メーカー研究開発に携わるプログラミング初心者が学んだことを必要最小限にまとめた記事です。
散布図行列
直観的に相関関係がわかるが、見慣れないと難解。
他分野の方への説明には適さないかも。
同分野の方と生データを共有して考察するのには良さそう。
何を表現できるか
複数の変数間の相関関係を表現。
Pythonコード
まずはcsvファイルをインスタンス化する。
今回は日本酒の官能評価データで
日本語が含まれるため、読み込み時に文字コード指定する。
#データ読み込み
#encodingで文字コードを指定すると日本語でもエラー起きない
import pandas as pd
sake = pd.read_csv('/content/drive/MyDrive/data/sake.csv', encoding='shift_jis')
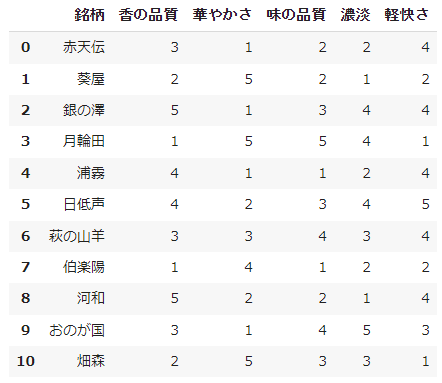
文字化けを避けるために、日本語データを英名へ置き換える。
#matplotlibは日本語で文字化けするので列名を英名へ変更
sake = sake.rename(columns={'銘柄':'Name', '香の品質':'Aroma', '華やかさ':'Splendor', '味の品質':'Flavor', '濃淡':'Tint', '軽快さ':'Lightness'})
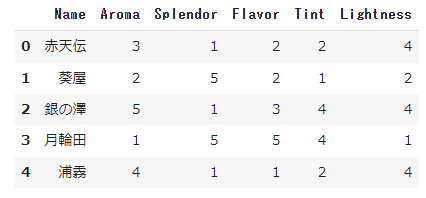
データを整えた後、散布図を作成する。
#散布図作成
import matplotlib.pyplot as plt
x = sake['Aroma']
y = sake['Splendor']
plt.scatter(x, y)
plt.title("scatter")
plt.xlabel("Aroma")
plt.ylabel("Splendor")
plt.grid(True)

近似直線を入れる。
まずは近似式y=ax+bのa,bの値を求める。
#近似直線、1次式y=ax+bのa,bを求める
import numpy as np
a, b = np.polyfit(x, y, 1)
#近似直線の式によって求められるy2に格納
y2 = a * x + b
得られたa,bを使い、近似式を散布図に挿入する。
#散布図に近似直線を追加
fig = plt.figure()
sns.set_style('darkgrid')
ax=fig.add_subplot(111)
ax.scatter(x,y)
#近似式の表示
ax.plot(x, y2, color = 'black')
plt.xlabel('Aroma')
plt.ylabel('Splendor')
plt.title("scatter")
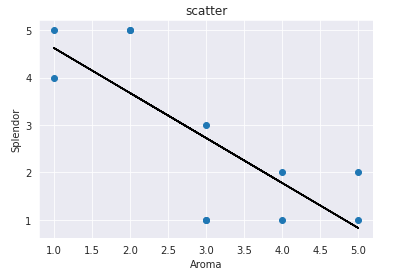
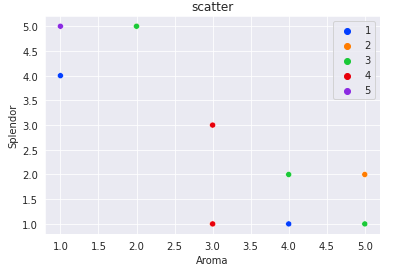
グラフのプロットの色分けをおこなう。
カラーパレットは無数にあるので、好きな色を選ぶ(以下、カラー参考サイト)。
https://medium.com/@morganjonesartist/color-guide-to-seaborn-palettes-da849406d44f
#散布図プロットの色分け
#スタイルのセット
sns.set_style('darkgrid')
#散布図の作成
sns.scatterplot(data = sake, x ='Aroma', y = 'Splendor', hue='Flavor',
palette = 'bright')
#凡例を追加
plt.legend(loc='upper right')
plt.xlabel('Aroma')
plt.ylabel('Splendor')
plt.title("scatter")
散布図行列はsns.pairplot()の1行で作成できる。
#スタイルのセット
sns.set_style('darkgrid')
#散布図行列
sns.pairplot(sake, #グラフにするデータの指定
hue='Aroma', #色分けする属性
palette = 'bright', #グラフの色
height=2 #各図の大きさ
)
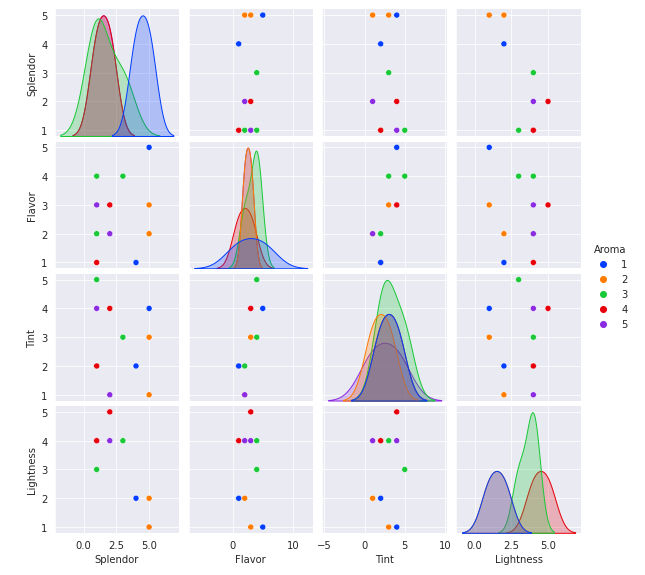
こんなデータに使いたい
複数の属性のうち、相関関係がありそうなデータ。