はじめに
Elasticsearchはバージョン11からInference APIという機能を提供しています。この機能を使うことで、ElasticsearchをembeddingなどのNLP/MLの機能を使うためのインターフェイスとして利用することができるようになります。
当初はElasticが開発した言語モデルのELSERのみをサポートしていましたが、現在では様々なモデルにアクセスするためのインターフェイスとして機能するようになっています。大変便利な機能なのですが、そもそもこのAPIがどんなことを実現するのかということについては若干分かりづらい面もあると思われますので、ここで紹介したいと思います。
Inference APIの利用にはEnterprise Licenseが必要です。参照
Inference APIとは何か
Elasticsearchでは、ユーザーが選んだHugging Faceで公開されているNLPモデルをElandを使ってElasticsearchにアップロードすると、それをMLノード上で動作させることができるようになっています。このNLPモデルを使うことで、テキストのベクトル化(embedding)やエンティティ抽出(NER)、感情分析(sentiment analysis)などのタスクを実行することができます。
しかしご存知の通り、現在のNLPにおいては大規模言語モデル(LLM)を利用したembeddingなどは開発ベンダーがSaaSとして提供していることが多く、これらのモデルをElasticsearch上で動かすことはできません。
そこでElasticsearchはこれらのように実際のモデルの物理的な配置や、必要とされるAPIの仕様などを抽象化したInference APIを提供しています。
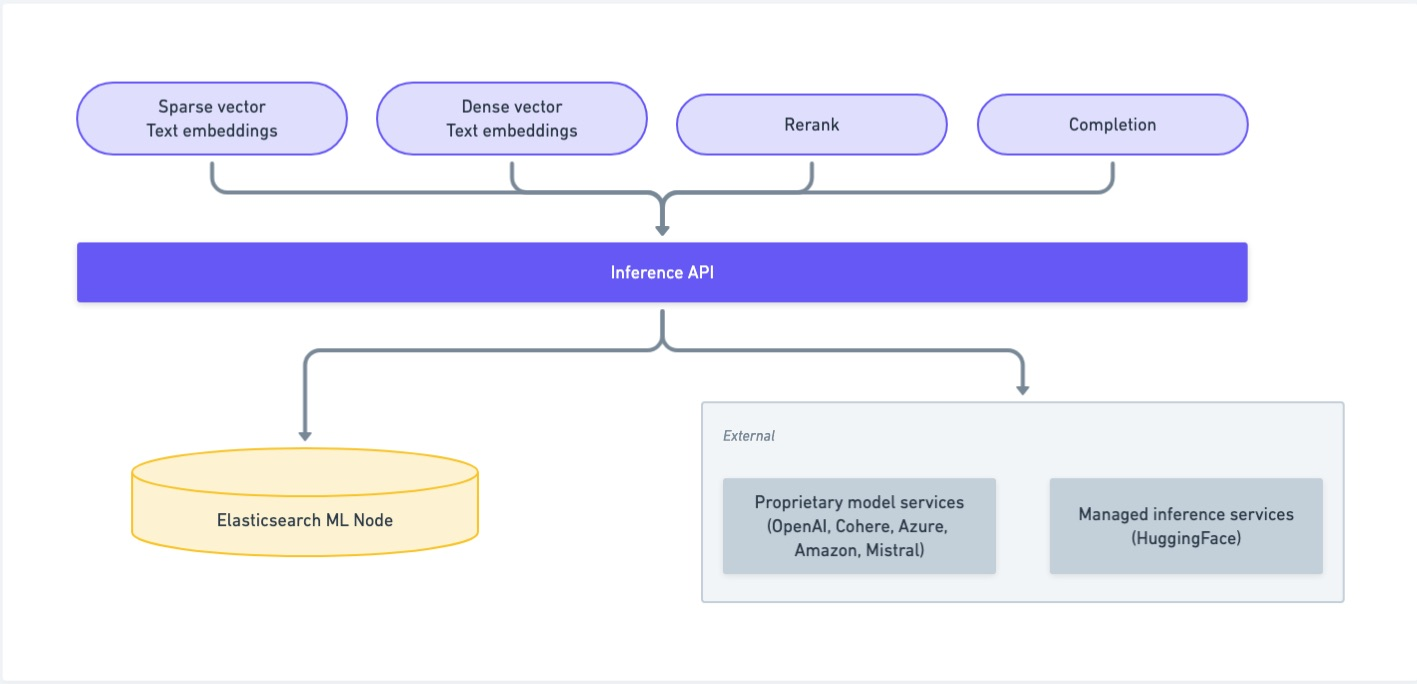
このInference APIを利用することで、Elasticsearchとしてはインデックス定義(マッピング)、データ投入、検索クエリーのいずれからもこのAPIを利用することによって、背後にある具体的なMLモデルを検索アプリケーション側から隠蔽することができるようになります。
Inference APIがサポートするサービスには以下があります(こちらを参照)。
- AlibabaCloud AI Search (completion, rerank, sparse_embedding, text_embedding)
- Amazon Bedrock (completion, text_embedding)
- Anthropic (completion)
- Azure AI Studio (completion, text_embedding)
- Azure OpenAI (completion, text_embedding)
- Cohere (completion, rerank, text_embedding)
- Elasticsearch (rerank, sparse_embedding, text_embedding - this service is for built-in models and models uploaded through Eland)
- ELSER (sparse_embedding)
- Google AI Studio (completion, text_embedding)
- Google Vertex AI (rerank, text_embedding)
- Hugging Face (text_embedding)
- Mistral (text_embedding)
- OpenAI (completion, text_embedding)
- Watsonx inference service (text_embedding)
使ってみる
実際に使って動作を確認してみましょう。
Elasticsearch上のE5を使う
まず最も基本的なパターンとして、ElasticsearchにバンドルされているDense vectorにembeddingするモデルであるE5のエンドポイントを作成してみましょう。
PUT _inference/text_embedding/my-e5-model
{
"service": "elasticsearch",
"service_settings": {
"num_allocations": 1,
"num_threads": 1,
"model_id": ".multilingual-e5-small"
}
}
以下でエンドポイントが作成できたか確認します。
GET _inference
以下のような結果が得られます。
{
"endpoints": [
{
"inference_id": "my-e5-model",
"task_type": "text_embedding",
"service": "elasticsearch",
"service_settings": {
"num_allocations": 1,
"num_threads": 1,
"model_id": ".multilingual-e5-small"
},
"chunking_settings": {
"strategy": "sentence",
"max_chunk_size": 250,
"sentence_overlap": 1
}
}
]
}
エンドポイントが作成できたので、このエンドポイントを使ってembeddingをしてみましょう。
POST _inference/text_embedding/my-e5-model
{
"input": "このエンドポイントを使って日本語テキストをembeddingしてみましょう。"
}
以下のようなレスポンスが得られます。
{
"text_embedding": [
{
"embedding": [
0.09948257,
-0.040724847,
-0.01904885,
-0.0512235,
(...)
