はじめに

Elasticsearchでは時系列データに対して異常検知(Anomaly Detection)のジョブを作成することができます。その際、内部ではElasticsearchのCreate anomaly detection jobs APIが利用されているわけなのですが、Kibanaからウィザード形式で簡単に作成することもできるため、多くの場合このKibanaのウィザードを使う方法でジョブを作成しているのではないでしょうか。
ただ、特に日本語ではそれぞれのウィザードでどのような検知ルールを定義できるのかがわかりにくい現状があるため、ここで簡単にそれぞれについて紹介したいと思います。
この記事で利用するElasticsearchのバージョンは8.12.2です。
ちなみに英語の場合は公式サイトにそれぞれのジョブタイプごとの説明が一応ありますが、テキストだけでかなり大雑把な説明にとどまっています。
シングルメトリック / Single Metric
最も基本的な種類のジョブで、単一の数値情報を時系列で分析します。横軸に時間、縦軸に今注目している数値がくる、というグラフを想像してもらうとわかりやすいですね。
典型的な分析内容は以下のようなものです。
- Webサーバーのアクセス回数の異常検知
- サービスのユニークユーザー数の異常検知
- レスポンスタイムの平均値
上記のように、一つのジョブで一つの数値のみを追跡、分析することになるため、サービス全体で一つの数値に集約されるデータについて分析することになります。
ちなみに、フィールドに適用する集計処理においてHigh Countは通常より上振れした場合にのみ反応し、Low Countは通常より下振れした場合にのみ反応するDetector Functionです。High Mean/Low Mean等も同様です。
検知結果はシングルメトリックビューワーで見ると以下のようになります。

最も高い深刻度(Severity)は78で、通常より1.1倍低いことがわかります。またこの異常はマーカーが「+」マークになっているため、Multi Bucket Anomary、つまり直近の値との比較での変化率が通常とは違うということがわかります。最もスコアの高い異常について、>マークを展開するとより詳細な情報を閲覧できます。

異常スコアについては以下の公式ドキュメントも参照してください。
マルチメトリック / Multi Metric
シングルメトリックでは一つのジョブで単一のメトリクスに対する分析を行いました。それに対して、マルチメトリックではホスト単位、ユーザー単位などデータを分割した上での分析や、CPUとメモリーの使用率を同時に分析するようなジョブを作成することができます。
典型的な分析内容は以下のようなものです。
