この記事はOpenCV Advent Calendar 2016の4日目の記事です.
はじめに
この記事ではOpenCVのcudaモジュールで提供されているcuda::Streamとその使い方を紹介します.
今回紹介するcuda::Streamですが,もしかしたらOpenCVドキュメントで見たことある方いらっしゃるかもしれませんね.
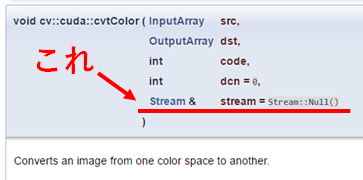
以降は基本的にOpenCV 3.x系を前提に説明します(最後の方で2.4系についても軽く触れます).
cuda::Streamクラスとは
CUDAのStreamはGPU上の処理を管理するキューのことでカーネル実行やメモリ転送の並列性,実行順序を制御するために用いられます.CUDAのStreamに関しては以下の記事を参照ください.
- ストリームを用いたコンカレントカーネルプログラミングと最適化
- How to Overlap Data Transfers in CUDA C/C++
- GPU Pro Tip: CUDA 7 Streams Simplify Concurrency
また,OpenCVのcudaモジュールではこのStreamを簡単に利用するためにcuda::Streamクラスを提供しています.
cuda::Streamクラスが提供するAPI
冒頭でも紹介したcuda::Streamクラスは以下のAPIを提供しています.
各APIの詳細については公式ドキュメントを参照ください.
| API | 機能 |
|---|---|
| waitForCompletion | Streamの一連の処理が終わるまで現在のCPUスレッドをブロッキングする |
| waitEvent | Streamのイベントを待機する ※イベントについては公式ドキュメントを参照ください |
| queryIfComplete | 現在のstream queueの処理が終わっているかどうかを調べる |
| enqueueHostCallback | Streamのキューイング処理完了後にホスト側で実行されるコールバック関数を設定する |
また,enqueueHostCallbackの使い方は公式テストコードが参考になるでしょう.
cuda::Streamクラスの使い方
OpenCVのcudaモジュールAPIで明示的にcuda::Streamを使うのは非常に簡単です.
基本的な実装手順は以下の通りです.
- cuda::Streamクラスのインスタンスを生成する
- cudaモジュールのAPIにcuda::Streamクラスのインスタンスを渡す
一言で言うと**「cuda::StreamクラスのインタンスをcudaモジュールのAPIに明示的にセットする」**だけでOKです.
サンプルコード
おそらく実際のコードを読むのがわかりやすいと思うのでサンプルコードを以下に示します.
// (1) cuda::Streamクラスのインスタンスを生成する
cv::cuda::Stream stream;
// (2) cudaモジュールのAPIにcuda::Streamクラスのインスタンスを渡す
cv::cuda::cvtColor(d_img, d_gray, cv::COLOR_BGR2GRAY, 0, stream);
cuda::Streamを使うメリット
cuda::Streamを使うことでデータ転送とカーネル実行をオーバーラップさせることができ,データ転送時間を隠蔽できるようになります.と言ってもピンと来ないと思うのでサンプルコードを用いながら説明します.
明示的にcuda::Streamをセットしない場合
OpenCVのcudaモジュールAPIにcuda::Streamクラスのインスタンスを明示的にセットしない場合,
Default Streamを使って処理が行われます.ここではサンプルコードとNVIDIA Visual Profilerで取得したタイムラインを示します.
サンプルコード
cv::Mat src(cv::Size(3840, 2160), CV_8UC3, cv::Scalar(0));
cv::cuda::HostMem dst1, dst2, dst3;
cv::cuda::GpuMat d_src;
cv::cuda::GpuMat d_gray1, d_gray2, d_gray3;
cv::cuda::GpuMat d_dst1, d_dst2, d_dst3;
// デバイスに転送
d_src.upload(src);
// GpuMatを使った処理(Default Stream)
cv::cuda::cvtColor(d_src, d_gray1, cv::COLOR_BGR2GRAY, 0);
cv::cuda::threshold(d_gray1, d_dst1, 200, 255, cv::THRESH_BINARY);
//ホストへ転送(Default Stream)
d_dst1.download(dst1);
// GpuMatを使った処理(Default Stream)
cv::cuda::cvtColor(d_src, d_gray2, cv::COLOR_BGR2GRAY, 0);
cv::cuda::threshold(d_gray2, d_dst2, 200, 255, cv::THRESH_BINARY);
//ホストに転送(Default Stream)
d_dst2.download(dst2);
// GpuMatを使った処理(Default Stream)
cv::cuda::cvtColor(d_src, d_gray3, cv::COLOR_BGR2GRAY, 0);
cv::cuda::threshold(d_gray3, d_dst3, 200, 255, cv::THRESH_BINARY);
//ホストに転送(Default Stream)
d_dst3.download(dst3);
タイムライン
サンプルコードを実行したときのタイムラインは以下の通りです.

