はじめに
Qiita初投稿の(@danish55)です。現在、カーディラーの販売促進部署に勤めております。
現在、自己研鑽の為にデータ分析を学んでおります。
学習のアウトプットとして本記事を投稿させて頂きます。
未熟者ゆえ至らぬ点が多々有るかと存じますが、暖かくご指摘頂けましたら幸いです。
本記事の概要
データ分析の流れを身に付ける為に、一般的な流れに沿ってデータ分析を行います。
実務でデータ分析を行っている方にインタビューしながら記事にしました。
教材としてSIGNATEのコンペティションの1つである、「自動車の走行距離予測」に取り組んでみます。
言語はPython、環境はGoogle Colaboratoryを使用しました。
データ分析プロセスの確認
一般的なデータ分析では、以下の6つのステージの順番で進めていきます。
1.問題の定義
2.データの取得と理解
3.データの前処理
4.パターンの分析・特定
5.モデルの作成
6.結果の提出
注意点として必ずこのプロセス通りに進むという訳では有りません。
前のステージに戻ることや、次のステージをスキップすることも有ります。
1.問題の定義
**明らかにしたい問いや課題を定義するステージです。**問題の定義が明確だと作業の道筋が立てやすく、無駄な作業が減り効率的になります。実務で問題を定義する際には、その業界や会社の理解、そして業務フローの理解が重要となります。その為、実際に業務を行っている人に対して今の現状や課題をヒアリングします。
今回のコンペの問題の定義は自動車の属性データからガソリン1ガロン(≒3.78L)当たりの走行距離を予測することです。蓄積された過去の入力データから連続値を予測するものなので「回帰」を行えば良いことが分かります。
2.データの取得と理解
**データの取得及び性質を理解することでどのようにデータを変換・補完・修正していくかの方針を立てるステージです。**実務では、非構造化データと呼ばれるデータ分析しにくいデータも取り扱います。非構造化データを収集する際には、そのデータを構造化データに変換する方法も考えつつ収集します。
今回のコンペの訓練およびテストデータは、SIGNATEのコンペティションページから取得できます。
データの理解についは、今回は3つを行います。
1つ目はデータの始まりと終わり5行を目視で確認します。この意味はこのデータに何がどのように含まれているのかを、ざっくりと確認することです。
2つ目は欠損値とデータ型を確認します。欠損値がある場合やデータ型に異常が有る場合は、統計的処理が不可能になることが有ります。
3つ目に要約統計量を確認します。データがどのような分散をしているのか、重複があるかなどを簡単に確認します。
データ中身を目視で確認
それではデータを読み込んで、中身を確認をしたいと思います。
#データを取り込みと確認
import pandas as pd
df_train = pd.read_table("./drive/MyDrive/train.tsv")
print(df_train.head())
print(df_train.tail())
出力結果から以下、10種類のデータが入っているようです。(ヘッダ名称を和訳してます)
①インデックス(整数)
②ガソリン1ガロンあたりの走行距離(小数)
③シリンダー(整数)
④排気量(小数)
⑤馬力(小数)
⑥重量(小数)
⑦加速度(小数)
⑧年式(整数)
⑨起源(整数)←車の原産国です。(1=アメリカ, 2=ヨーロッパ, 3=日本)
⑩車名(文字列)
「起源」のようなカテゴリ変数を説明変数として使用する場合は、ダミー変数化する必要が有りそうです。
id mpg cylinders displacement horsepower weight acceleration \
0 0 29.0 4 135.0 84.00 2525.0 16.0
1 3 31.9 4 89.0 71.00 1925.0 14.0
2 9 19.0 6 156.0 108.0 2930.0 15.5
3 11 28.0 4 90.0 75.00 2125.0 14.5
4 13 37.7 4 89.0 62.00 2050.0 17.3
model year origin car name
0 82 1 dodge aries se
1 79 2 vw rabbit custom
2 76 3 toyota mark ii
3 74 1 dodge colt
4 81 3 toyota tercel
id mpg cylinders displacement horsepower weight acceleration \
194 384 40.8 4 85.0 65.00 2110.0 19.2
195 385 20.2 8 302.0 139.0 3570.0 12.8
196 387 16.0 8 304.0 150.0 3433.0 12.0
197 395 43.4 4 90.0 48.00 2335.0 23.7
198 396 26.0 4 98.0 90.00 2265.0 15.5
model year origin car name
194 80 3 datsun 210
195 78 1 mercury monarch ghia
