■OSPF
特徴
・リンクステート型のルーティングプロトコル
・ダイクストラアルゴリズム(Shortest Path First:SPFアルゴリズム)による高速収束
・VLSM(variable length subnet mask)をサポート
・30分に1度 LSDB(Link-State Database:OSPFで使用するデータベース)を同期させる
・ネットワークに変更があったときにLSUが送信される(トリガードアップデート)
・等コストロードバランスをデフォルトでサポート
・エリアという概念による階層設計
・マルチエリアOSPFにすることで、他エリアのルーティング情報の集約が可能
隣接関係の確立
【OSPFステート】
OSPFを起動したルータが隣接関係を確立して、コンバージェンスするまでのステートの流れ
DOWN → INIT → 2WAY → EXSTART → EXCHANGE → LOADING → FULL
DOWN・・・Helloパケットを受信していない最初の状態
INIT・・・Helloパケットを受信し、相手を認識した状態
2WAY・・・お互いに認識した状態(DROTHER同士は経路情報を直接交換しないので「2WAY」状態でコンバージェンス)
EXSTART・・・DR、BDR決定(選出)済み
EXCHANGE・・・データベースの交換
LOADING・・・詳細情報確認
FULL・・・コンバージェンス(最適経路の計算が完了した状態)
【OSPFの経路学習プロセス】
・OSPFルータはHelloパケットを送信してネイバーを検出し、ネイバーテーブルを作成する。
・検出したネイバーに、マルチキャストでLSU(LSAを含むパケット)を送信する。
・LSUを受信したルータは、自分のネットワークに関する詳細な情報を保存したLSDBを作成する。(同じエリア内のルータは、同一のLSDBを保持)
・ルータはLSDBを元に、ダイクストラアルゴリズム(SPFアルゴリズム)により宛先ネットワークへの経路の計算を行い、最短経路を選択する。
・最短経路を選択する際のメトリックにはコスト(基準帯域幅÷インターフェースの帯域幅)を使用。コストの値が最小の経路がルーティングテーブルに登録される。なお、基準帯域幅のデフォルトは100Mbps。
・コンバージェンス後は、ネイバーにHelloパケットを定期的に送信し、リンクがアクティブであることを確認し続ける。(キープアライブ)
・ネットワークに変更があった場合はトリガーアップデートを使用して、変更情報だけをフラッディングする。(差分アップデート)
・各ルータは30分ごとにLSAを送信して情報の維持を行う。
※隣接関係をとるのに一致させるのが必要な項目
・Hello/Deadタイマー
・MTUサイズ
・エリアID
・ネットワークマスク
・スタブエリアフラグ
・認証パスワード
DR/BDR選出
DR/BDRとだけの間でLSAを交換することで、LSAを交換するネイバールータを減らすことができる。
DRとBDRの選出にはOSPFプライオリティ値が使用され、その値が同じ場合にはルータIDを使用する。OSPFプライオリティ値はHelloパケットに含まれており、OSPFルータがHelloパケットを交換して"2Way State"になった後にDR/BDRが選出される。
DRとBDRはセグメントごとに選出される。OSPFプライオリティ値はインターフェースごとに設定するので、あるOSPFルータにおいてNW1ではDRとなっても、NW2ではDROTHERになっている場合もある。
選出ルールは以下。
① OSPFプライオリティ値が最も大きいルータがDRになる。
② OSPFプライオリティ値が2番目に大きいルータがBDRになる。
③ OSPFプライオリティ値が同じ場合、ルータIDが最も大きいルータがDR、2番目に大きいルータがBDRとなる。
※ OSPFプライオリティ値はデフォルトで1。なお、OSPFプライオリティ値が0のOSPFルータは必ずDROTHERになる。
設定例(Cisco Catalyst)
■network ステートメントを使用せず、P2Pで接続する場合
※networkタイプ:ポイントツーポイント
⇒・DR/BDR選出しない
⇒・Wait Timer の 40 秒を待つことなく、速やかに LSA の交換に移れる
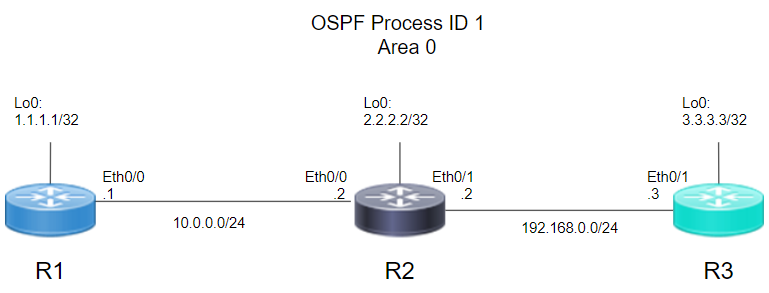
R1(config)# int lo0
R1(config-if)# ip address 1.1.1.1 255.255.255.255
R1(config-if)# ip ospf 1 area 0
R1(config)# int Eth0/0
R1(config-if)# ip address 10.0.0.1 255.255.255.0
R1(config-if)# ip ospf 1 area 0
