はじめに
Elasticsearch / Luceneに限らず、現代の情報検索の技術について理解するためには、多くの前提となる要素技術への理解が不可欠です。包括的とまではいきませんが、この記事では情報検索に携わる上での重要な用語や概念について紹介したいと思います。
検索にまつわる用語の整理
そもそもここで取り扱っている「検索」とは何のことかを整理しましょう。例えばブラウザやテキストエディタでの検索は、与えられた特定のテキストの中から、ある文字列パターンの出現箇所を見つけるもので「String matching」や「String searching」と呼ばれます。この処理においては検索の「関連性」のような観点はなく、入力されたテキストに完全一致する文字列を、検索対象の先頭からスキャンして漏れなくユーザーに提示することが求められます。
これに対して、システムで管理された多数のリソース群(文書や画像など)の中から、必要な情報を抽出する処理のことを「Information Retrieval」(IR)と呼びます。Elasticsearchなどの検索システムが取り扱うのはこちらの「Information Retrieval」です。

Information Retrievalで取り扱う個々の情報は「ドキュメント」と呼ばれることが多いと思います。そしてこのドキュメントの集合のことをコーパス(Corpus)と呼びます。
また、IRにおいて検索の問合せに使われる入力テキストのことをクエリー(Query)と呼びます。
IRの評価
通常IRで取り扱うコーパスは非常に大きいです。その中からいくつかのドキュメントが検索結果として取得できた時、その結果を評価するにはどうすれば良いでしょうか。
適合率(Precision)と再現率(Recall)
非常によく知られたIRの評価指標として適合率(Precision)と再現率(Recall)があります。
適合率(Precision)は、検索結果に含まれるユーザーが求めているドキュメントの割合を意味します。つまり、ノイズの少なさと言えます。

それに対して再現率(Recall)はコーパス全体に含まれる本来見つかるべきドキュメントに対する、検索結果に含まれるドキュメントの割合を意味します。こちらは検索の漏れのなさ、カバレッジの広さを意味しています。

適合率(Precision)と再現率(Recall)の以下の図がわかりやすいです。

一般に適合率と再現率はトレードオフの関係にあり、どちらか一方を上げようとすると別の一方が下がる結果となります。適合率を上げようとして検索結果から誤りを減らそうとすると(上記の図の円の範囲を狭めようとすると)、元々見つかっていたtrue positivesのドキュメントを取りこぼしてしまうかもしれません。逆に再現率を上げようとして検索結果の範囲を広げようとすると(円を大きくしようとすると)、ノイズとなるドキュメントまで検索結果に含めることになりがちです。
その他の指標
そのほかにも検索結果の品質の指標はいくつかあります。
一般に検索結果の品質は、そのランキング(ソート順)に強く依存していますが、上記のPrecisionとRecallは検索のランキングについては考慮していませんでした。DCG (Discounted cumulative gain)を使うと、検索結果の関連度の高さおよびそれに基づくランキングについても評価することが可能になります。またnDCG (Normalized DCG)はDCGのスコアを0.0 - 1.0に正規化したものです。これらもWikipediaに充実したページがあるので参考にしてください。
IRの品質評価を行う場合にはこれらの指標利用します。ElasticではElasticsearch Relevance Studioというツールを提供していますので、もしElsaticsearchを使ってIRを実現している場合には利用してください。
よく検索の精度がイマイチなので改善したいという要望があります。この時、具体的な課題を挙げて(Aで検索した時の結果にXが含まれるべき・べきでないなど)チューニングすることは重要ですが、その際にはチューニングによってその他の検索クエリーに対する精度が低下していないかモニターすることを忘れないようにしてください。そのモニタリングのためには、これらの指標値が大変役に立ちます。
Lexical search (キーワード検索、全文検索)
