はじめに
この記事は、C++17時代の並列ソート(C++ Advent Calendar 2017 16日目)の記事の続きです。この記事では、C++17時代の並列安定ソートについて考えます。
2018年9月2日追記
Twitterにて、@yohhyさんが、以下のようにツイートされていました。確かに、Intel C++ Compiler (ICC)及びそのParallelism TSの実装が優秀である可能性は棄却できなかったので、内容を大幅に書き換えました。std::threadについては、良い方法が思いつかなかったのでそのままです…。
C++17時代の並列安定ソート https://t.co/KCw80gW01N ICC(+lib実装)が強いというお話のような あとstd::thread版無駄にスレッドforkしすぎなのでペナルティ大きいね
— yoh (@yohhoy) 2018年2月11日
並列安定ソートとは
高速な安定ソートアルゴリズムとしては、例えばマージソートがよく知られています。マージソートでは、ソート対象の配列の要素数を$ N $とすると、ソート時間のオーダーは(ランダウの記号を使って)、$ O(N\log N) $と書けます。
マージソートは、安定ソートとしては十二分に高速なアルゴリズムであり、残念ながら、これ以上高速な安定ソートアルゴリズムの発明はあまり望めそうにもありません(仮に、マージソート以上に高速な安定ソートアルゴリズムが開発されたとしても、ソート時間のオーダーは$ O(N) $未満にはならないと思います)。
従って、安定ソートの高速化を行うには、マルチコアを使った、マージソートのスレッド並列化が有効でしょう。昨今のCPUには、少なくとも2個以上のCPUコアが内蔵されており、これを活用しない手はありません。
通常のマージソート
マージソートのスレッド並列化を考える前に、まず通常のマージソートの実装について触れておきます。マージソートの詳細な解説は他に譲りますが(例えば参考サイト[1])、例えばマージソートの実装は、以下のコードのようになります。なお、以下のコードは、参考サイト[2]に載っているコードを参考にさせて頂きました。
template < class RandomIter >
//! A template function.
/*!
指定された範囲の要素をマージソートでソートする
\param first 範囲の下限
\param last 範囲の上限
*/
void merge_sort(RandomIter first, RandomIter last)
{
// 部分ソートの要素数
auto const len = std::distance(first, last);
if (len <= 1) {
// 部分ソートの要素数が1個以下なら何もすることはない
return;
}
auto const middle = first + len / 2;
// 下部をソート(再帰)
merge_sort(first, middle);
// 上部をソート(再帰)
merge_sort(middle, last);
// ソートされた下部と上部をマージ
std::inplace_merge(first, middle, last);
}
並列安定ソートの実装
以下で、このマージソートのコードのスレッド並列化を、C++11標準のstd::threadを使った場合、OpenMPを使った場合、Intel® Threading Building Blocks (Intel® TBB)を使った場合、Intel® Cilk™ Plusを使った場合のそれぞれについて試してみたいと思います(マージソートは、再帰処理を別スレッドで実行することで、簡単にスレッド並列化できます)。また、C++17のParallelism TSによるstd::stable_sortにも触れたいと思います。なお、std::thread、OpenMP、Intel® TBB(以下では単にTBBと呼ぶことにします)、Intel® Cilk™ Plus(以下では単にCilkと呼ぶことにします)については、前回の記事で解説済みなので、この記事ではこれらの解説は行わないことにします。
安定ソートのC++11標準のstd::threadによるスレッド並列化
まず、C++11標準に含まれるstd::threadを使ったスレッド並列化(以下では単にstd::threadと呼びます)を試してみましょう。サンプルコードは以下のようになります。なおこのコードは、参考サイト[3]に載っているコードを参考にさせて頂きました。
template < class RandomIter >
//! A template function.
/*!
指定された範囲の要素を安定ソートする(std::threadで並列化)
\param first 範囲の下限
\param last 範囲の上限
*/
inline void stable_sort_thread(RandomIter first, RandomIter last)
{
// 再帰ありの並列安定ソートの関数を呼び出す
stable_sort_thread(first, last, 0);
}
template < class RandomIter >
//! A template function.
/*!
指定された範囲の要素を安定ソートする
\param first 範囲の下限
\param last 範囲の上限
\param reci 現在の再帰の深さ
*/
void stable_sort_thread(RandomIter first, RandomIter last, std::int32_t reci)
{
// 部分ソートの要素数
auto const len = std::distance(first, last);
if (len <= 1) {
// 部分ソートの要素数が1個以下なら何もすることはない
return;
}
// 再帰の深さ + 1
reci++;
// 現在の再帰の深さが閾値以下のときだけ並列化させる
if (reci <= THRESHOLD) {
auto const middle = first + len / 2;
// 下部をソート(別スレッドで実行)
auto th1 = std::thread([first, middle, reci]() { stable_sort_thread(first, middle, reci); });
// 上部をソート(別スレッドで実行)
auto th2 = std::thread([middle, last, reci]() { stable_sort_thread(middle, last, reci); });
// 二つのスレッドの終了を待機
th1.join();
th2.join();
// ソートされた下部と上部をマージ
std::inplace_merge(first, middle, last);
}
else {
// C++標準の安定ソートの関数を呼び出す
std::stable_sort(first, last);
}
}
上記コードの通り、現在の再帰の深さが閾値(上記コードにおけるTHRESHOLD)以下の時だけ、別スレッドで自分自身を呼び出して再帰させ、もしそうでなければ、C++標準の安定ソートの関数を呼び出します(なお、C++標準の安定ソートの関数の実装は、(私が確認した限りでは)単純に再帰を用いたマージソートではないようです)。この閾値については3が良いようです。この値には根拠があり、物理コア数(SMTの有無は関係ないようです)が異なる2台のPCで試行錯誤した結果、こうすると最もパフォーマンスが良くなることが分かりました。
安定ソートのOpenMPによるスレッド並列化
次に、OpenMPを使ったスレッド並列化を試してみましょう。サンプルコードは以下のようになります。なおこのコードは、参考サイト[3]および参考文献[1]に載っているコードを参考にさせて頂きました。
template < class RandomIter >
//! A template function.
/*!
指定された範囲の要素を安定ソートする(OpenMPで並列化)
\param first 範囲の下限
\param last 範囲の上限
*/
inline void stable_sort_openmp(RandomIter first, RandomIter last)
{
# pragma omp parallel // OpenMP並列領域の始まり
# pragma omp single // task句はsingle領域で実行
// 再帰ありの並列安定ソートの関数を呼び出す
stable_sort_openmp(first, last, 0);
}
template < class RandomIter >
//! A template function.
/*!
指定された範囲の要素を安定ソートする(OpenMPで並列化)
\param first 範囲の下限
\param last 範囲の上限
\param reci 現在の再帰の深さ
*/
void stable_sort_openmp(RandomIter first, RandomIter last, std::int32_t reci)
{
// 部分ソートの要素数
auto const len = std::distance(first, last);
if (len <= 1) {
// 部分ソートの要素数が1個以下なら何もすることはない
return;
}
// 再帰の深さ + 1
reci++;
// 現在の再帰の深さが閾値以下のときだけ並列化させる
if (reci <= THRESHOLD) {
auto const middle = first + len / 2;
// 次の関数をタスクとして実行
# pragma omp task
// 下部をソート
stable_sort_openmp(first, middle, reci);
// 次の関数をタスクとして実行
# pragma omp task
// 上部をソート
stable_sort_openmp(middle, last, reci);
// 二つのタスクの終了を待機
# pragma omp taskwait
// ソートされた下部と上部をマージ
std::inplace_merge(first, middle, last);
}
else {
// C++標準の安定ソートの関数を呼び出す
std::stable_sort(first, last);
}
}
安定ソートのTBBによるスレッド並列化
次に、TBBを使ったスレッド並列化を試してみましょう。サンプルコードは以下のようになります。なおこのコードは、参考サイト[3]に載っているコードを参考にさせて頂きました。
template < class RandomIter >
//! A template function.
/*!
指定された範囲の要素を安定ソートする(TBBで並列化)
\param first 範囲の下限
\param last 範囲の上限
*/
inline void stable_sort_tbb(RandomIter first, RandomIter last)
{
// 再帰ありの並列安定ソートの関数を呼び出す
stable_sort_tbb(first, last, 0);
}
template < class RandomIter >
//! A template function.
/*!
指定された範囲の要素を安定ソートする
\param first 範囲の下限
\param last 範囲の上限
\param reci 現在の再帰の深さ
*/
void stable_sort_tbb(RandomIter first, RandomIter last, std::int32_t reci)
{
// 部分ソートの要素数
auto const len = std::distance(first, last);
if (len <= 1) {
// 部分ソートの要素数が1個以下なら何もすることはない
return;
}
// 再帰の深さ + 1
reci++;
// 現在の再帰の深さが閾値以下のときだけ並列化させる
if (reci <= THRESHOLD) {
auto const middle = first + len / 2;
// 二つのラムダ式を別スレッドで実行
tbb::parallel_invoke(
// 下部をソート
[first, middle, reci]() { stable_sort_tbb(first, middle, reci); },
// 上部をソート
[middle, last, reci]() { stable_sort_tbb(middle, last, reci); });
// ソートされた下部と上部をマージ
std::inplace_merge(first, middle, last);
}
else {
// C++標準の安定ソートの関数を呼び出す
std::stable_sort(first, last);
}
}
安定ソートのCilkによるスレッド並列化
次に、Cilkを使ったスレッド並列化を試してみましょう。サンプルコードは以下のようになります。なおこのコードは、参考サイト[4]および参考文献[1]に載っているコードを参考にさせて頂きました。
template < class RandomIter >
//! A template function.
