除しています。)
焼きなまし法について
PWSCup2021では自チームを含む多くのチームが焼きなまし法(擬似アニーリング法)と呼ばれる方法を利用して、有用性指標を満たすようにデータの調整を行っていました。焼きなまし法とは、最適解を得るための手法の一つで、初期状態からパラメータを変化させて状態を評価し、評価結果が良ければ採用、悪ければ不採用というループを繰り返す方法です。採用する状態の決定において、一定の確率で悪い評価も許容することで局所解に陥ることを防ぐことが期待されます。
ただし、この手法は非常に重い処理になることが多い手法です。我々の環境/データでも、一回の有用性指標の評価には1秒程度の時間がかかり、各クラスタの採用/不採用について評価するためには1ループあたり数分、全採用クラスタを決定するには数時間を要しました。
前述のクラスタリングアルゴリズムで乱数を利用しているため、理想的には複数の乱数シードを用いてクラスタおよび匿名加工データを作成し、その中でより堅牢なデータを選択する、ということをしたかったのですが、焼きなまし法の処理に時間がかかったことから、タイムアップまでになんとか作成できたデータを提出することになりました。
攻撃フェイズ戦略
次に攻撃フェイズの戦略について説明します。
匿名加工フェイズで検討したように、レコードの再識別にはレコード間の距離(類似性)に基づいて、より距離の近いレコードを推定対象とすることが考えられます。
しかしながら、相手チームにおいてもこのような攻撃方法は容易に想定されるため、匿名加工データ作成時に対策が施されている可能性が高いです。サンプリングデータCTのレコードと匿名加工データDのレコードが完全一致しているのにも関わらず、実は削除データXに由来するデータだった、ということも十分に考えられます。
理想としては、レコード間の距離以外の指標(偽装されにくいものほど望ましい)を導入し、その指標に基づいてメンバシップ推定や再識別攻撃を行うことですが、残念ながら自チームではそのような指標を見出すことはできませんでした。
また、他の参加チームの攻撃手法紹介やPWSCup2021結果発表においても、本戦で他チームに対して突出した攻撃成功率を誇るチームや手法はなく、今回のPWSCup2021のルールの下では、そのような攻撃指標は見出されなかったと認識しています。