では実際に検索を実装する際、どのような仕組みで検索エンジンはコーパスからドキュメントを見つけるのでしょうか。いくつかのアルゴリズムがあるので、重要なものを紹介します。
まず一般的な検索として実装されているのは、Lexical searchあるいはキーワード検索として知られている手法です。これはクエリーに含まれている単語を含むコーパス内のドキュメントを検索し、結果として返します。
またLexical searchとして実装されたIRの仕組みことを全文検索 (Full-text search)と呼びます。
Inverted Index (転置インデックス)
全文検索システムでは、大量のドキュメントコーパスの中から目的のドキュメントを見つけ出さなければいけません。しかし検索実行時にコーパスのドキュメントをフルスキャンしていると検索処理に時間がかかりすぎます。そこで通常Lexical searchでは、ドキュメントに含まれている単語からそのドキュメントへのリンクを保存したInverted Index(転置インデックス)を作成します。そして検索実行時にはクエリーを単語に分解し、それぞれの単語からその単語を含むドキュメントをこの転置インデックスを参照して見つけ出します。検索エンジンを利用している場面でインデックスという時は、この転置インデックスのことを指している場合が多いと思います。
ちなみにこれは技術的にはドキュメントを、コーパスに含まれるすべての単語(Vocabulary)次元の疎ベクトル(Sparse vector)表現していることに相当します。(ただし後述のSemantic searchの文脈におけるSparse vector検索とは別物であることにも注意してください。)
転置インデックスについては、古いですが以下のブログ記事が参考になります。
転置インデックスの構成要素には大きく二つのものがあります。Dictionary (辞書)とPostings list(ポスティングリスト)です。

辞書はコーパスに含まれるすべての語彙(単語、あるいはターム)を保存したリストで、それぞれの語彙がコーパスの中でどれだけ出現したかという情報も保持しています。
それに対してポスティングリストは、それぞれの語彙を含むドキュメントのIDの配列を保持したリストです。このデータ構造自体のことを転置インデックスと呼ぶ場合もあります。転置インデックスを使った検索では、クエリーに含まれる単語を見つけ出し、その単語に対応するポスティングリストを走査(スキャン)することによって、その後を含むドキュメントを高速に見つけ出すことができます。
また、該当の語彙がドキュメントのどの位置に出現したのかという情報も重要な場合があります(例えばフレーズ検索をする場合は位置情報が連続しているかを調べます)。そのためLucene/Elasticsearchなどの転置インデックスではこの位置(Position)情報も保持しています。
転置インデックスは前文検索システムにとって極めて重要なものですので、どのような仕組みで動作しているのかを把握しておくことは検索に携わるエンジニアにとっては不可欠だと思います。
Similarity (類似度)とBM25
転置インデックスを引くことで検索結果の候補を素早く見つけ出すことができますが、この中から検索クエリーにより関連度の高いドキュメントを検索結果の上位にする必要があります。そのために検索エンジンは検索クエリーと検索結果に対してSimilarity (類似度)の計算を行い、類似度の高いものを検索の上位とすることで、ユーザーがより求めているドキュメントを素早く提示できるようにしています。
キーワード検索におけるSimilarityの計算ではOkapi BM25(あるいは単にBM25)が有名です。BM25のベースはTF-IDFというもので、以下の二つの要素の積になっています。
- TF (Term Frequency) : ドキュメントに(クエリーにある)単語(ターム)がどれだけ出現するか
- IDF (Inverse Document Frequency) : コーパス内にあるその単語を含むドキュメントの総数の逆数
クエリーに含まれる単語について多く言及している文書はTFが高く、高スコアになります。また、その単語が他の文書では滅多に言及されない単語だった場合はIDFが大きくなり、こちらも好スコアとなるわけです。