/*!
指定された範囲の要素を安定ソートする(Cilkで並列化)
\param first 範囲の下限
\param last 範囲の上限
*/
inline void stable_sort_cilk(RandomIter first, RandomIter last)
{
// 再帰ありの並列安定ソートの関数を呼び出す
stable_sort_cilk(first, last, 0);
}
template < class RandomIter >
//! A template function.
/*!
指定された範囲の要素を安定ソートする
\param first 範囲の下限
\param last 範囲の上限
\param reci 現在の再帰の深さ
*/
void stable_sort_cilk(RandomIter first, RandomIter last, std::int32_t reci)
{
// 部分ソートの要素数
auto const len = std::distance(first, last);
if (len <= 1) {
// 部分ソートの要素数が1個以下なら何もすることはない
return;
}
// 再帰の深さ + 1
reci++;
// 現在の再帰の深さが閾値以下のときだけ並列化させる
if (reci <= THRESHOLD) {
auto const middle = first + len / 2;
// 下部をソート(別スレッドで実行)
cilk_spawn stable_sort_cilk(first, middle, reci);
// 上部をソート(別スレッドで実行)
cilk_spawn stable_sort_cilk(middle, last, reci);
// 二つのスレッドの終了を待機
cilk_sync;
// ソートされた下部と上部をマージ
std::inplace_merge(first, middle, last);
}
else {
// C++標準の安定ソートの関数を呼び出す
std::stable_sort(first, last);
}
}
C++17のParallelism TSによるstd::stable_sortを使った並列化ソート
C++17から、並列アルゴリズムライブラリ(Parallelism TS)がC++標準のSTLに実装され、並列STLが利用可能になりました。Parallelism TSの解説は他に譲りますが(例えば参考サイト[5])、例えばstd::stable_sortをスレッド並列化して実行するには、以下のコードのように記述します。
std::vector< std::pair<int, int> > v(1000000);
// std::stable_sortをスレッド並列化して実行する
std::stable_sort(std::execution::par, v.begin(), v.end());
2018年7月31日現在、Parallelism TSをサポートしているコンパイラは、**Intel C++ Compiler 18.0と、Microsoft Visual C++ (MSVC) 14.14 (Visual Studio 2017 version 15.7.3)**以降のみです(ただし、Intel C++ Compiler 18.0では、Parallelism TSの利用に、<pstl/algorithm>と<pstl/execution>という、非標準のヘッダファイルをインクルードする必要があります。同様にMSVC 14.14でも、Parallelism TSの利用には、<execution>という、非標準のヘッダファイルのインクルードが必要です)。しかし、実はIntel C++ Compiler 18.0におけるParallelism TSの実装は、Parallel STLという名称でGitHubにてオープンソースで公開されている(ライセンスはApache License 2.0)ので、任意のコンパイラでParallelism TSを試すことができます。
並列安定ソートのパフォーマンス測定
それでは、以上のスレッド並列化された安定ソート関数のパフォーマンス(ソート時間)を、std::stable_sortと比較してみましょう。またあわせて、Parallelism TSによるstd::stable_sortのソート時間も確認していきます。パフォーマンスを測定した環境は、
- CPU: Intel Core i7-7820X (Skylake-X, Hyper Threading ON (物理8コア論理16コア), SpeedStep OFF, Turbo Boost OFF)
- メモリ: DDR4-2666 32GB (8GB×4)
であり、WindowsとLinuxでかなり挙動が異なるため、それぞれ別個に測定し、さらに、両方の環境において、それぞれ二つのコンパイラで測定しました。ここで、配列の要素を100個から1億個まで変化させ、ソートにかかった時間を測定しました。ただし、測定回数は10回とし、その平均を結果としました。Windowsの測定環境は、
- OS: Microsoft Windows 10 Enterprise (64bit)
であり、次の二つのコンパイラで測定しました。
- Microsoft Visual C++ (MSVC) 14.14 (Visual Studio 2017 version 15.7.5) x64ビルド
- Intel Parallel Studio XE 2018 Update 3 (Intel C++ Compiler 18.0 Update 3) on Visual Studio 2017 x64ビルド
また、Linuxの測定環境は
- OS: Linux Mint 18.3 Sylvia (x64)
であり、次の二つのコンパイラで測定しました。
- Clang 6.0.1 (llvm 6.0.0)(コンパイル最適化オプション: -O3 -mtune=native -march=native)
- Intel Parallel Studio XE 2018 Update 3 (Intel C++ Compiler 18.0 Update 3)(コンパイル最適化オプション: -O3 -xHOST -ipo)
また、Windows及びLinuxの両方において、使用しているTBBとParallel STLのバージョンは以下です。
- TBB: Threading Building Blocks 2018 Update 4
- Parallel STL: Parallel STL 20180529 release
Windows - Microsoft Visual C++ (MSVC) 14.14 (Visual Studio 2017 version 15.7.5) の場合
まず、OSがWindowsで、コンパイラがMSVC 14.14 (Visual Studio 2017 version 15.7.5)の場合について述べたいと思います。
完全にシャッフルされたデータをソートする場合
まずは、完全にシャッフルされたデータが詰められた配列の要素をソートする場合のパフォーマンスを測定しました。ここで言う「完全にシャッフルされたデータが詰められた配列」とは、例えば、
auto const n = 1000000;
std::vector< std::pair<int, int> > vec(n);
std::random_device rnd;
auto randengine = std::mt19937(rnd());
std::uniform_int_distribution<int> distribution(1, n / 10);
for (auto i = 0; i < n; i++) {
vec[i] = std::make_pair(distribution(randengine), i);
}
上記のコードのvecのような配列のことです。測定結果を以下の表にまとめました(単位は秒)。
| 配列の要素数 | std::stable_sort | std::thread | TBB | std::stable_sort (MSVC内蔵のParallelism TS) | std::stable_sort (Parallel STLのParallelism TS) |
|---|---|---|---|---|---|
| 100 | 0.0000011 | 0.0026115 | 0.0000671 | 0.0000411 | 0.0000016 |
| 500 | 0.0000052 | 0.0023779 | 0.0000278 | 0.0000293 | 0.0000050 |
| 1000 | 0.0000105 | 0.0021268 | 0.0000212 | 0.0000304 | 0.0000165 |
| 5000 | 0.0000733 | 0.0020665 | 0.0000448 | 0.0000950 | 0.0000397 |
| 10000 | 0.0001511 | 0.0020659 | 0.0000772 | 0.0001351 | 0.0000531 |
| 50000 | 0.0009275 | 0.0024830 | 0.0003096 | 0.0003152 | 0.0001565 |
| 100000 | 0.0019366 | 0.0023855 | 0.0005417 | 0.0005371 | 0.0003142 |
| 500000 | 0.0118314 | 0.0041874 | 0.0029073 | 0.0021368 | 0.0019765 |
| 1000000 | 0.0252828 | 0.0076421 | 0.0063895 | 0.0040965 | 0.0041267 |
| 5000000 | 0.1785216 | 0.0447942 | 0.0432663 | 0.0248951 | 0.0264671 |
