はじめに
在宅勤務が板について久しい昨今ですが,Covid-19前と現在では仕事におけるコミュニケーション手段に大きな変化が生じています.Covid-19前はオフィスに行って仕事の話や雑談は主に音声対話によって行われていましたが,今ではそのほとんどがSlack等のチャットツール上で行われています.これにより,Slack等のチャットツールのデータがかつてないほど蓄積されています.
本記事では,Covid-19以降に大量に蓄積された蓄積されたSlackのデータを用いて,いわゆるPeople Analytics的なことをやっていきたいと思います.具体的には,仕事に対するエンゲージメントをSlackから推定します.在宅勤務になりface-to-faceのコミュニケーションが減少し,同僚や部下のエンゲージメントを把握しづらくなっています(まあ,face-to-faceコミュニケーションなら完全にエンゲージメントを把握できるのかというと,かなり怪しい気もしますが…).エンゲージメントが下がった状態でその人を放置しておくと,バーンアウトといった状態につながり,会社にとっても本人にとっても良くない結果となってしまします.ですから,Slack等のコミュニケーションから仕事へのエンゲージメントを推定する手法を紹介します.
XT部ではどのぐらいSlackを使っているの?
本格的な分析に入る前に,XT部で実際にどれぐらいSlackが利用されているのかを紹介します.
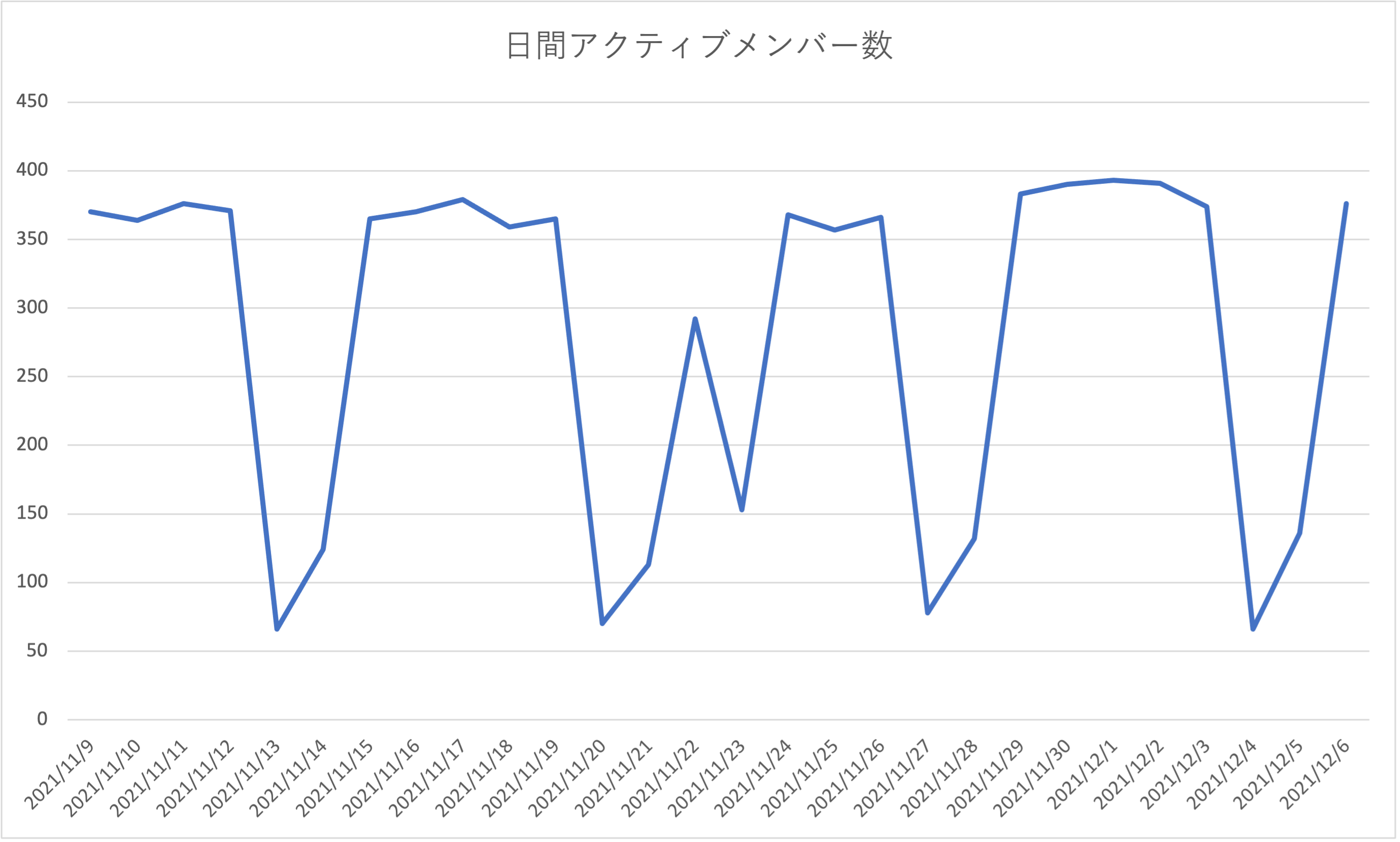
会社の中ではXT部はどちらかといえば小規模な組織で,そのほとんど全員がSlackを利用しています.日によってアクティブなユーザの数は多少の推移がありますが,ここ1ヶ月ぐらいは概ね350--400の間で安定しています.
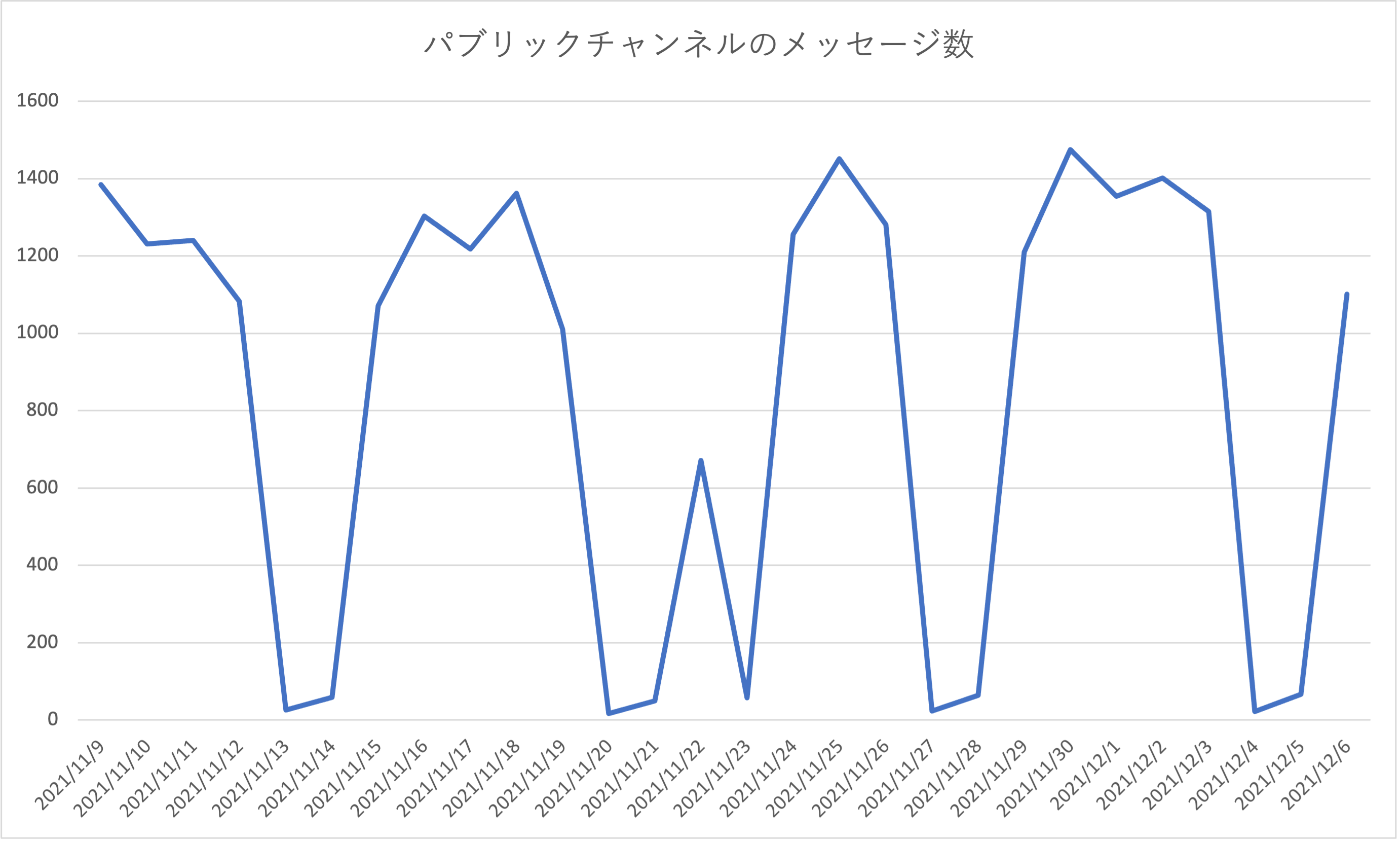
また,平日の日毎のメッセージ数は概ね1200--1400を推移しています.うーん,皆さん結構Slackを使っていますねー
土日祝日のメッセージ数がガクッと落ちていることからも,健全な企業という感じが伝わってきます(休日勤務をする人もいるので完全にゼロではありませんが)
そもそもエンゲージメントってなに?
「仕事へのエンゲージメントってそもそもなに?」や「どうやって計測するの?」といった疑問があると思いますが,これらの問いに対しては組織行動論と呼ばれる分野の知見で回答できます.具体的には,Wilmarら[1]の研究によって仕事に対するエンゲージメントを表す指標としてWork Engagement(以下,WE)が以下のように定義されています:
WEとは,仕事に関するポジティブで充実した心理状態であり,活力,熱意,没頭によって特徴づけられる.エンゲージメントは,特定の対象,出来事,個人,行動などに向けられた一時的な状態ではなく,仕事に向けられた,持続的かつ全体的な感情と認知である.
この記事は組織行動論に関する解説記事ではないので,一旦ここは「なるほど,組織行動論という分野でこういった概念が定式化されているんだな」と認めてもらえればと思います.WEは質問紙調査によって計測可能で,その日本語版に関する研究も行われています.
データセット
今回の記事では,WEをslackのデータから予測するモデルを構築します.そのために,WEの正解データをShimazuら[2]によって提案されている質問紙を用いて計測しました.また,SlackのデータはXT部のワークスペースのパブリックチャンネルから収集し,メンションされている人をメッセージの送り先とみなします.メンションがないメッセージについては,メッセージが投稿されたチャンネルに所属するメンバー全員を送り先とみなします.
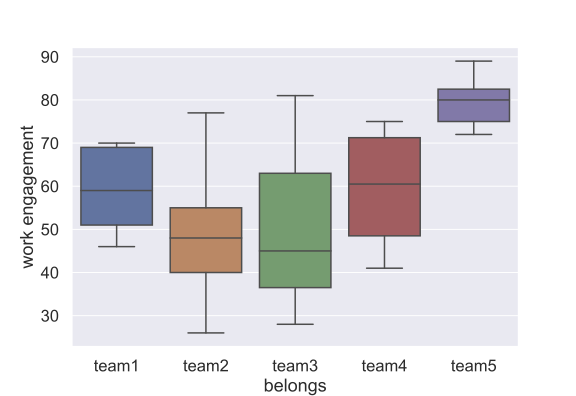
当時のXT部には5つのチームが存在していました.チーム名は匿名化してありますが,各チームのWEのboxplotを数に示します.チーム5に所属するメンバーのWEは高い場所に固まっており,チーム2に所属するメンバーのWEはかなりばらつきがある事が分かります.同じ部署なのに面白いですね.