BM25ではTF-IDFのスコアが無限に大きくなったりしないようにサチュレーション関数をかけてスコアの幅を調整したものになっています。これについて詳しく説明したElasticのブログ記事も参照してください。

つまりBM25を使ったLexical searchでは、まず転置インデックスを使って検索クエリーに含まれる単語を含むドキュメント一覧を素早く見つけた後、BM25でそれぞれのドキュメントの関連度を計算し、それが高い順にソートして検索結果を作成しているわけですね。
トークナイズ
これまでに見てきた通り、転置インデックスを構築するためには、入力された文書を単語(ターム)に分割することが前提になっています。この文書を単語に区切る処理のことをトークナイズと呼びます。英語などの多くのヨーロッパ言語では単語の区切り目には基本的にスペースがあるため、トークナイズは難しくありません。
形態素解析
それに比較し、主に漢字文化の日本語、中国語、韓国語(ハングル)ではそのような単語を区切る文字あるいは記号が存在しません。そのため多くの場合言語ごとに辞書を用意して、テキストの文法構造を解析して単語への分割を実現します。このテキスト分析処理のことを形態素解析(Morphological Analysis)と呼びます。
日本語の形態素解析器としては、以下のようなものが有名です。
Elasticsearchで利用できるKuromojiは、基本的にMeCabをLuceneで利用できるようにしたJavaポーティングです。利用する日本語辞書もMeCabと同様のものを利用できます。
以下は「すもももももももものうち」をKuromojiを使って解析した結果の例です。
すもももももももものうち
すもも 名詞,一般,*,*,*,*,すもも,スモモ,スモモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
も 助詞,係助詞,*,*,*,*,も,モ,モ
もも 名詞,一般,*,*,*,*,もも,モモ,モモ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
うち 名詞,非自立,副詞可能,*,*,*,うち,ウチ,ウチ
形態素解析を利用することによって、スペースのような単語の切れ目を持たない言語のテキストを、適切な単語の単位でトークナイズをすることができるようになります。
N-Gram
形態素解析は辞書ベースでテキストの文法構造をすべて分析するものなので処理の負荷が高く、また辞書に依存しているため新語に弱いという弱点があります。
形態素解析以外で広く使われていて、かつ基本的にどのような言語にも技術的には対応できるのがN-Gramというトークナイズ手法です。N-Gramでは、入力されたテキストを機械的にN文字のまとまりごとにタームとして切り出します。N=1: Unigram, N=2: Bigram, N=3Trigramと呼び、日本語の検索ではBigramが利用されることが多いです。
例えば「バイグラム」という文字列をBigramでトークナイズすると、以下のような結果となります。
バイ, イグ, グラ, ラム
直感的にわかる通り、N-Gramのトークナイザーを検索でそのまま利用すると、ノイズが多くPrecisionの低い結果となりがちです。Elasticsearchではmatch_phraseなどを使って、ひとまとまりの(未知語も含む)テキストを検索する場合などには非常に有効です。
テキストプロセッシング
通常検索エンジンがドキュメントを転置インデックスに取り込む際は、何らかの前処理(パイプライン処理)を施します。トークナイザーもその前処理の一つですが、以下のような典型的な前処理があります。
- 小文字への変換 : アルファベットをすべて小文字(あるいは大文字)に変換することで、大文字と小文字の区別なく検索を実現できるようにする
- 活用のある語の原型への変換 : 名詞の複数形、動詞の人称や時制の活用などを、単数形や原型などに変換することで、活用による揺れを吸収する
- ストップワード : 英語の冠詞や日本語の助詞などのように、それ自体では検索の対象とならない語を除外する
- シノニム : ある語に対して類義語をセットでインデックスに登録したりクエリーに追加したりすることで、例えば「パソコン」というクエリーで「PC」を含むドキュメントを見つけることができるようにする
