はじめに
Elasticsearchは以下のような機械学習(Machine Learning)の機能を提供しています。
- 異常検知(Anomaly Detection)
- データフレーム分析(Data Frame Analytics)
- ベクトル検索
これらの機能に関連する情報はシステムのどこかに永続化されていないといけませんが、Elasticsearchでは(ある意味当然ながら)インデックスにドキュメントとして保存しています。Kibanaを通して利用するだけであれば特に内部のデータ構造について知る必要はありませんが、APIなどを駆使してより柔軟にMachine Learningを利用したいという場合にはそれについて詳しく知りたい場合があるでしょう。
しかしこれらのデータはあくまで内部のデータ構造で、Elasticsearchとしてはインデックス名がドット(.)から始まるシステムインデックスとして取り扱っており、公式には仕様を公開していません。またシステムインデックスの構造については予告なく変更となる場合があります。
この記事ではこれらのデータ構造について紹介します。ただ上記のような理由で公式ドキュメントがあるわけではありません。紹介する情報は私個人がリバースエンジニアリング的に調べたもので、Elasticとしての公式見解ではありませんのでその点はご承知おきください。
記事執筆時点で使ったElasticsearchのバージョンは8.12.2です。
(生成AI系の話は毛色が違うのでここでは扱いません)
ElasticsearchのMachine Learning関連インデックス
では、Elasticsearchに保存されているMachine Learning関連のシステムインデックスにはどのようなものがあるでしょうか。Machine Learningに関連するものはインデックス名が.ml-で始まっているので、以下のコマンドで調べてみます。
GET _cat/indices?s=index&index=.ml*&h=index
私の環境では以下のようなレスポンスとなりました。
.ml-annotations-000001
.ml-anomalies-custom-events_per_fileset
.ml-anomalies-shared
.ml-config
.ml-inference-000005
.ml-inference-native-000001
.ml-inference-native-000002
.ml-notifications-000002
.ml-state-000001
.ml-stats-000001
この中で、.ml-anomalies-custom-events_per_filesetについてはAnomaly Detectionのジョブで専用インデックスを利用する設定にしたために作成されたもので、私の環境固有のものです。それ以外についてはおそらく(連番を除いて)他の環境でも同様となるはずです。(機能を全く使っていない状態では作成されていないものもあると思います。)
それぞれのインデックスの概要は以下の通りです。
| インデックス名 | 説明 |
|---|---|
| .ml-annotations-* | モデルスナップショットの切り替わりなど、Elasticsearchの機械学習ジョブに関連するアノテーションを保存するインデックス。 |
| .ml-anomalies-custom-{ジョブ名} | Anomaly Detectionでジョブ名というジョブを作成し、専用インデックスを利用する設定にしたために作成されたインデックス。構成は.ml-anomalies-sharedと同一。 |
| .ml-anomalies-shared | Anomaly Detectionジョブによって検出された異常を保存するインデックス。異常スコア、原因、インフルエンサーなど、異常に関する詳細情報が含まれる。 |
| .ml-config | 機械学習ジョブの設定を保存するインデックス。分析タイプ、モデル設定、データフィード設定などが含まれる。 |