- サーバーごとのCPU、メモリーの使用率の異常検知
- 地域ごとの売上推移の異常検知
- データセンターごとのレスポンスタイムの異常検知
以下はKibanaのeCommerseのサンプルデータで、地域ごとの売上とユニークユーザー数を分析するジョブを作成する時の画面です。
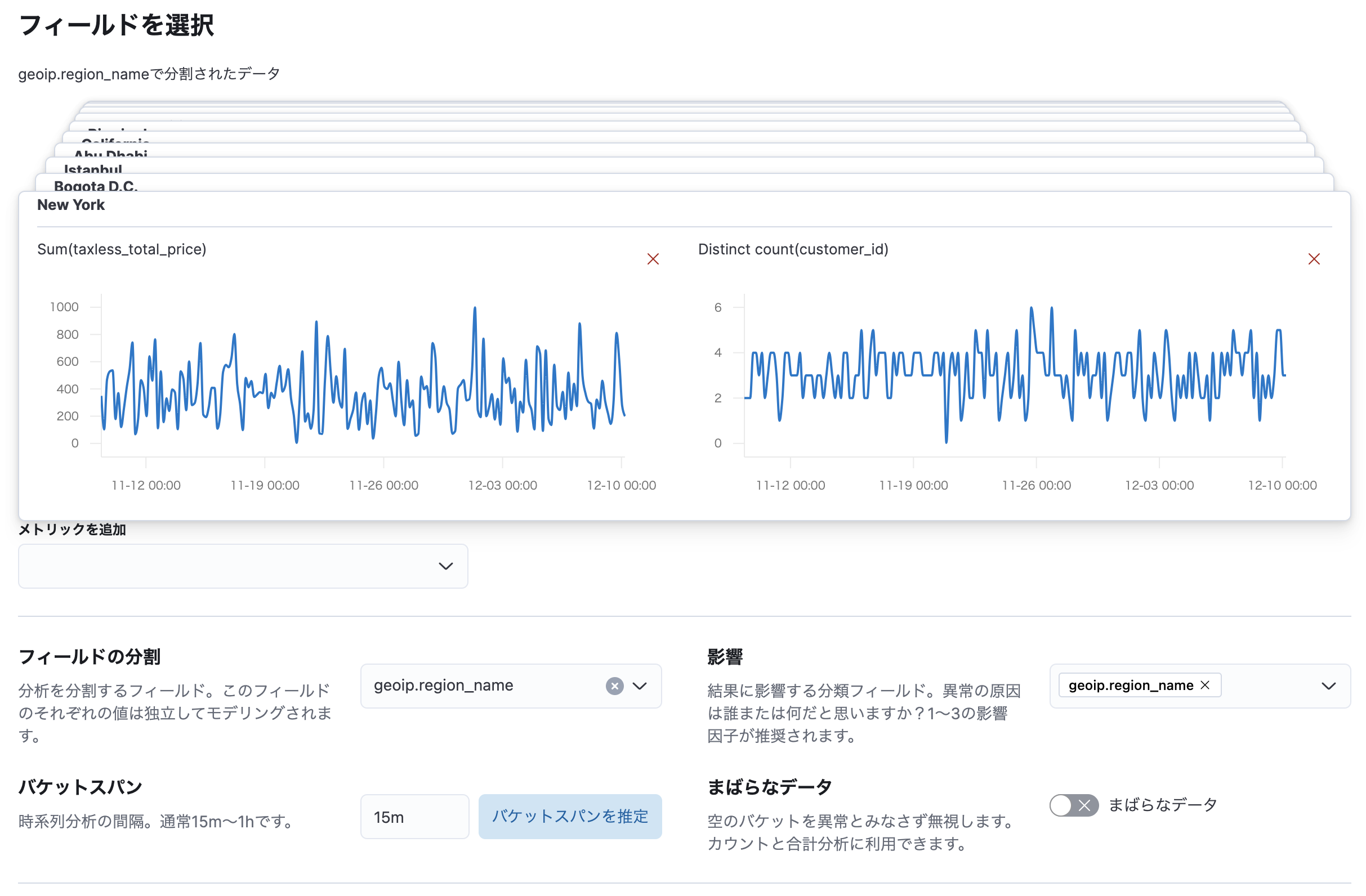
「フィールドの分割」でgeoip.region_nameを選んでいるため、集計するメトリックスが都市ごとに分割されていることがわかります。
あと一つ大きな注意点ですが、ここで売上とユニークユーザー数の二つのメトリックを同時に扱っていますが、ElasticsearchのMulti Metricではこれらの相関は見ていません。あくまでそれぞれの数値が、過去の振る舞いとの比較でどれだけ通常から逸脱しているかを判断しています。「ユーザー数が増えているのに売上は下がっているからおかしい」のような分析はできません。
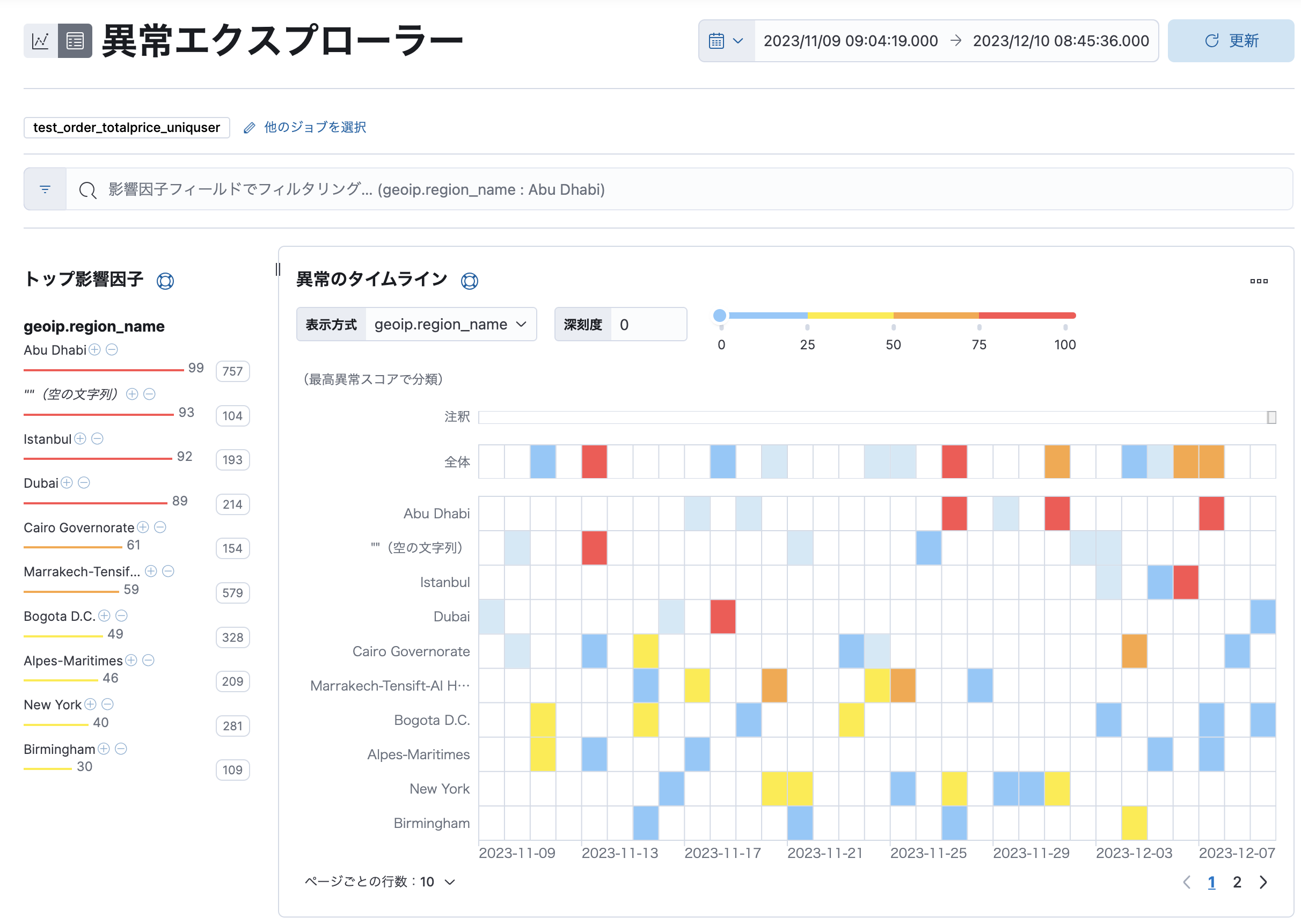
ジョブの実行が終わると、異常エクスプローラー(Anomaly Explorer)で検知した異常を閲覧することができます。画面上のスイムレーンで、分割したそれぞれの要素ごとに、どれくらいの異常が発生しているかを概観できます。