上記は一例で、検索エンジンごとに多くの前処理が実装されているはずです。例えばElasticsearchではキャラクターフィルター、あるいはトークンフィルターとして実装します(上記の箇条書きはすべてトークンフィルターです)。ちなみにElasticsearchにおけるIngest Pipelineはこれとはまた別のものですので注意してください。
Semantic Search (意味検索)
Lexical Searchは特に適切な前処理などを組み合わせることで、かなり良い仕事をします。特に速度性能は抜群です。
しかしこれまでに見てきた通り、Lexical Searchを実装する際は検索クエリーに含まれる単語が転置インデックスの辞書とマッチすることが重要、というか前提になります。従って同じ概念について検索する際に別の検索語がクエリーとして使われると、検索漏れが発生してしまいます。また、マルチモーダルと呼ばれるテキスト以外の音声や画像、動画などに対する検索は根本的に実装することができません。
そこでSemantic searchと呼ばれる、ユーザーの「意図」を汲み取って必要な情報を取得するための仕組みが開発されています。Semantic searchでは、クエリーの文字列に意味内容の似通った文書を検索することができます。
現在特にSemantic searchが求められている背景には生成AIの発達があります。生成AI(LLM)により正確な回答を求めるためには、適切な前提知識(コンテキスト)を与える必要があります。このために、既存の文書群(この場合ナレッジベースなどと呼ばれることがあります)から適切な文書を見つけ出し、前提知識としてLLMに与えるRAG(Retrieval Augmented-Generation)という仕組みが広まっています。このコンテキストを見つけるための検索(Retrieval)では、通常ユーザーは知りたい情報の意味的な内容を入力しているだけで、具体的な用語等についてはクエリーに含まれていません。例えば「チャットボットを実装するために必要な技術」という検索クエリーから、Semantic searchなどの関連技術情報についてのドキュメントを検索するには、キーワード検索だけでは不十分です。従ってこのような検索ではSemantic searchが不可欠となっているのです。
ベクトル検索
Semantic searchは通常ベクトル検索として実装されます。ベクトル検索とは、文書およびクエリーをベクトルとして表現し、クエリーベクトルに最も近い文書ベクトルを検索結果として返す技術です。
言葉だけだと何のことかわかりませんね。以下のブログに良い図があったので拝借します。
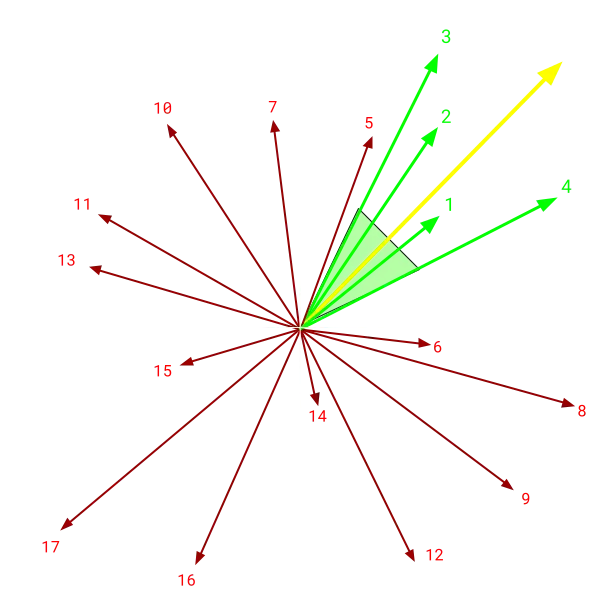
この図で番号のついている矢印が、コーパス内の文書を表現するベクトルです。それに対し、黄色い矢印はクエリーを表すベクトルです。このクエリーベクトルに対して類似する文書ベクトルは緑色の4つなので、これらのベクトルに対応する文書を検索結果として返すのがベクトル検索です。
確かにそう言われれば動作しそうな気はしますが、さてそもそもどのように文書やクエリーをベクトルに変換するのでしょうか。この記事の対象とする範囲を逸脱してしまうので詳しく説明することはできませんが、Semantic searchの文脈におけるベクトル検索では、機械学習の技術を使って他の多くの文書で調べた単語の出現パターンを学習したモデルを作成し、そのモデルを使ってテキストをベクトルに埋め込む(Embedding)、ということが行われます。
またここで重要なのはベクトル表現を作成するという処理と、ベクトル検索の処理は全く別物だということです。機械学習のモデルはあくまでベクトル表現を作成する際に利用されます。Lucene/Elasticsearchではベクトル検索(ベクトルデータベース)の機能は持っていますが、テキストをベクトル化する機能は(本質的には)持っていません。テキストのベクトル化には、何らかの形でElasticsearchの外部のMLモデルを必要とします。
(Elasticsearchユーザー向けの注: ただし、ELSERおよびMultilingual-E5モデルはElasticsearchにバンドルされているため、特に追加の作業なく利用することが可能です。)
