はじめに
Elasticsearchでは8.14からSearch APIにRetrieverという新しい検索機能を実装し、8.16でGAになりました。
このRetrieverがどんなものでどうやって使うのかついては、すでにあちこちで比較的多くの記事がElastic公式からも出ています。そこでこの記事ではそれらも参照しながら紹介したいと思います。
Retrieverとは
まずそもそもElasticsearchなどが提供する全文検索とは何かについて考えると、それは当然ブラウザ上でCtrl+Fを使って行うような単純なキーワードマッチではありません。入力されたキーワードに完全一致する箇所を見つけた順に単に列挙していては、検索結果は1:ノイズが多く(適合率が低い)、2:キーワードに揺れがあると検索漏れも発生する(再現性が低い)、という問題が生じます。
そこでBM25に代表されるような転置インデックスベースのアルゴリズムが考案されてました。BM25を利用すると非常に高速かつクエリーに対して適合率および再現性の高い検索が実現できます。またRAGのようにLLMと組み合わせる用途では、ベクトル検索を利用することも増えてきました。
そして近年では、最初の検索結果に対して、例えば機械学習の機能を使ったリランキング、LLMを使ったリランキングといった処理を順次適用していくような検索パイプラインを構築する手法が考えられています。Elasticsearchを使ったリランキングについては以下の記事を参照してください。
大変わかりやすく図も多いので、この記事をベースに説明します。
まず最初の検索(First-stage retrieval)では通常のBM25やベクトル検索などを使って比較的大きなドキュメントセットを取得します。その結果をより上位のリランカー(Mid-stage rerankers, Final rerankking)を使い、よりユーザーの求めるドキュメントに絞り込んでいく、という流れです。
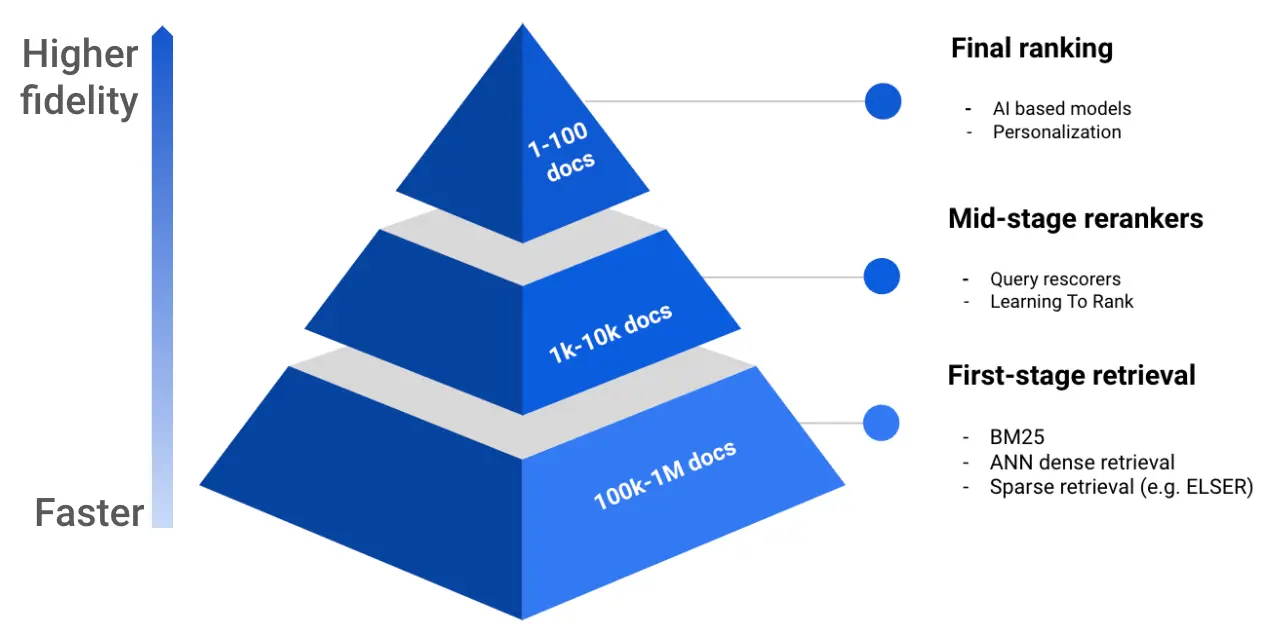
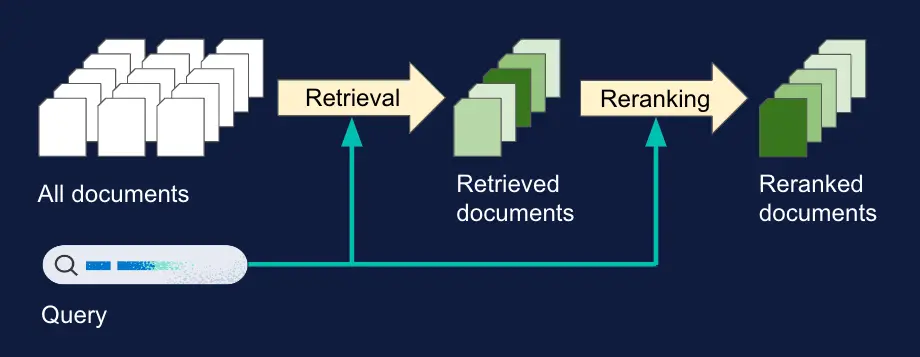
ここでわかるように、これを実際にElasticsearchで実現しようと思うと、以下のような処理をアプリケーションで記述する必要がありました。
- _searchで検索結果を取得し(First-stage retrieval)、LTRのようなリランカーでリランキングする(Mid-stage rerankers)
- _inference/rerankでCohereなど、外部のLLM等を使った最終的なリランキングを行う(Final reranking)
