はじめに
この記事は、MATLABのN-wayToolboxというフレームワークを利用してPARAFAC(Parallel Factor Analysis)を実装した際の備忘録です。N-wayToolboxは、多次元データ解析の分野で広く用いられており、PARAFACを実行するための代表的なツールボックスの一つです。
PARAFACは、蛍光分析データ(例えば、励起蛍光マトリクス:EEM)のように複数の成分が重なり合っている多次元データから、それぞれの潜在的な成分を分離するのに非常に有効な手法です。この記事では、PARAFACのアルゴリズムの概要から、N-wayToolboxを使った具体的な実装方法までを解説します。
目次
なぜPARAFACを使うのか
データ分析において、複数の要因が複雑に絡み合った多次元データは、その潜在的な構造を把握するのが難しい場合があります。特に、蛍光分析で得られるEEMデータは、複数の蛍光成分が重なり合って観測されるため、個々の成分を分離して解析することが困難です。
PARAFACは、このような多次元データを少数の潜在的な因子の組み合わせに分解し、データの構造を抽出する多変量解析手法です。これにより、重なり合った複数のピークを個別の成分として分離し、データの背後にある本質的なパターンを明らかにすることが可能になります。
アルゴリズムについて
↓後述で使用するコードの作成者による論文
PARAFACの計算原理
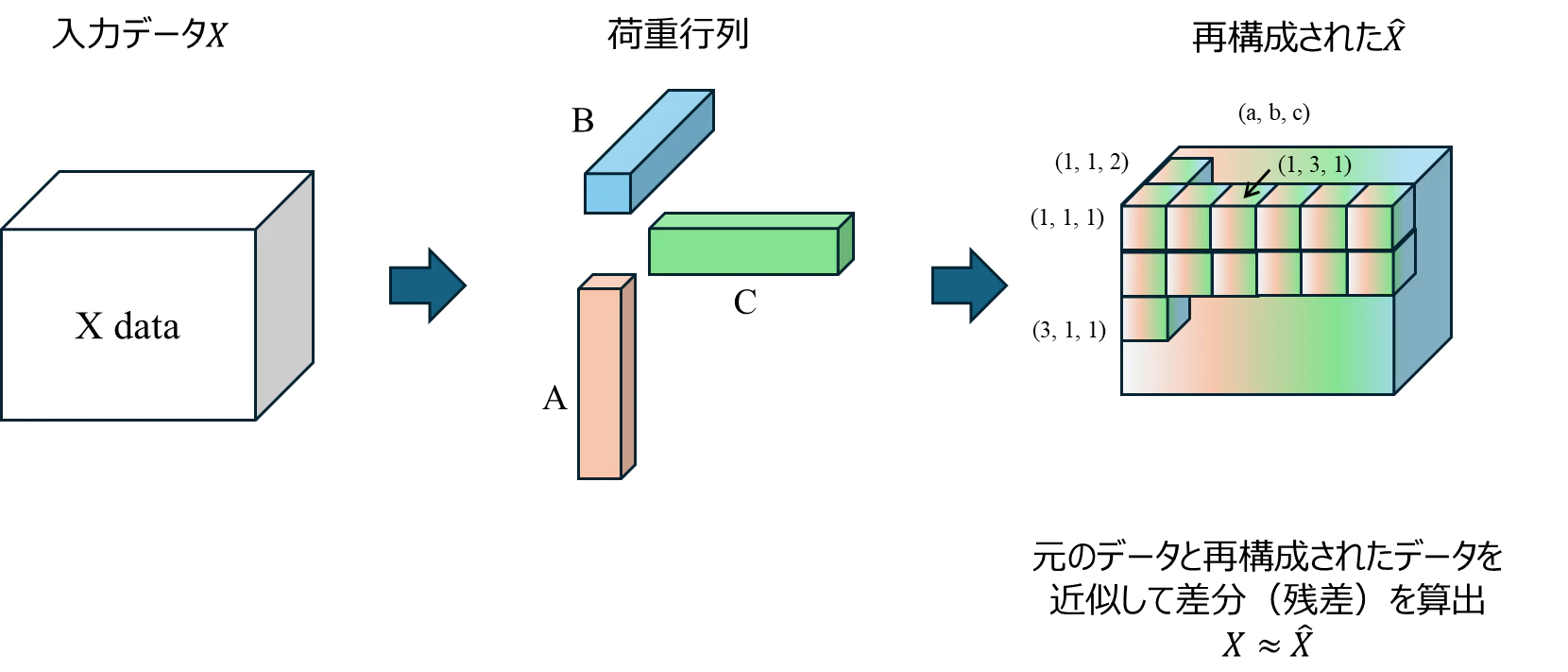
PARAFAC(Parallel Factor Analysis)は、多次元データを少数の潜在的な因子の組み合わせで表現し、データの構造を抽出する多変量解析手法である。3次元データ(テンソル)Xの場合、このモデルは以下の数式で定義される。
$$
xijk≈∑_{f=1}^Fa_{if}b_{jf}c_{kf}+e_{ijk}
$$
ここで、$x_{ijk}$はテンソルの要素、Fは因子の数、$a_{if}, b_{jf}, c_{kf}$は各次元に対応する荷重行列の要素、$e_{ijk}$は残差である。
1. 荷重行列の算出(交互最小二乗法)
PARAFACモデルの計算には、主に交互最小二乗法(ALS)が用いられる。このアルゴリズムは、以下の手順を繰り返すことで、誤差(残差の二乗和)が最小となるように荷重行列A,B,Cを最適化する。
- 初期化: まず、因子の数Fを決定し、荷重行列A,B,Cをランダムな値で初期化する。
-
更新:
- 行列BとCを固定し、残差が最小となるように行列Aを更新する。