ベクトル検索における類似度 (Similarity)
Lexical searchではBM25を使って類似計算を行いますが、ベクトル検索ではクエリーベクトルと文書ベクトルの類似度を以下のいずれかのような尺度で計算します。
- ユークリッド距離: 幾何学的な距離(近いほうが似ている)
- コサイン: 角度(同じ方向を向いている方が似ている)
- 内積: 向きと大きさ(同じ方向を向いていて、ベクトルが大きい方が似ている)
距離計算については以下の記事が詳しいです。
どの類似度を使うにせよ、工夫がない場合には入力されたクエリーベクトルに対してコーパス内にある全てのベクトルに対して距離計算を実行する必要があるため(ブルートフォース)、計算の効率はよくありません。
HNSW (Hierarchical Navigable Small World)
そこで多くのベクトルデータベースではHNSW(Hierarchical Navigable Small World)と呼ばれる高速化手法を導入しています。HNSWでは各ベクトルをノードとしたグラフとしてベクトル空間を表現しますが、さらにノードの密度が疎なものから密ものに至る複数レイヤーのグラフを作成し、上位から最もクエリーに近いノードを探索していくことで高速かつスケーラブルなベクトル検索を実現する手法が開発されています。

図は元となっている論文からの引用です。
これについて詳しく説明することまた長くなってしまうので、詳細は上記論文等を参照してください。
Quantization (量子化)
HNSWを使うとベクトル間の比較の回数を劇的に減らせますが、このグラフ構造を含め基本的にすべてのノードの情報をメモリー上に展開する必要がある点については変わりません。そこで大量のデータを対象にベクトル検索を実現するためには、如何にメモリーの使用量を抑えるかが鍵になります。
通常、テキストをベクトルにエンべディングするとそれぞれの要素はfloat32 (4バイト)の精度で表現されています。これをより少ないビット数に圧縮することでメモリーの使用量を抑えることが可能です。Elasticsearchではint8, int4やbitへの量子化がサポートされています。
当然量子化を実施するとその分ベクトルの類似度計算の精度が下がります。しかしElasticsearchでは実際に必要な検索件数よりも多く量子化した状態で検索し(オーバーサンプリング)、その後見つかった検索結果に対して元のFloatのベクトルを使って再度類似度計算をすることで検索精度をむしろ向上させるテクニックなども導入されています。
Sparse Vector Search (疎ベクトル検索)
これまで何の断りもなくベクトル検索書いてきましたが、通常単にベクトル検索というと、それは密ベクトル(Dense Vector)を使った検索を意味します。これは、任意の次元のベクトルのそれぞれの要素に隙間なく情報が埋め込まれているベクトルを利用しているからです。
それに対してSparse Vectorでは、通常コーパスにある語彙次元の広大なベクトル空間を利用しつつ、少ない語彙に対するスコアのみを保存し、それ以外はすべてゼロという疎ベクトルを使った検索を実現します。
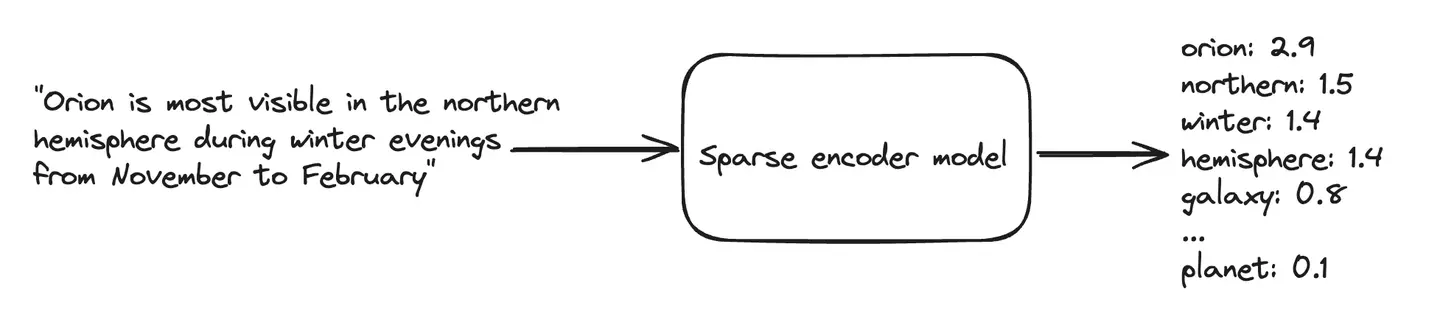
Sparse Vector Searchについては以下の記事を書いていますの参照してください。
Sparse Vectorを作成するモデルとしてはNaverによるSPLADEが有名です。
またElasticsearchでは上記SPLADEの影響を受けつつ、公式の組み込みモデルであるELSERがあります。
Sparse Vectorでは各語彙に対応するスコアを持つ、という構造を取るため、転置インデックスの構造を利用しやすいのが特徴です。Sparse Vectorの作成には外部モデルが必要ですが、一度そのようなモデルでベクトル表現が得られれば、いわゆるDense Vectorで使われていたような幾何学的な手法ではなく、転置インデックスに対するスコア計算として実現することができ、速度やメモリーの効率性を高めることができます。
まとめ
この記事では情報検索で必要となるであろう基本的な技術の構成要素について紹介してきました。不足に気づけば追記していくつもりです。
これから検索関連の開発を始める場合などにぜひ参照してください。