| .ml-inference-* | 機械学習モデルのメタデータを保存するインデックス。モデルの種類や各種設定など。 |
| .ml-inference-native-* | Trained Modelsに表示される機械学習モデル(Data Frame Analyticsで作成したものおよびElandでアップロードしたものなど)の本体(バイナリーデータ)を保存するインデックス。私の環境では2つあったが、おそらくバージョンアップによって新しいものが作られた。 |
| .ml-notifications-* | KibanaのJob Messageに表示されるJob startedやClosedなどのログメッセージを保存するインデックス。 |
| .ml-state-* | Anomaly Detectionで作成されるモデルの本体(バイナリー)を保存するインデックス。Mappingsがトップレベルでdisableされているので、ドキュメントの内容では検索できない。 |
| .ml-stats-* | Data Frame Analyticsでジョブを実行した後の結果が保存されるインデックス。 |
以下、それぞれごとにもう少し掘り下げて説明します。
.ml-annotations-*
モデルスナップショットの切り替わりなど、ジョブの実行結果に対して自動的に付与されるアノテーションを保存します。シングルメトリックビューワーのAnnotationsセクションに表示される内容です。以下の例だと検知したインジェストの遅れがアノテーションとして表示されています。
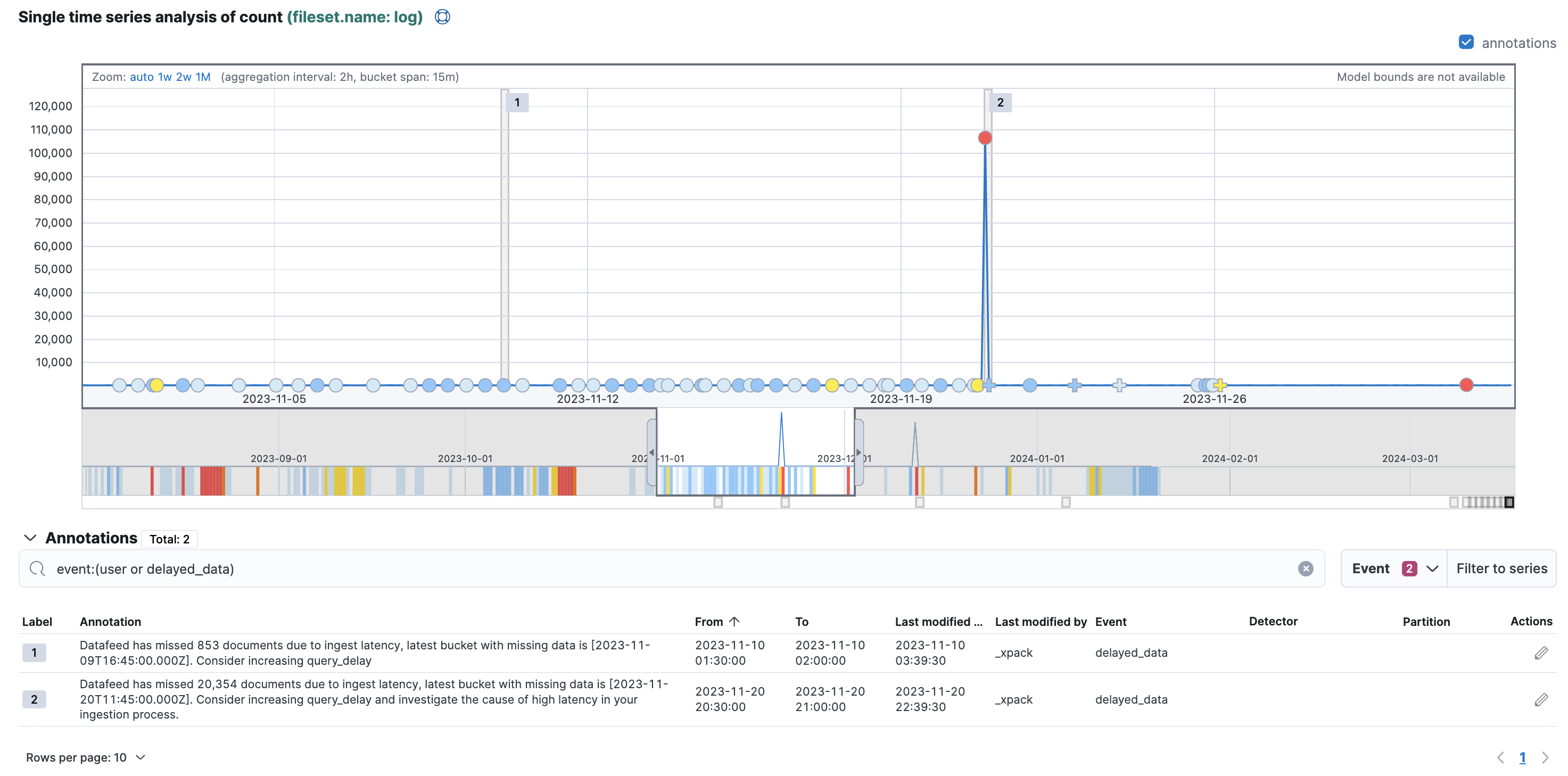
保存されているドキュメントは以下のようなものです。
{
"annotation": "Datafeed has missed 853 documents due to ingest latency, latest bucket with missing data is [2023-11-09T16:45:00.000Z]. Consider increasing query_delay",
"create_time": 1699549320161,
"create_username": "_xpack",
"timestamp": 1699547400000,
"end_timestamp": 1699549200000,
"job_id": "events_per_fileset",
"modified_time": 1699555170144,
"modified_username": "_xpack",
"type": "annotation",
"event": "delayed_data"
}
.ml-anomalies-*
検知した異常を保存するインデックスで、おそらくこのインデックスが最もユーザーとしては重要でしょう。このインデックスはresult_typeごとにいくつかの種類のデータを保存しています。
| result_type | 説明 |
|---|---|
| model_plot | モデルの予測と実際の値のプロット |
| bucket | バケットごとの異常スコア |
| bucket_influencer | バケット内の各インフルエンサーの異常スコア |
| model_size_stats | モデルのサイズと使用リソースの統計 |
| influencer | インフルエンサーごとの異常スコア |
| record | 個々の異常スコア |
| datafeed_timing_stats | データフィードのタイミング統計 |
| timing_stats | ジョブの実行タイミング統計 |
以下、それぞれのresult_typeについて説明します。
共通
異常スコアには以下の二つがあります。
- anomaly_score : 今計算されている異常スコアで、新しいデータが投入されることで更新される可能性がある
- initial_anomaly_score : 初めて計算された異常スコアで、更新されない
