みなさん、
日本語でのテキストデータを持ち、そのデータから大事なインサイトを生み出そうと思ったことありませんか。
本記事ではGoogleで検索する時に使われている最先端の自然言語モデル「BERT」を使用し、日本語のテキストを高精度で分類しましょう。
問題定義
NHKのAPIによって入手した番組情報(番組題名, 概要など)を元に番組のジャンルを予測します。13のジャンルのうち、正解のジャンルを予測する多クラス分類問題です。
データ
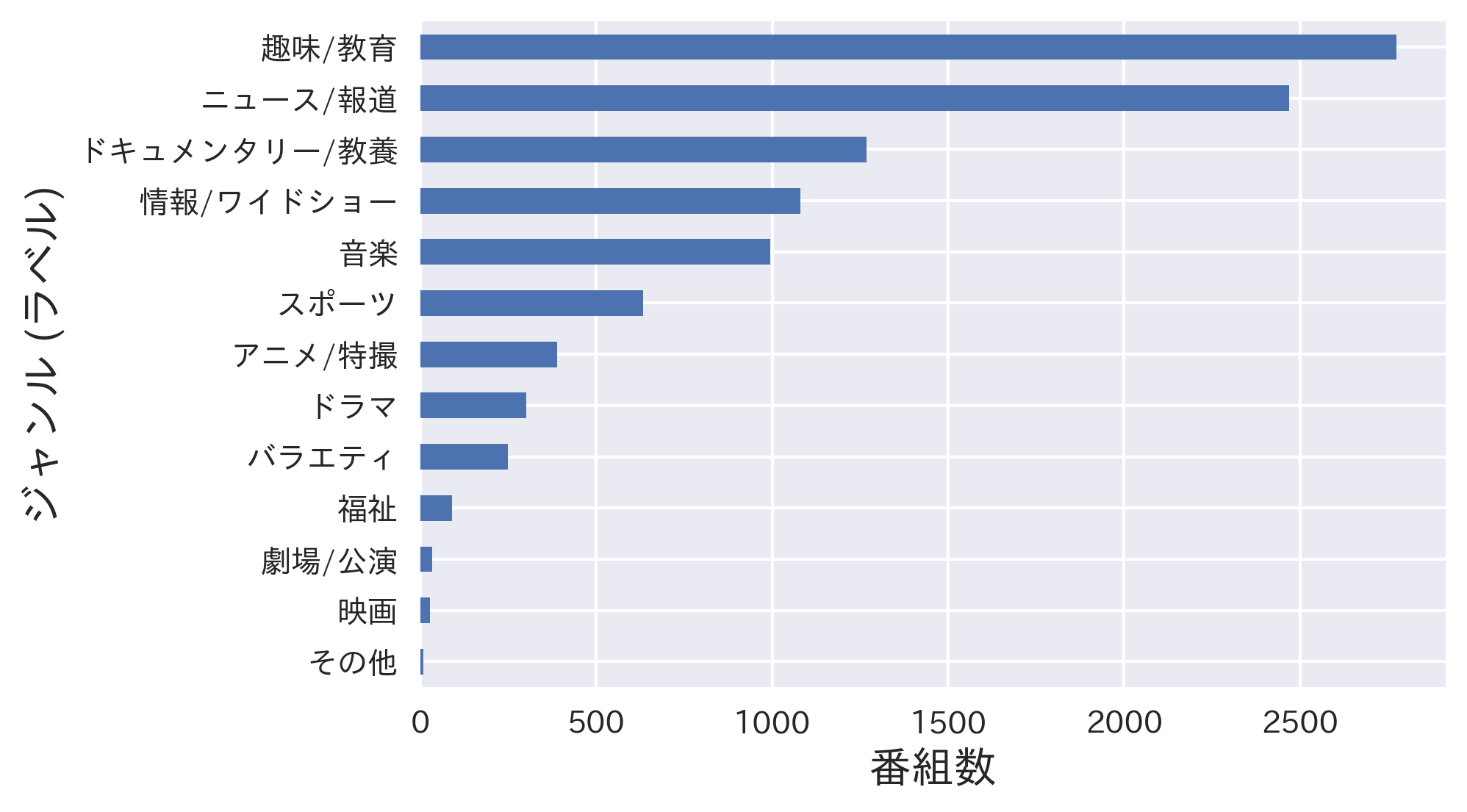
NHKは当日から7日間の間のテレビ・ラジオ・ネットラジオの番組表をAPIによって公開しています。公開データに各番組の題名 (Title)、副題(Subtitle)、概要 (Content)とジャンルなどが含まれています。ここ7日間のデータしか入手できませんので週一回ぐらいAPIに繋がってデータを入手し、2021/8/30から2021/9/24までの10,321ユニーク番組をデータベース化しました。こちらのリンクよりアクセスしてください。ちなみに、合計ジャンル数は13です。
データの例
探索的データ解析 (Exploratory Data Analysis)
ジャンルの分布状態を見ると、不均衡データということが把握できます。したがって、データを訓練データセットと検証データセットに分ける時に「Stratification」する必要あります。(i.e. 検証データが全体のデータと同じ分布特徴を持つように行われるデータの分け方)また、モデルの精度評価メトリックとして、不均衡データに適しているWeighted F1 Scoreを使います。
モデル
パラメーターなど
10,321番組を80-20%の割合で訓練データと検証データに分けます。10エポックを通してモデルを学習させ、各エポックで訓練データでのLossと検証データでの精度を追跡します。各エポックの終わりにモデルを保存し、検証データでの精度のもっとも高いエポックのモデルを最終モデルとしてピックアップします。
構築
モデルにインプットとしてTitle、SubtitleとContentを連結し、この一つのデータのみをインプットします。アウトプットとして、各番組において13ジャンルそれぞれのその番組のジャンルになりえる確率が出されます。この13次元の配列から、一番高い確率をピックアップし、そのジャンルをモデルの予測として扱っています。予測を正解ラベルと比較し、精度評価を行なっています。