そのため、我々のチームは、強い匿名加工を施すチームは、有用性指標の限度までデータを加工してくるであろうという仮説を元に攻撃方法を検討しました。
攻撃は、サンプリングデータCTの内、それぞれのレコードが匿名加工の過程において削除/未削除されたかを推定するメンバシップ推定と、未削除レコードが匿名加工データのどのレコードかを当てるレコードリンケージの二段階で行います。
メンバシップ推定
まずはサンプリングデータCTのうち、どのレコードが匿名加工データDに含まれているかを推定します。
結論から申し上げますが、我々のチームでは、メンバシップ推定を行いませんでした。
紆余曲折あったものの、結果的には全件正例(元データBから加工対象データCを作成する過程で削除されていない状態)として回答することにしました。というのも、攻撃スコア算出に利用される指標の定義を考えると、全件正例で回答した場合のRecall*Precsicionの値は、0.5になることが確定します。例えば、レコード間距離のような推定指標を用いてメンバシップ推定の正例負例を50レコードずつ決定する場合、全件正例と同等の値を出すためには、7割以上の確率で正解する必要があります。
メンバシップ推定において、より精度の高い推定方法を検討しましたが、上記水準を超えることができず、有用性基準を満たさない(削除データ由来のサンプリングデータであることが確定する)レコードのみを負例とし、残りのレコードを全て正例と回答することにしました。
ここは工夫点かと思っていたのですが、他の参加チームでも同様の作戦をとっているところが多く、コンテスト巧者からすれば当然の選択だったのかもしれません。
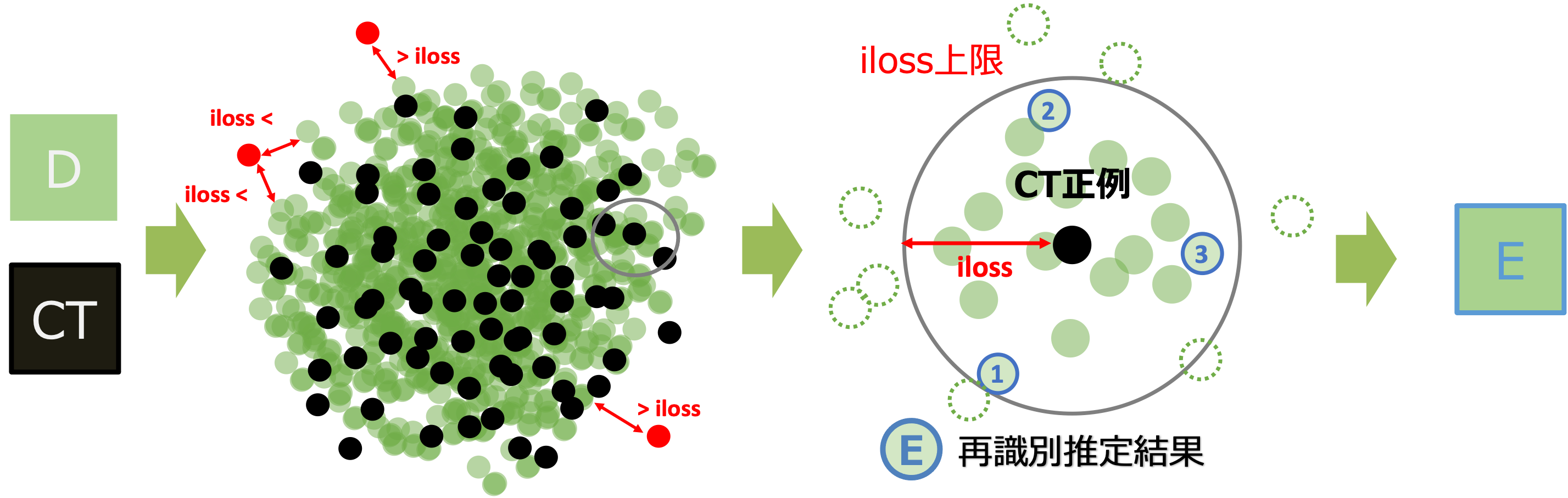
メンバシップ推定のイメージ図
上図は匿名加工データDとサンプリングデータCTのイメージ図です。
サンプリングデータCTに対していずれの匿名加工データDも有用性の基準を満たさない場合には、当該データが加工前のデータCに含まれていることはあり得ませんので負例が確定します。その他のCTについては、全て正例として次のレコードリンケージ(再識別)を行いました。
レコードリンケージ
前述のように強い匿名加工を施すチームは、有用性指標の限度までデータを加工してくるという仮説を元に攻撃方法を検討します。