R1(config-if)# ip ospf network-type point-to-point
R2(config)# int lo0
R2(config-if)# ip address 2.2.2.2 255.255.255.255
R2(config-if)# ip ospf 1 area 0
R2(config)# int Eth0/0
R2(config-if)# ip address 10.0.0.2 255.255.255.0
R2(config-if)# ip ospf 1 area 0
R2(config-if)# ip ospf network-type point-to-point
R2(config)# int Eth0/1
R2(config-if)# ip address 192.168.0.2 255.255.255.0
R2(config-if)# ip ospf 1 area 0
R2(config-if)# ip ospf network-type point-to-point
R3(config)# int lo0
R3(config-if)# ip address 3.3.3.3 255.255.255.255
R3(config-if)# ip ospf 1 area 0
R3(config)# int Eth0/1
R3(config-if)# ip address 192.168.0.3 255.255.255.0
R3(config-if)# ip ospf 1 area 0
R3(config-if)# ip ospf network-type point-to-point
■network ステートメントを使用し、物理IFでMD5認証する場合
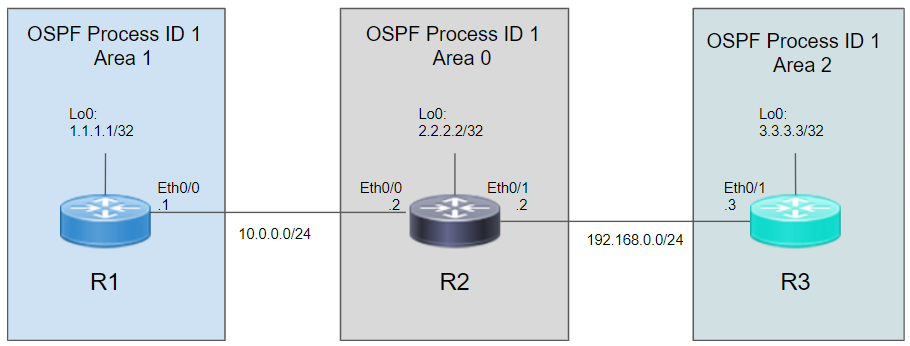
R1(config)# interface Loopback0
R1(config-if)# ip address 1.1.1.1 255.255.255.255
R1(config)# interface Eth0/0
R1(config-if)# ip address 10.0.0.1 255.255.255.0
R1(config-if)# ip ospf message-digest-key 1 md5 pass321
R1(config)# router ospf1
R1(config-router)# router-id 1.1.1.1
R1(config-router)# network 1.1.1.1 0.0.0.0 area 1
R1(config-router)# network 10.0.0.0 0.0.0.255 area 0
R2(config)# interface Loopback0
R1(config-if)# ip address 2.2.2.2 255.255.255.255
R2(config)# interface Eth0/0
R2(config-if)# ip address 10.0.0.2 255.255.255.0
R2(config-if)# ip ospf message-digest-key 1 md5 pass321
R2(config)# interface Eth0/1
R2(config-if)# ip address 192.168.0.2 255.255.255.0
R2(config-if)# ip ospf message-digest-key 1 md5 pass654
R2(config)# router ospf1
R2(config-router)# router-id 2.2.2.2
R2(config-router)# network 2.2.2.2 0.0.0.0 area 0
R2(config-router)# network 10.0.0.0 0.0.0.255 area 0
R2(config-router)# network 192.168.0.0 0.0.0.255 area 0
R3(config)# interface Loopback0
R3(config-if)# ip address 3.3.3.3 255.255.255.255
R3(config)# interface Eth0/1
R3(config-if)# ip address 192.168.0.1 255.255.255.0
R3(config-if)# ip ospf message-digest-key 1 md5 pass654
R3(config)# router ospf1
R3(config-router)# router-id 3.3.3.3
R3(config-router)# network 3.3.3.3 0.0.0.0 area 2
R3(config-router)# network 192.168.0.0 0.0.0.255 area 0