| 10000000 | 0.3662624 | 0.0950084 | 0.0953184 | 0.0534481 | 0.0560704 |
| 50000000 | 2.0523977 | 0.5322783 | 0.5254569 | 0.2688943 | 0.3195224 |
| 100000000 | 4.3668062 | 1.0508450 | 1.0545572 | 0.5382259 | 0.6705182 |
これをグラフにすると、以下の図のようになります(両対数グラフであることに注意してください)。
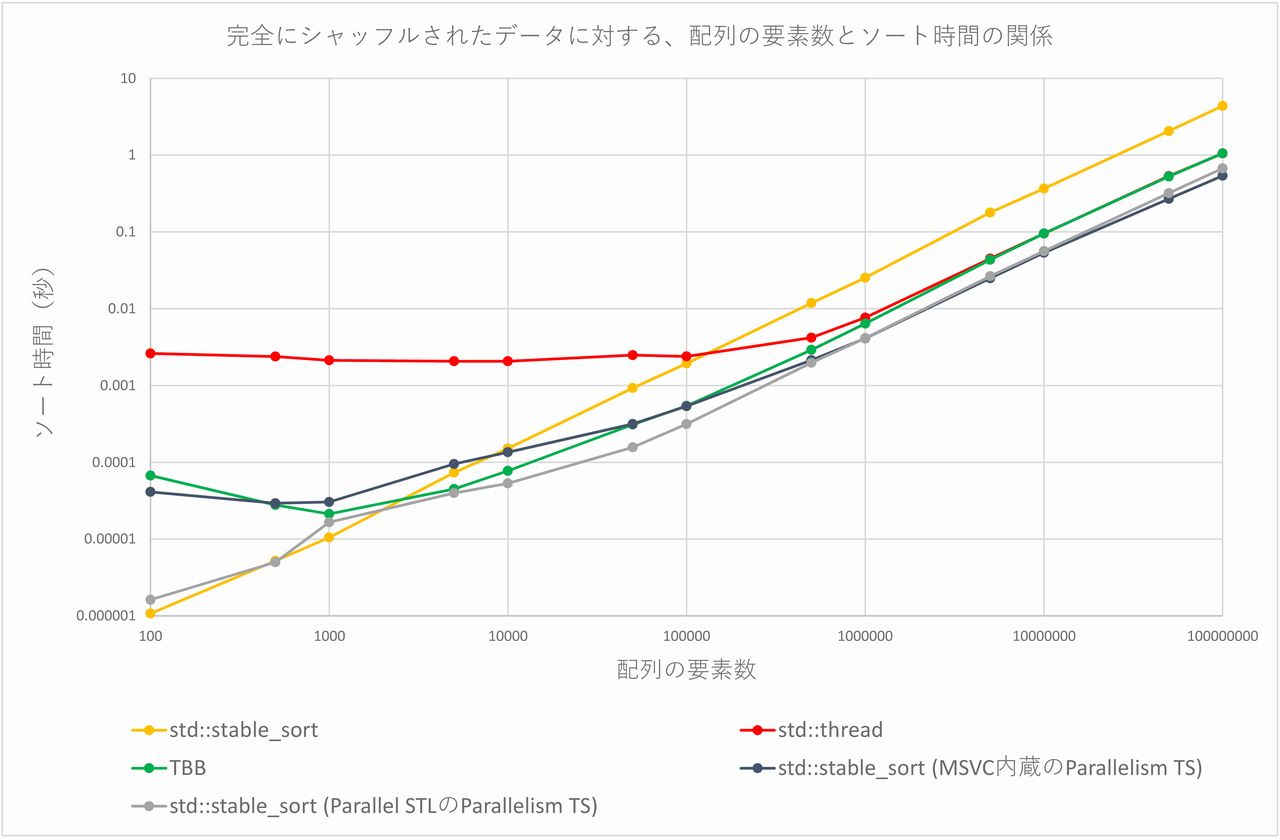
TBBは、配列の要素数が5000個以上でstd::stable_sortよりも高速になります(配列の要素数が100個~1000個の場合は、スレッド生成のコストが高くつくため、std::stable_sortより遅くなっています)。原因は分かりませんが、std::threadはパフォーマンスが悪く、配列の要素数が50万個以上でやっと、std::stable_sortよりも高速になります。std::threadは、配列の要素数100個~10万個で、ソート時間がほとんど変化していないのも不思議です(おそらく、スレッド生成のコストのためだと思われます)。
また、std::threadとTBBは、配列の要素数が500万個以上になると概ね同じような傾向を示します。std::threadとTBBは、配列の要素数が500万個以上では、std::stable_sortよりも4倍前後高速であることが分かります。
MSVC内蔵のParallelism TSのstd::stable_sortは、配列の要素数が1万個以上で通常のstd::stable_sortより高速であり、配列の要素数が5万個以上の場合は、通常のstd::stable_sortよりも3倍弱~8倍強程度高速です。
Parallel STLのParallelism TSのstd::stable_sortは、配列の要素数が5000個以上で通常のstd::stable_sortより高速であり、配列の要素数が5万個以上の場合は、std::stable_sortよりも6倍前後高速です。
また、MSVC内蔵のParallelism TSのstd::stable_sortと、Parallel STLのParallelism TSのstd::stable_sortとを比較すると、配列の要素数が50万個までは後者の方が高速ですが、それ以上の要素数となると前者が高速になる、という興味深い結果が得られています。配列の要素数が1億個の場合、前者は後者より約25%高速です。
あらかじめソートされたデータをソートする場合
極端な場合として、あらかじめソートされたデータが詰められた配列の要素をソートする場合のパフォーマンスを測定しました。ここで言う「あらかじめソートされたデータが詰められた配列」とは、例えば、
auto const n = 1000000;
std::vector< std::pair<int, int> > vec(n);
std::random_device rnd;
auto randengine = std::mt19937(rnd());
std::uniform_int_distribution<int> distribution(1, n / 10);
for (auto i = 0; i < n; i++) {
vec[i] = std::make_pair(distribution(randengine), i);
}
std::stable_sort(vec.begin(), vec.end());
上記のコードのvecのような配列のことです。測定結果を以下の表にまとめました(単位は秒)。
| 配列の要素数 | std::stable_sort | std::thread | TBB | std::stable_sort (MSVC内蔵のParallelism TS) | std::stable_sort (Parallel STLのParallelism TS) |
|---|---|---|---|---|---|
| 100 | 0.0000008 | 0.0021719 | 0.0000045 | 0.0000063 | 0.0000007 |
| 500 | 0.0000035 | 0.0022665 | 0.0000090 | 0.0000192 | 0.0000035 |
| 1000 | 0.0000074 | 0.0020004 | 0.0000095 | 0.0000179 | 0.0000129 |
| 5000 | 0.0000536 | 0.0020720 | 0.0000262 | 0.0000599 | 0.0000322 |
| 10000 | 0.0001061 | 0.0020184 | 0.0000466 | 0.0000858 | 0.0000437 |
| 50000 | 0.0006275 | 0.0019536 | 0.0001785 | 0.0002226 | 0.0001633 |
| 100000 | 0.0014713 | 0.0021245 | 0.0003727 | 0.0003563 | 0.0003002 |
| 500000 | 0.0088359 | 0.0036245 | 0.0020669 | 0.0014269 | 0.0017316 |
| 1000000 | 0.0195887 | 0.0060088 | 0.0047318 | 0.0028093 | 0.0035194 |
| 5000000 | 0.1440418 | 0.0371351 | 0.0341914 | 0.0189277 | 0.0233815 |
| 10000000 | 0.2926114 | 0.0819667 | 0.0799007 | 0.0381445 | 0.0510962 |
| 50000000 | 1.6508358 | 0.4523384 | 0.4528470 | 0.1958574 | 0.2922036 |
| 100000000 | 3.5459284 | 0.9005250 | 0.8989781 | 0.3969237 | 0.6149898 |
これをグラフにすると、以下の図のようになります。

TBBは配列の要素数が5000個以上で、std::stable_sortよりも高速になります(配列の要素数が100個~1000個の場合は、これらはスレッド生成のコストが高くつくため、std::stable_sortより遅くなっています)。std::threadは相変わらずなぜかパフォーマンスが悪く、配列の要素数が50万個以上でやっと、std::stable_sortよりも高速になります。std::threadは、配列の要素数100個~10万個で、ソート時間がほとんど変化していないのも相変わらずです。
std::threadとTBBは、配列の要素数が1000万個以上でよく似た傾向を示します。std::threadおよびTBBは、配列の要素数が1000万個以上で、std::stable_sortよりも3.5倍強~4倍弱高速になっています。
MSVC内蔵のParallelism TSのstd::stable_sortは、配列の要素数が1万個以上で通常のstd::stable_sortより高速であり、配列の要素数が50万個以上の場合は、通常のstd::stable_sortよりも6倍強~9倍弱程度高速です。
Parallel STLのParallelism TSのstd::stable_sortは、配列の要素数が1000個の場合を除いて、std::stable_sortより高速です。配列の要素数が10万個以上の場合、前者は後者より5倍弱~6倍強程度高速となっています。
また、MSVC内蔵のParallelism TSのstd::stable_sortと、Parallel STLのParallelism TSのstd::stable_sortとを比較すると、配列の要素数が10万個までは後者の方が高速ですが、それ以上の要素数となると前者が高速になる、という興味深い結果が得られています。配列の要素数が1億個の場合、前者は後者より約54%高速です。
最初の1/4だけソートされたデータをソートする場合
最後に、最初の1/4だけソートされたデータが詰められた配列の要素をソートする場合のパフォーマンスを測定しました。ここで言う「最初の1/4だけソートされたデータが詰められた配列」とは、例えば、
auto const n = 1000000;
std::vector< std::pair<int, int> > vec(n);
std::random_device rnd;
auto randengine = std::mt19937(rnd());
std::uniform_int_distribution<int> distribution(1, n / 10);
for (auto i = 0; i < n; i++) {
vec[i] = std::make_pair(distribution(randengine), i);
}
std::stable_sort(vec.begin(), vec.begin() + n / 4);
上記のコードのvecのような配列のことです。この配列の要素を500個から1億個まで変化させて、ソートにかかった時間を測定し、結果を下の表にまとめました(単位は秒)。ただし測定回数は10回とし、その平均を結果としました。
| 配列の要素数 | std::stable_sort | std::thread | TBB | std::stable_sort (MSVC内蔵のParallelism TS) | std::stable_sort (Parallel STLのParallelism TS) |
|---|---|---|---|---|---|
| 100 | 0.0000010 | 0.0022033 | 0.0000085 | 0.0000121 | 0.0000010 |
