はじめに
先日、自作の検索・置換ツールを作った際にgrepや他の検索ツールとのベンチマークをいろいろ取ってみたので結果を公開します。
当然ですが、検索文字列や検索対象、実行環境によって結果は異なりますので参考程度にどうぞ。
(ちなみにackも取ったのですが全ケースで他より50倍~100倍程度遅い結果になったので比較からは外しました。ackは超多機能という感じなのでgrep代替というより違うジャンルのツールと思ったほうがいいかもしれません)
前提
実行環境
- CPU: Xeon E5-2690 @ 2.90GHz × 2
- MEM: 256GB
- OS: CentOS 7.2
ツールのバージョン・オプション
基本的に各ツールともデフォルト設定重視で表示結果を揃える程度の調整です。
また、hwについてはXFSファイルシステム上で検索出来ない不具合があったため手元で暫定的に修正したバージョン(こちら)を使っています。そのため本来の速度が出ていない可能性がありますので、ご注意ください。
| tool | version | option |
|---|---|---|
grep |
2.20 | --binary-files=without-match --color=auto -r |
ag |
0.30.0 | --nogroup |
pt |
2.1.0 | --nogroup |
hw |
1.1.0 | --no-group |
sift |
0.7.1 | |
ambs |
0.2.1 |
測定方法
時間測定には/usr/bin/timeを使い、10回測定した平均を取っています。検索結果は/dev/nullに捨てたりせず、実際に表示させています。また、ディスクI/Oに影響されないよう検索対象はディスクキャッシュに乗った状態で測定しています。
結果
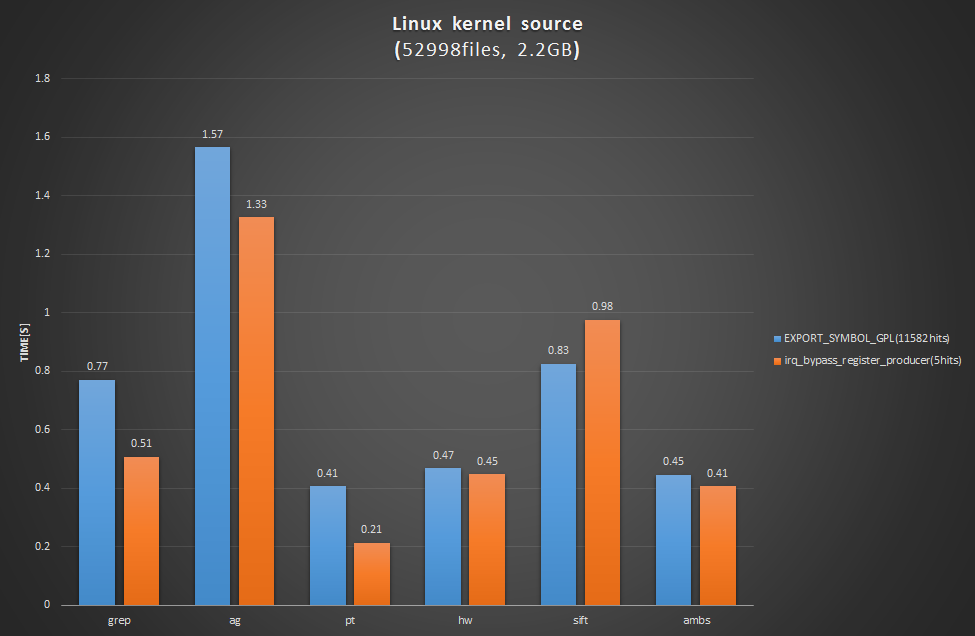
Linuxカーネルソース
linuxをクローン直後(ファイル総数約5万、2.2GB)のディレクトリ検索です。検索結果の多いキーワード(EXPORT_SYMBOL_GPL)と少ないキーワード(irq_bypass_register_producer)の2通りの結果になります。
