はじめに
Elasticsearchはそれなりに以前からベクトル検索を実現していて、加えてv8.0からは外部のNLPモデルをElasticsearchに取り込んで、Elasticsearch上でテキストのベクトル化(embedding)を実行することが可能でした。しかし残念ながら日本語については、テキストのトークナイズ処理が対応しておらず、適切なテキスト分析ができない状態でした。
そこで日本語モデルを利用する際に適切なトークナイズを実現できるように以下のPRを送ったところ無事マージされてv8.9から利用できるようになりました。
ElasticsearchのPR
ElandのPR
そこでこの取り込まれた機能を使って、具体的に日本語のベクトル検索やテキスト分類を実施するサンプルを以下の公式ブログに書きました。
上記を見てもらえれば使い方は一通りわかるかと思うのですが、若干長めの説明をしているので、ここでは御託はいいからベクトル検索の使い方だけ教えろ!という忙しい皆様のための簡略版の記事をお届けしようと思います。より丁寧な説明を読みたい方は上記ブログを参照してください。
Elandのインストール
ElandはElasticが提供するPythonライブラリで、ElasticsearchのデータとPyTorchやscikit-learn などのPythonの充実した機械学習ライブラリを連携させるための機能を提供しています。このElandにバンドルされる eland_import_hub_model というコマンドラインツールを利用すると、Hugging Faceで公開されているNLPモデルをElasticsearchにインポートすることができます。
Elandは以下のようにインストールしてください。
$ pip install torch==1.13
$ pip install transformers
$ pip install sentence_transformers
$ pip install fugashi
$ pip install ipadic
$ pip install unidic_lite
$ pip install eland
NLPモデルのインポート
日本語の文章を数値列にエンベッド(ベクトル化)するためのモデルをHugging Faceで選定しましょう。今回の記事では以下のモデルを利用することにします。
Hugging FaceのモデルページからFiles and versionsタブを開き、tokenizer_config.jsonファイルの内容を確認してください。ここでword_tokenizer_typeの値がmecabとなっていることを確認してください。
{
"do_lower_case": false,
"word_tokenizer_type": "mecab",
"subword_tokenizer_type": "wordpiece",
"mecab_kwargs": {
"mecab_dic": "unidic_lite"
}
}
確認できたら、以下のコマンドでElasticsearchにインポートします。
$ eland_import_hub_model \
--url "https://your.elasticserach" \
--es-api-key "your_api_key" \
--hub-model-id cl-tohoku/bert-base-japanese-v2 \
--task-type text_embedding \
--start
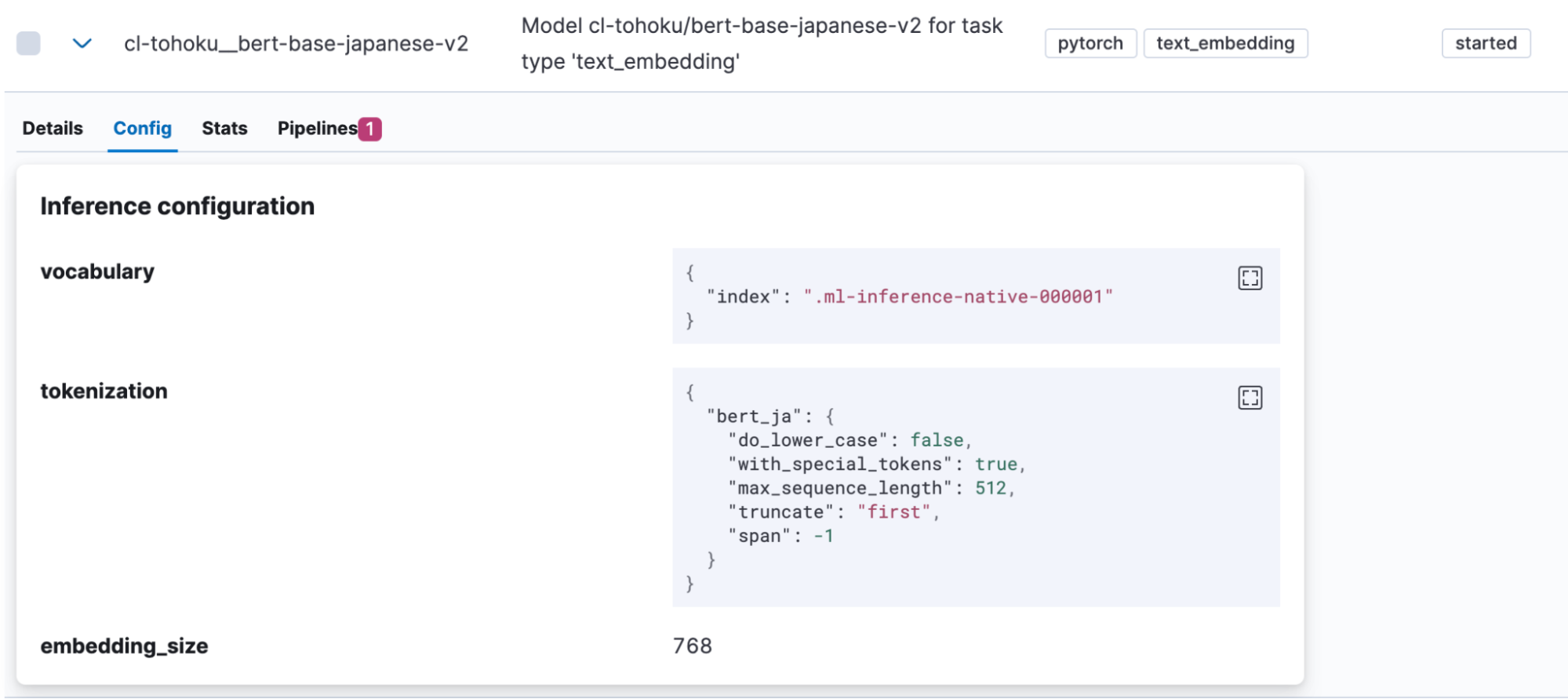
正常にインポートが完了すると、KibanaのMachine Learning > Model Management >Trained Modelsにインポートしたモデルが表示されます。ここでモデルのConfigタブを開くと、tokenizationとして”bert_ja”が使われており、日本語を扱うモデルとして正しく登録されていることがわかります。
ベクトル埋め込みを利用したセマンティック検索の実装
ベクトル検索をするためには、インデックスに元の日本語テキストをエンベッドしたベクトル値がインデックスされている必要があります。そこで、先ほどアップロードしたモデルを使ってインデックスに投入される前に日本語テキストをベクトル化するinferenceプロセッサーを含むパイプラインを作成します。