そのため、まずは予備戦で匿名加工フェイズのスコアが高かったチームの加工の特徴を分析することにしました。
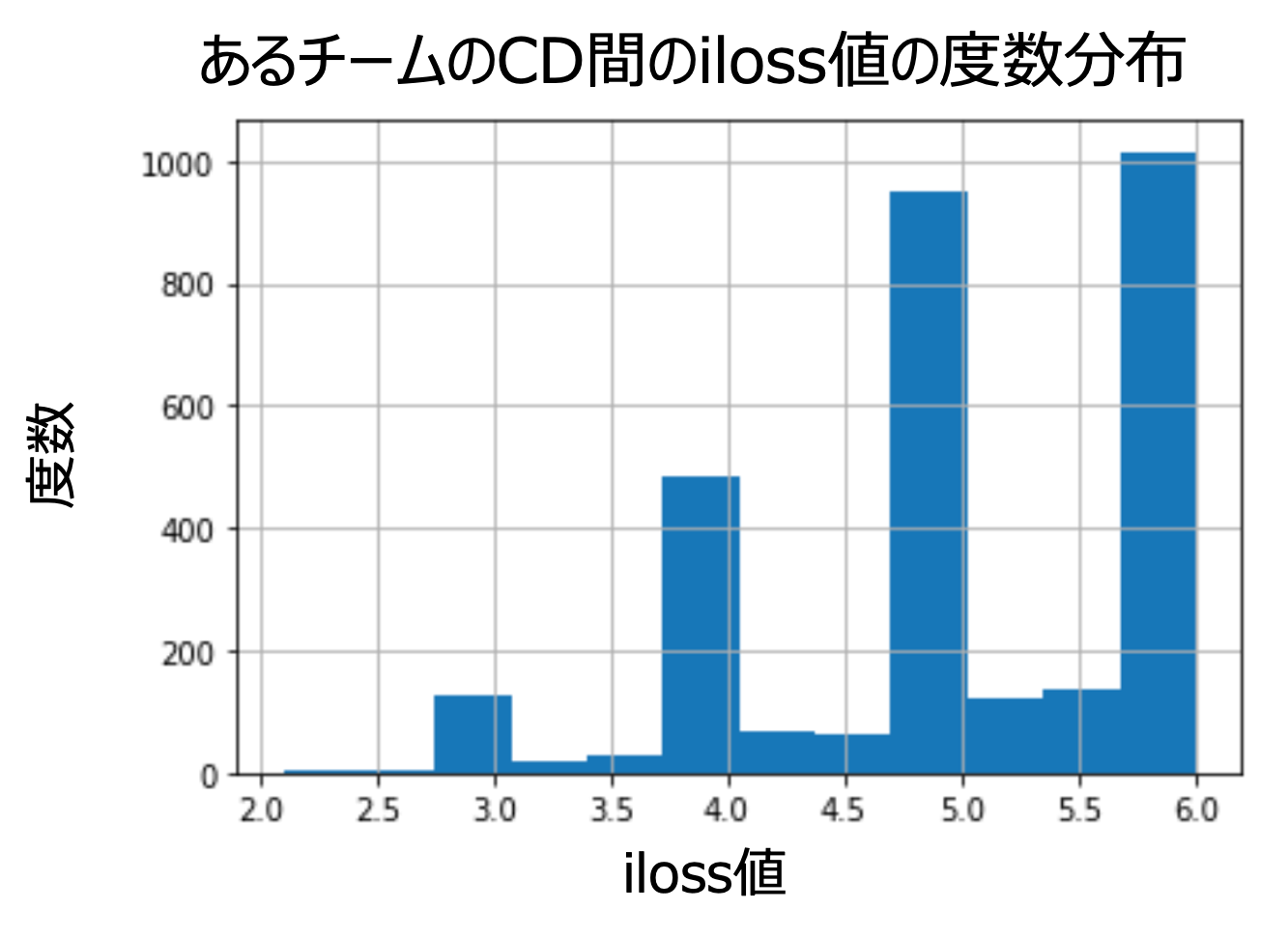
上図は、横軸に匿名加工前後でのレコードあたりの情報変更量(どの程度属性値を変更しているか)、縦軸にレコード数をとったヒストグラムで、あるチームの元データBと匿名加工データDでどの程度データに変更があったかを可視化しています。
予備戦では、データの変更に対する上限値は6(本戦ではより厳しく4に設定変更)で設定されていました。上図において、情報変更量が5から6の領域に多くのレコードが存在することがわかります。つまり匿名加工データDに含まれる多くのレコードが、安全性基準の上限値に近いところまで加工されており、我々の仮説に近いデータの加工傾向が見てとれます。
他のレコードとの距離に依るところもありますが、この状態のデータに対してレコード間距離が近いレコードを再識別対象として推定しても、正解できる可能性は非常に低いということがわかります。
そのため、再識別攻撃の推定レコードは、有用性指標を満たす範囲で最も距離の遠い(最も改変されている)レコードから選択することにしました。しかし、この条件でも候補となるレコードが多数存在します。各レコードの候補として回答できるのは3行までですので、この候補から絞り込みを行う必要があります。
そこで次に、属性情報の置換のしやすさに着目して分析を行いました。
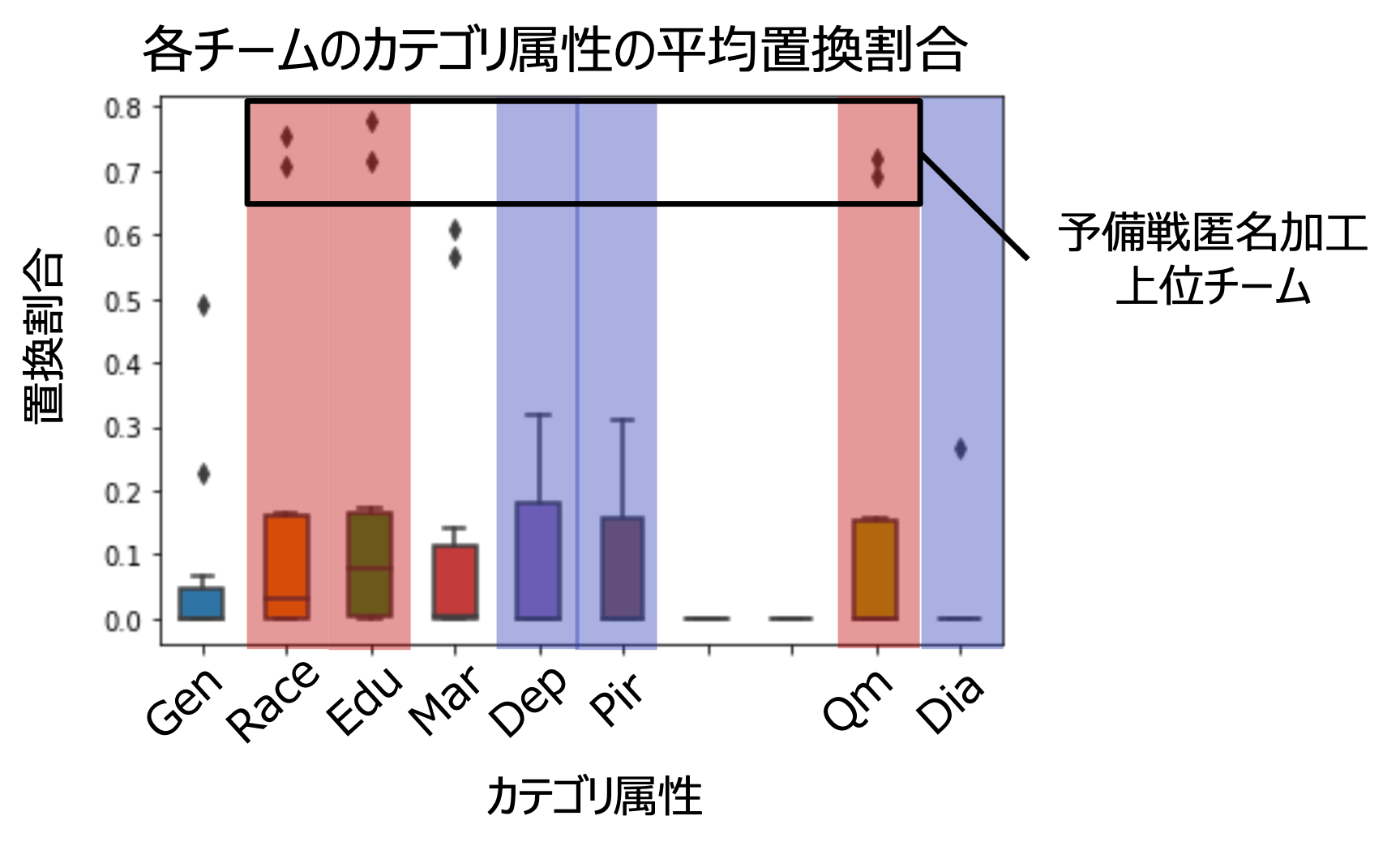
上図は横軸に各カテゴリ属性、縦軸に各チームの匿名加工前後での属性値の置換率をボックスプロットで示したものです。多くのチームでは有用性指標の上限まで加工を施していないためか、各属性での値の置換率に特徴は見られませんでした。一方で、予備戦匿名加工の上位チームにおいては、赤枠で囲んだ属性では置換率が高く、青枠で囲んだ属性では置換率が低いというように、属性毎に置換率が大きく変化している傾向が見てとれます。