現時点のElasticsearchでは、Mid-stage rerankerは単一の_searchクエリで実行することができますが、最終のリランキングは別のAPIを利用する必要があります。こちらも絵がありましたので貼っておきます。
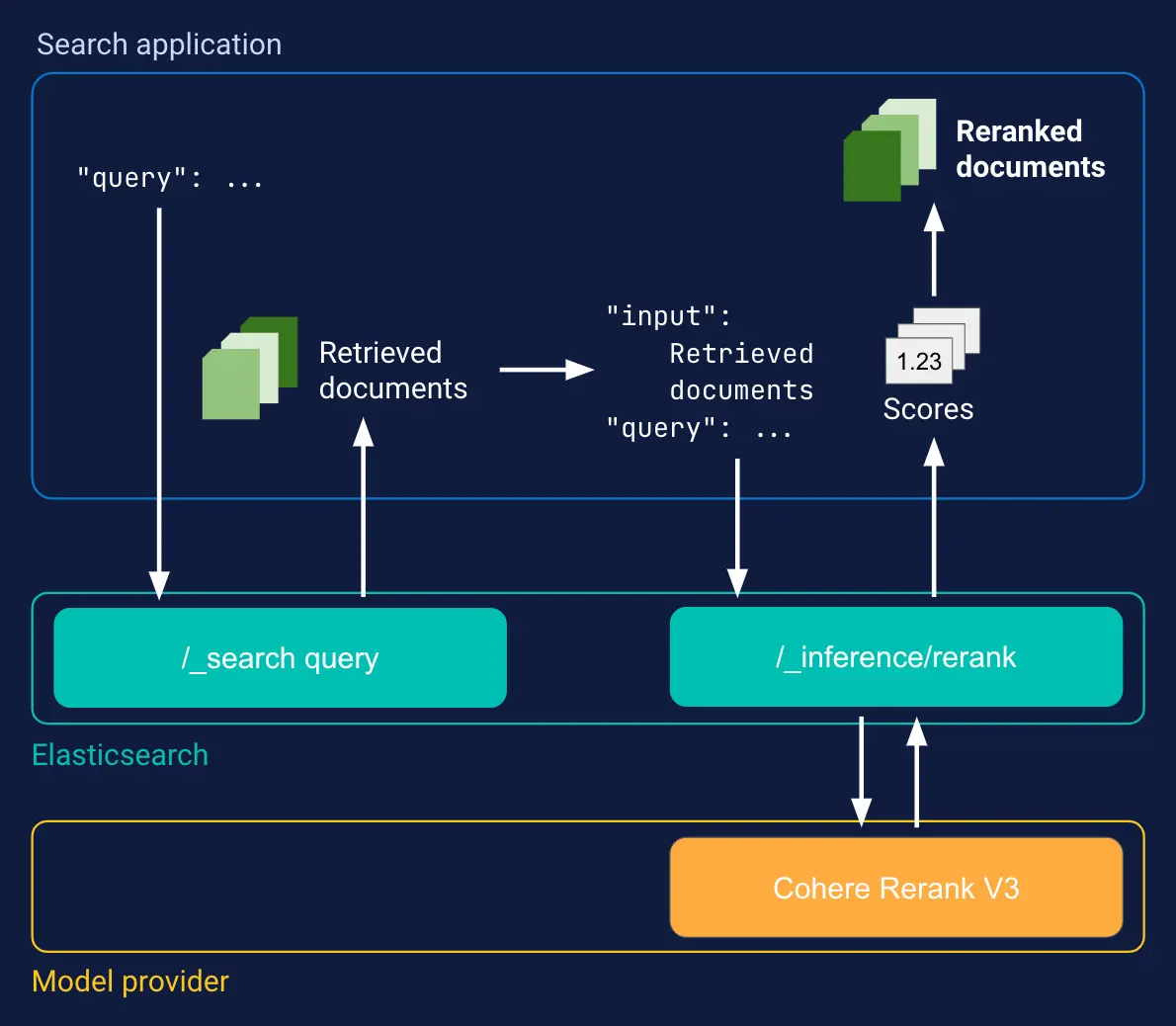
アプリケーション側に検索に関わるパイプライン処理が記述される必要があることがわかります。面倒ですね。
しかしRetrieverを使うことで、この検索パイプライン処理を一つのElasticsearch APIの内部で実装することができるようになります。
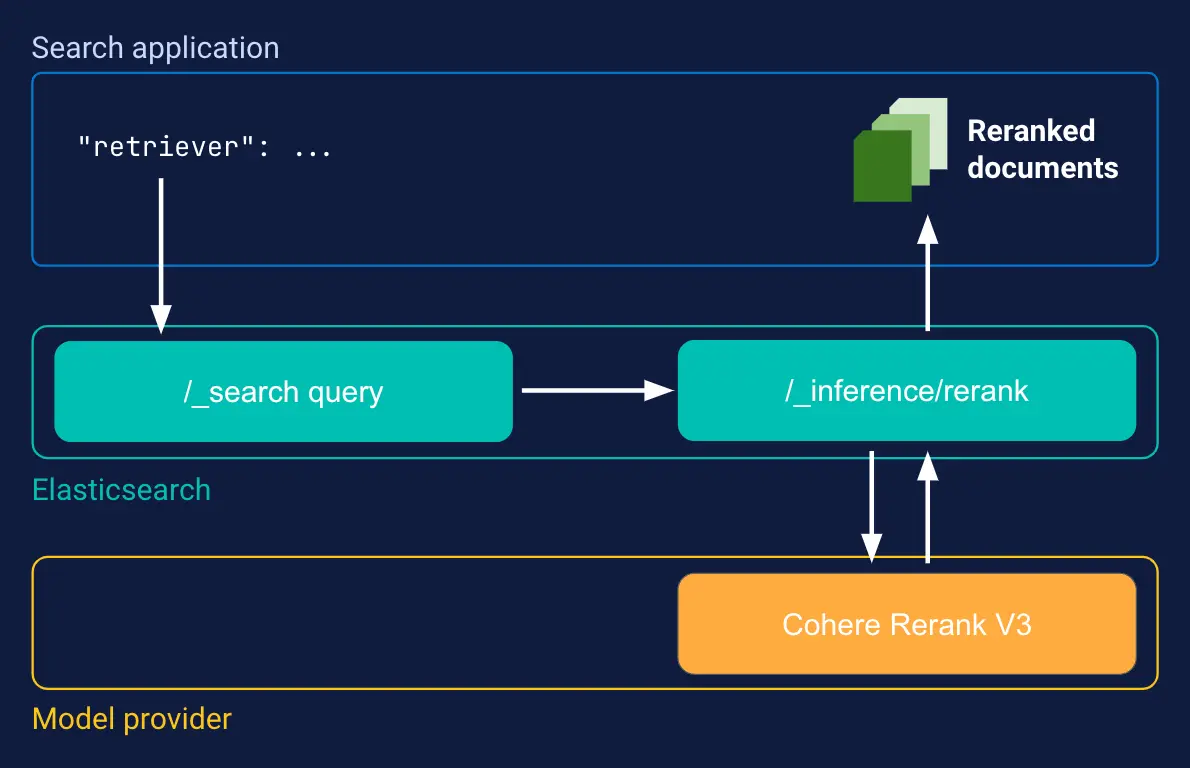
このようにElasticsearchのRetrieverは、最終的な検索結果を取得するためにA→B→C...といった複数のパイプライン処理を適用しないケースで、それらに対する単一のエンドポイントを提供するものとしてデザインされているわけです。また、これまでのRetrieverを利用しないクエリーで実現できるものでも、Retrieverを利用することでクエリーの構造がわかりやすくなり、検索アプリケーションを実現しやすくなるという利点もあります。
使用例
では実際にRetrieverを使った検索の例を見てみましょう。
standard : シンプルな例
実用的なメリットはありませんが、単にRetrieverを試すということなら、通常のqueryをstandardリトリーバーとしてラップすればOKです。
GET my_index/_search
{
"retriever": {
"standard": {
"query": {
"match": {
"title": "ElasticsearchのRetriever"
}
}
}
}
}
knn : ベクトル検索
knnクエリーはknnリトリーバーとして実装できます。
GET my_index/_search
{
"retriever": {
"knn": {
"field": "title_semantic.inference.chunks.embeddings",
"query_vector_builder": {
"text_embedding": {
"model_id": ".multilingual-e5-small_linux-x86_64",
"model_text": "ElasticsearchのRetriever"
}
},
"k": 10,
"num_candidates": 10
}
}
}
対象のインデックスがsemantic_textフィールドを使っている場合は、standardリトリーバーのsemanticクエリーで検索可能です。