| 500 | 0.0000050 | 0.0021576 | 0.0000106 | 0.0000229 | 0.0000054 |
| 1000 | 0.0000097 | 0.0020028 | 0.0000126 | 0.0000264 | 0.0000150 |
| 5000 | 0.0000699 | 0.0019778 | 0.0000409 | 0.0000681 | 0.0000391 |
| 10000 | 0.0001392 | 0.0020157 | 0.0000627 | 0.0000984 | 0.0000500 |
| 50000 | 0.0008206 | 0.0022561 | 0.0002464 | 0.0002711 | 0.0001767 |
| 100000 | 0.0018484 | 0.0022459 | 0.0005558 | 0.0004637 | 0.0003192 |
| 500000 | 0.0112465 | 0.0041846 | 0.0029794 | 0.0019834 | 0.0018932 |
| 1000000 | 0.0239758 | 0.0074982 | 0.0061861 | 0.0038709 | 0.0040501 |
| 5000000 | 0.1724476 | 0.0449774 | 0.0439685 | 0.0245257 | 0.0254787 |
| 10000000 | 0.3529354 | 0.0958476 | 0.0938564 | 0.0508221 | 0.0549481 |
| 50000000 | 1.9788633 | 0.5245452 | 0.5270426 | 0.2613809 | 0.3120799 |
| 100000000 | 4.1497270 | 1.0439199 | 1.0433895 | 0.5293130 | 0.6556512 |
これをグラフにすると、以下の図のようになります。
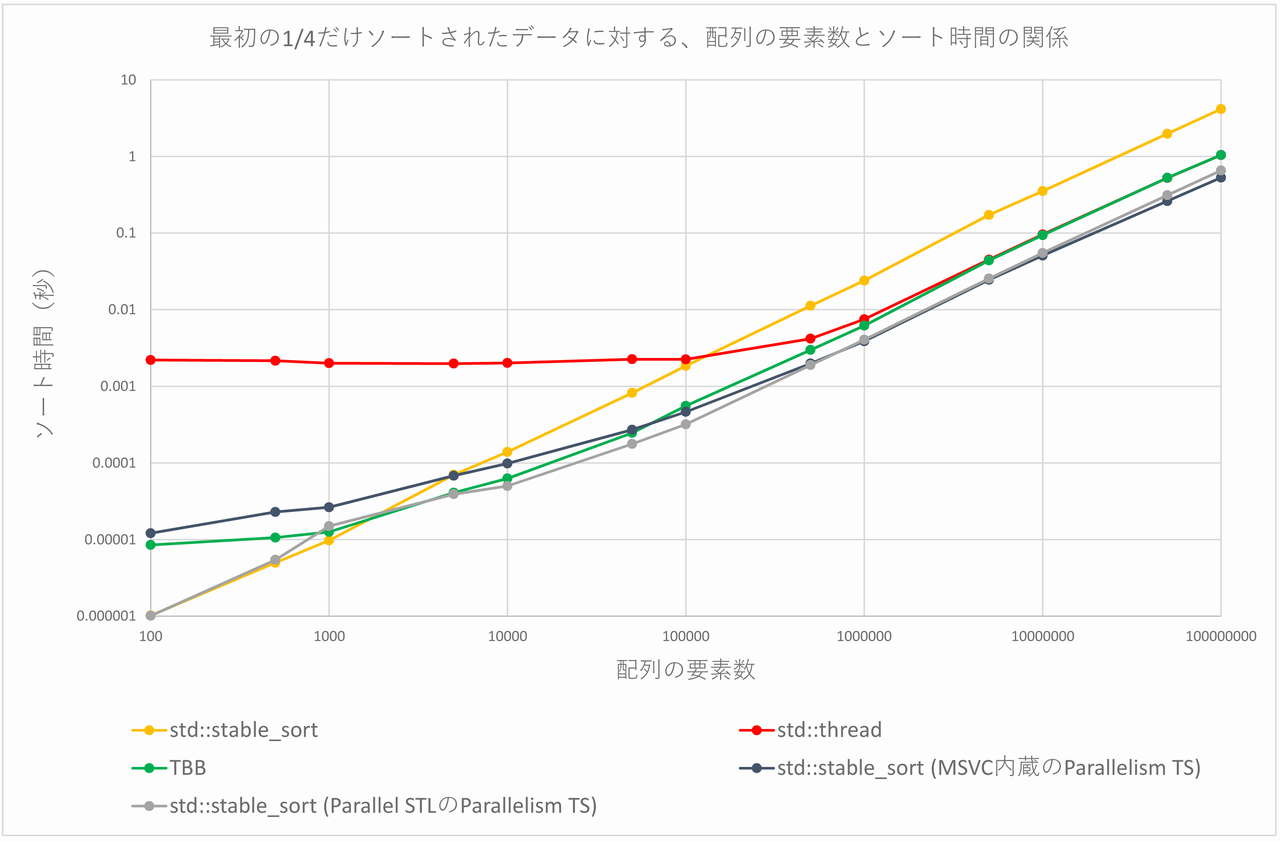
TBBは、配列の要素数が5000個以上でstd::stable_sortよりも高速になります(配列の要素数が100個~1000個の場合は、これらはスレッド生成のコストが高くつくため、std::stable_sortより遅くなっています)。std::threadは相変わらずなぜかパフォーマンスが悪く、配列の要素数が50万個以上でやっと、std::stable_sortよりも高速になります。std::threadは、配列の要素数100個~10万個で、ソート時間がほとんど変化していないのも相変わらずです。
また、std::threadおよびTBBは、配列の要素数が500万個以上になると概ね同じような傾向を示します。std::threadおよびTBBは、配列の要素数が500万個以上では、std::stable_sortよりも4倍弱程度高速であることが分かります。
MSVC内蔵のParallelism TSのstd::stable_sortは、配列の要素数が5000個以上で通常のstd::stable_sortより高速であり、配列の要素数が100万個以上の場合は、通常のstd::stable_sortよりも6倍強~8倍弱程度高速です。
Parallel STLのParallelism TSのstd::stable_sortは、配列の要素数が500個および1000個の場合を除いて、std::stable_sortより高速です。配列の要素数が10万個以上の場合、前者は後者より6倍弱~7倍弱程度高速となっています。
また、MSVC内蔵のParallelism TSのstd::stable_sortと、Parallel STLのParallelism TSのstd::stable_sortとを比較すると、配列の要素数が50万個までは後者の方が高速ですが、それ以上の要素数となると前者が高速になる、という興味深い結果が得られています。配列の要素数が1億個の場合、前者は後者より約24%高速です。
Windows - Intel C++ Compiler 18.0 Update 3 (on Visual Studio 2017)の場合
次に、OSがWindowsで、コンパイラがIntel C++ Compiler 18.0 Update 3 (on Visual Studio 2017)の場合について述べたいと思います。
完全にシャッフルされたデータをソートする場合
まずは、完全にシャッフルされたデータが詰められた配列の要素をソートする場合のパフォーマンスを測定しました(MSVCの場合と同様ですので、コードは省略します)。測定結果を以下の表にまとめました(単位は秒)。
| 配列の要素数 | std::stable_sort | std::thread | OpenMP | TBB | Cilk | std::stable_sort (Parallel STLのParallelism TS) |
|---|---|---|---|---|---|---|
| 100 | 0.0000028 | 0.0024343 | 0.0007652 | 0.0000786 | 0.0004776 | 0.0000017 |
| 500 | 0.0000081 | 0.0028117 | 0.0000215 | 0.0000190 | 0.0000154 | 0.0000081 |
| 1000 | 0.0000169 | 0.0026439 | 0.0000213 | 0.0000188 | 0.0000266 | 0.0000188 |
| 5000 | 0.0001112 | 0.0026608 | 0.0000469 | 0.0000457 | 0.0000868 | 0.0000387 |
| 10000 | 0.0002342 | 0.0026064 | 0.0000788 | 0.0000793 | 0.0001325 | 0.0000573 |
| 50000 | 0.0014391 | 0.0029143 | 0.0003284 | 0.0003362 | 0.0004038 | 0.0002418 |
| 100000 | 0.0023378 | 0.0023932 | 0.0007431 | 0.0008555 | 0.0007382 | 0.0004942 |
| 500000 | 0.0137053 | 0.0049478 | 0.0039294 | 0.0034219 | 0.0037808 | 0.0019197 |
| 1000000 | 0.0290871 | 0.0082519 | 0.0081154 | 0.0071921 | 0.0085777 | 0.0040678 |
| 5000000 | 0.1966980 | 0.0480671 | 0.0517505 | 0.0467189 | 0.0480708 | 0.0261598 |
| 10000000 | 0.3996020 | 0.1004243 | 0.1136648 | 0.0989834 | 0.1034688 | 0.0560094 |
| 50000000 | 2.2135913 | 0.5457411 | 0.6231291 | 0.5453292 | 0.5525160 | 0.3132208 |
| 100000000 | 4.7689131 | 1.1100551 | 1.2893282 | 1.1116285 | 1.1275548 | 0.6558609 |
これをグラフにすると、以下の図のようになります(両対数グラフであることに注意してください)。
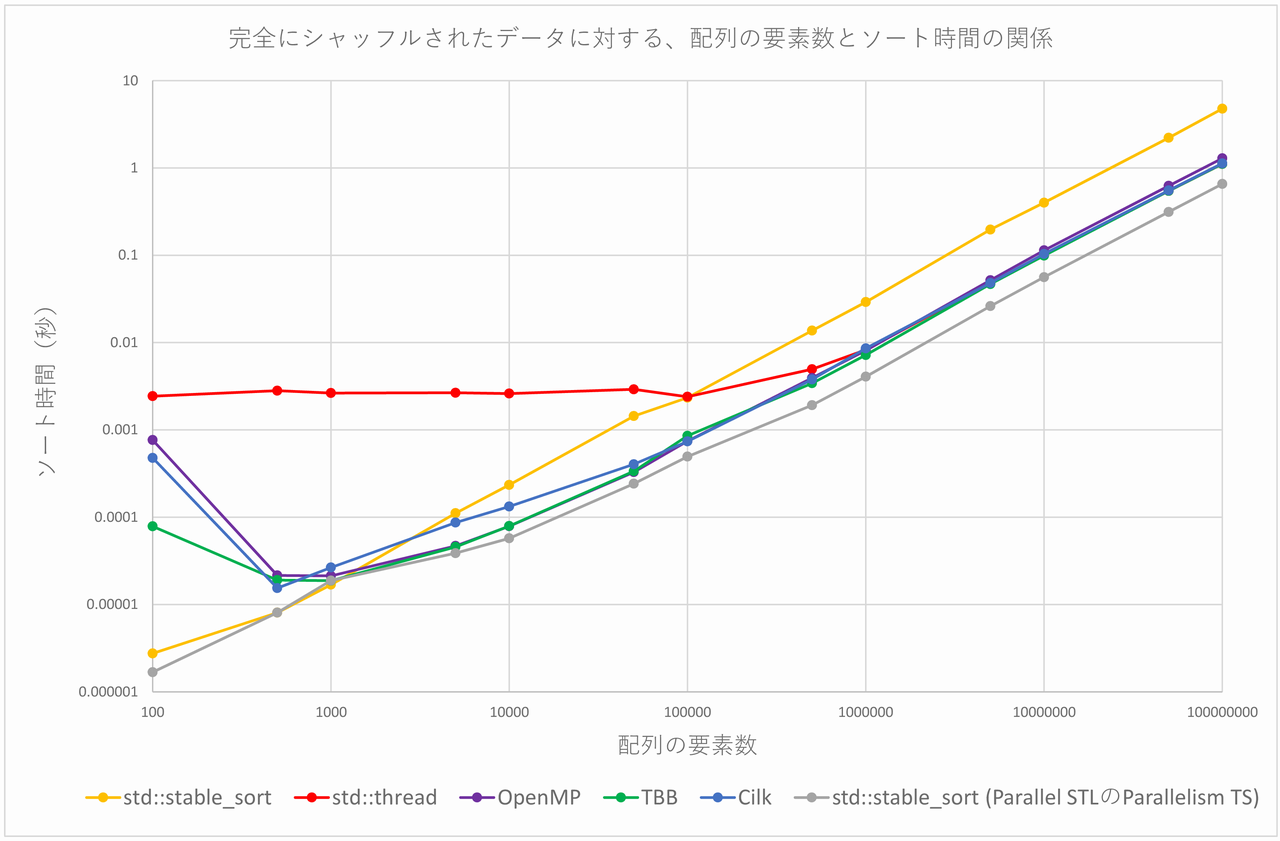
OpenMP、TBB、Cilkは配列の要素数が5000個以上で、std::stable_sortよりも高速になります(配列の要素数が100個~1000個の場合は、これらはスレッド生成のコストが高くつくため、std::stable_sortより遅くなっています)。原因は分かりませんが、std::threadはパフォーマンスが悪く、配列の要素数が50万個以上でやっと、std::stable_sortよりも高速になります。std::threadは、配列の要素数100個~10万個で、ソート時間がほとんど変化していないのも不思議です(おそらく、スレッド生成のコストのためだと思われます)。
また、OpenMP、TBBは、配列の要素数が5000個以上で概ね同じような傾向を示し、配列の要素数が10万個以上では、これにCilkが加わります。加えて、配列の要素数が1000万個以上では、さらにこれにstd::threadが加わります。std::thread、OpenMP、TBB、Cilkは、配列の要素数が1000万個以上では、std::stable_sortよりも、3.5倍~4倍強程度高速であることが分かります。ただ、OpenMPは配列の要素数5000万個以上のパフォーマンスがぱっとせず、std::threadに逆転されています。
Parallelism TSのstd::stable_sortは、配列の要素数が1000個の場合を除いて通常のstd::stable_sortより高速です。特に、配列の要素数が5万個以上の場合、前者は後者よりも5倍弱~7.5倍程度高速です。
あらかじめソートされたデータをソートする場合
次に、あらかじめソートされたデータが詰められた配列の要素をソートする場合のパフォーマンスを測定しました(MSVCの場合と同様ですので、コードは省略します)。測定結果を以下の表にまとめました(単位は秒)。
| 配列の要素数 | std::stable_sort | std::thread | OpenMP | TBB | Cilk | std::stable_sort (Parallel STLのParallelism TS) |
|---|---|---|---|---|---|---|
| 100 | 0.0000010 | 0.0025278 | 0.0000241 | 0.0000070 | 0.0000040 | 0.0000012 |