属性の置換がIloss(情報量の変化)に与える影響は等価ですが、糖尿病罹患予測へ寄与する影響は異なります。そのため、Ilossの限度まで加工するにしても、他の有用性指標を満たすためには加工しやすい属性と加工しにくい属性があるのではないかと考えました。よって、サンプルデータCTと匿名加工データDから再識別を行う際に、同じIloss上限に近いレコードでも、置換されやすい属性が不一致(置換されている)であり、置換されにくい属性が一致(置換されていない)しているレコードを回答候補として優先するようにルールを設定しました。
より巧妙な匿名加工を施しているチームを想定すれば、逆に置換しにくい属性こそ優先して置換する、という匿名加工戦略も想定されます。しかしながら、有用性の指標の達成がより難しくなるのではないかという予想から、自チームでは上記の戦略を採用しました。
具体的な攻撃手順
攻撃フェイズの方針は決まりましたので、具体的な攻撃手順について説明します。
各チームのサンプリングデータCTおよび、匿名加工データDについて下記の手順で再識別を実施します。
- CTから一行抽出し、Dの全レコードに対してIloss(情報量変化)を算出
- CTとDのいずれのレコードペアにおいてもIloss>4となったCTを負例と判定
- 属性値の置き換えスコアを算出(Race,Education,Qmが一致していればそれぞれ+1、Dep,Pir,Diaが不一致であればそれぞれ−1として総和を取る)
- CTに対するDのIlossで降順ソート
- CTに対する属性値の置き換えスコアで降順ソート
結果のプレゼンテーションで発表されていた手法によると、多くの参加チームで、類似の手法(全件正例でメンバシップ推定、Iloss(情報量変化)の最大からの選択で再識別)を用いて攻撃フェイズにおける推定を行っていました。
一方で、同順位のレコードからどのように再識別対象を選択するかという部分では、自チームが実施した属性値の置換率に着目した順位付けは他の報告例がなくユニークな攻撃方法であったと感じています。
PWSCupの結果について
コンテストの結果は下記のページから公開されています。
コンテスト結果
前述の攻撃戦略が功を奏したのか、本戦では攻撃部門2位を獲得することができました。しかしながら予備戦の影響が大きく、攻撃部門の総合成績は4位となりました。
予備戦匿名加工フェイズの結果分析から、攻撃フェイズの目標としていた匿名加工上位チームにも高い攻撃スコアを得ることができ、堅牢な匿名加工を施すチームに対して高精度で攻撃を成功させるという目標を一部達成できたと考えています。