OSPFのcost
コストは帯域幅から自動計算されるが、手動設定も可能。
※意図的に通信させたくない場合等に利用する。
R1(config)# interface Eth0/1
R1(config-if)# ip ospf cost 100 ###値は 1 - 65535
確認コマンド
show ip protocols
show ip ospf
show ip ospf interface
show ip ospf neighbor
show ip ospf database network
■BGP
特徴
・パスベクタ型ルーティングプロトコル
AS内のルート情報に付加されたパスアトリビュートを送信して最適経路を決定する。デフォルトでは、宛先ネットワークまでに経由する。
・AS(Autonomous System)間で経路情報を交換するEGP(Exterior Gateway Protocol)
・TCP(ポート:179)を利用するので信頼性が高い
・使用するデータベースは「ネイバーテーブル」 「BGPテーブル」 「ルーティングテーブル」の3種類
・ピアから受信したルート情報はBGPテーブルに格納される
・同じ宛先に対する経路が複数存在する場合は パスアトリビュートによって最適パスを決定
・ピアにアドバタイズするルート情報は BGPテーブルに格納されている中の最適パスのみ
・ルーティングテーブルに格納するのは BGPテーブルに格納されている中の最適パスのみ
・自身で生成した経路のNext Hopは「0.0.0.0」になる
・トリガーアップデートを行う
【BGPメッセージ】
BGPは4種類のメッセージをやり取りすることで、手動で定義したネイバーとのネイバー関係を確立/維持して、BGPネイバーテーブル、BGPテーブル、ルーティングテーブルを最新に保つ。
OPEN
TCPコネクションの確立後、BGPネイバーとのセッションを開始するための最初のメッセージ。
OPENメッセージには「バージョン、AS番号、BGPのルータID、holdtime、認証」の情報がある。
UPDATE
BGPテーブル作成時に送信される全てのルート情報、または変更発生時に送信される差分のルート
情報が含まれるメッセージ。送信されるルート情報には、パスアトリビュートの情報も含まれる。
KEEPALIVE
BGPネイバー関係を維持するための生存確認メッセージ。Ciscoルータではデフォルトで60秒ごとに
KEEPALIVEメッセージが送信される。なお、BGPネイバーのダウンとみなすホールドタイムは180秒。
NOTIFICATION
エラーを検出した時に通知されるメッセージ。BGPネイバーが確立できない場合や、ホールドタイム
を超過した場合などにNOTIFICATIONメッセージでエラー通知を行い、BGPセッションを切断する。
ROUTE REFRESH
相手ルータに対し 全経路情報を要求するメッセージ
【6つの状態と状態遷移】
BGPでは「OPEN/UPDATE/KEEPALIVE/NOTIFICATION」メッセージをやりとりすることによって、
以下の6つのいずれかの状態になる。Established状態に遷移すればBGPネイバーは完全に確立する。
show ip bgp neighborsコマンドの3行目の"BGP state"項目で、以下の状態を確認することができる。
Idle
BGPの設定直後の状態。BGPネイバーへのIP到達性があればTCP接続を開始する状態。
BGPネイバーへのIP到達性があれば「Connect」状態へ遷移する。
Connect
TCP接続の完了を待っている状態。TCP接続が成功した場合はOPENメッセージを送信
して「OPEN Sent」状態へ遷移する。TCP接続が失敗した場合は「Active」状態へ遷移。
Active
TCP接続を試行している状態。ネイバーのIPアドレス、AS番号、認証パスワードの設定
ミスがある場合、Active状態のままとなるか「idle→Active→idle」という状態を繰り返す。
Open Sent
OPENメッセージを送信し、BGPネイバーからのOPENメッセージ確認を待っている状態。
OPENメッセージが受理できる場合、KEEPALIVEメッセージの送信を開始して、OPEN
Confirm状態に遷移。受理できない場合は、NOTIFICATIONを送信してidle状態へ遷移。
Open Confirm
KEEPALIVEメッセージ、または、NOTIFICATIONメッセージを待っている状態。
KEEPALIVEを受信すれば「Established」状態へ遷移(BGPネイバー確立の成功)
AS番号の不一致などによってNOTIFICATIONを受信した場合は「idle」状態へ遷移。
Established
BGPネイバーが正常に確立している状態。この状態の後、UPDATEメッセージを交換でき