APIを使って異常スコアを取得するようなケースでは通常anomaly_scoreを使ったほうが良いと思いますが、もしも定期実行していて同じバケットであれば前回と同じ値を取ることが期待されるような場合はinitial_anomaly_scoreを使う必要があるでしょう。
これらのスコアは0 - 100の値を取り、probabilityから計算されています。スコアリングについては以下のドキュメントが参考になります。
model_plot
Anomaly Detectionのジョブを作成するとき、「Enable model plot」オプションが有効になっていると作成されるデータです。

ジョブをシングルメトリックビューワーで見た時に表示される、薄いブルーのバンドを表す情報を表しています。
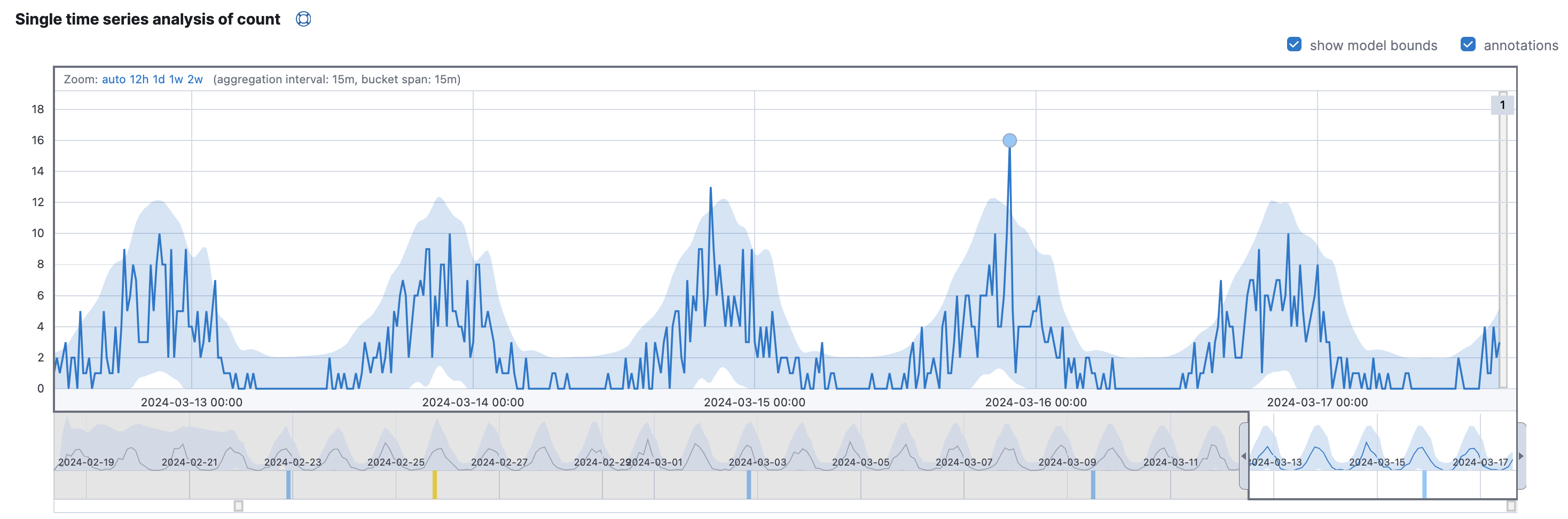
以下、サンプルのドキュメントです。model_lowerとmodel_upperの間が薄いブルーで表示されているわけですね。
{
"job_id": "kibana_sample_data_logs_visits",
"result_type": "model_plot",
"bucket_span": 900,
"detector_index": 0,
"timestamp": 1710657000000,
"model_feature": "'count per bucket by person'",
"model_lower": 0,
"model_upper": 5.195418743295091,
"model_median": 2.1109213299426832,
"actual": 3
}
bucket
バケット自体の情報を荒らすデータです。異常が検知されなくても作成されます。以下のようにis_interim: trueのものは、まだそのバケットは閉じておらず、途中経過のデータであることを示しています。
timestampはバケットの開始時刻(unixtime)を表していることも重要な点です。終了時刻は直接持っていないため、bucket_span秒経過後を計算する必要があります。
この情報はGet bucket APIで取得できます。
以下、サンプルドキュメントです。
{
"job_id": "kibana_sample_data_logs_visits",
"timestamp": 1710657900000,
"anomaly_score": 0,
"bucket_span": 900,
"initial_anomaly_score": 0,
"event_count": 1,
"is_interim": true,
"bucket_influencers": [],
"processing_time_ms": 0,
"result_type": "bucket"
}
bucket_influencer
バケット内のインフルエンサーごとの異常スコアを保存するドキュメントです。
これはGet bucket APIのうち、bucket_influencersフィールドで取得できる情報です。
以下、サンプルドキュメントです。
{
"job_id": "ecommerce_anomaly_job",
"result_type": "bucket_influencer",
"influencer_field_name": "customer_gender",
"initial_anomaly_score": 0,
"anomaly_score": 0,
"raw_anomaly_score": 0,
"probability": 0.06373888722181943,
"timestamp": 1699728300000,
"bucket_span": 900,
"is_interim": false
}
model_size_stats
モデルのサイズと使用リソースの統計を表すドキュメントです。
Get anomaly detection job statistics APIのレスポンスのうち、model_size_statsフィールドの情報が格納されています。
以下、サンプルドキュメントです。
{
"job_id": "ecommerce_anomaly_job",
