はじめに
以下のコードはすべてGoogle Colab ノートブックで共有していますので、実際に1つ1つ実行して試すことができます![]()
重要なこと
時系列データを取り扱う対象として日経平均株価を用いています。株価をプロットして遊んでみるなどしますが、その図を見て投資しろとか言うつもりは全くありません。投資は自己責任で行ってください。
目的
主にDataCampで学んだことの自分のためのまとめとして、Quandl APIを用いた株価推移の観察をやってみます。なお、僕は株は詳しくありません。
Qiitaアカウントを作ってアウトプットするのが一番の勉強になるって話を聞いたので、アウトプット練習も兼ねてます。やさしい先輩方いろいろ教えて下さい![]()
この記事を読んで得られると思われるもの
- Pythonを用いたAPIの叩き方
- 時系列データの処理
- 時系列データの図示
- 日経平均に対する感覚
参考元
日経平均の推移を観察する
Quandl APIを用いて株価を取得する
【準備】
Quandlでアカウントを作成し、APIキーの発給を受けてください。
# 発給されたAPIトークン文字列をいれてください。
API_TOKEN = '____'
Quandl DocumentationのAPIの利用法をもとに日経平均(Nikkei/USD Futures, Continuous Contract #2 (NK2))を取得してみます。時系列データの取得の基本定義が以下の通りなので、このブラケットを埋めるようにAPIを叩きます:
GET https://www.quandl.com/api/v3/datasets/{database_code}/{dataset_code}/data.{return_format}
なお、Quandl Codeを見れば{database_code}/{dataset_code}が何かがわかります。今回の場合はCHRIS/CME_NK2ですね。データはjsonで返してもらおうと思います。最終的に次のようになります:
GET https://www.quandl.com/api/v3/datasets/CHRIS/CME_NK2/data.json?api_key=API_TOKEN
PythonでAPIを叩いてJSONデータを取得してみましょう。
APIを叩いてjsonを受け取るためにrequests.get()を、jsonを辞書に変換するために.json()を用います。
# Quandl codeをいれてください。
QUANDL_CODE = 'CHRIS/CME_NK2'
# 必要なモジュールです。実行してください。
import requests
import json
# エンドポイントを定義する。
url = f'https://www.quandl.com/api/v3/datasets/{QUANDL_CODE}/data.json?api_key={API_TOKEN}'
# JSONデータを受け取り、JSONデータを辞書型に変えます。
catched_response = requests.get(url)
json_data = catched_response.json()
さて、元のjsonデータの構造を見てみると、datasetというキーに対してid, dataset_code,...という値が対応していることがわかります。今回実際に使いたいのはdatasetの中にあるcolumn_namesとdataであることに注意して抜き出しておきましょう。
# 列名リストと値リストを作る
columns = json_data['dataset_data']['column_names']
values = json_data['dataset_data']['data']