任意のセルをクリックすると、その分割要素およびバケットの時間帯での絞り込みをすることができ、また簡易的なメトリクスの推移も表示されるので、どのような振る舞いが発生していたかを簡単に理解することができます。
集団 / Population
集団/Population分析では、それ以外の分析が「自分自身の過去のデータ」との比較で異常を検知しているのとは異なり、「他のエンティティー」と比較して振る舞いの異常度合いを検出します。例えば次のようなルールを作成することができます。
- 他ユーザーに比べて外部と通信する回数・トラフィックが多いユーザーを検出する(情報漏洩の疑い)
- 他のホストに比べて外部と通信する回数・トラフィックが多いホストを検出する(マルウェア感染の疑い)
- 他のホストに比べて通信先のIPアドレスが多いホストを検出する(ポートスキャン)
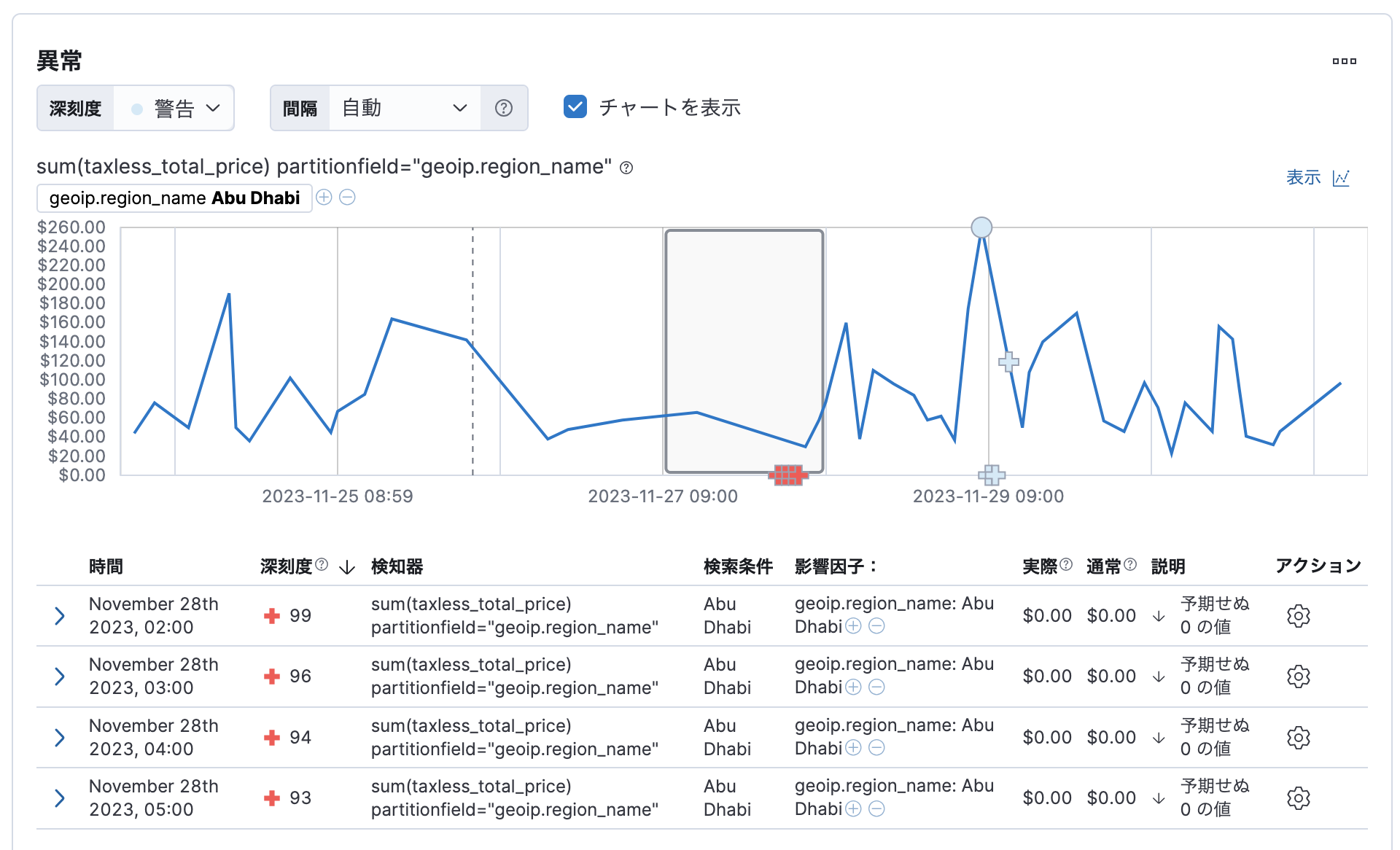
以下はKibanaのVisitsのテストデータで、clientipごとに他との比較で異常を検知した結果です。「177.120.218.48」のアクセスが一時他に比べて多かった(あるいは少なかった)ことがわかります。

この赤くなっているバケットをクリックしてみましょう。

すると、他のIPからはおおよそ一時かなたり1回のアクセスであるのに対し、このIPからは7回のアクセスが来ていることがわかります。