"result_type": "model_size_stats",
"model_bytes": 242186,
"peak_model_bytes": 242186,
"model_bytes_exceeded": 0,
"model_bytes_memory_limit": 11534336,
"total_by_field_count": 4,
"total_over_field_count": 2,
"total_partition_field_count": 3,
"bucket_allocation_failures_count": 0,
"memory_status": "ok",
"assignment_memory_basis": "model_memory_limit",
"categorized_doc_count": 0,
"total_category_count": 0,
"frequent_category_count": 0,
"rare_category_count": 0,
"dead_category_count": 0,
"failed_category_count": 0,
"categorization_status": "ok",
"log_time": 1703056968053,
"timestamp": 1699488000000
}
influencer
それぞれのジョブについて、インフルエンサーの影響度を保存するドキュメントです。
Get influencers APIで取得できる情報を保存しています。
以下、サンプルドキュメントです。
{
"job_id": "ecommerce_anomaly_job",
"result_type": "influencer",
"influencer_field_name": "day_of_week",
"influencer_field_value": "Saturday",
"day_of_week": "Saturday",
"influencer_score": 0,
"initial_influencer_score": 0,
"probability": 0.0481955320297127,
"bucket_span": 900,
"is_interim": false,
"timestamp": 1699728300000
}
record
検出された異常を表すドキュメントです。例えばWatcherや外部ツールからカスタマイズした条件で検知した異常を抽出するようなユースケースではこのドキュメントを利用することになるでしょう。
Get records APIで取得できる情報を保存しています。このAPIで条件を絞り込める場合は、(Search APIなどで直接アクセスするより)こちらを利用する方が適切です。
Anomaly Explorerにある以下のような表はこのデータをもとに表示されています。
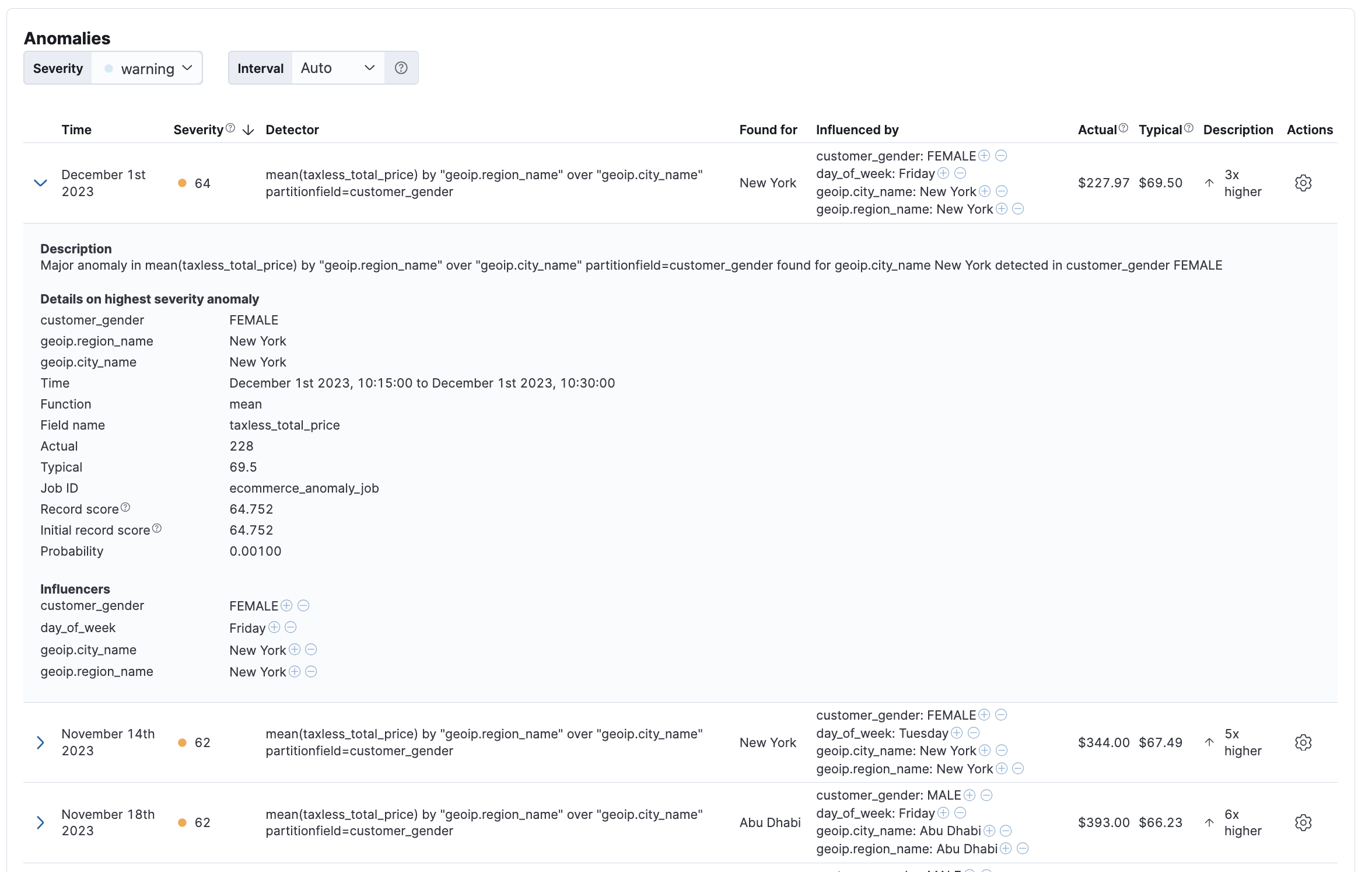
以下、サンプルドキュメントです。
{
"job_id": "ecommerce_anomaly_job",
"result_type": "record",
"probability": 0.0011769740163459295,
"record_score": 62.310491417654355,
"initial_record_score": 62.310491417654355,
"bucket_span": 900,
"detector_index": 0,
"is_interim": false,
"timestamp": 1699937100000,
"by_field_name": "geoip.region_name",
"partition_field_name": "customer_gender",
"partition_field_value": "FEMALE",
"function": "mean",
"function_description": "mean",