- 次に、行列AとCを固定し、残差が最小となるように行列Bを更新する。
- 最後に、行列AとBを固定し、残差が最小となるように行列Cを更新する。
このプロセスを1つの反復(iteration)として繰り返す。
2. モデルの評価と反復停止
各反復の後、モデルの精度を評価する。入力データXと、現在の荷重行列から再構成されたデータ($\hat{X}=∑_{f=1}^Fa_{if}b_{jf}c_{kf}$)との間の誤差(残差の二乗和など)を算出する。
この反復計算は、以下のいずれかの条件が満たされた時点で停止する。
- 最大反復回数に達した場合。
- 誤差の変化率が事前に設定した閾値を下回った場合。
最終的に、最も誤差の小さいモデル(最適な荷重行列)を出力する。
わかりやすかった記事
Understanding the CANDECOMP/PARAFAC Tensor Decomposition, aka CP; with R code
実装方法
1. N-waytoolboxのダウンロード
MATLABホームの「アドオンの入手」を開く
N-wayToolboxと検索し、ダウンロードする
2. デモデータでPARAFACを実行
デモデータを作成してPARAFACのデモを行う。
2.1. 3次元データの作成
clear;clc;close all
% 3次元テンソルのサイズ
n_time = 100; % 時間軸のサンプル数
n_channels = 10; % チャンネル数
n_spectra = 50; % スペクトルの次元数
tensor_data = zeros(n_time, n_channels, n_spectra);
% 2つのピークの位置を設定
peak1_position = [40, 3, 20];
peak2_position = [60, 7, 30];
% ピークの強度
peak1_strength = 1;
peak2_strength = 1;
% ピークをデータに追加
for t = 1:n_time
for c = 1:n_channels
for s = 1:n_spectra
% ピーク1とピーク2の影響を加算
tensor_data(t, c, s) = tensor_data(t, c, s) ...
+ peak1_strength * exp(-((t - peak1_position(1))^2 + (c - peak1_position(2))^2 + (s - peak1_position(3))^2) / 5) ...