カテゴリー分け / Categorization
主に数値を扱う他の分析と違い、カテゴリー分け/Categorizationはテキストフィールドを対象にした分析を行います。主にログデータに対する分析に効果を発揮します。
ログデータはそれぞれの行ごとに例えばアクセスURLやトラフィック量など、毎回変数として変わる部分がありますが、大枠としてはこれはアクセスログ、これはデータベースに接続するときのログ、これは外部APIの呼び出しに失敗した時のログ、というようにカテゴライズことができるでしょう。このカテゴライズをElasticの機械学習が自動で行なったうえで、それぞれのカテゴリーごとの出力傾向を分析するのがカテゴリー分け/Categorization分析になります。
ウィザードでは対象となるデータソースを選択した後、「カウント」か「ほとんどない」を選択し、実際にカテゴライズするテキストが入っているフィールドを指定します。

すると画面上で実際に今あるインデックスの中のデータで、どのようなカテゴリーが抽出されるかをプレビューすることができます。

ジョブを実行すると異常エクスプローラーで以下のような結果を閲覧することができます。ただこれを見るときには若干慣れが必要で、Elasticではそれぞれのカテゴリーに適切な(人にわかりやすい)名前を自動でつけることができません(例えばアクセスログ、とか)。そこで見つかったカテゴリーごとに1からの連番を振ります。ジョブを実行するたびにどのカテゴリーに何番が割り振られるかはわかりません(時系列にどのような順番で書き込まれているかによる)。ここでは2番のカテゴリーで高い異常が検知されているようです。
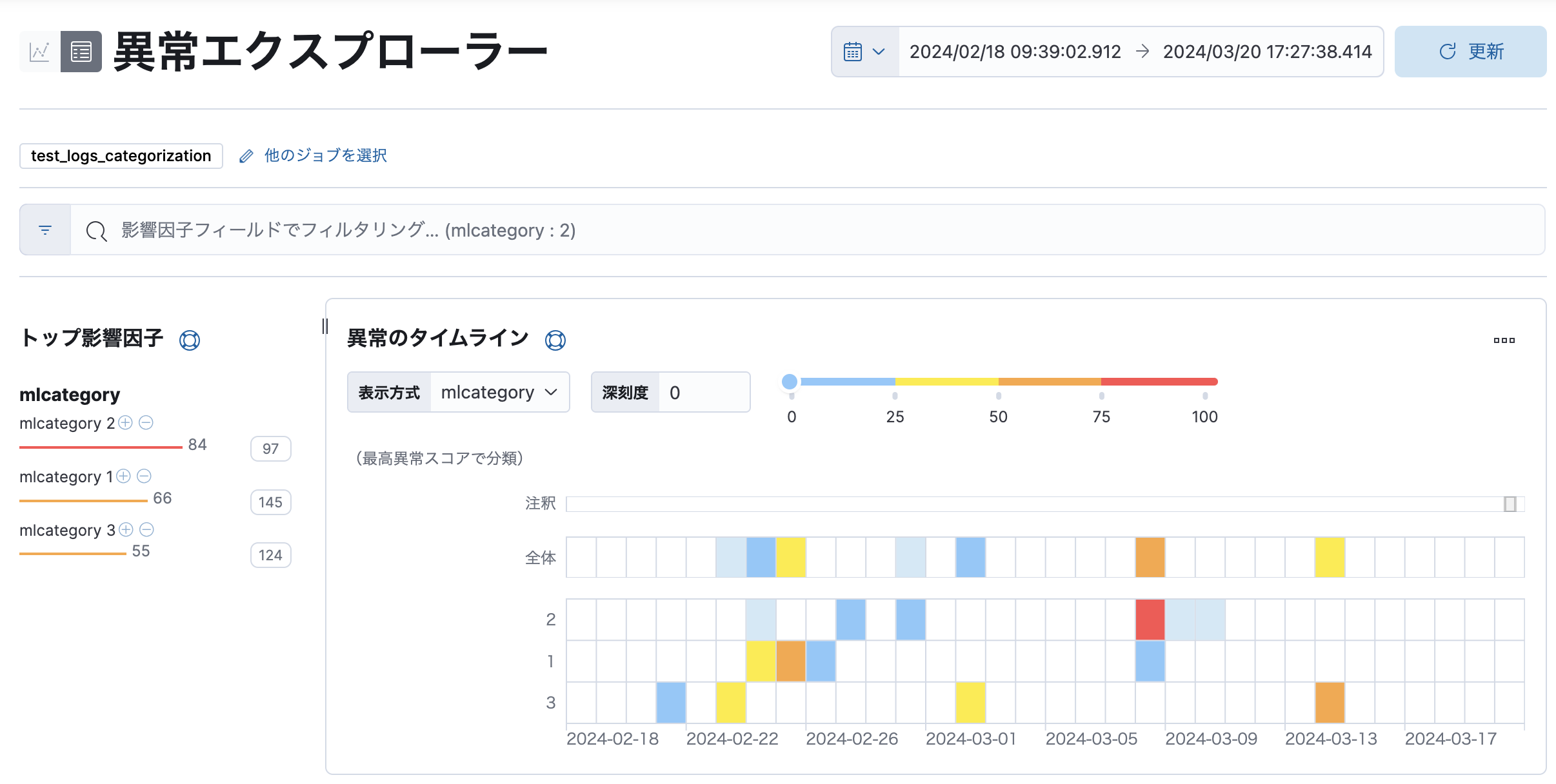
では、その異常をもたらしているログメッセージはどんなものだったのでしょうか。

表形式の中にも該当のカラムがありますがちょっと狭すぎて何が書いてあるかわかりませんね。当該の異常の>マークを展開して、「カテゴリーの例」タブを表示しましょう。するとそのカテゴリーに分類されたログメッセージの例を見るとができます。
ほとんどない / Rare

個人的にはこの「ほとんどない/Rare」のタイプの内、上記の選択肢それぞれがどういう挙動をするのかが直感的にわかりにくいと感じましたので、それぞれ説明します。
ちなみに英語UIの方がいくらかわかりやすいかもしれません。

ほとんどない / Rare
一つのフィールドに注目して、そのフィールドに滅多に現れない値が出現したときに異常として捉えます。メトリックにおけるシングルメトリックジョブのような位置付けと理解するとわかりやすいかもしれません。例えば次のようなルールを作成することができます。
- 滅多に検出されないプロセスを見つける