"field_name": "taxless_total_price",
"over_field_name": "geoip.city_name",
"over_field_value": "New York",
"causes": [
{
"probability": 0.0011769740163459295,
"by_field_name": "geoip.region_name",
"by_field_value": "New York",
"partition_field_name": "customer_gender",
"partition_field_value": "FEMALE",
"function": "mean",
"function_description": "mean",
"typical": [
67.48611017886203
],
"actual": [
344
],
"field_name": "taxless_total_price",
"over_field_name": "geoip.city_name",
"over_field_value": "New York"
}
],
"influencers": [
{
"influencer_field_name": "geoip.region_name",
"influencer_field_values": [
"New York"
]
},
{
"influencer_field_name": "geoip.city_name",
"influencer_field_values": [
"New York"
]
},
{
"influencer_field_name": "day_of_week",
"influencer_field_values": [
"Tuesday"
]
},
{
"influencer_field_name": "customer_gender",
"influencer_field_values": [
"FEMALE"
]
}
],
"geoip.region_name": [
"New York"
],
"geoip.city_name": [
"New York"
],
"customer_gender": [
"FEMALE"
],
"day_of_week": [
"Tuesday"
]
}
datafeed_timing_stats
データフィードのタイミング統計。
Get datafeed statistics APIのレスポンスのうち、timing_statsフィールドの情報が格納されています。
以下、サンプルドキュメントです。
{
"result_type": "datafeed_timing_stats",
"job_id": "ecommerce_anomaly_job",
"search_count": 7,
"bucket_count": 2975,
"total_search_time_ms": 131,
"exponential_average_calculation_context": {
"incremental_metric_value_ms": 2,
"latest_timestamp": 1702165536000,
"previous_exponential_average_ms": 19.082691389707662
}
}
timing_stats
ジョブの実行タイミング統計。
Get anomaly detection job statistics APIのレスポンスのうち、timing_statsフィールドの情報が格納されています。
以下、サンプルドキュメントです。
{
"result_type": "timing_stats",
"job_id": "ecommerce_anomaly_job",
"bucket_count": 2974,
"minimum_bucket_processing_time_ms": 0,
"maximum_bucket_processing_time_ms": 16,