196 70 1 amc rebel sst
197 80 2 vw dasher (diesel)
198 73 2 fiat 124 sport coupe
欠損値とデータ型の確認
次に欠損値とデータ型を確認します。
#特徴量の情報を出力
print(df_train.info)
出力結果から、今回は欠損値は無いようです。
しかし、先ほど小数として出力されているように見えた「馬力」が文字列として出力されているようです。数値として扱う為にデータ型を変更する必要が有りそうです。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 199 entries, 0 to 198
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 199 non-null int64
1 mpg 199 non-null float64
2 cylinders 199 non-null int64
3 displacement 199 non-null float64
4 horsepower 199 non-null object
5 weight 199 non-null float64
6 acceleration 199 non-null float64
7 model year 199 non-null int64
8 origin 199 non-null int64
9 car name 199 non-null object
dtypes: float64(4), int64(4), object(2)
要約統計量の確認
最後に要約統計量からデータの雰囲気を掴みます。
# 基本統計量を出力
print(df_train.describe(include='all'))
特徴量の単位がバラバラです。尺度を揃える為に標準化が必要そうです。
また「車名」はユニークなものが多いです。もし車名を特徴量として使う場合は、加工が必要そうです。
id mpg cylinders displacement horsepower \
count 199.000000 199.000000 199.000000 199.000000 199
unique NaN NaN NaN NaN 71
top NaN NaN NaN NaN 100.0
freq NaN NaN NaN NaN 12
mean 200.170854 24.307035 5.296482 183.311558 NaN
std 113.432759 7.797665 1.644562 98.400457 NaN
min 0.000000 9.000000 3.000000 71.000000 NaN
25% 98.500000 18.000000 4.000000 98.000000 NaN
50% 202.000000 24.000000 4.000000 140.000000 NaN
75% 294.500000 30.500000 6.000000 250.000000 NaN
max 396.000000 44.600000 8.000000 454.000000 NaN
weight acceleration model year origin car name
count 199.000000 199.000000 199.000000 199.000000 199
unique NaN NaN NaN NaN 167
top NaN NaN NaN NaN chevrolet impala
freq NaN NaN NaN NaN 4
mean 2883.839196 15.647739 76.165829 1.582915 NaN
std 819.766870 2.701885 3.802928 0.798932 NaN
min 1613.000000 8.500000 70.000000 1.000000 NaN
25% 2217.500000 14.000000 73.000000 1.000000 NaN
50% 2702.000000 15.500000 76.000000 1.000000 NaN
75% 3426.500000 17.150000 80.000000 2.000000 NaN
max 5140.000000 23.700000 82.000000 3.000000 NaN
3.データの前処理
データを分析しやすい様に加工するステージです。実務のデータ分析でも、この部分が全体の作業量の80%以上を占めると言われるくらい重要な部分になります。この前処理を適切に行うことによって有用なデータ分析が行えるかが決まります。
今回は、3つの前処理を行いたいと思います。
1つ目は「馬力」のデータ型を数値型に変更する処理を行います。理由は先に述べましたようにこのままでは数字としての処理が行えない為です。
2つ目はカテゴリー型である「起源」のダミー変数化です。理由は、数値に大小関係の存在しない項目をそのまま説明変数に使うと精度が下がってしまいまうからです。
3つ目は連続値データの標準化です。理由は「重量」「排気量」など桁数が異なるものを説明変数としてそのまま使うと、桁数の違いなどで係数の違いがそのまま影響度を表すとは限らなくなります。