BGPテーブルやルーティングテーブルが生成される。この「Established」状態になっても
NOTIFICATIONメッセージを受信した場合には「idle」状態へ遷移する。
【BGPのベストパス選択アルゴリズム】
BGPでは、宛先に到達するためのパスが複数ある場合、先ずそれらのパスをBGPテーブルに格納し、そこから1つパスのみルーティングテーブルにインストールする。
複数のパスの中から最適経路を1つだけ選択するためには以下の「ベストパス選択のアルゴリズム」を使用する。
BGPのパス属性には以下のような優先順位があり、"NEXT_HOPアトリビュートのIPアドレスに到達できること"を前提として、以下の比較条件が満たせるまで次の比較条件に進み、ベストパスが1つだけ選択される。ベストパスはBGPテーブルで>と表示される。
※"宛先ネットワークのネクストホップに到達できなければ、そのルートはベストパスにはならない"ということになる。
1 Cisco独自のWEIGHTアトリビュートが最も大きいルートを優先
2 LOCAL_PREFアトリビュートが最も大きいルートを優先
3 ローカルルートが発生元であるルート(networkコマンドで生成したルート)を優先
4 AS_PATHアトリビュートが最も短いルートを優先
5 ORIGINアトリビュートが最も小さいルートを優先( IGP < EGP < Incomplete )
6 MED(MULTI_EXIT_DISC)アトリビュートが最も小さいルートを優先
7 IBGPで学習したルートよりもEBGPで学習したルートを優先
8 ネクストホップに対して最小のIGPメトリックを持つルートを優先
9 EBGPネイバーから受信したルートのうち、最も古いルート(先に受信したルート)を優先
10 ルータIDが最小のBGPピアから受信したルートを優先
11 BGPピアのIPアドレスが最小のルートを優先
ルートのWEIGHT値が同じである場合はLOCAL_PREF値を比較し、LOCAL_PREF値も同じである場合は、ローカルルートが発生元であるかを確認する、という流れで優先度順で比較差が出るまでチェックされる。
※最後まで差が出ない場合は、ルータIDが小さいBGPピアから伝えられた経路を優先。
【BGPのルータID】
BGPルータIDは、BGPのベストパス選択アルゴリズムで最後まで差が出なかった場合に使用される。
BGPルータIDを比較して小さい方のBGPピアから伝えられた経路を優先するので、静的割り当てにより意図的にベストパス選択に影響を与えることができる。
静的に設定しない場合は、有効なループバックインターフェースの中で一番大きなループバックアドレスが割り当てられる。有効なループバックインターフェースがない場合は、それ以外のインターフェースの中で一番大きなIPアドレスが割り当てられる。
■BGPルータIDの静的割り当て
(config-router)# bgp router-id {ルータIDに設定したいIPアドレス}
【eBGPにおけるループ回避】
BGPルートのループ防止のために、AS_PATHアトリビュートを利用しており、BGPルートに付加されているAS_PATHアトリビュートに自AS番号が含まれていると、ルートはループしているとみなして受信しない
⇒AS_PATH属性に自身のAS番号を含む経路情報を破棄する。
※BGP経由で学習したルート情報のAS_PATHに自身のAS番号が含まれている場合でも、ルート情報を破棄せず、学習可能
(config)# router bgp 456
(config-router)# network 10.0.0.0 mask 255.255.255.0
(config-router)# neighbor 10.0.0.1 remote-as 123
(config-router)# neighbor 10.0.0.1 allowas-in
※特定のネイバーへBGPルートをアドバタイズするときに、AS_PATHの先頭のAS番号を自AS番号に書き換える。
(config)# router bgp 456
(config-router)# network 10.0.0.0 mask 255.255.255.0
(config-router)# neighbor 10.0.0.1 remote-as 123
(config-router)# neighbor 10.0.0.1 as-override
【BGPピアグループ】
ピアグループとは、同じアウトバウンドポリシー(ルートマップやディストリビュートリストなど)を適用するピアをグループ化する機能。
BGPでは複数のピアに対して同じ設定を繰り返すことが多いので、ピアグループを利用することで設定効率が良くなる。
ピアグループの主な特徴とルールは以下の通り。
・ローカルでのみ有効
・設定をグループごとにまとめられるので設定効率が上がる