匿名加工部門の上位チームへの平均攻撃スコアが約0.04でしたので、メンバシップ推定のスコアが0.5だったと仮定すると、再識別攻撃を1割程度当てることができたのかと思います。
また、匿名加工部門の総合成績は7位という結果になりました。本戦では前述の戦略で堅牢な匿名加工を施したつもりになっていましたが、残念ながら相手チームからの攻撃を受けてしまい、上位成績を獲得することはできませんでした。
一方で、PWSCup2021での取り組みや匿名加工技術についてわかりやすく伝えたことが評価され、優秀発表賞を頂戴することができました。

他チームの攻撃/匿名加工手法について
コンテストの結果を見ると多くのチームが類似の手法を用いていたように思います。匿名加工フェイズでは、匿名加工データDと削除データXの置き換えに加えて、有用性を満たすための調整(焼きなまし法)、攻撃フェイズでは有用性の閾値上限からの選択が多く見られました。
今回のコンテストにおいてはこれらの手法が局所解なのかもしれません。数多のチームが互いに異なる過程を経て検討した結果が、いずれも類似しているというのは、このようなコンテストの面白いところかと思います。
ポスターセッションでの議論においても、お互いの手法で類似している部分が多かったためか、オンラインにも関わらず活発な意見交換ができたように思います。
その他、本節ではPWSCup2021で登場した匿名加工/攻撃手法についてご紹介します。
データ生成による匿名加工データ作成
データ生成(合成データ)とは、元のデータセットの統計的特徴と類似するデータセットを生成する技術です。
データ生成方法として、CTGANなどのGAN(敵対的生成NW)を利用した手法が提案されています。
合成データは昨年度のPWSCupやNeurIPSでもテーマに取り上げられており、昨今注目が集まっている分野です。
このような方法を用いることで、元データを直接加工して匿名加工データを作成するのではなく、
元データを利用して新たに類似するデータを生成し、この類似データを用いて匿名加工データを作成することができます。元データと直接紐づかない生成データを作成することができるため、匿名性の高いデータを作成できると期待されています。
元データ参照攻撃
この方法は予備戦で猛威を振るった攻撃方法です。