PUT _ingest/pipeline/japanese-text-embeddings
{
"description": "Text embedding pipeline",
"processors": [
{
"inference": {
"model_id": "cl-tohoku__bert-base-japanese-v2",
"target_field": "text_embedding",
"field_map": {
"title": "text_field"
}
}
}
]
}
パイプラインが登録できたら、これを利用してインデックスを作成します。作成するインデックスにはベクトルを保存するフィールドが必要なため、適切にmappingを定義しておきます。
PUT japanese-text-with-embeddings
{
"mappings": {
"properties": {
"text_embedding.predicted_value": {
"type": "dense_vector",
"dims": 768,
"index": true,
"similarity": "cosine"
}
}
}
}
テストのために直接ドキュメントを登録する場合、以下のように作成したpipelineを指定してインデックスに書き込みます。
POST japanese-text-with-embeddings/_doc?pipeline=japanese-text-embeddings
{
"title": "日本語のドキュメントをベクトル化してインデックスに登録する。"
}
ベクトル化されたドキュメントの登録が完了したらいよいよ検索が可能です。アップロードしたモデルを使ってクエリーをベクトルにエンベッドしてから検索をするには、以下のように検索APIを実行します。
GET japanese-text-with-embeddings/_search
{
"knn": {
"field": "text_embedding.predicted_value",
"k": 10,
"num_candidates": 100,
"query_vector_builder": {
"text_embedding": {
"model_id": "cl-tohoku__bert-base-japanese-v2",
"model_text": "日本語でElasticsearchを検索したい"
}
}
}
}
この検索クエリーを実行すると、以下の様なレスポンスが得られます。
"hits": [
{
"_index": "japanese-text-with-embeddings",
"_id": "vOD6MIoBdRdLZd7EKaBy",
"_score": 0.82438844,
"_source": {
"title": "日本語のドキュメントをベクトル化してインデックスに登録する。",
"text_embedding": {
"predicted_value": [
-0.13586345314979553,
-0.6291824579238892,
0.32779985666275024,
0.36690405011177063,
(略、768次元のベクトルが表示される)
],
"model_id": "cl-tohoku__bert-base-japanese-v2"
}
}
}
]
検索できましたね。
検索ランキングについてチューニングする際は、ベクトル検索と通常のキーワード検索の結果をうまくブレンドするReciprocal rank fusion (RRF)という機能もリリースされています。こちらも合わせて確認してください。
ベクトル検索を使ったセマンティック検索を実現する流れについては以上になります。通常の検索に比べ、若干手間が必要だったり機械学習特有の用語が出てきますが、一度設定してしまえば検索自体は通常とほとんど変わらない方法で実現できますので、ぜひ一度試してみてください。
また公式ブログの方ではテキスト分類(感情分析)タスクを実現する例も載せていますので、併せて確認してください。