| 500 | 0.0000066 | 0.0024098 | 0.0000116 | 0.0000096 | 0.0000112 | 0.0000061 |
| 1000 | 0.0000130 | 0.0024543 | 0.0000214 | 0.0000123 | 0.0000216 | 0.0000162 |
| 5000 | 0.0000892 | 0.0025811 | 0.0000342 | 0.0000378 | 0.0000735 | 0.0000361 |
| 10000 | 0.0001863 | 0.0025043 | 0.0000612 | 0.0000676 | 0.0001009 | 0.0000525 |
| 50000 | 0.0010895 | 0.0023352 | 0.0002439 | 0.0002422 | 0.0003158 | 0.0001738 |
| 100000 | 0.0017058 | 0.0021916 | 0.0005659 | 0.0005653 | 0.0005863 | 0.0003187 |
| 500000 | 0.0104512 | 0.0038888 | 0.0028856 | 0.0023875 | 0.0029704 | 0.0017006 |
| 1000000 | 0.0224070 | 0.0066834 | 0.0061044 | 0.0052853 | 0.0060912 | 0.0034883 |
| 5000000 | 0.1583679 | 0.0384794 | 0.0420551 | 0.0376311 | 0.0379392 | 0.0232153 |
| 10000000 | 0.3253611 | 0.0846750 | 0.0951028 | 0.0834605 | 0.0861120 | 0.0503459 |
| 50000000 | 1.8031218 | 0.4607694 | 0.5266053 | 0.4715529 | 0.4706979 | 0.2814851 |
| 100000000 | 3.8835950 | 0.9299866 | 1.0593142 | 0.9262875 | 0.9366599 | 0.5908954 |
これをグラフにすると、以下の図のようになります。

TBBは配列の要素数が1000個以上で、OpenMPとCilkは配列の要素数が5000個以上で、std::stable_sortよりも高速になります(配列の要素数が100個~500個あるいは1000個の場合は、これらはスレッド生成のコストが高くつくため、std::stable_sortより遅くなっています)。std::threadは相変わらずなぜかパフォーマンスが悪く、配列の要素数が50万個以上でやっと、std::stable_sortよりも高速になります。また、std::threadは、配列の要素数100個~10万個で、ソート時間がほとんど変化していないのも相変わらずです。
また、OpenMP、TBBは、配列の要素数が5000個以上で概ね同じような傾向を示し、配列の要素数が10万個以上では、これにCilkが加わります。加えて、配列の要素数が1000万個以上では、さらにこれにstd::threadが加わります。std::thread、OpenMP、TBB、Cilkは、配列の要素数が1000万個以上では、std::stable_sortよりも、3.5倍弱~4倍強程度高速であることが分かります。ただ、OpenMPは配列の要素数5000万個以上のパフォーマンスがぱっとせず、std::threadに逆転されています。
Parallelism TSのstd::stable_sortは、配列の要素数が100個および1000個の場合を除いて通常のstd::stable_sortより高速です。特に、配列の要素数が5万個以上の場合、前者は後者よりも5.5倍弱~7倍弱程度高速です。
最初の1/4だけソートされたデータをソートする場合
最後に、最初の1/4だけソートされたデータが詰められた配列の要素をソートする場合のパフォーマンスを測定しました(MSVCの場合と同様ですので、コードは省略します)。測定結果を以下の表にまとめました(単位は秒)。
| 配列の要素数 | std::stable_sort | std::thread | OpenMP | TBB | Cilk | std::stable_sort (Parallel STLのParallelism TS) |
|---|---|---|---|---|---|---|
| 100 | 0.0000013 | 0.0020534 | 0.0000239 | 0.0000066 | 0.0000050 | 0.0000015 |
| 500 | 0.0000079 | 0.0024445 | 0.0000168 | 0.0000115 | 0.0000140 | 0.0000077 |
| 1000 | 0.0000166 | 0.0026528 | 0.0000236 | 0.0000146 | 0.0000242 | 0.0000190 |
| 5000 | 0.0001056 | 0.0024328 | 0.0000403 | 0.0000428 | 0.0000766 | 0.0000400 |
| 10000 | 0.0002247 | 0.0026112 | 0.0000713 | 0.0000747 | 0.0001145 | 0.0000619 |
| 50000 | 0.0013051 | 0.0025520 | 0.0003050 | 0.0003151 | 0.0003658 | 0.0002016 |
| 100000 | 0.0021368 | 0.0024806 | 0.0007443 | 0.0007487 | 0.0007337 | 0.0003216 |
| 500000 | 0.0128706 | 0.0046529 | 0.0036691 | 0.0031970 | 0.0036925 | 0.0019054 |
| 1000000 | 0.0277495 | 0.0083698 | 0.0082237 | 0.0071353 | 0.0083889 | 0.0038582 |
| 5000000 | 0.1879769 | 0.0475730 | 0.0519138 | 0.0464047 | 0.0470317 | 0.0252200 |
| 10000000 | 0.3844914 | 0.1008541 | 0.1138961 | 0.1000084 | 0.1055175 | 0.0544826 |
| 50000000 | 2.1126191 | 0.5393258 | 0.6168799 | 0.5444908 | 0.5504398 | 0.3034701 |
| 100000000 | 4.5543029 | 1.1146969 | 1.2752200 | 1.1067939 | 1.1236864 | 0.6374640 |
これをグラフにすると、以下の図のようになります。

TBBは配列の要素数が1000個以上で、OpenMPとCilkは配列の要素数が5000個以上で、std::stable_sortよりも高速になります(配列の要素数が100個~500個あるいは1000個の場合は、これらはスレッド生成のコストが高くつくため、std::stable_sortより遅くなっています)。std::threadは相変わらずなぜかパフォーマンスが悪く、配列の要素数が50万個以上でやっと、std::stable_sortよりも高速になります。また、std::threadは、配列の要素数100個~10万個で、ソート時間がほとんど変化していないのも相変わらずです。
また、OpenMP、TBBは、配列の要素数が5000個以上で概ね同じような傾向を示し、配列の要素数が10万個以上では、これにCilkが加わります。加えて、配列の要素数が1000万個以上では、さらにこれにstd::threadが加わります。std::thread、OpenMP、TBB、Cilkは、配列の要素数が1000万個以上では、std::stable_sortよりも、3.5倍弱~4倍強程度高速であることが分かります。ただ、OpenMPは配列の要素数5000万個以上のパフォーマンスがぱっとせず、std::threadに逆転されています。
Parallelism TSのstd::stable_sortは、配列の要素数が100個および1000個の場合を除いて通常のstd::stable_sortより高速です。特に、配列の要素数が5万個以上の場合、前者は後者よりも6.5倍~7.5倍程度高速です。
Linux - Clang 6.0.1 (llvm 6.0.0)の場合
次に、OSがLinuxで、コンパイラがClang 6.0.1 (llvm 6.0.0)の場合について述べたいと思います。
完全にシャッフルされたデータをソートする場合
まずは、完全にシャッフルされたデータが詰められた配列の要素をソートする場合のパフォーマンスを測定しました。測定結果を以下の表にまとめました(単位は秒)。
| 配列の要素数 | std::stable_sort | std::thread | OpenMP | TBB | std::stable_sort (Parallel STLのParallelism TS) |
|---|---|---|---|---|---|
| 100 | 0.0000042 | 0.0002699 | 0.0002484 | 0.0000098 | 0.0000013 |
| 500 | 0.0000091 | 0.0114416 | 0.0000198 | 0.0000199 | 0.0000081 |
| 1000 | 0.0000185 | 0.0004796 | 0.0000229 | 0.0000222 | 0.0000182 |
| 5000 | 0.0001084 | 0.0041875 | 0.0000600 | 0.0000926 | 0.0009587 |