・UPDATEメッセージがグループごとに生成されるようになるのでルータの負荷が減る
・アウトバウンドのポリシーは個別に設定できない
・インバウンドのポリシーは個別にも設定できる
BGPピアグループの設定
■ピアグループを作成する
(config)# router bgp {AS番号}
(config-router)# neighbor {グループ名} peer-group
■ピアグループごとに共通になるパラメータを設定(オプション)
(config-router)# neighbor {グループ名} remote-as {AS番号}
(config-router)# neighbor {グループ名} update-source {インターフェース}
(config-router)# neighbor {グループ名} route-map {ルートマップ名} {in | out}
■ピアグループにまとめるピアを指定
(config-router)# neighbor {ピアのIPアドレス} peer-group {グループ名}
【BGPピア設定】
ネイバーとの接続に可用性を持たせたい場合、loopbackやSVIのIF間でピアリングを組むことがある。
BGPメッセージを送信する際に送信元アドレスは出力IFのIPアドレスを使用するのに対し、宛先アドレスはneighbor remote-asコマンドで指定したアドレスをデフォルトで使用する。
BGPメッセージを受信したBGPルータは、BGPメッセージに含まれた送信元IPアドレスと、設定上のneighbor remote-as コマンドで指定した宛先IPアドレスを比較して、一致した場合にBGPネイバーを組む.
Loopback(直接接続ではない経路)をeBGPピアにする
① 直接接続ではないので neighborコマンドで指定するアドレスへの経路がない
⇒ スタティックルートなどで経路を作成する
② 受信するBGPメッセージの送信元アドレスとneighborコマンドで指定するピアのアドレスが一致しなくなる
⇒ neighborにupdate-source {VLANXXXX|loopbackX}コマンドで送信元アドレスを変更する
③ eBGPパケットのTTL(time to live)は「デフォルトで1」なので、直接接続していない(コードC以外の)経路にはパケットを送信しない ※iBGPの場合はTTL255。
⇒ ebgp-multihopコマンドでTTLを変更する(2以上にすることで直接接続していない経路にもパケットを送信するようになる)
⇒ disable-connected-checkコマンドで直接接続していない経路にもパケットを送信させる
【BGPの認証】
BGPはMD5認証をサポートしている。
MD5認証では、パスワードを使用してお互いを認証するので証明書は不要。
ネイバー間で異なるパスワードを設定していた場合、ネイバー関係を確立できないため通信を行うことができない。
■認証設定コマンド(ピア/ピアグループに設定する場合)
Router(config-router)# neighbor {IPアドレス/グループ名} password {パスワード}
【経路集約】
BGPの自動経路集約では、BGPへ再配送されるルートに対して集約が行われる。
networkコマンドで指定したルートなどBGPでアドバタイズするルートが自動集約される訳ではないため注意。
Ciscoの機器ではBGPにおける自動集約がデフォルトで無効になっている。
自動集約を有効化するには以下のコマンドを使用する。
(config)#router bgp {自身のAS番号}
(config-router)#auto-summary
自動集約を無効化するには以下のコマンドを使用します。
(config)#router bgp {自身のAS番号}
(config-router)#no auto-summary
【経路制御】
ACL、Prefix-listで一致したアドレスをINやOUTで指定できる。
MED値の変更などを行いたい場合は、route-mapのmatchコマンドで、ACL、Prefix-list、AS_PATHアクセスリストを指定し、フィルタリング後にsetコマンドで属性を変更する。
matchはACLよりもPrefix-listの方が柔軟に行える。
ip prefix-list PREFIX1 seq 5 permit 192.168.10.0/24
ip prefix-list PREFIX1 seq 10 permit 10.0.0.0/24
ip prefix-list PREFIX1 seq 15 permit 172.21.168.0/24
!
access-list 3 permit any
!
route-map ROUTEMAP permit 10
match ip address prefix-list PREFIX1
set metric 50
!