データ型の変更と欠損値の補完
さっそく「馬力」のデータ型を数値に変更する処理を行います。「馬力」データの中身を確認するとデータの内、4件が「?」と入力されていました。恐らく欠損が有るものの値として「?」を入力したものと思われます。そのため、まず「馬力」の平均を取り、その後「?」の4件に平均を代入するという処理を行います。
# 「馬力」のデータ型変換と欠損値へ平均値を代入
import pandas as pd
horsepower_mean = df_train[~df_train["horsepower"].str.contains('\?')]['horsepower'].astype(float).mean()
print("馬力の平均", horsepower_mean)
df_train['horsepower'] = df_train['horsepower'].replace(['\?'],horsepower_mean,regex=True).astype(float)
print(df_train.info())
正しくデータ型の変更が行えました。
馬力の平均 101.2974358974359
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 199 entries, 0 to 198
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 199 non-null int64
1 mpg 199 non-null float64
2 cylinders 199 non-null int64
3 displacement 199 non-null float64
4 horsepower 199 non-null float64
5 weight 199 non-null float64
6 acceleration 199 non-null float64
7 model year 199 non-null int64
8 origin 199 non-null int64
9 car name 199 non-null object
dtypes: float64(5), int64(4), object(1)
ダミー変数化
続いてカテゴリー型である「起源」をダミー変数化します。この際に、注意しなければならないのは多重共線性という問題です。
回帰分析にダミー変数をそのまま使用すると、変数同士の相関が高くなり、多重共線性が起こり、テストデータに対する予測精度が低下してしまいます。
そこでダミー変数化する際には、列の1つを削除します。
#ダミー変数化
import pandas as pd
df_train = pd.get_dummies(df_train, columns=["origin"],drop_first = True)
print(df_train.head())
ダミー変数化できました。削除したorigin_1(アメリカ)は、origin_2(ドイツ)、origin_3(日本)が共に0として表されます。
id mpg cylinders displacement horsepower weight acceleration \
0 0 29.0 4 135.0 84.0 2525.0 16.0
1 3 31.9 4 89.0 71.0 1925.0 14.0
2 9 19.0 6 156.0 108.0 2930.0 15.5
3 11 28.0 4 90.0 75.0 2125.0 14.5
4 13 37.7 4 89.0 62.0 2050.0 17.3
model year car name origin_2 origin_3
0 82 dodge aries se 0 0
1 79 vw rabbit custom 1 0
2 76 toyota mark ii 0 1
3 74 dodge colt 0 0
4 81 toyota tercel 0 1
標準化
最後にデータの標準化を行います。標準化とは、データを分散1、平均0の値に加工することです。
# 標準化
# StandardScalerのインポート
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df_train[[ 'displacement', 'horsepower', 'weight',
'acceleration','model year', ]] = scaler.fit_transform(df_train[[ 'displacement', 'horsepower', 'weight',
'acceleration','model year', ]])
print(df_train.head())
標準化できました。
id mpg cylinders displacement horsepower weight acceleration \
0 0 29.0 4 -0.492207 -0.492627 -0.438837 0.130705
1 3 31.9 4 -0.960864 -0.862864 -1.172599 -0.611386