BERT
この問題を解くためにはGoogleが開発したBERTを使います。🤗 Hugging Face LibraryによってBERTの日本語のpre-trainedモデルを使用し、この問題を解けるように微調整を行います。Pre-trainedモデルとして東北大学の研究者らが開発したWikipediaの日本語の約3,000万の文章を用いて学習されたbert-base-japanese-v2を使います。豊富なデータを元に学習された高度なモデルですので、日本語の文脈やニュアンスをある程度理解できるモデルです。
結果
BERTモデルはパラーメータが多いためCPUで学習させるのが難しいのでGoogle ColabにてGPUのある実行環境で学習させます(無料実行可能)。また、モデルを加速させ、メモリー過大が起きないようにインプットを32番組(Batch)ごとにモデルに入力します。学習の推移は以下の図に表示されています:

各ジャンルの予測パーフォマンスは以下の図で表示されています:

なお、Confusion Matrixは分類問題の結果において不可欠ですかね:

要約すれば、モデルは10番目のエポックで一番高い精度 (97%)を得ました。また、訓練Lossも検証精度も10エポック頃に横ばいになっていますので、10以降のエポックで得られるメリってが少ないです。
データが多ければ多いほど、精度が上がるはずですので、この問題において完璧なモデルを構築できるのが可能だと思います。なお、この問題だけでなく、BERTのpre-trainedモデルはそれぞれの問題を解くために微調整するだけで有力なツールになるでしょう。
質問・コメントなどがありましたら danyelkoca@gmail.com までお聞かせください。
Dataset: https://github.com/danyelkoca/NHK/blob/main/data.csv
Code: https://colab.research.google.com/drive/12ezR2Q4MZHE9m_Ppv_RfuqnKt-G9yX3f?usp=sharing
Happy hacking!