- 滅多にアクセスしない通信先IPアドレスを見つける
以下は滅多に使われないユーザーがログに現れたことを検知するジョブの例です。
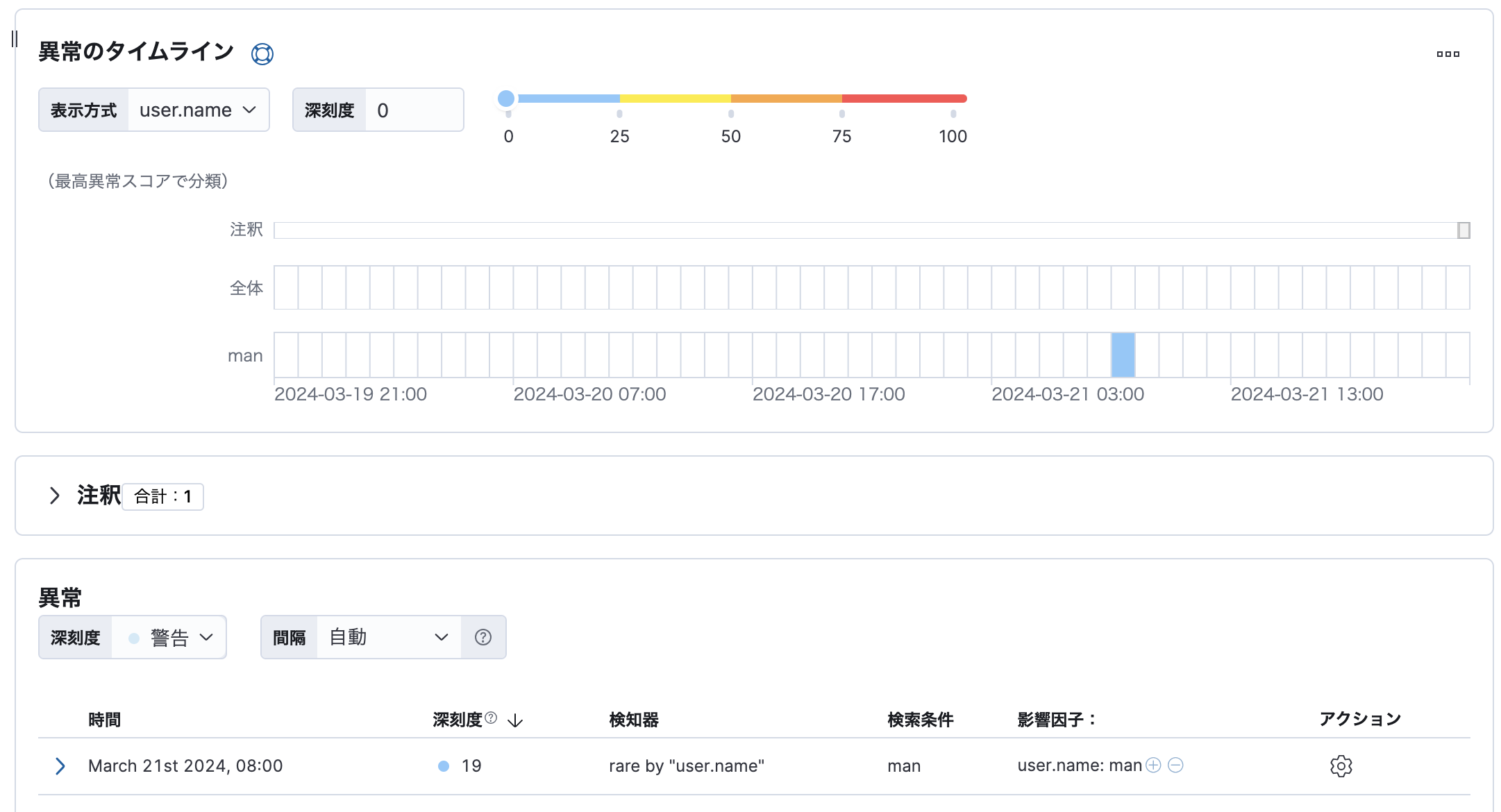
母集団でまれ / Rare in population
RareとPopulationの分析を同時にかけるジョブです。ある集団の中で他のメンバーから滅多に検出されないことを特定のメンバーから検出した場合に異常として検知します。例えば次のようなルールを作成することができます。
- 他のユーザーは滅多にアクセスしないURLにアクセスしているユーザーを検知する
以下はsource.ipごとに他のsource.ipでは稀なプロセス名を検知するジョブを作成した場合の例です。


母集団で頻繁にまれ / Frequently rare in population
はい、何を言っているかパッとわかりましたか? 私はわかりませんでした。
このジョブでは、ある集団の中で他のメンバーから滅多に検出されないことを、特定のメンバーから頻繁に検出した場合に異常として検知します。例えば次のようなルールを作成することができます。
- 他のユーザーは滅多にアクセスしない色々なURLに、何度もアクセスしているユーザーを検知する
以下は他のプロセスでは滅多に出現しないevent.actionが現れるプロセスを検知するジョブの結果例です。