2 9 19.0 6 -0.278255 0.190887 0.056452 -0.054818
3 11 28.0 4 -0.950675 -0.748945 -0.928011 -0.425863
4 13 37.7 4 -0.960864 -1.119182 -1.019732 0.613064
model year car name origin_2 origin_3
0 1.537995 dodge aries se 0 0
1 0.747140 vw rabbit custom 1 0
2 -0.043716 toyota mark ii 0 1
3 -0.570953 dodge colt 0 0
4 1.274377 toyota tercel 0 1
4.パターンの分析・特定
**データを視覚化してパターンを探したり、特徴量や目的変数の相関性を見るステージです。**パターンといっても多種多様で早期に特定するには、経験を積むのが一番とのことです。
今回は相関関係を中心に見ていきます。
まずは相関係数を出力して数値として見ます。
その後散布図を出力して視覚として見ます。
相関係数
まず目的変数である「mpg(ガソリン1ガロンあたりの走行距離)」とその他の特徴量(説明変数)との相関係数を見ます。
相関係数は、-1〜1までの値の数値を取ります。相関係数の絶対値が1に近いほど相関が強く、0に近いほど相関が弱いという関係があります。
目安としては、以下の表のようになります。
| 相関係数(絶対値) | 評価 |
|---|---|
| 0~0.3未満 | ほぼ無関係 |
| 0.3~0.5未満 | 非常に弱い相関 |
| 0.5~0.7未満 | 相関がある |
| 0.9以上 | 非常に強い相関 |
それでは相関関係を見ていきます。
# 相関係数を出力
print(df_train.corr())
出力結果から、一見すると目的変数である「mpg」との相関関係は「シリンダー」「排気量」「馬力」「重さ」に負の相関、「年式」に正の相関が有りそうです。ただし、この相関をこのまま鵜呑みにしてはいけません。
id mpg cylinders displacement horsepower \
id 1.000000 -0.052688 0.103419 0.098416 0.082364
mpg -0.052688 1.000000 -0.770160 -0.804635 -0.778664
cylinders 0.103419 -0.770160 1.000000 0.950600 0.846099
displacement 0.098416 -0.804635 0.950600 1.000000 0.889019
horsepower 0.082364 -0.778664 0.846099 0.889019 1.000000
weight 0.070563 -0.820660 0.893256 0.933038 0.865194
acceleration -0.087649 0.379721 -0.479561 -0.523955 -0.652973
model year -0.093272 0.568471 -0.303462 -0.329817 -0.377874
origin_2 -0.044349 0.297894 -0.360582 -0.387486 -0.295186
origin_3 -0.009584 0.388215 -0.320742 -0.390168 -0.275663
weight acceleration model year origin_2 origin_3
id 0.070563 -0.087649 -0.093272 -0.044349 -0.009584
mpg -0.820660 0.379721 0.568471 0.297894 0.388215
cylinders 0.893256 -0.479561 -0.303462 -0.360582 -0.320742
displacement 0.933038 -0.523955 -0.329817 -0.387486 -0.390168
horsepower 0.865194 -0.652973 -0.377874 -0.295186 -0.275663
weight 1.000000 -0.401757 -0.265562 -0.327802 -0.375637
acceleration -0.401757 1.000000 0.194854 0.160272 0.110562
model year -0.265562 0.194854 1.000000 -0.027979 0.138603
origin_2 -0.327802 0.160272 -0.027979 1.000000 -0.239856
origin_3 -0.375637 0.110562 0.138603 -0.239856 1.000000
気をつけなければならないのが特徴量同士の相関係数になります。なぜならば、重回帰分析を行う場合、特徴量同士で相関関係が強いものを説明変数として使用してしまうと「多重共線性」という現象が起き、テストデータに対する予測精度が低下してしまうからです。