"average_bucket_processing_time_ms": 0.6590450571620712,
"exponential_average_bucket_processing_time_ms": 0.693712454263083,
"exponential_average_calculation_context": {
"incremental_metric_value_ms": 0,
"latest_timestamp": 1702165500000,
"previous_exponential_average_ms": 3.7464209978820575
}
}
.ml-config
作成したAnomaly Detectionジョブの定義を保存するインデックスです。
Get anomaly detection jobs APIでこのインデックスの内容を取得することができます。
以下、サンプルドキュメントです。
{
"job_id": "ecommerce_anomaly_job",
"job_type": "anomaly_detector",
"job_version": "11.0.0",
"create_time": 1703056955087,
"model_snapshot_id": "1703056976",
"description": "",
"analysis_config": {
"bucket_span": "15m",
"detectors": [
{
"detector_description": """mean(taxless_total_price) by "geoip.region_name" over "geoip.city_name" partitionfield=customer_gender""",
"function": "mean",
"field_name": "taxless_total_price",
"by_field_name": "geoip.region_name",
"over_field_name": "geoip.city_name",
"partition_field_name": "customer_gender",
"detector_index": 0
}
],
"influencers": [
"geoip.region_name",
"geoip.city_name",
"customer_gender",
"day_of_week"
],
"model_prune_window": "30d"
},
"analysis_limits": {
"model_memory_limit": "11mb",
"categorization_examples_limit": 4
},
"data_description": {
"time_field": "order_date",
"time_format": "epoch_ms"
},
"model_plot_config": {
"enabled": true,
"annotations_enabled": false
},
"model_snapshot_retention_days": 10,
"daily_model_snapshot_retention_after_days": 1,
"results_index_name": "shared",
"allow_lazy_open": false,
"finished_time": "2023-12-20T07:22:57.096Z"
}
.ml-inference-000*
Data Frame Analyticsで作成したもの、およびElandでアップロードした学習済みモデルのメタデータを保存するためのインデックスです。KibanaのTrained Modelsとして一覧表示されるデータを管理しています。
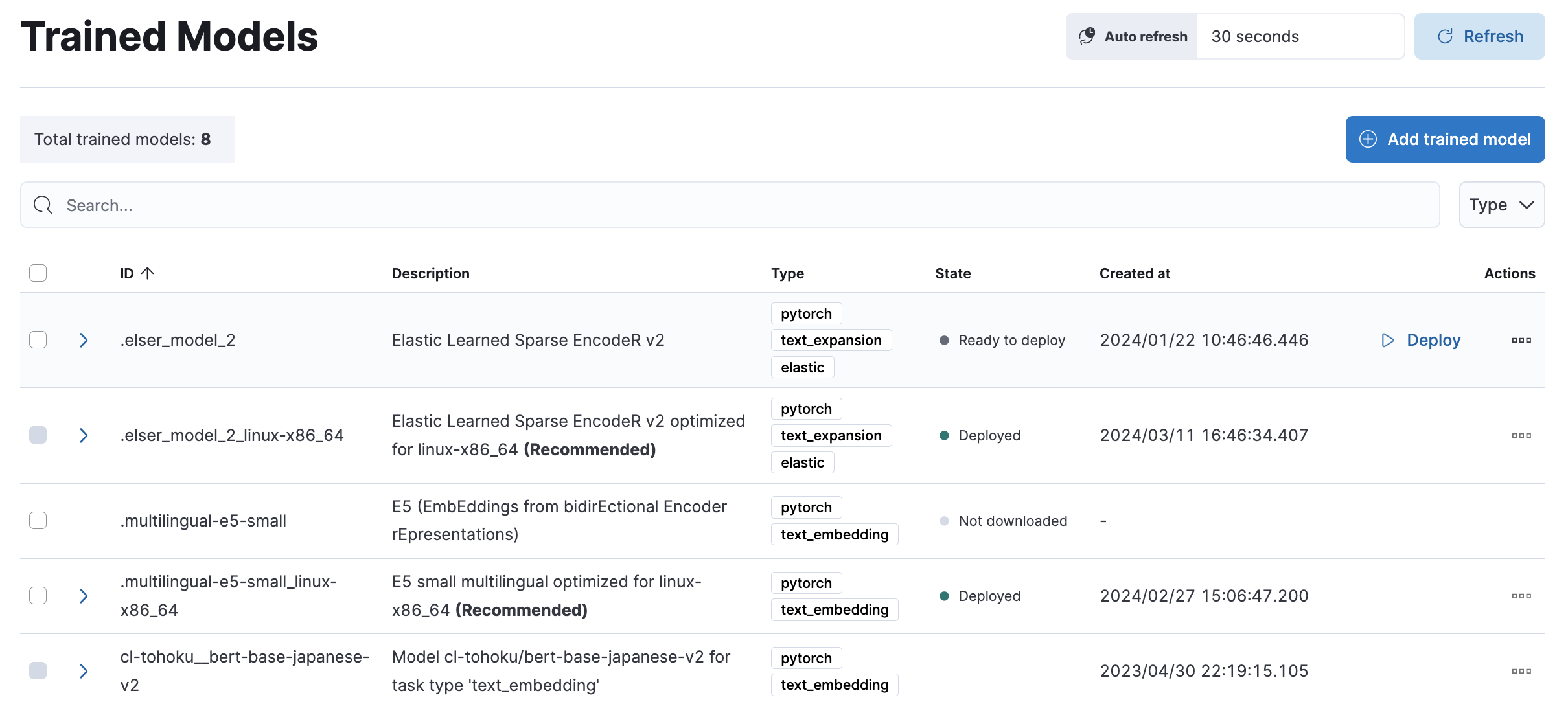
このインデックスのデータはGet trained models APIで参照できます。
以下、サンプルドキュメントです。
{