]
}
]
}
Azure OpenAI
次に、Elasticsearchの外部にあるサービスを利用するEndpointを作成してみましょう。ここではAzure OpenAIを利用します。詳細は以下の公式ドキュメントを参照してください。
このドキュメントにある通りなのですが、以下のようにしてエンドポイントを作成します。
PUT _inference/text_embedding/azure_openai_embeddings
{
"service": "azureopenai",
"service_settings": {
"api_key": "<api_key>",
"resource_name": "<resource_name>",
"deployment_id": "<deployment_id>",
"api_version": "2024-02-01"
}
}
このときAzure OpenAI側では、当然ながらtext-embedding-3-largeなどembeddingのためのモデルを選んでデプロイし、そのdeployment idをパラメータに渡してください。gpt-4oなどはChat completionタスク用なのでembeddingには使えません。
Azure OpenAIのそれぞれのモデルが対応するタスクについては以下を参照してください。
作成されたエンドポイントを使って再度embeddingを試してみましょう。
POST _inference/text_embedding/azure_openai_embeddings
{
"input": "このエンドポイントを使って日本語テキストをembeddingしてみましょう。"
}
結果は省略しますがE5のエンドポイントと同じようにベクトル化された値が返ってくるはずです。
このように、Elasticsearchに作成したエンドポイントをインターフェイスとして、Azure OpenAIのモデルでembeddingを行うAPIエンドポイントを作成することができました。以後、Elasticsearchの検索機能以外からもこのエンドポイントをプロキシーのようにして利用することも可能です。便利ですね。
チャンキング
NLPの言語モデルでembeddingするとき、通常1回のAPIで扱えるトークン数に上限があります。そこで入力のテキストを複数の「チャンク」に分割してそれぞれembeddingするテクニックを「チャンキング」と呼びます。
このチャンキングを自前で実装するのは面倒なのですが、Elasticsearchでsemantic_text型のフィールドにデータを投入する際にInference APIを利用すると、これを自動で行ってくれます。公式ドキュメントに詳細は記載されていますが、簡単に概要を説明します。
チャンキングとトークン
Inference APIを使ってテキストをsemantic_textフィールドに投入する場合、Inference APIは入力されたテキストを自動的にチャンキングします。このときチャンキングの方式としてsentenceとwordの二つのストラテジーをサポートしており、8.16でのデフォルトはsentenceです(その前はwordでした)。sentenceのときは可能な限り「文(sentence)」の区切りでチャンクは分割され、かつ1文ずつ前後のチャンクでオーバーラップするように設定されます。1チャンクの上限はデフォルトでは250トークン(=word)です。
トークナイザー
日本語では単語の区切れ目がスペース等の区切り文字で分割されておらず、アルファベットを使った英語のような言語に比べて入力されたテキストをトークンに分割することは困難です。そのため例えばElasticsearchがテキストをインデックスする際は任意のアナライザーを利用してトークナイズを行います。チャンキングの際も同様ですが、こちらの場合は任意のアナライザーを利用できるわけではなく、ICU4Jのトークナイザーが利用されます。たとえばKuromojiのような日本語に特化した形態素解析を行うアナライザーに比べると分割の精度は高くありませんが、チャンキングは単にMLモデルに渡すためのテキストを分割する処理を行っているだけであるため、特にsentenceストラテジーを利用しているケースでは大きな問題にならないと思います。ただし、ICU4Jトークナイザーの行うトークナイズと、言語モデルが行うトークナイズでは処理内容が異なるため、言語モデルに渡されるテキストが実際に言語モデル側で何トークンとカウントされるかはやってみないとわかりません。したがっておおよその目安として捉えた方がよいでしょう。
Inference Endpointの更新
作成したInference EndpointはUpdate inference APIで設定を更新することができます。
PUT _inference/text_embedding/my-e5-model/_update
{
"service_settings": {
"num_allocations": 2,
"num_threads": 1
}
}
ただし、Endpointの更新がサポートされるのは8.16からで、この時点で以下は更新できないようです。
- service_settings.model_id : 指定してもエラーにはなりませんが設定には反映されません
- chunking_settings : 設定するとエラーになります
おわりに
この記事ではElasticsearchのInference APIについて紹介しました。主なユースケースはsemantic_textとの組み合わせでの利用になると思います。ただアプリケーションから言語モデルへのアクセスをElasticsearchに一元化することで、システムのアーキテクチャーをクリーンにするという用途でも利用可能ですので、一度この記事を参考に動作を確認して有用性を検討してみてください。