今回で言うと「シリンダー」と「排気量」に非常に強い相関が見れます。調べてみると「排気量=シリンダー内径面積×ピストン行程×シリンダー数」で求められる為、相関が有るのは当然のようです。何を説明変数として採用するかはその分野の知識も必要です。

散布図
次に散布図として可視化して確かめてみます。この意味は数値として相関係数が低く、相関が無さそうな特徴量も何かしらの法則性に基づいてデータが分布している可能性が有るからです。そのため相関分析をする際には散布図を描画し、見落としを防ぐ必要があります。
#散布図を作成
import seaborn as sns
sns.pairplot(df_train, x_vars=[ 'cylinders', 'displacement', 'horsepower', 'weight',
'acceleration', 'model year', 'origin_2','origin_3'], y_vars=["mpg"])
ダミー変数化した項目については、0と1で表される為このような分布になります。その他の項目については特殊な分布の形は無さそうです。

5.モデルの作成
**アルゴリズム選定とモデル実装・評価のステージです。**モデル作成に使用できる機械学習のアルゴリズムは現在、60個以上存在します。その為、問題の種類と解決策の要件を理解した上で、適切なアルゴリズムを選択する必要があります。
今回は「線形重回帰分析」を選択します。回帰モデルには、他にも一般的に使われている「ロジスティック回帰」など有ります。私が今回「線形重回帰分析」を選んだ理由は、現在統計学を学んでおり、その中で学んだことのある線形重回帰を使ってみたいと思ったからです
それでは「mpg」を目的変数、説明変数を「排気量」「重さ」「馬力」「年式」「起源」として学習用データで重回帰モデルを作成します。(「シリンダー」は、先の理由から外しました。「重さ」や「馬力」についても特徴量同士の相関が高かったですが、それぞれ特徴量の性質が異なると判断して今回は目的変数として使用します。)
また今回はデータ量が少ないのでデータの評価方法として「KFold法」を選択します。データを5分割にして4個分を学習データ、1個をバリテーションデータにして決定係数を算出します。それを5回繰り返して、平均を取ったものを今回の決定係数として採用します。
# モデルの実装と評価
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import KFold
X = df_train[["displacement","weight","horsepower","model year",'origin_2','origin_3']]
y = df_train[["mpg"]]
acc_results = []
kf = KFold(n_splits=5,shuffle=True,random_state=20)
linear_regression = LinearRegression()
for train_index, val_index in kf.split(X):
X_train, X_val = X.iloc[train_index], X.iloc[val_index]
y_train, y_val = y.iloc[train_index], y.iloc[val_index]
linear_regression.fit(X_train, y_train)
acc = linear_regression.score(X_val, y_val)
acc_results.append(acc)
print("傾き:", linear_regression.coef_)
print("切片:", linear_regression.intercept_)
print("決定係数:", np.mean(acc_results))
結果は以下のようになりました。決定係数は1に近いほど、回帰式が実際のデータに当てはまっていることを表しており、今回の値はまずまずの値と言えます。
傾き: [[ 1.44732828 -5.13878094 -1.33239738 3.13828398 3.14843987 3.22627336]]
切片: [23.10479828]
決定係数: 0.8137744478423075
視覚化
作成したモデルの有用性を第三者に説明する必要が有るケースも有ります。
その際には視覚化して分り易くする必要が有ります。
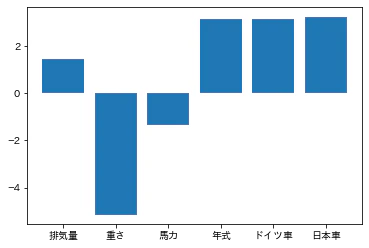
今回は作成した重回帰モデルの説明変数の重要度を視覚化します。
# 特徴量重要度の視覚化
import matplotlib.pyplot as pyplot
import japanize_matplotlib
importance = linear_regression.coef_.ravel()
labels = ["排気量", "重さ", "馬力", "年式", "ドイツ車", "日本車"]
pyplot.bar([x for x in range(len(importance))], importance, tick_label=labels)