"model_id": "cl-tohoku__bert-base-japanese-v2",
"model_type": "pytorch",
"created_by": "api_user",
"version": "8.7.0",
"create_time": 1682860755105,
"model_size_bytes": 0,
"estimated_operations": 0,
"license_level": "platinum",
"description": "Model cl-tohoku/bert-base-japanese-v2 for task type 'text_embedding'",
"tags": [],
"doc_type": "trained_model_config",
"input": {
"field_names": [
"text_field"
]
},
"inference_config": {
"text_embedding": {
"vocabulary": {
"index": ".ml-inference-native-000001"
},
"tokenization": {
"bert": {
"do_lower_case": false,
"with_special_tokens": true,
"max_sequence_length": 512,
"truncate": "first",
"span": -1
}
}
}
},
"location": {
"index": {
"name": ".ml-inference-native-000001"
}
}
}
.ml-inference-native-*
.ml-inference-000*インデックスに対応した、実際の学習済みモデルのバイナリデータが保存されています。
.ml-notifications-*
Anomaly DetectionでJob Messagesとして表示されている内容が保存されているインデックスです。インデックスにはData Frame Analyticsなどそれ以外のML関連のイベントを含めて記録されています。
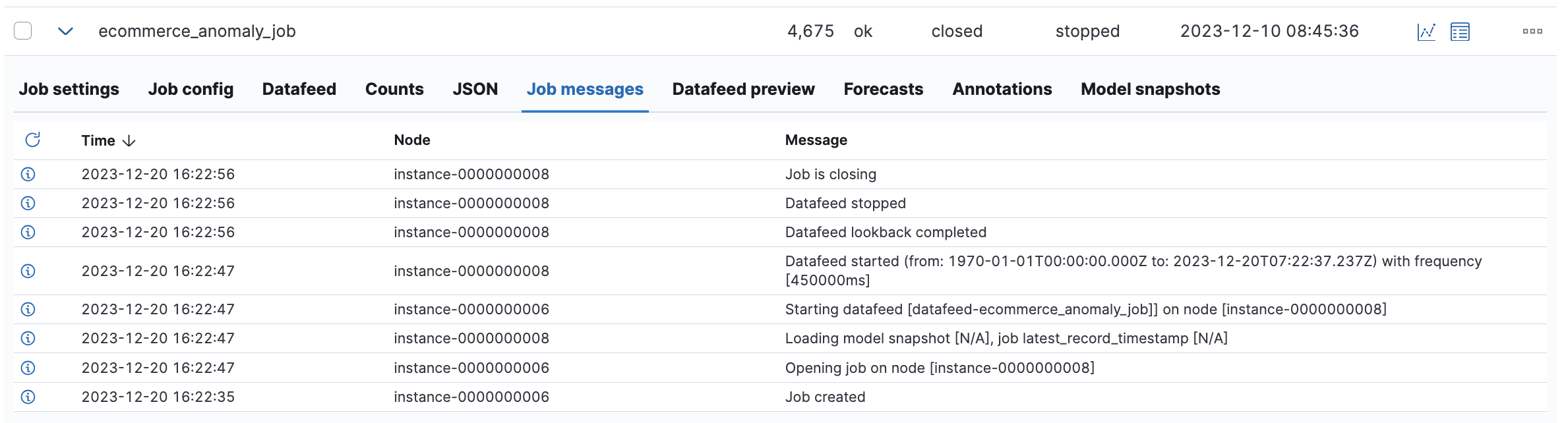
以下、サンプルドキュメントです。
{
"job_id": "cl-tohoku__bert-base-japanese-v2",
"message": "Started deployment",
"level": "info",
"timestamp": 1682860856923,
"node_name": "instance-0000000000",
"job_type": "inference"
}
.ml-state-*
Anomaly Detectionで作成されたモデルの本体(バイナリデータ)が保存されているインデックスです。
Mappingレベルでenabled: faleとなっているため、このインデックスに対して検索を行うことはできません。
.ml-stats-*
Data Frame Analytics Jobの実行結果のスタッツが記録されているインデックスです。以下の画面を表示する際に参照されています。
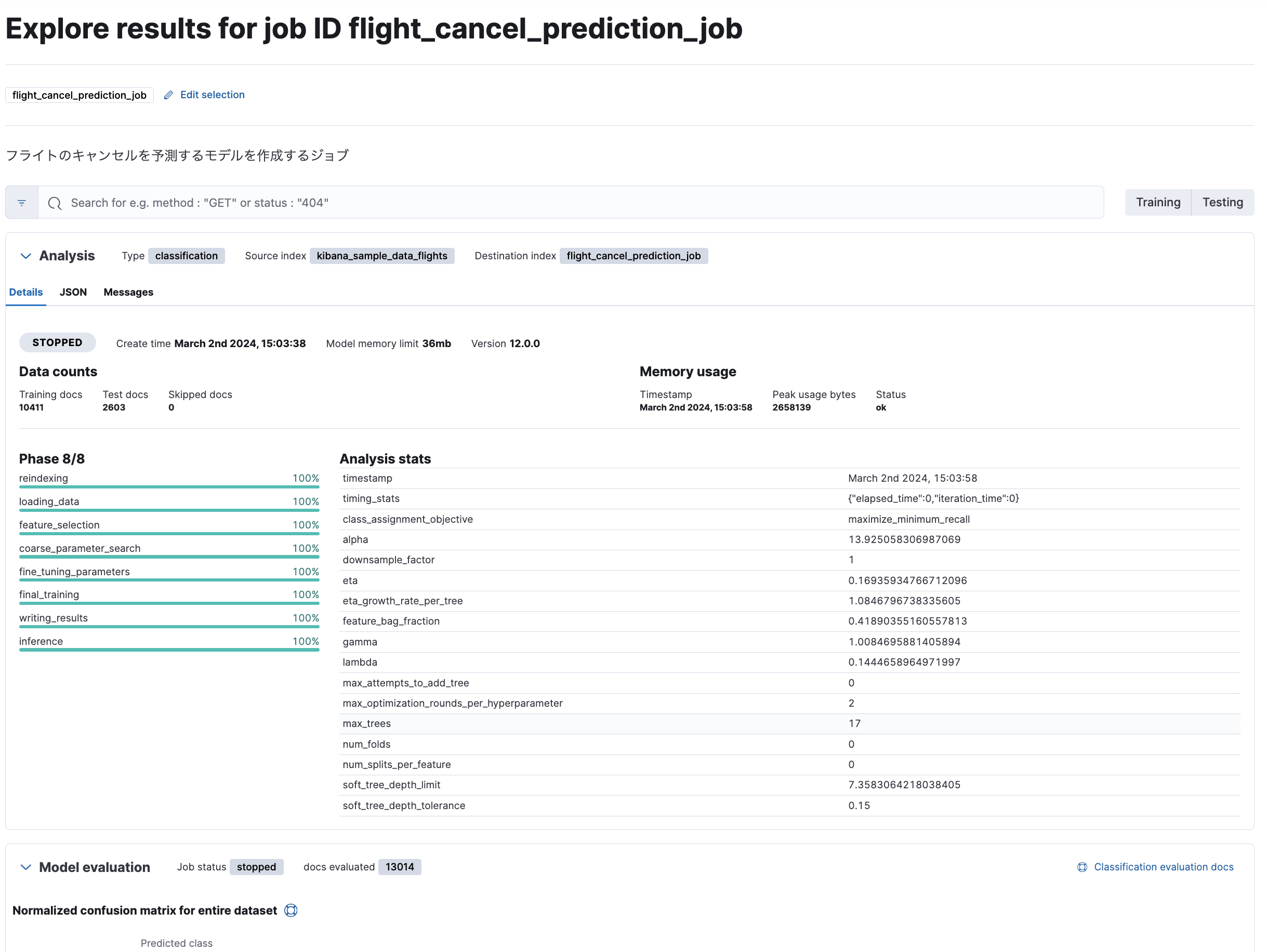
以下、サンプルドキュメントです。
{
"type": "classification_stats",
"job_id": "flight_cancel_prediction_job",
"timestamp": 1709359438743,
"iteration": 0,
"hyperparameters": {
"class_assignment_objective": "maximize_minimum_recall",
"alpha": 13.925058306987069,
"downsample_factor": 1,
"eta": 0.16935934766712096,
"eta_growth_rate_per_tree": 1.0846796738335605,
"feature_bag_fraction": 0.41890355160557813,
