目標
YoloV2をラズパイに突き刺したNCSで動かすことが目標。本当はyolov2を動かしたかったが、実験したところ、yolov2では内部でConvolution1×1を使用しており、NCSではConvolution1×1に対応していないっぽくてエラーになるのと、なんとか通過させてもNCSを動かすときにメモリを食い過ぎるのかタイムアウトエラーになって予測できなかった。結局このページではtiny-yolov2を動かす。ただ、それだけでは精度がイマイチなのでtiny-yolov2のパラメーターを少し増やして若干の精度向上を図る。
前提
caffeのインストールが完了していること。
ncsdkのインストールは完了していること。
yolov2(darknet)のビルドが完了していること。
ubuntu16.04で実行。
ラズパイ2を使用。
大筋の流れ
- yolov2の本家サイトから、tiny-yoloのcfgファイルとweightファイルをダウンロードする
- 1.でダウンロードしたファイルを変換ツールでcaffeモデルのファイルに変換する
- caffeのファイルをNCS用ファイルに変換する
- 3.のファイルをNCSに取り込む
- NCSでの動作確認をする
- tiny-yoloのパラメーターを変更して再学習、精度向上
- 再学習したデータでNCSでの動作確認をする
やり方
1.変換用ツールのダウンロードとビルド
git clone https://github.com/duangenquan/YoloV2NCS.git
cd YoloV2NCS
※32bit環境でビルドするときはYoloV2NCS/src/PythonWrapper.cppのlong buflenをint buflenに編集する。
make
2. Yoloの本家サイトからyolo-voc.weightとyolo-voc.cfgをダウンロードする
yolo-voc.cfgファイルとyolo-voc.weightsファイルをダウンロードする。
ダウンロードしたファイルはYoloV2NCS/models/yolomodelsの下に保存する。
https://github.com/pjreddie/darknet/blob/master/cfg/tiny-yolo-voc.cfg
https://pjreddie.com/media/files/tiny-yolo-voc.weights
3. caffe用モデルファイルに変換する
cd YoloV2NCS/models
YoloV2NCS/models/convertyo.shを開いて
filename=tiny-yolo-vocをfilename=yolo-vocに変更する
convertyo.shは中で
../python/create_yolo_prototxt.pyと
../python/create_yolo_caffemodel.pyを呼び出している。
python3で動かす場合、
../python/create_yolo_caffemodel.pyはprint文を()付きに直すだけでOK。
../python/create_yolo_prototxt.pyは内部で
ConfigParserをimportしているが、これはpython2.7じゃないと何かエラーになる。
../python/create_yolo_prototxt.pyはcaffeがなくても動くスクリプトなので
自分の環境ではconvertyo.shを以下のように書き換え、
../python/create_yolo_prototxt.pyはpython2.7で、
../python/create_yolo_caffemodel.pyはpython3で動かしている。
python ../python/create_yolo_prototxt.py $yolocfg $yolocfgcaffe