| 10000 | 0.0002383 | 0.0008501 | 0.0000951 | 0.0020551 | 0.0014596 |
| 50000 | 0.0028868 | 0.0025240 | 0.0004484 | 0.0012936 | 0.0029692 |
| 100000 | 0.0028767 | 0.0034530 | 0.0007961 | 0.0019264 | 0.0023556 |
| 500000 | 0.0171434 | 0.0045218 | 0.0045673 | 0.0066249 | 0.0013887 |
| 1000000 | 0.0326480 | 0.0093069 | 0.0098487 | 0.0089216 | 0.0028205 |
| 5000000 | 0.2178053 | 0.0685428 | 0.0721122 | 0.0672707 | 0.0210134 |
| 10000000 | 0.4522254 | 0.1540057 | 0.1662819 | 0.1533819 | 0.0459579 |
| 50000000 | 2.4523511 | 0.8305380 | 0.9459534 | 0.8279470 | 0.2646077 |
| 100000000 | 5.2052429 | 1.6590719 | 1.9130576 | 1.6582086 | 0.5622037 |
これをグラフにすると、以下の図のようになります。

Windowsの場合と比べて、ばらついた結果となっています。
最も安定して高速なのはOpenMPであり、OpenMPは、配列の要素数が5000個以上で、std::stable_sortよりも高速になります(配列の要素数が100個および1000個の場合は、これらはスレッド生成のコストが高くつくため、std::stable_sortよりも遅くなっています)。またTBBは、配列の要素数が5万個以上でstd::stable_sortより高速となります。そして、std::threadについては、Windowsの場合と同様になぜかパフォーマンスが悪く、配列の要素数が50万個以上で、やっとstd::stable_sortよりも高速になります(配列の要素数が5万個の場合は例外です)。
また、std::threadとOpenMPは、配列の要素数が50万個以上になると概ね同じような傾向を示し、配列の要素数が100万個以上では、これにTBBが加わります。std::thread、OpenMP、TBBは、配列の要素数が100万個以上では、std::stable_sortよりも3倍弱~3.5倍強程度高速であることが分かります。ただ、OpenMPは配列の要素数100万個以上のパフォーマンスがぱっとせず、std::threadに逆転されています。
Parallel STLのParallelism TSのstd::stable_sortは、配列の要素数100個~1000個の場合を例外とすると、配列の要素数が50万個以上で、通常のstd::stable_sortより高速になります。そして、Parallel STLのParallelism TSのstd::stable_sortは、配列の要素数が50万個以上では、通常のstd::stable_sortよりも9倍強~12倍強程度高速です。
あらかじめソートされたデータをソートする場合
次に、あらかじめソートされたデータが詰められた配列の要素をソートする場合のパフォーマンスを測定しました(Windowsの場合と同様ですので、コードは省略します)。
| 配列の要素数 | std::stable_sort | std::thread | OpenMP | TBB | std::stable_sort (Parallel STLのParallelism TS) |
|---|---|---|---|---|---|
| 100 | 0.0000030 | 0.0003019 | 0.0002182 | 0.0000050 | 0.0000010 |
| 500 | 0.0000074 | 0.0051950 | 0.0000168 | 0.0000099 | 0.0000067 |
| 1000 | 0.0000151 | 0.0004664 | 0.0000320 | 0.0000185 | 0.0000149 |
| 5000 | 0.0000707 | 0.0048394 | 0.0002182 | 0.0000960 | 0.0000815 |
| 10000 | 0.0001985 | 0.0085996 | 0.0000678 | 0.0008084 | 0.0037916 |
| 50000 | 0.0023106 | 0.0018623 | 0.0002959 | 0.0025833 | 0.0060654 |
| 100000 | 0.0022983 | 0.0034753 | 0.0006066 | 0.0035684 | 0.0073107 |
| 500000 | 0.0127995 | 0.0037070 | 0.0034771 | 0.0049181 | 0.0021441 |
| 1000000 | 0.0270117 | 0.0079515 | 0.0078500 | 0.0074855 | 0.0022344 |
| 5000000 | 0.1896785 | 0.0611827 | 0.0648100 | 0.0602991 | 0.0183753 |
| 10000000 | 0.3928091 | 0.1436042 | 0.1564120 | 0.1415115 | 0.0405805 |
| 50000000 | 2.1148438 | 0.7841555 | 0.8847548 | 0.7866273 | 0.2354345 |
| 100000000 | 4.5191925 | 1.5708433 | 1.7876409 | 1.5692360 | 0.5035276 |
これをグラフにすると、以下の図のようになります。

これもWindowsの場合と比べると、結果がばらついています。
最も安定して高速なのはOpenMPであり、OpenMPは、配列の要素数が5000個以上で、std::stable_sortよりも高速になります(配列の要素数が100個および1000個の場合は、これらはスレッド生成のコストが高くつくため、std::stable_sortよりも遅くなっています)。またTBBは、配列の要素数が5万個以上でstd::stable_sortより高速となります(配列の要素数5000個の場合は例外です)。そして、std::threadについては、Windowsの場合と同様になぜかパフォーマンスが悪く、配列の要素数が50万個以上で、やっとstd::stable_sortよりも高速になります(配列の要素数が5万個の場合は例外です)。
また、std::threadとOpenMPは、配列の要素数が50万個以上になると概ね同じような傾向を示し、配列の要素数が100万個以上では、これにTBBが加わります。std::thread、OpenMP、TBBは、配列の要素数が100万個以上では、std::stable_sortよりも2.5倍強~3.5倍強程度高速であることが分かります。ただ、OpenMPは配列の要素数500万個以上のパフォーマンスがぱっとせず、std::threadに逆転されています。
Parallel STLのParallelism TSのstd::stable_sortは、配列の要素数100個~1000個の場合を例外とすると、配列の要素数が10万個以上で、通常のstd::stable_sortより高速になります。そして、Parallel STLのParallelism TSのstd::stable_sortは、配列の要素数が50万個以上では、通常のstd::stable_sortよりも9倍弱~12倍強程度高速です。
最初の1/4だけソートされたデータをソートする場合
最後に、最初の1/4だけソートされたデータが詰められた配列の要素をソートする場合のパフォーマンスを測定しました(Windowsの場合と同様ですので、コードは省略します)。
| 配列の要素数 | std::stable_sort | std::thread | OpenMP | TBB | std::stable_sort (Parallel STLのParallelism TS) |
|---|---|---|---|---|---|
| 100 | 0.0000014 | 0.0002584 | 0.0003095 | 0.0000073 | 0.0000013 |
| 500 | 0.0000089 | 0.0028603 | 0.0000167 | 0.0000124 | 0.0000079 |
| 1000 | 0.0000176 | 0.0006920 | 0.0000194 | 0.0000140 | 0.0000168 |
| 5000 | 0.0001051 | 0.0016110 | 0.0000451 | 0.0000440 | 0.0000779 |
| 10000 | 0.0002295 | 0.0009714 | 0.0000864 | 0.0002801 | 0.0005824 |
| 50000 | 0.0012765 | 0.0018135 | 0.0003643 | 0.0011229 | 0.0021124 |
| 100000 | 0.0027272 | 0.0035000 | 0.0007190 | 0.0017697 | 0.0022651 |
| 500000 | 0.0164990 | 0.0042929 | 0.0040529 | 0.0056731 | 0.0013547 |
| 1000000 | 0.0311844 | 0.0090062 | 0.0090693 | 0.0085631 | 0.0026479 |
| 5000000 | 0.2107174 | 0.0668972 | 0.0701089 | 0.0662209 | 0.0204921 |