route-map TO-INTERNET permit 10
match ip address 3 ###3はACL番号
set ip next-hop 192.168.100.6
!
router bgp XXXXX
neighbor 192.168.1.6 route-map ROUTEMAP out
neighbor 192.168.1.2 prefix-list PREFIX1 in
※permit,deny句がややこしくなるので注意。適当にやると管理が大変になりそう。
ルート マップでは permit 句と deny 句を使用できる。ACLと同様最後には暗黙のdenyがある。
deny 句は、ルートの照合の再配布を拒否する。ルートマップでは、一致基準としてACL を使用できる。
ACL には permit 句と deny 句もあるため、パケットがACLと一致した場合に次のルールが適用される。
ACL permit + route map permit:指定されたトラフィックはポリシールーティングに従う
ACL permit + route map deny:指定されたトラフィックはポリシールーティングが適用されず、通常処理される
ACL deny + route map permit:指定されたトラフィックはACLでブロックされ、ルートマップの評価は行われず、通常処理される(ACLにdenyされた時点でルートマップから除外されるため)
ACL deny + route map deny:指定されたトラフィックはACLでブロックされ、ポリシールーティングも適用されず、通常処理される
router bgp 65002 #1
no synchronization
bgp log-neighbor-changes
neighbor 110.1.1.1 remote-as 65001 #2
neighbor 110.1.1.1 route-map test in #3
neighbor 192.168.1.1 remote-as 65002 in #4
neighbor 192.168.1.2 remote-as 65002 in #5
!
access-list 1 permit 172.16.1.0 0.0.0.255 #6
!
route-map test permit 10 #7
match ip address 1
set local-preference 150 #8
!
route-map test permit 20 #9
!
【1】BGPを有効化(自身が所属するASは65002)
【2】AS65001に所属する 「110.1.1.1」と ピアを確立(eBGPピア)
【3】110.1.1.1のピアから送られてきた経路情報にルートマップ「 lptest 」を適用
【4】AS65002に所属する 「192.168.1.1」と ピアを確立(iBGPピア)
【5】AS65002に所属する 「192.168.2.2」と ピアを確立(iBGPピア)
【6】ルートマップで利用するアクセスリスト「1」を作成(172.16.1.0/24 が対象)
【7】ルートマップ「 lptest 」を作成(シーケンス番号10)
【8】アクセスリスト「1」に一致したら ローカルプリファレンスを150にする
【9】暗黙のdeny回避用の設定(matchがないので全てに一致、setがないので何も変更しない)
110.1.1.1のピアから送られてきた「172.16.1.0/24」の経路情報のローカルプリファレンスを150にしている。
ローカルプリファレンスのデフォルト(100)よりも高くしているため、「172.16.1.0/24」への経路は RCから 110.1.1.1へ向かう経路が優先されることになる。
ルートリフレクタ
ルートリフレクタはiBGPピアから受信したルートを別のiBGPピアに反射する(伝える)機能。
iBGPではiBGPスプリットホライズン(iBGPピアから受信した経路情報を他のiBGPピアに伝えない)
という働きがあるため、AS内の一部BGPスピーカが経路情報を学習できないという状況が発生する。
これを回避するにはルートリフレクタを使用することでフルメッシュ(全スピーカと隣接関係を結ぶ)にすることなく iBGPスプリットホライズンの問題を解決できる。
RouterC(config)#router bgp 65200 ・・・AS番号65200でBGPを起動
RouterC(config-router)#neighbor 100.1.1.1 remote-as 65200 ・・・100.1.1.1をiBGPピアに指定
RouterC(config-router)#neighbor 110.1.1.2 remote-as 65200 ・・・110.1.1.2をiBGPピアに指定
RouterC(config-router)#neighbor 100.1.1.1 route-reflector-client ・・・100.1.1.1(RouterB)をクライアントに指定(RouterCをルートリフレクタに)する。
クライアントに指定されなかったRouterDはノンクライアントになる。
設定パラメータ例
router bgp 65XXX
bgp router-id 192.168.1.1
bgp log-neighbor-changes
!