python3 ../python/create_yolo_caffemodel.py -m $yolocfgcaffe -w $yoloweight -o
$yoloweightcaffe
yoloのモデルファイルをcaffeモデルに変換する。
./convertyo.sh
実行時、Region layer is not supported"みたいなエラーが出ても無視してよい。
コマンド終了後、YoloV2NCS/models/caffemodels
にyolo-voc.prototxtとyolo-voc.caffemodelができていれば成功。
4.NCS用ファイルを作成する
mvNCCompile ./caffemodels/yolo-voc.prototxt -w ./caffemodels/yolo-voc.caffemodel -s 12
カレントディレクトリにgraphファイルが吐かれます。
5.NCSで動かす
graphファイルを../detectionExample/にコピーし、detectionExampleに移動してMain.pyを実行する。
cp ./graph ../detectionExample/
cd ../detectionExample/
python3 Main.py --image ../data/dog.jpg
以下の画像が表示されれば成功。
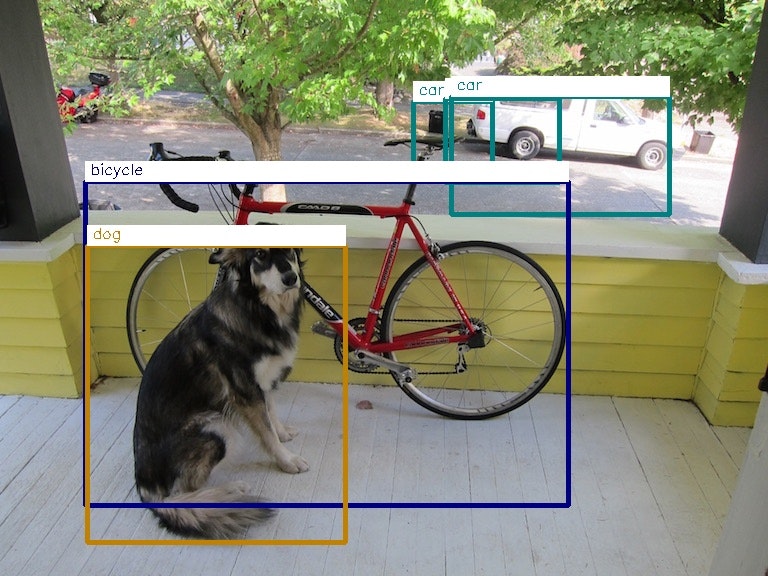
車の矩形が複数あるのはtiny-yolo-v2の精度の問題。これはパラメーターを改善することで以下のように改善できる。tiny-yoloのパラメーターの変更と再学習については後述する。
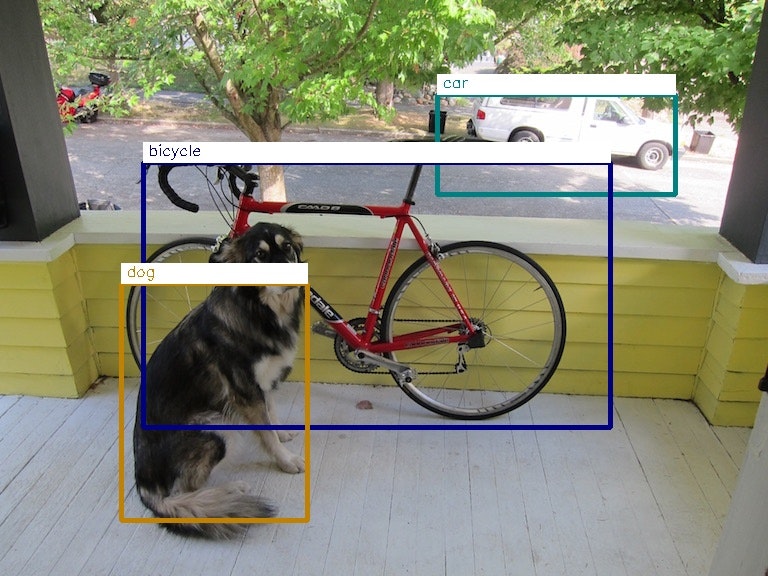
※同じ学習データをを本家のdarknetで実行すると以下のように表示され、微妙に矩形の位置が異なる(自転車のハンドルの高さあたり、車の上下あたりなど)。ObjectWrapper.pyのどこかに不良があるみたいだけど、原因がわかりません。誰かわかったら教えてください。
6.tiny-yolov2のパラメーター変更と再学習
https://pjreddie.com/darknet/yolo/
に記載されているが、手順をまとめておく。
以下を実行して、学習用の画像データをダウンロードする。
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
wget https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
wget https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
tar xf VOCtrainval_11-May-2012.tar
tar xf VOCtrainval_06-Nov-2007.tar
tar xf VOCtest_06-Nov-2007.tar
解凍したデータはdarknet/scriptsの下に全部置く。
ラベル生成用のツールをダウンロードする
wget https://pjreddie.com/media/files/voc_label.py
ダウンロードしたvoc_label.pyもscriptsの下に置く。
以下を実行して、ラベルを生成する。
python voc_label.py
以下を実行して各ラベルを一つのマージする。
cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt
cfg/voc.dataを編集する。
classes= 20(分類するオブジェクトの種類の数。今回は変更なし)
train = <path-to-voc>/train.txt(学習用データ)
valid = <path-to-voc>2007_test.txt(検証用データ)