+ peak2_strength * exp(-((t - peak2_position(1))^2 + (c - peak2_position(2))^2 + (s - peak2_position(3))^2) / 5);
end
end
end
% データの確認
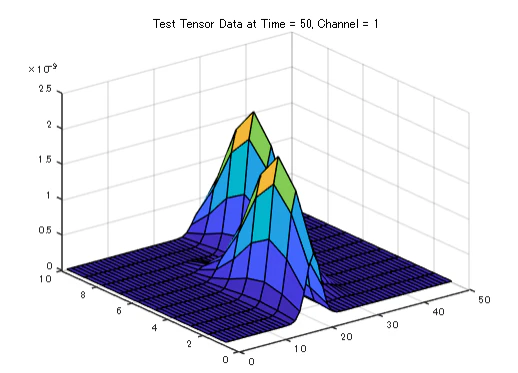
figure;
surf(squeeze(tensor_data(50, :, :)));
title('Test Tensor Data at Time = 50, Channel = 1');
xlabel('Spectral Dimension');
ylabel('Channels');
zlabel('Intensity');
2.2. PARAFACの実行
[Factors,it,err,corcondia] = parafac(X, fac);でPARAFACを実行
入力引数と出力引数は、それぞれ以下の通りです。
入力引数
X : 対象とする多次元配列データ
fac : ファクター数(何個に分離するか)
出力引数
Factors : 荷重行列。Xが[100, 10, 50]かつfac=2の時、Factorsは、[[100, 2],[10, 2],[50, 2]]の行列
it : 使用された反復回数。アルゴリズムが収束したのか、単に最大反復回数に達したのかをチェックするのに役立ちます (デフォルトは 2500)。
err : モデルの適合度 = 誤差の2乗和(欠損要素を含まない)。
corcondia : コアの一貫性テスト。理想的には100%であるべき。100% を大幅に下回る場合、モデルは有効でない。
また、factorsはセル配列で格納されており、[dim1,dim2,dim3] = fac2let(factors);を使用することでarray配列へと変換することができる。
% 荷重行列の数を設定
factor = 2;
% PARAFACを実行
[factors,it,err,corcondia] = parafac(tensor_data, factor);
% 結果をArray配列へ
[dim1,dim2,dim3] = fac2let(factors);
2.3. 各ファクターの結果を可視化
分離結果を可視化するためにdim2,dim3 のテンソル積を算出する。
計算処理としては以下の通り、
figure;
for i = 1:factor
F = ckron(dim2(:, i), dim3(:, i)');% n-waytoolboxから提供
subplot(1,factor,i)
hold on;
surf(squeeze(F))
end
%F([10, 50]の行列)= dim2([10, 1]の行列)×dim3([50, 1]の行列)の転置行列
F = ckron(dim2(:, i), dim3(:, i)');
dim2とdim3のテンソル積は、特定のファクター(i)におけるスペクトル形状を表します。この計算によって、各ファクターがどのような波長パターンを持つのかを可視化できます。
この計算にはグローバル関数であるkronを使用することもできます。
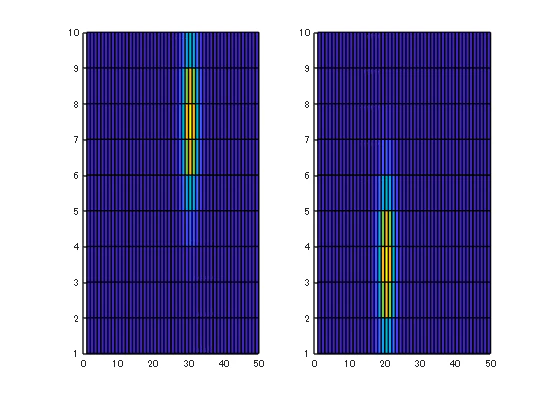
2.4. 結果の可視化
デモデータの可視化結果を考察すると、左図のファクター1は、設定した2つのピークのうち、一方(z=20付近)のスペクトル形状を捉えている可能性があり、右図のファクター2は、もう一方のピーク(z=30付近)を捉えていることが示唆されます。このように、PARAFACによって、重なり合った複数のピークを個別の成分に分離できていると解釈できます。