GET my_index/_search
{
"retriever": {
"standard": {
"query": {
"semantic": {
"field": "title_semantic",
"query": "ElasticsearchのRetriever"
}
}
}
}
}
RRF
RRFを使ってBM25とknnを組み合わせる場合は以下のようにrrfリトリーバーが利用できます。このリトリーバーは複数のサブリトリーバーを組み合わせて実装します。
GET my_index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"title": "ElasticsearchのRetriever"
}
}
}
},
{
"knn": {
"field": "title_semantic.inference.chunks.embeddings",
"query_vector_builder": {
"text_embedding": {
"model_id": ".multilingual-e5-small_linux-x86_64",
"model_text": "ElasticsearchのRetriever"
}
},
"k": 10,
"num_candidates": 10
}
}
],
"rank_constant": 1,
"rank_window_size": 50
}
}
}
text_similarity_reranker : Semantic Reranking
BM25やベクトル検索を使ったスコアリングはそれぞれのドキュメントを一定のアルゴリズムを使って関連度をスコアリングするものです。しかし本当にやりたいことはドキュメントの内容がユーザーの求めている情報に最も近いものを最上位に表示することですね。
そこでLLMなどのモデルにドキュメントの内容を評価させてソートさせるのがSemantic Rerankingです。ElasticsearchのInference APIではRerankingのタスクにも対応しています。詳しくは例えばCohereのモデルを利用したRerankingについては以下の記事を参照してください。
また、日本語のためのモデルを扱う例として以下の記事もあります。
ここではこの記事でも紹介されている以下のモデルを使う例を試してみましょう。
事前にElandを使ってモデルをアップロードしておきます。
eland_import_hub_model \
--url=http://elastic:password@localhost:9200 \