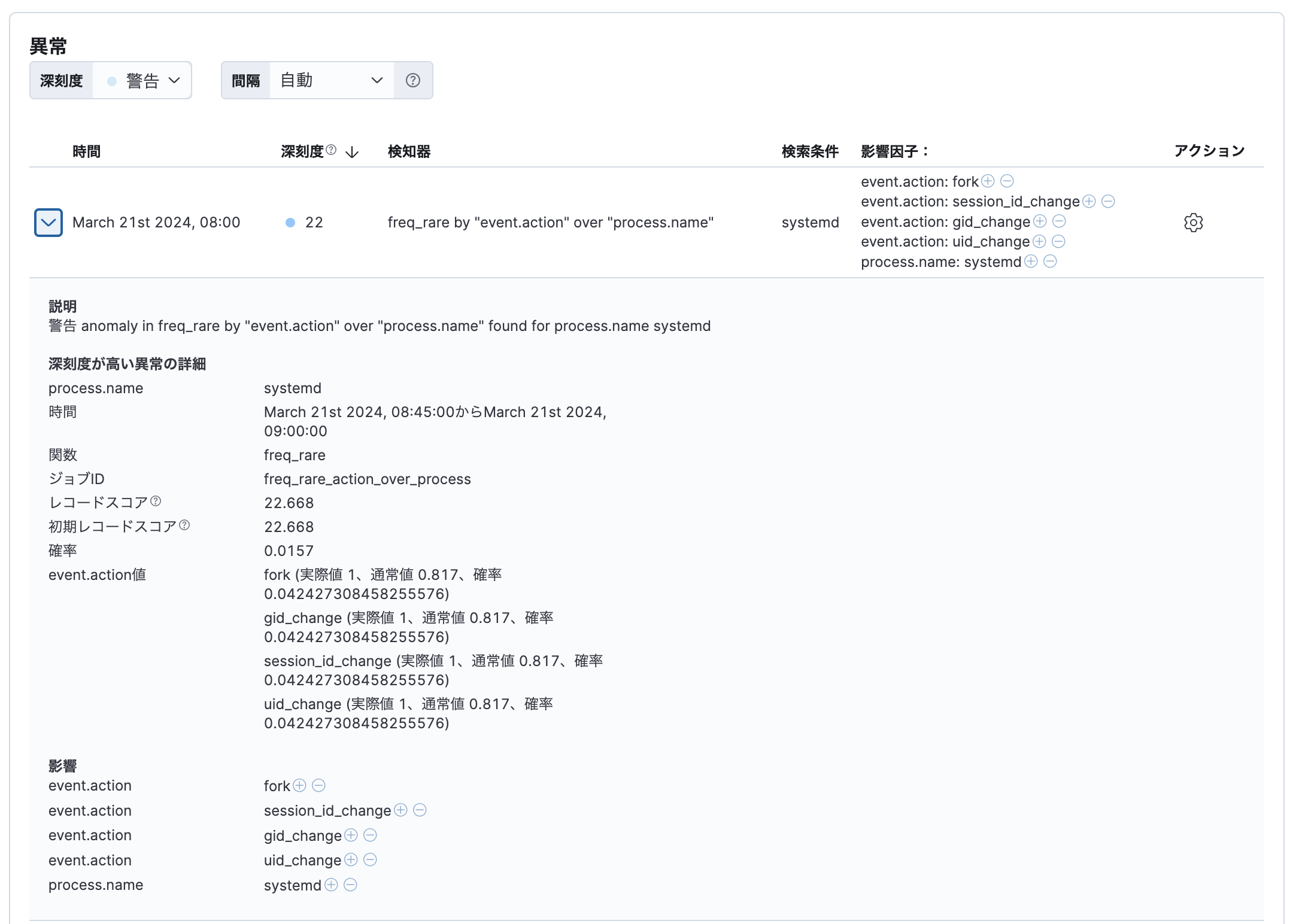
地理情報
緯度経度で表される地理情報をもとに、滅多にない場所がデータに現れた場合、異常として検知されます。
例えば次のようなルールを作成することができます。
- ユーザーごとに普段ログインしない場所からログインした
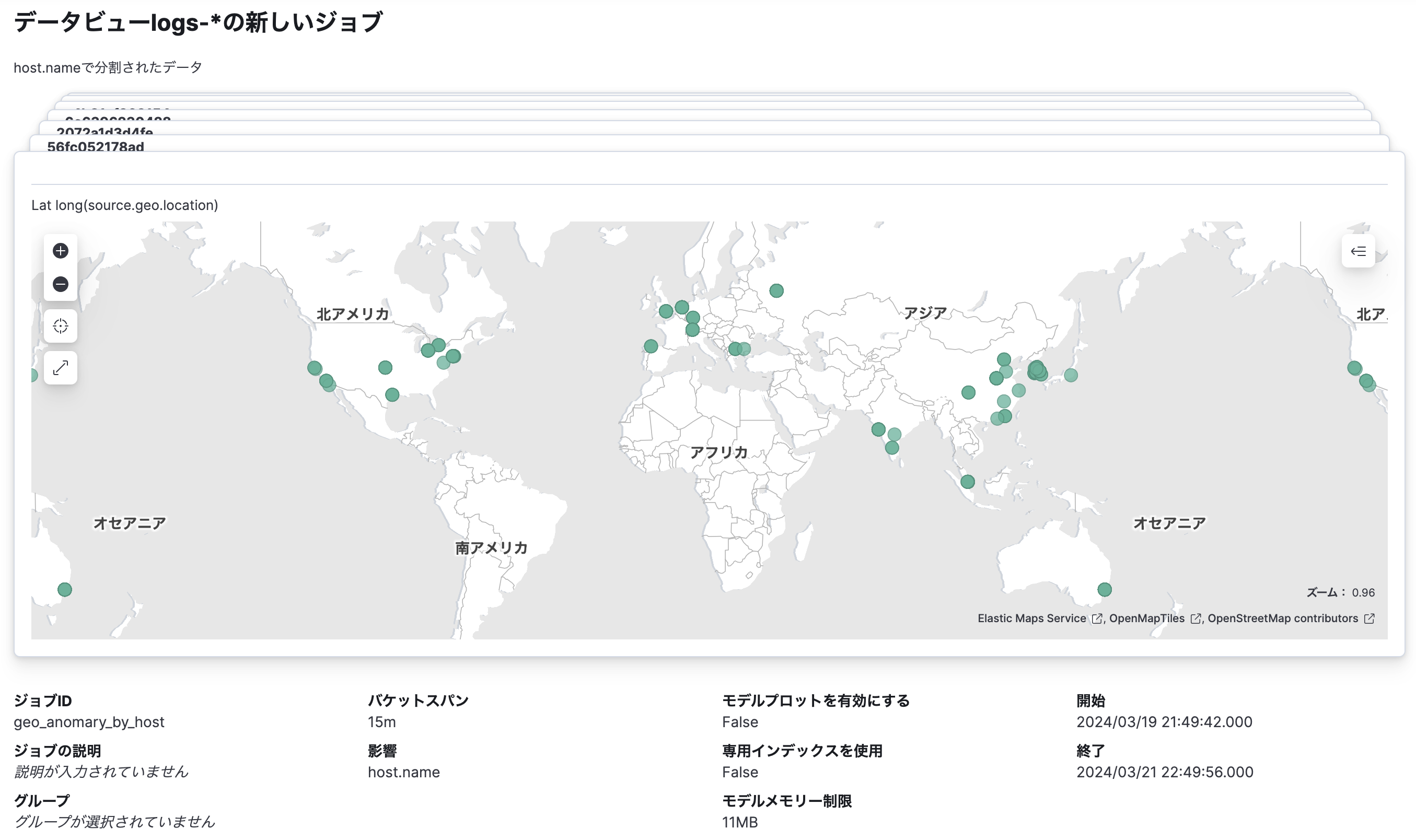
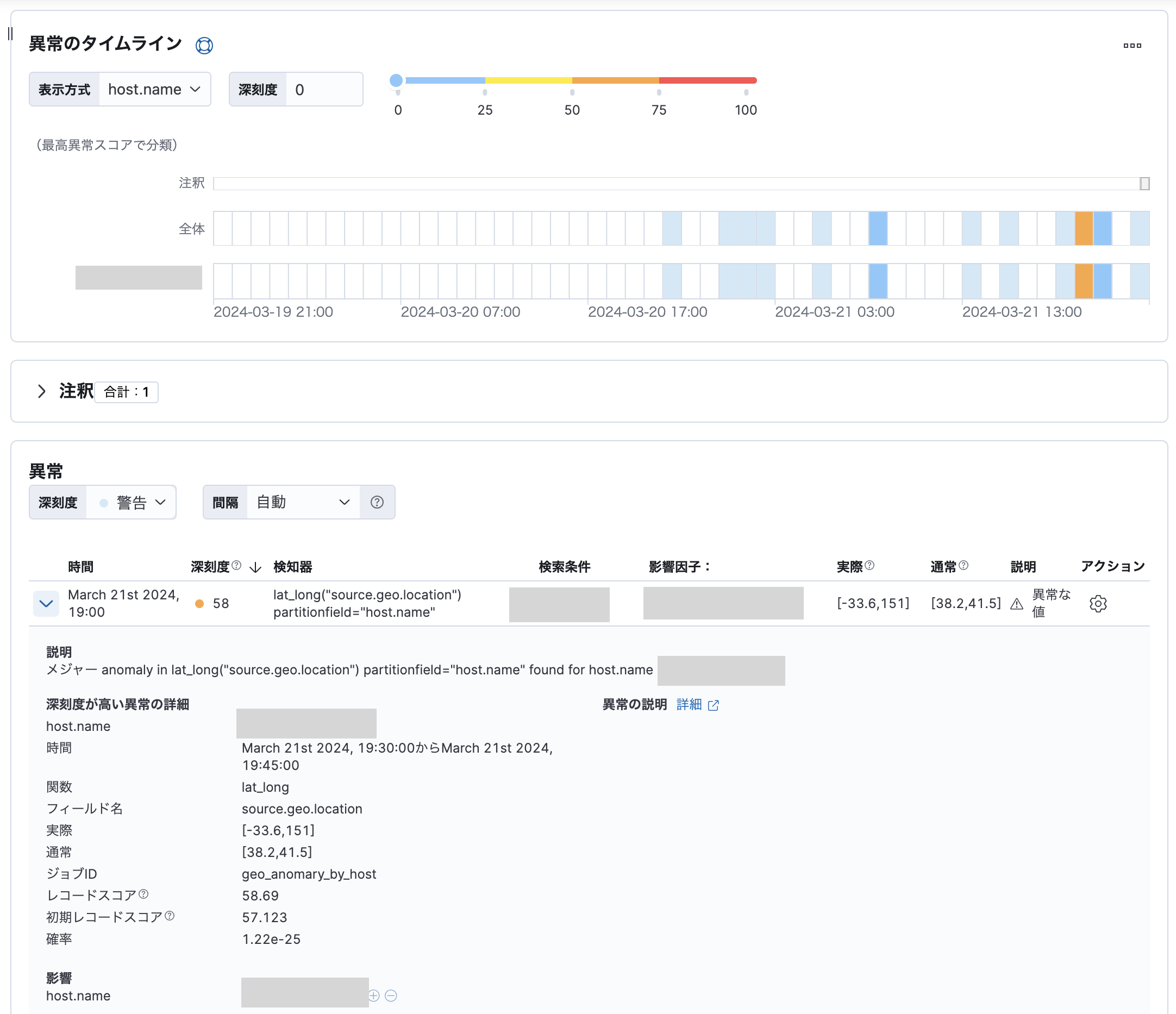
以下はホストごとにsource.ipから得られる位置情報が通常と異なる場合を検知するジョブを作成する例です。
結果は以下のようになりました。(ホスト名の部分はマスクしています)
また、アクションからMapへ移動して地図上で位置情報の通常との差異を表示することもできます。

ギアマークから「Mapsで表示」をクリックすると、以下のような画面を表示できます。

おわりに
ElasticsearchのAnomaly Detectionのウィザードで簡単に作成できるジョブの種類について、大雑把に説明しました。それぞれのウィザードで実際にどのような検知ルールが作成できるのかがわからなかったり、やりたいことが決まっているがどのウィザードを使うのが適切かわからないような場合に参照してください。