攻撃フェイズ戦略の節で、今回PWSCupにおいては匿名加工データを高精度で推定する指標は見出されなかった、と記載しましたが、予備戦では高精度でメンバシップ推定及び再識別攻撃を行う方法が発見されておりました。
予備戦では、元データBが各チームで共通であり、公式にアナウンスされていた訳ではありませんでしたが、提出した匿名加工データDの順番が攻撃フェイズでの他チームへの提供時にシャッフルされていない、という状態になっていました。
この状態に気づいたチームは、元データBと匿名加工データDにおいて、レコードの並び順が保存されている、という知見を活用した攻撃を行いました。(残念ながら我々のチームはこの状態に気づくことができませんでした...)
この攻撃は非常に強力でしたが、攻撃者が元データBを参照できる、という仮定が必要になります。
つまり、攻撃者が明らかにしようとしている対象の元データを持っているということになり、
問題設定の意図するところと乖離が生じてしまいます。そのため、本戦においてはこの攻撃方法は禁止(各チームごとに異なる元データを生成し利用)になりました。
他チームの戦略について
資料の公開にご同意されたチームについては、PWSCup2021のHPにて、当日のポスター発表資料が公開されています。
本稿で紹介しきれなかった戦略についても知りたい、という方は是非ご参照ください。
まとめ
最後までお読みいただきありがとうございます。
個人情報を保護しつつ利活用したいというニーズは高まっており、プライバシ保護データ活用技術は今後ますます注目される技術分野であると考えています。
参加メンバが皆思うように時間が取れず、ヒットポイントを削りながら取り組んだにも関わらず、上位入賞を逃してしまったことは非常に悔しく思います。しかしながら実務では貴重な、実データを用いた分析加工技術の習得や、プライバシ保護技術界隈での有識者と議論できる良い機会になったかと思います。
今回の取り組みでは、匿名加工情報の作成に焦点を当てたコンペティションに取り組んできました。類似する技術分野として、暗号化したままデータ分析が可能な秘密計算技術や、隔離された計算リソースで演算を実行するConfidential Computingなど、様々な分野があります。匿名加工技術だけでなく広く見識を深めながら、今後も安心安全なデータ利活用に向けて取り組んでいきたいと思います。