--hub-model-id=hotchpotch/japanese-reranker-cross-encoder-xsmall-v1 \
--task-type=text_similarity \
--max-model-input-length=512 \
--clear-previous \
--start
次にこのモデルを使うRerankerのInference Endpointを作成します。
PUT _inference/rerank/ja_reranker
{
"service": "elasticsearch",
"service_settings": {
"num_allocations": 1,
"num_threads": 1,
"model_id": "hotchpotch__japanese-reranker-cross-encoder-xsmall-v1"
}
}
では、いざretrieverを使ってRerankingを含む検索クエリーを実行してみましょう。
POST my_index/_search
{
"retriever": {
"text_similarity_reranker": {
"retriever": {
"standard": {
"query": {
"semantic": {
"field": "text_semantic",
"query": "自動車"
}
}
}
},
"field": "text",
"rank_window_size": 100,
"inference_id": "ja_reranker",
"inference_text": "自動車",
"min_score": 0.6
}
}
}
このように1回のretrieverクエリーで検索とRerankingが実現できています。しかしretrieverが使えないケースでは、一度検索結果を取得した後、その結果を別のInference APIでRerankingする必要があります。retrieverを使うことでそのような処理を全てElasticsearchに任せることができるわけですね。
おわりに
ElasticsearchのRetrieverについて説明しました。現時点ではRerankerを使うケース以外ではそこまで「なくてはならない」ものにはなっていないかもしれませんが、今後検索パイプラインがより高度化するに従って恩恵を得ることができるようになると思います。例えば、Kibanaで利用できるPlaygroundが生成するクエリーにはRetrieverが採用されています。特に生成AIとの組み合わせのような場面では便利に使えるようになると思いますので、ぜひどのような機能なのか試してみてください。