データを覗いてみる
データの取得に成功しました![]()
データを表にして覗いていきましょう。すべてが数値であるというわけではないデータを表にするためにpandasを呼び出しておきましょう。
import pandas as pd
データフレームを作っていきます。今回は時系列データを扱うのでcolumnsの1つである'Date'をdatetimeIndexに変えたいと思います。
# データフレームを作成します。日付('Date')をDataTimeIndexにします。
df = pd.DataFrame(values, columns=columns)
df.Date = pd.to_datetime(df.Date)
df.set_index('Date', inplace=True)
何かおかしなデータが入っていたりしないかを確認するために.info()を用いて確認します。
df.info()
2019年9月26日現在、df.info()を実行すると次のような結果が得られます。
| DatetimeIndex | 7310 entries, 2019-09-25 to 1990-09-26 |
| Open | 7118 non-null float64 |
| High | 7284 non-null float64 |
| Low | 7256 non-null float64 |
| Last | 7308 non-null float64 |
| Change | 0 non-null object |
| Settle | 7310 non-null float64 |
| Volume | 7310 non-null float64 |
| Previous Day Open Interest | 7310 non-null float64 |
データは全部で7310個あるようです。始値、高値、低値、終値のどれもfloat64となっており、数値以外が混ざり込んでいるということはなさそうですが、どれも7310 non-null float64ではないため、いくつか欠損値が存在していそうです。実際に中身を見てみましょう。
df.head()
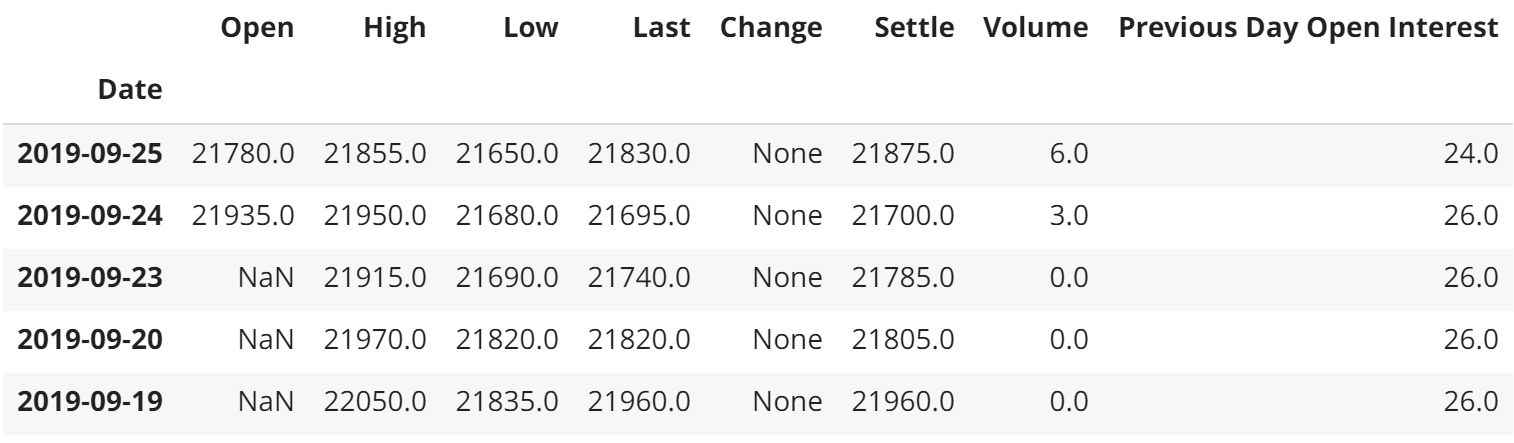
先頭データを読み込んでみることで次のことに気がつきます。
- 日付が降順に並んでいる(スライスで影響してきます。)
- 土日が抜けている
- 9月19日, 20日, 23日と始値がすべてNaNである。
土日が抜けていることは別におかしなことでもないですし問題もないので無視するとして、まずは欠損値の処理をします。
欠損値を処理する
始値、高値、低値、終値それぞれに欠損値があるのでこれらを埋めてみます。
大雑把にそれぞれの欠損値の処理方針を次のように決めます。
- 始値: その日の終値を用いる
- 高値: 直前および直後のNaNではない高値に線形で伸びるとする
- 低値: 直前および直後のNaNではない高値に線形で伸びるとする。ただし始値以下にならない。
- 終値: 直前および直後のNaNではない終値に線形で伸びるとする。ただし高値以上にならない。
それぞれやってみましょう。前日の終値がないために始値が出せないということがないように、高値→終値→始値→低値の順で処理します。
途中でnumpyarray同士を比較して大きい方/小さい方を採用するということを行いますのでnumpyを召喚しておきます。
# 条件付き処理に必要です。実行してください。
import numpy as np
書き方が2つあって気持ち悪いと思います。ごめんなさい![]()
np.minimum, np.maximumはそれぞれnumpyarrayの比較をします。