pyplot.show()
これでどの説明変数がどのくらい結果に寄与しているかが視覚として分かりました。

6.結果の提出
成果物の適用ステージです。実務では成果物をリリースしたら終了ではなく、その後定期的な保守管理を行うようです。また、「最終のレポート」や「プロジェクトのレビュー」などもするようです。
今回はSIGNATE作ったモデルを使用して「mpg」を予測したものをcsv形式で提出して終了とさせていただきます。
# テストデータでの予測と結果提出
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
df_test = pd.read_table("./drive/MyDrive/test.tsv", sep='\t')
df_test['horsepower'] = df_test['horsepower'].replace(['\?'],horsepower_mean,regex=True).astype(float)
df_test = pd.get_dummies(df_test, columns=["origin"],drop_first = True)
df_test[[ 'displacement', 'horsepower', 'weight',
'acceleration','model year']] = scaler.fit_transform(df_test[[ 'displacement', 'horsepower', 'weight',
'acceleration','model year']])
X_test = df_test[["displacement","weight","horsepower","model year",'origin_2','origin_3']]
y_pred = linear_regression.predict(X_test)
df_test['mpg'] = y_pred
df_test[['id', 'mpg']].to_csv('./submit.csv', header=False,index=False)
結果は誤差が3.7478877でした。この誤差は「RMSE」という評価関数で表され0に近い程予測の精度が高いことを示します。リーダーボードを見たらもっと誤差の低い人が多くいましたのでまだまだ改善の余地が有るということだと思います。
ちなみに「多重共線性」を危惧して説明変数から外した「シリンダー」を入れて再度モデルを作って見た結果、誤差が3.6852274と少しだけ改善されました。また、そのモデルに更に相関係数が低かった為、説明変数として入れなかった「加速度」を追加したところ誤差が6.0582930と大幅に悪化しました。
作ったモデルに対してどの特徴量を当てはめたら一番良い結果になるのかは、実際に色々試してみないと分からないということだと思います。
結果に対する考察
ここからは結果を提出した後に気づいたことを書きます。
自身の記事を読み直してふと違和感を感じました。
「排気量」は目的変数に対して負の相関が有りました。しかし、回帰係数の符号はプラスでした。これでは、排気量が高いほど、走行距離は伸びることになり、相関関係とは真逆となります。
そこで、調べてみると今回のケースのような場合は「多重共線性」の可能性が有るとのことでした。
「排気量」と相関の有ったが説明変数として使った「重さ」「馬力」が悪さをしているようでした。
そこで、目的変数と一番相関の高かった「重さ」を残し、「排気量」「馬力」を消して再度モデル化してみました。結果は以下のようになりました。
傾き: [[-5.00727484 3.2225105 2.67519918 2.70510764]]
切片: [23.28833663]
決定係数: 0.8134900711409323
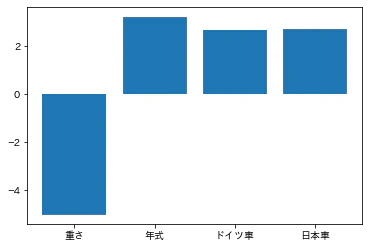
コンペの誤差は3.7589497となり、誤差、決定係数ともに最初のモデルの結果とほぼ変わりませんでした。今回の件から言えるのは、何でもかんでも相関係数の高いものを説明変数に入れて重回帰分析をしても精度は上がらないということです。データ分析には、実装する為のプログラミング能力とは別に統計的な知識が不可欠だと感じました。
今回出来なかったこと
今回出来なかったこととして「車名」の列に入っていた文字列から「TOYOTA」といったメーカーの名前の入った列を新規で作ります。そしてその後にダミー変数化してメーカーを説明変数として使用して予測すればもっと精度が良いものになるかと感じました。
また、線形重回帰のみではなく複数のモデルとの比較によってどのモデルが最も良い精度を出すのかを行うともっと面白いかと思います。
おわりに
ここまで見ていただき、ありがとうございました。
「データ分析は、誰にも『本当のゴール』が分からない」という言葉を聞いたことが有ります。私は学習を通じて、データ分析の本質とは「完璧な正解方法が無いからこそ、試行錯誤によって「よりよい正解」を目指すこと」だと感じました。試行錯誤の多いデータ分析だからこそ基本的な流れを身に付けることはとても重要だと感じました。