cudaモジュールAPIにcuda::Streamクラスのインスタンスを明示的にセットしないと
Default Streamが使われていてデータ転送やカーネル実行が並列に行われてないことがわかります.
明示的にcuda::Streamをセットする場合
ここではcuda::Streamを使った場合のサンプルコードとタイムラインを示します.
サンプルコード
cv::Mat src(cv::Size(3840, 2160), CV_8UC3, cv::Scalar(0));
cv::cuda::HostMem dst1, dst2, dst3;
cv::cuda::GpuMat d_src;
cv::cuda::GpuMat d_gray1, d_gray2, d_gray3;
cv::cuda::GpuMat d_dst1, d_dst2, d_dst3;
cv::cuda::Stream stream[3];
// デバイスに転送
d_src.upload(src);
// GpuMatを使った処理(cuda::Stream)
cv::cuda::cvtColor(d_src, d_gray1, cv::COLOR_BGR2GRAY, 0, stream[0]);
cv::cuda::threshold(d_gray1, d_dst1, 200, 255, cv::THRESH_BINARY, stream[0]);
//ホストに転送(cuda::Stream)
d_dst1.download(dst1, stream[0]);
// GpuMatを使った処理(cuda::Stream)
cv::cuda::cvtColor(d_src, d_gray2, cv::COLOR_BGR2GRAY, 0, stream[1]);
cv::cuda::threshold(d_gray2, d_dst2, 200, 255, cv::THRESH_BINARY, stream[1]);
//ホストに転送(cuda::Stream)
d_dst2.download(dst2, stream[1]);
// GpuMatを使った処理(cuda::Stream)
cv::cuda::cvtColor(d_src, d_gray3, cv::COLOR_BGR2GRAY, 0, stream[2]);
cv::cuda::threshold(d_gray3, d_dst3, 200, 255, cv::THRESH_BINARY, stream[2]);
//ホストに転送(cuda::Stream)
d_dst3.download(dst3, stream[2]);
タイムライン
サンプルコードを実行したときのタイムラインは以下の通りです.

このサンプルコードでは複数のcuda::Streamを使ってデータ転送やカーネル実行に割り当てることでデータ転送とカーネル実行をオーバーラップさせることができていることがわかります.
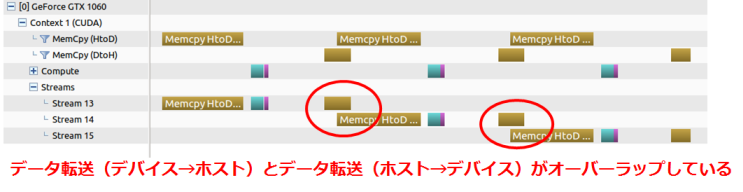
また,サンプルコードは割愛しますが,今回用いたGeForce GTX 1060はCopy Engineを2つ持っているので,処理によっては以下のように**データ転送(ホスト→デバイス)とデータ転送(デバイス→ホスト)**をオーバーラップさせることもできます.
cuda::Streamクラスを使った実装方法
ここまではOpenCVのcudaモジュールのAPIでcuda::Streamを明示的に使うお話でした.
一方でOpenCVと連携した自作CUDAカーネルでcuda::Streamを利用したいケースもあると思います.
基本的な実装手順は以下の通りです.