| 10000000 | 0.4394317 | 0.1506196 | 0.1659428 | 0.1484146 | 0.0437576 |
| 50000000 | 2.3798534 | 0.8260514 | 0.9395964 | 0.8265195 | 0.2572223 |
| 100000000 | 5.0570558 | 1.6553056 | 1.8786694 | 1.6590271 | 0.5409205 |
これをグラフにすると、以下の図のようになります。

これもWindowsの場合と比べると、結果がばらついています。
最も安定して高速なのはOpenMPであり、OpenMPは、配列の要素数が5000個以上で、std::stable_sortよりも高速になります(配列の要素数が100個および1000個の場合は、これらはスレッド生成のコストが高くつくため、std::stable_sortよりも遅くなっています)。またTBBは、配列の要素数が5万個以上でstd::stable_sortより高速となります(配列の要素数1000個および5000個の場合は例外です)。そして、std::threadについては、Windowsの場合と同様になぜかパフォーマンスが悪く、配列の要素数が50万個以上で、やっとstd::stable_sortよりも高速になります。
また、std::threadとOpenMPは、配列の要素数が50万個以上になると概ね同じような傾向を示し、配列の要素数が100万個以上では、これにTBBが加わります。std::thread、OpenMP、TBBは、配列の要素数が100万個以上では、std::stable_sortよりも2.5倍強~3.5倍強程度高速であることが分かります。ただ、OpenMPは配列の要素数100万個以上のパフォーマンスがぱっとせず、std::threadに逆転されています。
Parallel STLのParallelism TSのstd::stable_sortは、配列の要素数が1万個および5万個の場合を除いて、通常のstd::stable_sortより高速です。そして、Parallel STLのParallelism TSのstd::stable_sortは、配列の要素数が50万個以上では、通常のstd::stable_sortよりも9倍強~12倍強程度高速です。
Linux - Intel C++ Compiler 18.0 Update 3の場合
次に、OSがLinuxで、コンパイラがIntel C++ Compiler 18.0 Update 3の場合について述べたいと思います。
完全にシャッフルされたデータをソートする場合
まずは、完全にシャッフルされたデータが詰められた配列の要素をソートする場合のパフォーマンスを測定しました。測定結果を以下の表にまとめました(単位は秒)。
| 配列の要素数 | std::stable_sort | std::thread | OpenMP | TBB | Cilk | std::stable_sort (Parallel STLのParallelism TS) |
|---|---|---|---|---|---|---|
| 100 | 0.0000020 | 0.0002902 | 0.0001342 | 0.0000100 | 0.0000438 | 0.0000018 |
| 500 | 0.0000112 | 0.0080094 | 0.0000179 | 0.0000141 | 0.0000383 | 0.0000125 |
| 1000 | 0.0000243 | 0.0050901 | 0.0000217 | 0.0000188 | 0.0000342 | 0.0000248 |
| 5000 | 0.0001319 | 0.0029801 | 0.0000621 | 0.0000916 | 0.0000951 | 0.0009155 |
| 10000 | 0.0002762 | 0.0014744 | 0.0001365 | 0.0005762 | 0.0001778 | 0.0013228 |
| 50000 | 0.0024027 | 0.0022768 | 0.0009290 | 0.0015045 | 0.0008020 | 0.0031610 |
| 100000 | 0.0032912 | 0.0015548 | 0.0011456 | 0.0015709 | 0.0012082 | 0.0024054 |
| 500000 | 0.0163761 | 0.0062482 | 0.0060270 | 0.0087941 | 0.0063345 | 0.0015730 |
| 1000000 | 0.0346694 | 0.0120389 | 0.0127702 | 0.0120815 | 0.0126348 | 0.0031695 |
| 5000000 | 0.2289409 | 0.0808948 | 0.0867401 | 0.0823682 | 0.0908485 | 0.0233266 |
| 10000000 | 0.4657141 | 0.1821793 | 0.1944595 | 0.1813423 | 0.1901677 | 0.0509413 |
| 50000000 | 2.5260640 | 0.9773687 | 1.0929505 | 0.9770083 | 0.9863234 | 0.2813270 |
| 100000000 | 5.3428762 | 1.9617348 | 2.1972802 | 1.9608014 | 1.9714949 | 0.5906630 |
これをグラフにすると、以下の図のようになります。

コンパイラがClangの場合と同様に、Windowsの場合と比べて、ややばらついた結果となっています。
最も安定して高速なのはOpenMPであり、OpenMPは、配列の要素数が1000個以上で、std::stable_sortよりも高速になります(配列の要素数が100個および500個の場合は、これらはスレッド生成のコストが高くつくため、std::stable_sortよりも遅くなっています)。またOpenMPと同様にTBBも、配列の要素数が1000個以上でstd::stable_sortより高速となります(配列の要素数が1万個の場合は例外です)。Cilkについては、配列の要素数が5000個以上でstd::stable_sortより高速となります。そして、std::threadは、配列の要素数が5万個以上で、std::stable_sortよりも高速になります。
また、OpenMPとCilkは、配列の要素数が10万個以上になると概ね同じような傾向を示し、配列の要素数が50万個以上ではこれにstd::threadが加わり、さらに配列の要素数が100万個以上ではこれにTBBが加わります。std::thread、OpenMP、TBB、Cilkは、配列の要素数が100万個以上では、std::stable_sortよりも2.5倍前後高速であることが分かります(配列の要素数が1000万個以上では、OpenMPのパフォーマンスが若干悪くなっています)。
Parallel STLのParallelism TSのstd::stable_sortは、配列の要素数が10万個以上で、通常のstd::stable_sortより高速になります(配列の要素数が100個の場合は例外です)。そして、Parallel STLのParallelism TSのstd::stable_sortは、配列の要素数が50万個以上で、通常のstd::stable_sortより9倍弱~11倍弱高速です。
あらかじめソートされたデータをソートする場合
次に、あらかじめソートされたデータが詰められた配列の要素をソートする場合のパフォーマンスを測定しました。測定結果を以下の表にまとめました(単位は秒)。
| 配列の要素数 | std::stable_sort | std::thread | OpenMP | TBB | Cilk | std::stable_sort (Parallel STLのParallelism TS) |
|---|---|---|---|---|---|---|
| 100 | 0.0000013 | 0.0002983 | 0.0001380 | 0.0000077 | 0.0000063 | 0.0000018 |
| 500 | 0.0000093 | 0.0033725 | 0.0000152 | 0.0000123 | 0.0000177 | 0.0000091 |
| 1000 | 0.0000196 | 0.0035130 | 0.0007426 | 0.0013010 | 0.0004688 | 0.0003224 |
| 5000 | 0.0001092 | 0.0007608 | 0.0001355 | 0.0001354 | 0.0002872 | 0.0000794 |
| 10000 | 0.0002277 | 0.0007284 | 0.0000952 | 0.0014066 | 0.0007640 | 0.0035261 |
| 50000 | 0.0018535 | 0.0022877 | 0.0004407 | 0.0019628 | 0.0013656 | 0.0046165 |
| 100000 | 0.0025024 | 0.0012134 | 0.0009116 | 0.0012206 | 0.0009220 | 0.0024779 |
| 500000 | 0.0129809 | 0.0053708 | 0.0048942 | 0.0078129 | 0.0051413 | 0.0013314 |
| 1000000 | 0.0275331 | 0.0107424 | 0.0105094 | 0.0106823 | 0.0141371 | 0.0025941 |
| 5000000 | 0.1919668 | 0.0749993 | 0.0762208 | 0.0738974 | 0.0798090 | 0.0206319 |