names = data/voc.names(ラベルの名前)
backup = backup(学習済みデータの保存先。darknetコマンドの下にbackupができる)
tiny-yolo-voc.cfgを編集し、フィルター数を変更する。変更箇所には→を記述している。
[net]
batch=32
subdivisions=8
width=416
height=416
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
max_batches = 160200→学習回数変更
policy=steps
steps=-1,100,20000,30000
scales=.1,10,.1,.1
[convolutional]
batch_normalize=1
filters=32→フィルター数を16→から32に変更
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=64→フィルター数を32→から64に変更
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=128→フィルター数を64→から128に変更
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=256→フィルター数を128→から256に変更
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=512→フィルター数を256→から512に変更
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=1024→フィルター数を512→から1024に変更
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=1
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
###########
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=125
activation=linear
[region]
anchors = 1.08,1.19, 3.42,4.41, 6.63,11.38, 9.42,5.11, 16.62,10.52
bias_match=1
classes=20
coords=4
num=5
softmax=1
jitter=.2
rescore=1
object_scale=5
noobject_scale=1
class_scale=1
coord_scale=1
absolute=1
thresh = .6
random=1
※あまりパラメーター数を増やすと、NCS実行時にタイムアウトを起こす。上に記したパラメーターでNCSを実行すると推測に450ms秒くらいかかる。変更しない場合は250msくらいかかる。
変更後、以下を実行すると学習が始まる。GTX1060で2日くらいかかる。
./darknet detector train cfg/voc.data cfg/tiny-yolo-voc.cfg ./tiny-yolo-voc-final.weights
学習データは随時backupディレクトリに吐かれる。
学習が完了したら、
tiny-yolo-voc-final.weightsをtiny-yolo-voc.weightsにリネームしたものとtiny-yolo-voc.cfgを
YoloV2NCS/models/yolomodelsに上書きして、3.〜5.を再度実行する。
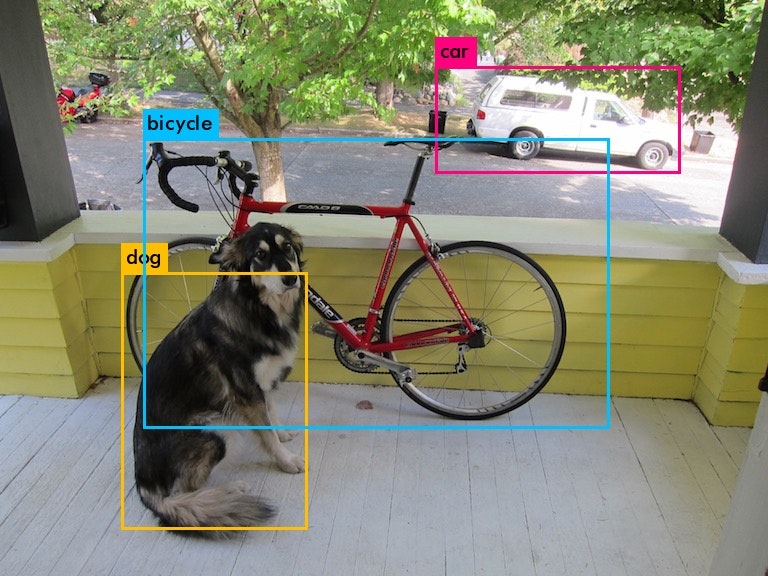
実行したら、以下のようにtiny-yoloでも何とか分類できる。
