DynamoDBのデータをちょっとCSVで引き抜きたいってとき、色々方法はありますがマネジメントコンソールから一番手っ取り早くやる方法を紹介します。
項目を探索してエクスポート
DynamoDBのマネジメントコンソールからテーブルをスキャンorクエリすることで得られた結果をCSV形式でダウンロードできます。

ただし、このやり方には注意点があり今ページ上で読み込まれた分のデータしか出力してくれません。
「次のページを取得」が表示されなくなるまでポチポチ押していかないとすべての結果が得られず、少ないデータならこれでもいいのですが量が多いと難儀します。
PartiQLエディタを使ってエクスポート
こっちが本題です。
PartiQLエディタではSQLに似た構文を使ってDynamoDBをクエリすることができます。
クエリ結果を見るだけでなくCSV形式でエクスポートすることができ、これを使えば例えばWHERE句で項目を絞り込んだ結果やSELECT句で任意のカラムを削った状態でのエクスポートも可能になります。
※SELECT句でのカラムの並び替えやエイリアス付与はできないよう
SELECT
StringPK
,NumberSK
,BooleanValue
,DecimalListValues[0]
,JsonValue.bar
FROM "my_table"
WHERE StringPK = 'bar'
ORDER BY NumberSK DESC
例えば上記のようなクエリが実行できます。
※文字列引用符がシングルコーテーション限定なのに注意

これも先ほどの手順と同じように一度に取得できる項目数に限界はあるのですが。
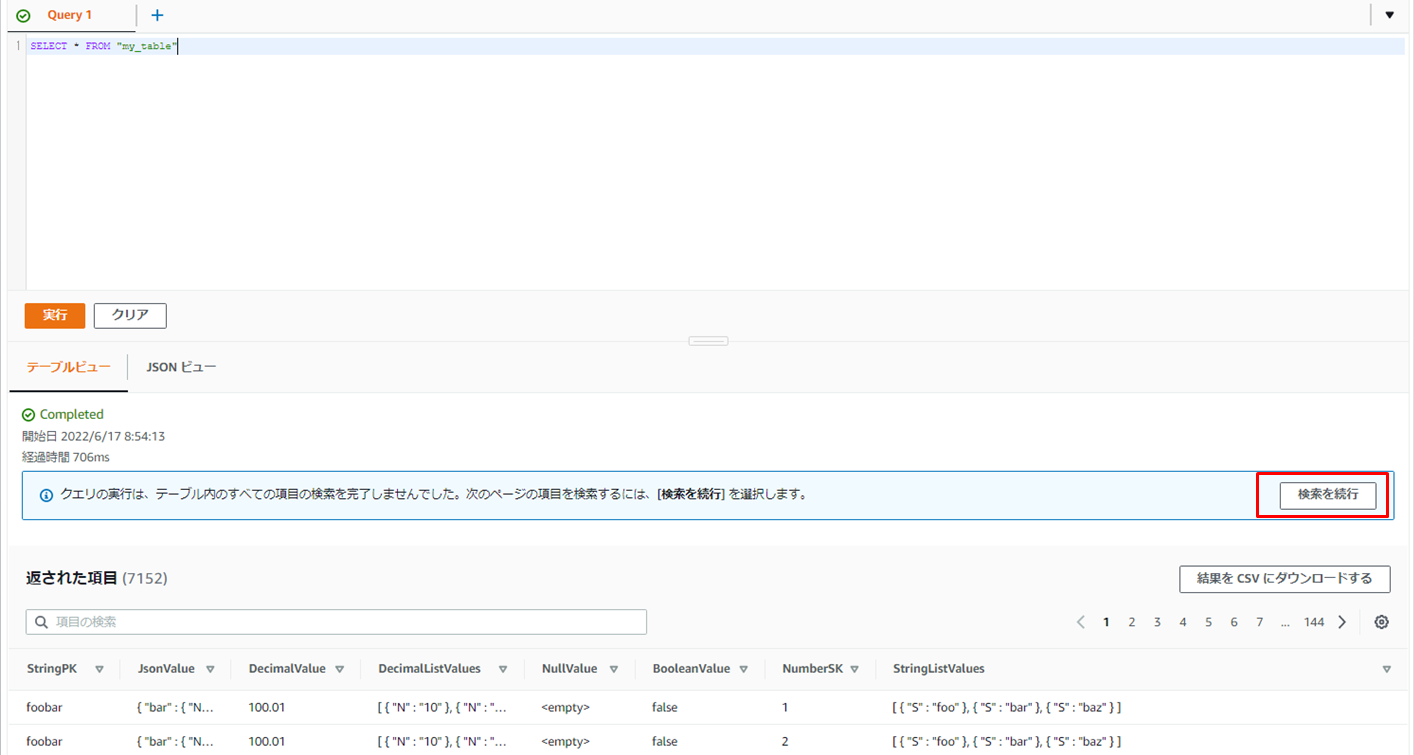
テスト用に作った10,000項目あるテーブルでも一回の実行で0.7秒ほどで7,000件近く取ってこれるので、先ほどの手順より圧倒的に少ない回数ですぐに全件読み込むことが可能です(※注:試したのは10,000項目までです)。
注意点
1点気を付けることがあるのは、項目を探索ではスキャン及びクエリで消費した読み込みキャパシティユニットが表示されますが、PartiQLエディタでは表示がありません。
じゃあ消費されていないのかというとそんなことがあるはずはなく、しっかり消費されています。
ExecuteStatement APIでクエリを実行するときにReturnConsumedCapacityパラメータを付けると消費したキャパシティユニットを確認することができます。
$ aws dynamodb execute-statement --statement "SELECT * FROM my_table" --return-consumed-capacity TOTAL
~省略~
"NextToken": "qLVEjEw4XwpTOlsc3SViU54Fqt/G/Sz5sZ7jynxjdsrpkYT4gtXNfZm4WObnb9dTW2nu7YOBOKtCVb8OaVBak0PdEfxF4dQxTMee4cAUQCTN9ft+UWJuNywRhAh7mHjoOZcg/4doWfx8JtIuWkiVn5/FEdOyImCCgWWc4Tv7Q7QI4TkjRPkrYypTKduo3nE8l2r7KiXlLMeUF/BAQBS3txpe+Jtuh4cpBooBpfQn1rFOHTYasbNvSxJhfyMQAKd0O+KaoigAeWCZlLOQ/buNRnliyWOEXCOzhx//7ho4wFwvnTfN5SixkAq1iu1aE0qTXVePQz0jWQT+2iogXCdxd9529TfKm8AG5Ls0w5bdWzJ9NbBHfO6bE7Ul7kvRK/Y=",
"ConsumedCapacity": {
"TableName": "my_table",
"CapacityUnits": 128.5
},
"LastEvaluatedKey": {
"StringPK": {
"S": "bar"
},
"NumberSK": {
"N": "152"
}
}
}
先ほどの10,000項目読みだすクエリだと128.5キャパシティユニット消費しています。
速いわけです、たとえテーブルのプロビジョンされた読み込みキャパシティーユニットを1に設定してても問答無用で消費されるので、キャパシティーモードがオンデマンドになっているのと同じ状況と考えた方がよさそうです。
利用するときはDynamoDBのコストを考えてなるべくクエリの無駄打ちをしないようにした方がよいでしょう。
limitを付けると返す項目数を制限してキャパシティユニットの消費を抑えられますが…。
ExecuteStatement APIしか対応しておらず、PartiQLエディタ上でLIMIT句のようなものは使えないようです。