| 10000000 | 0.3903988 | 0.1690604 | 0.1811576 | 0.1699743 | 0.1760434 | 0.0442615 |
| 50000000 | 2.1112987 | 0.9240587 | 1.0261229 | 0.9227150 | 0.9296763 | 0.2511312 |
| 100000000 | 4.4901949 | 1.8494511 | 2.0299710 | 1.8507081 | 1.8566890 | 0.5243624 |
これをグラフにすると、以下の図のようになります。

これもコンパイラがClangの場合と同様に、Windowsの場合と比べて、ややばらついた結果となっています。
最も安定して高速なのはOpenMPであり、OpenMPは配列の要素数が1万個以上で、std::stable_sortよりも高速になります(配列の要素数が100個~5000個の場合は、これらはスレッド生成のコストが高くつくため、std::stable_sortよりも遅くなっています)。またCilkは、配列の要素数が5万個以上でstd::stable_sortより高速となります。std::threadおよびTBBは、配列の要素数が10万個以上で、std::stable_sortよりも高速になります。
また、OpenMPとCilkは、配列の要素数が10万個以上になると概ね同じような傾向を示し(配列の要素数が100万個の場合は例外です)、配列の要素数が50万個以上ではこれにstd::threadが加わり、さらに配列の要素数が100万個以上ではこれにTBBが加わります。std::thread、OpenMP、TBB、Cilkは、配列の要素数が500万個以上では、std::stable_sortよりも2倍強~2.5倍強程度高速であることが分かります(配列の要素数が1000万個以上では、OpenMPのパフォーマンスが若干悪くなっています)。
Parallel STLのParallelism TSのstd::stable_sortは、配列の要素数が10万個以上で、通常のstd::stable_sortより高速になります(配列の要素数が500個および5000個の場合は例外です)。そして、Parallel STLのParallelism TSのstd::stable_sortは、配列の要素数が50万個以上で、通常のstd::stable_sortより8.5倍弱~10.5倍強高速です。
最初の1/4だけソートされたデータをソートする場合
最後に、最初の1/4だけソートされたデータが詰められた配列の要素をソートする場合のパフォーマンスを測定しました。測定結果を下の表にまとめました(単位は秒)。
| 配列の要素数 | std::stable_sort | std::thread | OpenMP | TBB | Cilk | std::stable_sort (Parallel STLのParallelism TS) |
|---|---|---|---|---|---|---|
| 100 | 0.0000017 | 0.0002687 | 0.0001380 | 0.0000085 | 0.0000084 | 0.0000021 |
| 500 | 0.0000109 | 0.0072554 | 0.0007863 | 0.0003870 | 0.0005002 | 0.0000107 |
| 1000 | 0.0000230 | 0.0011445 | 0.0000345 | 0.0000314 | 0.0000325 | 0.0000241 |
| 5000 | 0.0001268 | 0.0020716 | 0.0000668 | 0.0001539 | 0.0004197 | 0.0007278 |
| 10000 | 0.0002656 | 0.0007889 | 0.0001059 | 0.0004859 | 0.0007577 | 0.0009305 |
| 50000 | 0.0014957 | 0.0063541 | 0.0005617 | 0.0018787 | 0.0094868 | 0.0037320 |
| 100000 | 0.0026061 | 0.0012845 | 0.0010543 | 0.0010724 | 0.0078940 | 0.0029554 |
| 500000 | 0.0154350 | 0.0059731 | 0.0055994 | 0.0054995 | 0.0124223 | 0.0015082 |
| 1000000 | 0.0325561 | 0.0123378 | 0.0119831 | 0.0118902 | 0.0183067 | 0.0030264 |
| 5000000 | 0.2208511 | 0.0797578 | 0.0834784 | 0.0806177 | 0.0869387 | 0.0222961 |
| 10000000 | 0.4490077 | 0.1787169 | 0.1953096 | 0.1803625 | 0.1867398 | 0.0488319 |
| 50000000 | 2.4361120 | 0.9779750 | 1.0879679 | 0.9769515 | 0.9858323 | 0.2720978 |
| 100000000 | 5.1402342 | 1.9615940 | 2.1906579 | 1.9613580 | 1.9670266 | 0.5692198 |
これをグラフにすると、以下の図のようになります。

これもコンパイラがClangの場合と同様に、Windowsの場合と比べて、ややばらついた結果となっています。
最も安定して高速なのはOpenMPであり、OpenMPは配列の要素数が5000個以上で、std::stable_sortよりも高速になります(配列の要素数が100個~1000個の場合は、これらはスレッド生成のコストが高くつくため、std::stable_sortよりも遅くなっています)。std::threadおよびTBBは、配列の要素数が10万個以上で、std::stable_sortよりも高速になります。Cilkはなぜかパフォーマンスが悪く、配列の要素数が50万個以上でやっとstd::stable_sortより高速となります。
また、OpenMPとTBBは、配列の要素数が10万個以上になると概ね同じような傾向を示し、配列の要素数が50万個以上ではこれにstd::threadが加わり、さらに配列の要素数が500万個以上ではこれにCilkが加わります。std::thread、OpenMP、TBB、Cilkは、配列の要素数が500万個以上では、std::stable_sortよりも2倍強~3倍弱程度高速であることが分かります。ただ、配列の要素数が1000万個以上では、OpenMPのパフォーマンスが若干悪くなっており、Cilkに逆転されています。
Parallel STLのParallelism TSのstd::stable_sortは、配列の要素数が50万個以上で、通常のstd::stable_sortより高速になります(配列の要素数が500個の場合は例外です)。そして、Parallel STLのParallelism TSのstd::stable_sortは、配列の要素数が50万個以上で、通常のstd::stable_sortより9倍弱~11倍弱程度高速です。
まとめ
安定ソートを、C++11標準のstd::thread、OpenMP、TBB、Cilkでそれぞれスレッド並列化し、std::stable_sort、C++17のParallelism TSによるstd::stable_sortと速度を比較しました。その結果、C++11標準のstd::thread、OpenMP、TBB、Cilkでスレッド並列化した安定ソートは、特にソート対象の配列の要素数が多い場合に、概ねstd::stable_sortより良好なパフォーマンスを発揮するものの、Parallel STLのParallelism TSによるstd::stable_sortの速度には劣ることがわかりました。そして、Parallel STLのParallelism TSによるstd::stable_sortは、特にソート対象の配列の要素数がある程度多い場合、非常に良好なパフォーマンスを示すことが分かりました。さらに、コンパイラがMSVCの場合、Parallelism TSによるstd::stable_sortについては、Parallel STLの実装と、MSVC内蔵の実装とを比べると、配列の要素数が少ない場合は前者が高速だが、要素数がある閾値を超えると後者の方が高速であることが確かめられました。
従って、要素数が大きい配列を高速にソートしたい場合、Parallel STLが利用できる環境では、Parallel STLのParallelism TSによるstd::stable_sortを積極的に利用するべきだと考えられます。MSVCでは、自身に内蔵のParallelism TSによるstd::stable_sortを利用するのも良いでしょう。C++17のParallelism TSが、早期に各コンパイラに実装されることを期待します。
サンプルコードへのリンク
以上のコードのサンプルは、以下のGitHubリポジトリにアップロードしてあります。二条項BSDライセンスですので、どうぞご自由にご利用ください。
https://github.com/dc1394/parallelstablesort
参考サイト
[1] アルゴリズムとデータ構造編【整列】 第7章 マージソート
[2] C++で様々なソートアルゴリズムを実装する
[3] 分割統治
[4] C/C++ プログラムの変換
[5] Faith and Brave - C++で遊ぼう C++1z 並列アルゴリズムライブラリ
参考文献
[1] 菅原清文 『Cilkがやってきた-C/C++プログラマーのための並列プログラミング言語』 カットシステム(2011)