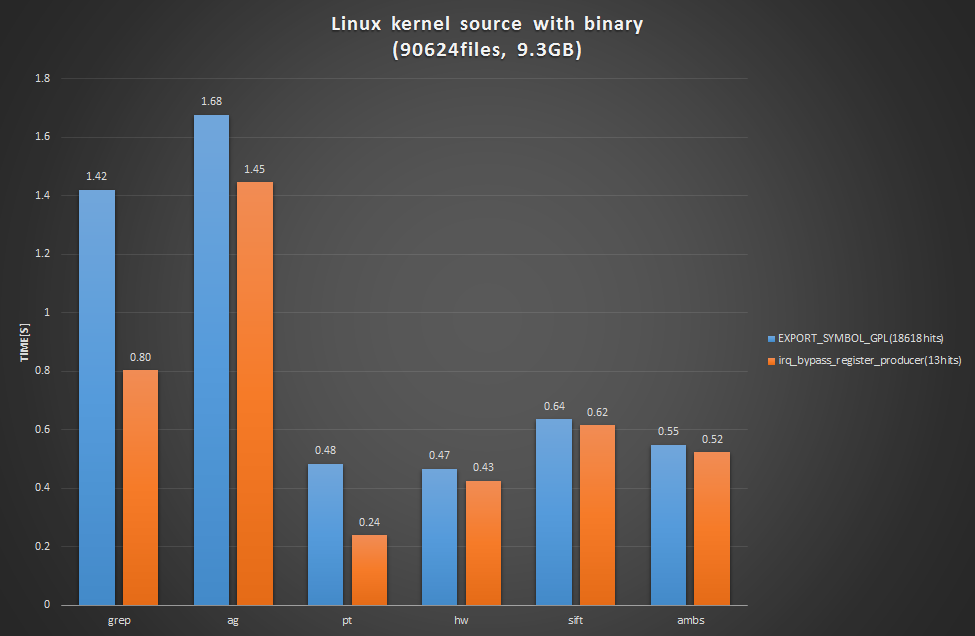
Linuxカーネルソース(ビルド済み)
↑と同じですが、カーネルビルドを行いバイナリが生成された状態(ファイル総数約9万、9.3GB)での検索結果です。生成されたバイナリは.gitignoreで無視されるので、そのあたりを考慮したツールが有利になる条件です。
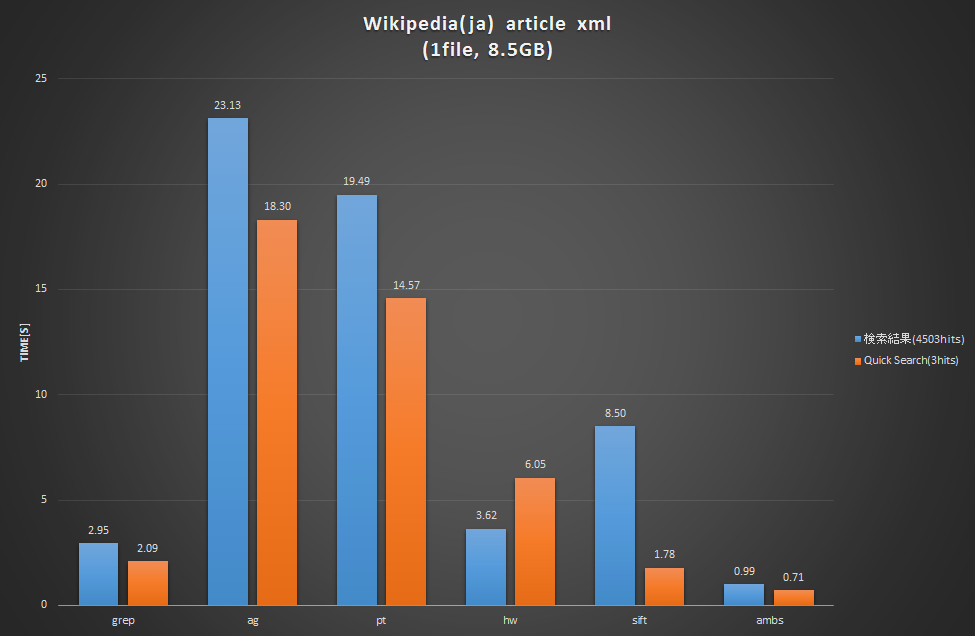
Wikipedia XML
日本語WikipediaのXML(ファイル数1、8.5GB)からの検索です。こちらも検索結果の多いキーワード(検索結果)と少ないキーワード(Quick Search)の2通り行っています。
まとめ(感想)
特に結論めいたものはありませんので、特に気になったツールについてざっくりとコメントを。
grep
シングルスレッドとは思えない速さです。32スレッドのマシンなので他のマルチスレッド系ツールが圧倒するかと思っていましたが、そうでもないようです。この結果だけを見るならgrepで十分かなぁという気もします。もちろん.gitignore無視とか日本語周りとか機能面で新しいツールを使う動機はあるのですが。
pt
CPUの使用率がすごいです(32スレッド中22スレッド程度使い切っていました)。さすがGoroutineという感じで速いのですが、個人的には検索結果の表示順序が一定しないのは少し使いづらいかなぁと感じてしまいます。
hw
結構安定して速いしEUC-JP/Shift-JIS検索も対応ということで良い感じなのですが、若干不安定です。ベンチマークのためにいろいろ試しているとSEGVで落ちたり.gitignore周りで無限再帰に陥ったりしました。いろいろパターンは発見したので、時間ができたらIssue/PRなど投げてみたいと思います。
ambs
(自分でそう作ったから、という話ではありますが)巨大ファイル検索は速いです。ファイル数が多い場合の検索は当初今の10倍くらいは遅かったのですが、ベンチマーク取っているうちに最適化したくなってしまい、1か月くらい試行錯誤しました。最終的にはだいたいのパターンで他のツールと同等の速度が出るようになったと思います。