address-family ipv4 vrf VRFNAME
network 172.21.10.0 mask 255.255.255.0 ### 自分のAS内のルート情報をBGPでアドバタイズするNWアドレス
network 172.22.20.3 mask 255.255.255.255
neighbor 192.168.1.6 remote-as 17XXX ### 対向ASとのネイバー設定(eBGP)
neighbor 192.168.1.6 description eBGP
neighbor 192.168.1.6 password 7 094xxxxxxxxxxxxxxx
neighbor 192.168.1.6 timers 30 90
neighbor 192.168.1.6 fall-over bfd
neighbor 192.168.1.6 activate
neighbor 192.168.1.6 soft-reconfiguration inbound
neighbor 192.168.1.6 route-map ROUTEMAP_NAME out ### route-mapでフィルタリング
neighbor 192.168.1.2 remote-as 65XXX ### 自ASとのネイバー設定(iBGP)
neighbor 192.168.1.2 update-source Vlan3333 ### BGPパケットの送信元IPアドレスとしてSVIのIFを使用する
neighbor 192.168.1.2 timers 30 90 ### keepaliveの送信間隔(デフォ60秒)/holdtimeタイマー(デフォ180秒)の設定
neighbor 192.168.1.2 fall-over bfd ### 指定したBGPピアへの到達性をBFDで監視するよう設定
neighbor 192.168.1.2 activate ### ネイバーがIPv4ユニキャストアドレスファミリのプレフィックスをローカルデバイスと交換できるようにする。
neighbor 192.168.1.2 next-hop-self ### iBGPの特徴として、ネイバーにルートを広告する際にNexthopのIPアドレスが変更されない(eBGPの場合は変更される)ため、到達可能性に問題が発生する場合がある。192.168.1.2へ広報する際にNEXT_HOPを自身のアドレスに書き換える機能
neighbor 192.168.1.2 soft-reconfiguration inbound ### 指定したBGPピアまたはBGPピアグループから受信した、フィルタリング前のオリジナルの経路情報を保持しておくように設定
neighbor 192.168.1.2 prefix-list PREFIX_INFILTER_NAME in ### BGPルートを受信する時にPrefixフィルタリングを適用
neighbor 192.168.1.2 prefix-list PREFIX_OUTFILTER_NAME out ### BGPルートを送信する時にPrefixフィルタリングを適用
maximum-paths 2
exit-address-family
!
access-list 1 permit any
ip prefix-list PREFIX_INFILTER_NAME seq 10 permit 172.22.20.3/32
ip prefix-list PREFIX_OUTFILTER_NAME seq 20 deny 0.0.0.0/0 le 32
!
clear ip bgp ネイバーアドレス soft out
設定例(as-override , allowas-in)
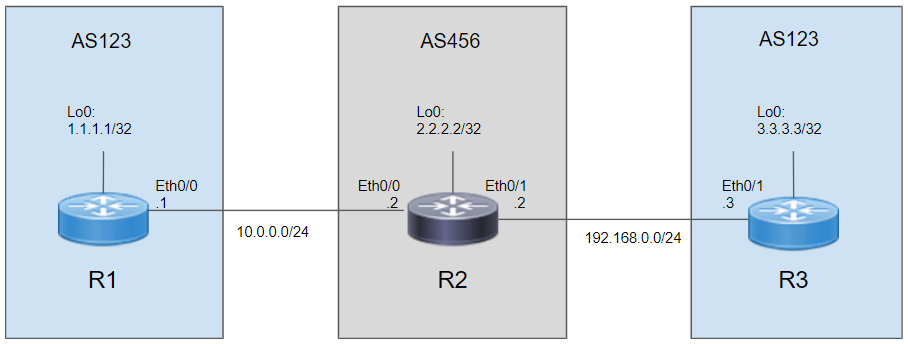
上記のようにPE(AS456)-CE(AS123)間でBGPを利用するとき、CEルータのAS番号は同じにすることがある。すると、AS_PATHによるループ防止によってBGPルートは無効になってしまう。
解決策として、as-overrideコマンドをPEに設定することで、特定のネイバーへBGPルートをアドバタイズするときにAS_PATHの先頭のAS番号を自AS番号に書き換える。
R2(config)# router bgp 456
R2(config-router)# network 10.0.0.0 mask 255.255.255.0
R2(config-router)# network 192.168.0.0 mask 255.255.255.0
R2(config-router)# network 2.2.2.2 mask 255.255.255.255
R2(config-router)# neighbor 10.0.0.1 remote-as 123
R2(config-router)# neighbor 10.0.0.1 as-override
R2(config-router)# neighbor 192.168.0.3 remote-as 123
R2(config-router)# neighbor 192.168.0.3 as-override