.interpolate()は欠損値をその欠損値の直前および直後の数値をもとにその間の値で埋めるメソッドです。なお、何も指定しなければlinearにやってくれます。
fillnaは値を指定するとその値で埋めてくれます。
df.High.interpolate(inplace=True)
df.Last = np.minimum(df.Last.interpolate(), df.High)
df.Open.fillna(df.Last, inplace=True)
df.Low = np.maximum(df.Low.interpolate(), df.Open)
本当はdf.Open.fillnaのところ、前日の終値を当て嵌めたかったのですがどうやっていいかわかりませんでした。
さてこれでちゃんと欠損値が埋まったかどうか確認してみましょう。
df.info()
処理の結果、以下のようになりました:
| DatetimeIndex | 7310 entries, 2019-09-25 to 1990-09-26 |
| Open | 7310 non-null float64 |
| High | 7310 non-null float64 |
| Low | 7310 non-null float64 |
| Last | 7310 non-null float64 |
| Change | 0 non-null object |
| Settle | 7310 non-null float64 |
| Volume | 7310 non-null float64 |
| Previous Day Open Interest | 7310 non-null float64 |
欠損値が消え去りました!おめでとうございます![]()
データの可視化
せっかくなので2019年4月以降の日経平均と2015年以降の日経平均とをそれぞれ図示してみましょう。matplotlibを用います。なお、Google colaboratoryを用いているのでマジック(%matplotlib inline)を用いています。
%matplotlib inline
import matplotlib.pyplot as plt
降順に日付が並んでいるので2015年までを指定するときは[:'2015']となります。
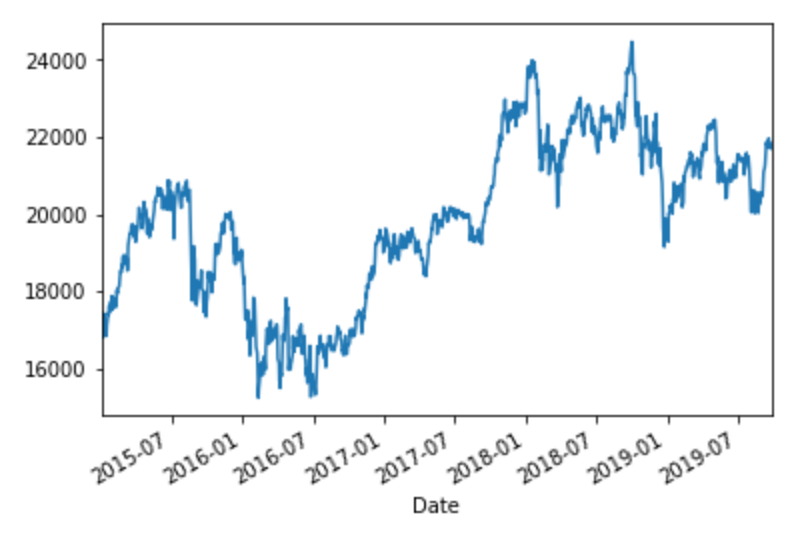
# 2015年以降の日経平均(終値のみ)
df.loc[:'2015', 'Last'].plot()
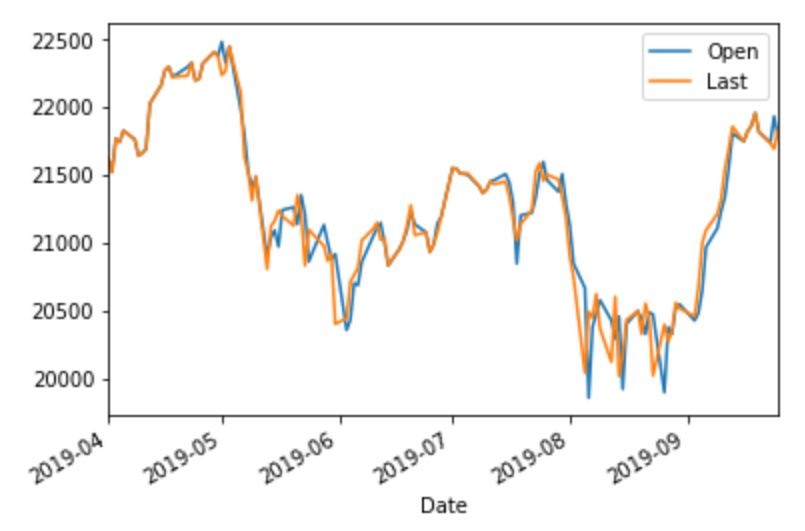
# 2019年4月以降の日経平均(始値と終値)
df.loc[:'2019-4', ['Open', 'Last']].plot()
移動平均(Rolling mean)
時系列データを平滑化する方法としては移動平均をとるという方法がありました。やってみましょう。
df.loc[:, 'Last'].plot()
df.loc[::-1, 'Last'].rolling(window = 90).mean().plot()
df.loc[::-1, 'Last'].rolling(window = 180).mean().plot()
plt.xlim('2016-04-01', '2019-09-25')
plt.ylim(15000, 25000)
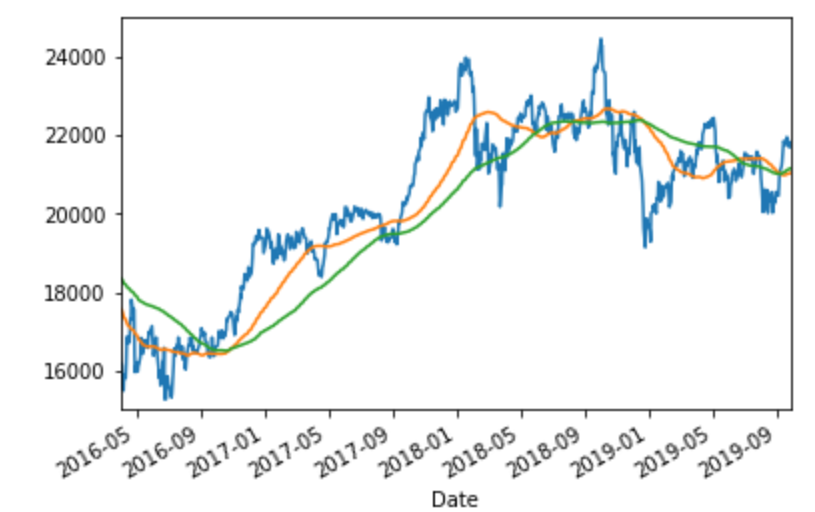
90日移動平均線と180日移動平均線が書けました!
終わりに
はじめてQiitaで記事を書いてみました!これからも勉強のため色々アウトプットしていきたいと思います。宜しくお願いします!