ちなみに,これは本筋からそれますが,質問紙に回答していただいた方のWEに色をつけて,Slackのメンションネットワーク上(ノードが人を表しており,メンションされている or している人の間にエッジを張っている)で可視化したものが次の図になります.赤に近づくほどWEが高く,青に近づくほどWEが低いことを表します.この図から,WEが高い人がグラフの中心部に集まっているように見え,グラフの中心には次数が高いノードが集まるように可視化しているので,WEが高い人は色々な人とコミュニケーションを取っているのかもしれません.

予測モデルの構築
WEの予測モデルを作っていきますが,今回は各チームへのメッセージ頻度
$$
\frac{\text{チーム}i\text{へのメンション数}}{\text{全てのメンションの数}},\quad i=1, 2, \dots, 5
$$
と,自チームのチーム番号を,ユーザの特徴量として用います.なぜテキストの中身を使わずにメンション情報というメタ的な情報のみを使うかというと,
- やりとりの情報を使うのは,プライバシー的に嫌がる人がいるかもしれないので,メタデータだけからWEを予測できた方が使いやすい
- コミュニティのネットワーク構造の中でどういう位置にいるかという情報の方が,何を話しているかという個別具体的な情報よりも重要そう(「人はネットワークワークの中で生きている」という計算機社会学分野で有名なフレーズからインスパイアされた)
という理由があります.
予測モデルにはLightGBMを使いました.ハイパラのチューニング等は記事が大量にあるので省略しますが,チューニングにはいつも通りOptuna先生にお世話になりました.
予測モデルの評価
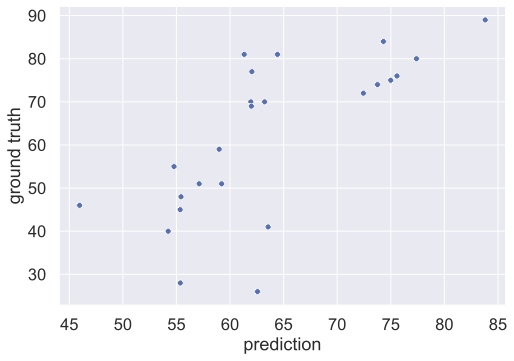
予測モデルの評価については,予測値と実測値の相関係数で行いました.その結果,相関係数$\rho$が0.72であり,帰無仮説が$\rho=0$の統計的仮説検定において帰無仮説を棄却できました(散布図は下図参照).
まとめ
今回の記事では,SlackのやりとりからWork Engagementを推定するという取組を行いました.実は本記事の内容は,自分の論文の一部になっている内容です.Asian CHI Symposium 2021というワークショップでBest Paper Awardを受賞した内容でして,ご興味のある方は是非一度ご覧になっていただければと思います.
また,本記事のような技術を研究したり実用化する際には,「WEが下がっているから,その社員を怒ろう」みたいなことは,決してやってはいけないと考えています.WEが下がっていることを確認したとして,それはその本人を助けるために活用されるべきだと考えています.本記事のようなテーマはどうしてもディストピア的な監視社会につながるような印象を与える場合がありますが,便利な技術というのは使い方次第で不幸な結果を生む可能性は否定できません.ですので,「そういった研究は監視社会につながるからやめた方が良い」という「研究自体の敬遠」はするべきではなく,利用者や提供者それぞれが便利な技術を適正に運用する意思を持ち,そのための仕組みを整備していくことが大事なのではないでしょうか.
ということで,最後にポエムも書いたので,本記事はここで終わりたいと思います!
ここまでご覧いただいた方,ありがとうございました!
参考文献
[1] Schaufeli, W. B., Salanova, M., González-Romá, V., & Bakker, A. B. (2002). The measurement of engagement and burnout: A two sample confirmatory factor analytic approach. Journal of Happiness studies, 3(1), 71-92.
[2] Shimazu, A., Schaufeli, W. B., Kosugi, S., Suzuki, A., Nashiwa, H., Kato, A., ... & Kitaoka‐Higashiguchi, K. (2008). Work engagement in Japan: validation of the Japanese version of the Utrecht Work Engagement Scale. Applied Psychology, 57(3), 510-523.