ちなみに、
Allowas-in(AS_Path属性に自身のAS番号が含まれている経路情報も受け入れる)をCEに設定することでも解決できる。
【コマンド構文:Allowas-inの有効化】
R3(config-router)# neighbor 192.168.0.2 allowas-in
確認コマンド
show ip bgp neighbors
show ip bgp summary
show ip bgp vpnv4 vrf XXX neighbors xxx.xxx.xxx.xxx advertised-routes
show ip bgp vpnv4 vrf XXX neighbors xxx.xxx.xxx.xxx routes
■再配送
再配送とは、あるルーティングプロトコルで受け取ったルート情報を別のルーティングプロトコルを使って伝達すること。
再配送は以下のような場面で使用される。
・ルーティングプロトコルを新しいものに移行するための一時的な処置
・マルチベンダ環境
・ルータにより使用しているルーティングプロトコルが異なるとき
[コマンド構文:OSPFへの再配送]
Router(config)# router ospf {プロセスID}
Router(config-router)# redistribute {プロトコル} [metric {値}] [metric-type {タイプ}] [tag {タグ}] [route-map {マップ名}] [subnets]
プロトコル ⇒再配送元になる「RIP」や「EIGRP{AS番号}」や「static」や「connected」などを指定
metric ⇒シードメトリックを指定(デフォルトは20だが、BGPからの再配送については1)
metric-type ⇒OSPFの外部メトリックタイプ1またはタイプ2を指定(デフォルトは2)
tag ⇒0~4294967295のタグ値を付加
route-map ⇒ルートマップを使用
subnets ⇒サブネット化されたルートも再配送(省略した場合はサブネット化されていないルートのみ再配送)
※「subnets」オプションは機種やIOSのバージョンによって動作が異なる。機種によっては「subnets」オプションを明示的に指定しなくてもサブネット化されたルートを再配送する場合がある。
[コマンド構文:BGPへの再配送]
Router(config)# router bgp {AS番号}
Router(config-router)# redistribute {プロトコル} [match {条件}] [metric {値}] [route-map {マップ名}]
プロトコル ⇒再配送元になる「EIGRP {AS番号}」や「OSPF {プロセスID}」や「static」や「connected」などを指定
match ⇒再配送する経路を選択(プロトコルにOSPFを指定した場合に使用可能なオプション)
{internal}OSPFの内部ルートのみを再配送する
{external 1}OSPFのASが持つ、外部メトリックタイプ1のルートのみを再配送する
{external 2}OSPFのASが持つ、外部メトリックタイプ2のルートのみを再配送する
metric ⇒シードメトリックを指定(IGPのメトリックをそのままMEDにする)
route-map ⇒ルートマップを使用
[コマンド構文:再配送用のルートマップの設定]
(config)# route-map {マップ名} [permit | deny] [シーケンス番号]
(config-router-map)# match {条件}
(config-router-map)# set {動作}
マップ名 ⇒任意の名前を入力
permit ⇒経路情報の再配送を行う
deny ⇒経路情報の再配送を行わない
シーケンス番号 ⇒ルートマップの処理を行う順番(若い番号から順に処理される)
match ip address {ACL} ⇒一致条件にACL番号またはACL名を使用する
match ip address prefix-list {リスト名} ⇒一致条件にプレフィックスリストを使用する
match length {最小値} {最大値} ⇒一致条件にL3のパケット長を使用する
match route-type {internal | external} ⇒一致条件にルートタイプを使用する
match tag ⇒一致条件にタグを使用する
set metric ⇒「match」に一致した経路情報のメトリックを変更する
set metric-type {internal | external | type-1 | type-2} ⇒「match」に一致した経路情報のルートタイプを変更する
set tag ⇒「match」に一致した経路情報にタグを付ける
【再配送の主な注意点】
・ルーティングループが発生しないように注意が必要
・RIPやEIGRPに再配送するにはシードメトリックの設定が必要
・OSPFに再配送されるのはデフォルトでサブネット化されていないルートだけ
・OSPFからBGPに再配送されるのはデフォルトでエリア内ルートとエリア間ルートだけ