- 関数の引数にcuda::Streamクラスの変数を追加する
-
cuda::StreamAccessor::getStreamメソッド(公式ドキュメント)を使ってCUDAのStreamを取得する - CUDAカーネル起動時に2.で取得したStreamを指定する
サンプルコード
こちらもおそらく実際のコードを読むのがわかりやすいと思うのでサンプルコードを以下に示します.
// (1) 関数の引数にcuda::Streamクラスの変数を追加する
void hoge_func(cv::cuda::GpuMat& img, cv::cuda::Stream& stream_)
{
// (2) CUDAのStreamを取得する
cudaStream_t stream = cv::cuda::StreamAccessor::getStream(stream_);
const dim3 threads(32, 8);
const dim3 grid(divUp(img.cols, threads.x), divUp(img.rows, threads.y));
// (3) CUDAカーネル起動時に(2)で取得したStreamを指定する
hoge_kernel<<<grid, threads, 0, stream>>>(img);
cudaGetLastError();
cudaDeviceSynchronize();
}
前に述べたように
- 関数の引数にcuda::Streamクラスの変数を追加する
-
cuda::StreamAccessor::getStreamメソッド(公式ドキュメント)を使ってCUDAのStreamを取得する - CUDAカーネル起動時に2.で取得したStreamを指定する
という流れそのままなので簡単ですね!
OpenCV 2.4系は?
冒頭で述べたようにここまでOpenCV 3.x系を前提とした話になっていました.ここまで聞いて「じゃあ,cuda::StreamクラスってOpenCV 2.4系じゃ使えないの?」と疑問が生じるかもしれませんが安心してください.
OpenCV 2.4系だとgpu::Streamクラスがその役割を担っています.
ただし,GpuMatクラスのupload,downloadメソッドの扱いが若干異っていて,OpenCV 2.4系だとgpu::Stream::enqueueUpload,gpu::Stream::enqueueDownloadメソッドを使う必要があります.
各APIの詳細は以下のURLを参照ください。
- http://docs.opencv.org/2.4.13/modules/gpu/doc/data_structures.html#gpu-stream-enqueueupload
- http://docs.opencv.org/2.4.13/modules/gpu/doc/data_structures.html#gpu-stream-enqueuedownload
ということで,2.4系だと具体的にどういう実装になるかイメージしやすいよう
3.x系と対比しながらサンプルコードを見てみましょう.
サンプルコード(OpenCV 3.x系)
// cuda::Streamクラスのインスタンスを生成する
cv::cuda::Stream stream;
// uploadメソッドにcuda::Streamクラスのインスタンスを渡す
d_src.upload(src, stream);
// GpuMatを使った処理
// downloadメソッドにcuda::Streamクラスのインスタンスを渡す
d_dst.download(dst, stream);
サンプルコード(OpenCV 2.4系)
// gpu::Streamクラスのインスタンスを生成する
cv::gpu::Stream stream;
// enqueueUploadメソッドを使う
stream.enqueueUpload(src, d_src);
// GpuMatを使った処理
// enqueueDownloadメソッドを使う
stream.enqueueDownload(d_dst, dst);
ということで,2.4系でもそこまで大きな違いがなく,Streamが使えることがわかると思います.
おわりに
この記事ではOpenCVのcudaモジュールで提供されているcuda::Streamとその使い方を紹介しました.
cudaモジュールを使う機会があれば必要に応じてcuda::Streamを使ってみてください!
備考
筆者は以下の環境で動作確認しました.
- CPU:Intel Core i7-6700HQ
- メモリ:64GB
- GPU:NVIDIA GeForce GTX 1060 / 6GB
- Ubuntu 16.04 LTS(64bit)
- OpenCV 3.1.0
- CUDA 8.0
- gcc 5.4.0
参考URL
- How to Overlap Data Transfers in CUDA C/C++
- GPU Pro Tip: CUDA 7 Streams Simplify Concurrency
- ストリームを用いたコンカレントカーネルプログラミングと最適化
- streamで速くする(1) ~イントロ
- streamで速くする(2)
- streamで速くする(3) ~からくり
- Getting started with OpenCV on GPUs
- Computer Vision on GPU with OpenCV
- Hyper-Qの限界までStreamを並列動作させてみた on JetsonTX1
- OpenCVのgpu::countNonZeroをgpu::Streamで高速化する