"gamma": 1.0084695881405894,
"lambda": 0.1444658964971997,
"max_attempts_to_add_tree": 0,
"max_optimization_rounds_per_hyperparameter": 2,
"max_trees": 17,
"num_folds": 0,
"num_splits_per_feature": 0,
"soft_tree_depth_limit": 7.3583064218038405,
"soft_tree_depth_tolerance": 0.15
},
"timing_stats": {
"elapsed_time": 0,
"iteration_time": 0
},
"validation_loss": {
"loss_type": "binomial_logistic",
"fold_values": []
}
}
KibanaのSaved Object
基本的にMLのジョブはElasticsearchが提供する機能です。ただし、Kibana上からジョブを作成すると、そのジョブは作成した時のKibana Spaceに紐づいた状態となります。複数のSpaceがある環境の場合、Spaceを切り替えると元のSpaceで作成したジョブは見えなくなるはずです。
実はKibanaではElasticsearchのシステムインデックスとは別に、KibanaのSaved ObjectとしてMLのジョブを管理しているため、このようなアクセス制限が可能となっています。KibanaのSaved Objectは.kibana_{version}インデックスに保存されていて、ML関連のオブジェクトは以下のtypeを持っています。
- ml-job
- ml-trained-model
以下、サンプルドキュメントです。
ml-job
{
"ml-job": {
"job_id": "ecommerce_anomaly_job",
"datafeed_id": "datafeed-ecommerce_anomaly_job",
"type": "anomaly-detector"
},
"type": "ml-job",
"references": [],
"managed": false,
"namespaces": [
"default"
],
"coreMigrationVersion": "8.8.0",
"typeMigrationVersion": "7.10.0",
"updated_at": "2023-12-20T07:22:36.267Z",
"created_at": "2023-12-20T07:22:35.506Z"
}
ml-trained-model
{
"ml-trained-model": {
"model_id": "elastic__distilbert-base-cased-finetuned-conll03-english",
"job": null
},
"type": "ml-trained-model",
"references": [],
"managed": false,
"namespaces": [
"*"
],
"coreMigrationVersion": "8.8.0",
"typeMigrationVersion": "7.10.0",
"updated_at": "2023-05-01T03:37:00.700Z",
"created_at": "2023-05-01T03:37:00.700Z"
}
また、「これらのML関連オブジェクトを複数のSpaceで共有したい」というよくある要望があります。KibanaのAPIを利用して実現可能なので、以下の記事で説明しています。あわせて参考にしてください。
おわりに
ElasticsearchのMachine Learningで利用されているシステムインデックスについて紹介しました。一覧で確認できるようなページは他になさそうなので、内部データ構造について確認したいときなどに参照してください。