はじめに
最近「Rustコンパイラが高速化した」という記事を見かけました。元ネタはこのブログですね。このブログの1つ前の記事は「2019年のRustコンパイラ高速化コミット一覧」みたいな内容なのですが、そこでPipelined compilationがそろそろ安定化されそうだと紹介されていました。
ちょうど手元にコンパイルの重いソースコードがあったので、その効果を測定してみました。
Pipelined compilationとは
今のRustコンパイラは依存関係のある複数のクレートは順番にコンパイルしています。例えばlibBがlibAに依存している場合
0s ----------------------------------10s------------------------------------20s
[libAのコンパイル ] [libBのコンパイル ]
という感じで、それぞれ10秒ずつ計20秒でコンパイルするイメージです。
Pipelined compilationではこれを
0s ----------------------------------10s------------------------------------20s
[libAのメタデータ生成][libAのコンパイル]
[libBのメタデータ生成][libBのコンパイル]
とします。後続のクレートが必要とするメタデータを先に生成して、できたところで後続のコンパイルをスタートさせます。というわけで、特に複数のクレートに分割された大規模なコードで効果を発揮しそうです。
測定対象
ここにあるソースコードです。とある言語のパーサ(作りかけ)ですが、今は内容はどうでもよくて問題はサイズです。
大きなクレートは2つあって
| crate | サイズ | サイズ(マクロ展開後) |
|---|---|---|
| sv-parser-parser | 571KB(18000行) | 892KB(22000行) |
| sv-parser-syntaxtree | 347KB(11000行) | 4822KB(110000行) |
となっています。特にマクロ展開後のサイズはServoあたりの巨大クレートともいい勝負という感じになっています。デバッグビルドでも1-2分はかかるので、これが速くなると結構嬉しいです。
また、sv-parser-parserがsv-parser-syntaxtreeに依存しているのでちょうどpipelined compilationが効きそうな構成です。
対象バージョン
現在pipelined compilationは安定化されていないのでnightlyを使います。以下のように環境変数CARGO_BUILD_PIPELININGで有効化できます。
CARGO_BUILD_PIPELINING=true cargo +nightly build
比較対象としてここ最近のstableと現在のbetaを測定しました。バージョンとしては1.34~1.36と1.37.beta, 1.38.nightlyとなります。
測定方法
Rust製のベンチマークツールhyperfineを使いました。自動で複数回実行して平均・標準偏差・最大・最小を取ってくれたり、各試行前のクリーンアップコマンドを指定できたりして便利です。
コマンドと結果表示ははこんな感じです。
$ hyperfine -p "cargo clean" \
"rustup override set nightly; CARGO_BUILD_PIPELINING=true cargo check" \
"rustup override set beta ; cargo check" \
"rustup override set 1.36.0 ; cargo check" \
"rustup override set 1.35.0 ; cargo check" \
"rustup override set 1.34.0 ; cargo check"
Benchmark #1: rustup override set nightly; CARGO_BUILD_PIPELINING=true cargo check
Time (mean ± σ): 56.946 s ± 0.228 s [User: 104.089 s, System: 4.363 s]
Range (min … max): 56.638 s … 57.328 s 10 runs
Benchmark #2: rustup override set beta ; cargo check
Time (mean ± σ): 58.317 s ± 0.283 s [User: 104.320 s, System: 4.538 s]
Range (min … max): 57.896 s … 58.651 s 10 runs
Benchmark #3: rustup override set 1.36.0 ; cargo check
Time (mean ± σ): 60.227 s ± 0.258 s [User: 106.636 s, System: 4.573 s]
Range (min … max): 59.829 s … 60.762 s 10 runs
Benchmark #4: rustup override set 1.35.0 ; cargo check
Time (mean ± σ): 64.896 s ± 0.307 s [User: 111.867 s, System: 4.715 s]
Range (min … max): 64.374 s … 65.382 s 10 runs
Benchmark #5: rustup override set 1.34.0 ; cargo check
Time (mean ± σ): 64.144 s ± 0.261 s [User: 110.511 s, System: 4.815 s]
Range (min … max): 63.818 s … 64.620 s 10 runs
Summary
'rustup override set nightly; CARGO_BUILD_PIPELINING=true cargo check' ran
1.02 ± 0.01 times faster than 'rustup override set beta ; cargo check'
1.06 ± 0.01 times faster than 'rustup override set 1.36.0 ; cargo check'
1.13 ± 0.01 times faster than 'rustup override set 1.34.0 ; cargo check'
1.14 ± 0.01 times faster than 'rustup override set 1.35.0 ; cargo check'
結果
1.34を100%としたときのコンパイル時間の比較結果はこんな感じになりました。
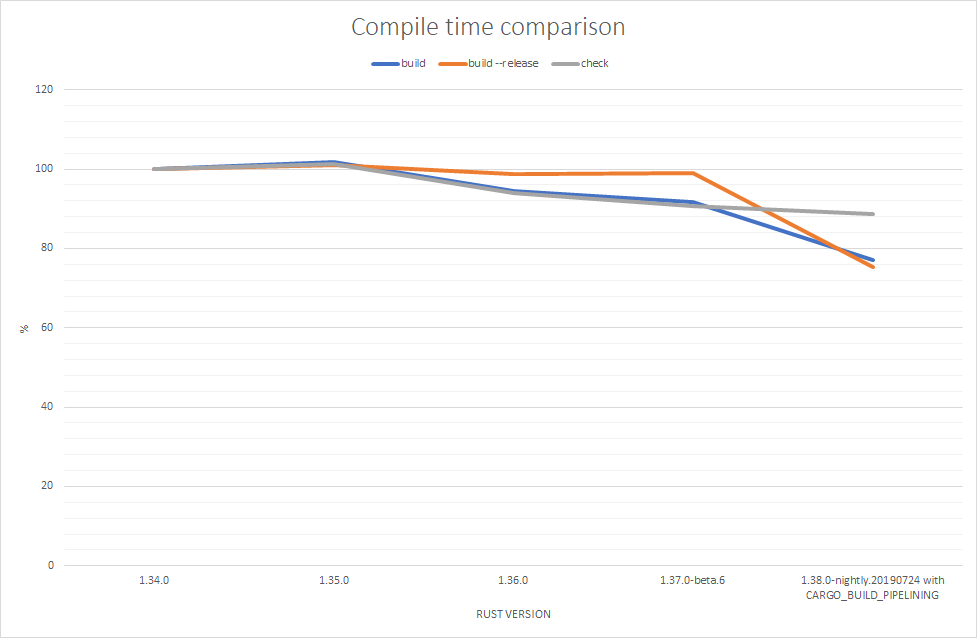
デバッグビルド・リリースビルド共にpipelined compilationで20%近く高速化しています。cargo checkはバイナリを生成しないモードなので、pipelined compilationでオーバーラップするはずだったバイナリ生成のフェーズがなく、効果がないということだと思います。
Pipelined compilationの効果が出やすいという想定ではありましたが、予想以上に速くなっていてstableでのリリースが楽しみです。