この記事は、「Machine Learning is Fun Part 6: How to do Speech Recognition with Deep Learning」(medium.com)の翻訳です。
音声認識はスマホやゲームコンソール、スマートウォッチなど、日常に浸透してきています。ホームオートメーションにも欠かせません。$50でAmazon Echo Dotを買えば、ピザを注文したり、天気予報を聞いたり、ゴミ袋を注文したり、大声で呼びさえすればいいのです。

Echo Dotはとても人気で、ホリデーシーズンにはAmazonが在庫を切らしたほどです。
しかし音声認識が出てきてもう数十年、今何故主流になったのでしょう? それはディープラーニングによって音声認識が十分な制度に到達し、配慮された環境外でも実用的になったからです。
Andrew Ngは音声認識の精度が95%から99%に到達し、コンピューターインターフェースの主流になると予測しました。この4%のギャップは、イライラさせる信頼できないものと、とても使えるものの差を意味します。ディープラーニングのおかげで、今や頂点に達しました。
機械学習はいつもブラックボックスというわけではない
もしどうやって機械翻訳を実現するかご存知なら、単純に録音音声を与え、対応するテキストをニューラルネットワークに学習すれば良いのではと思うでしょう。
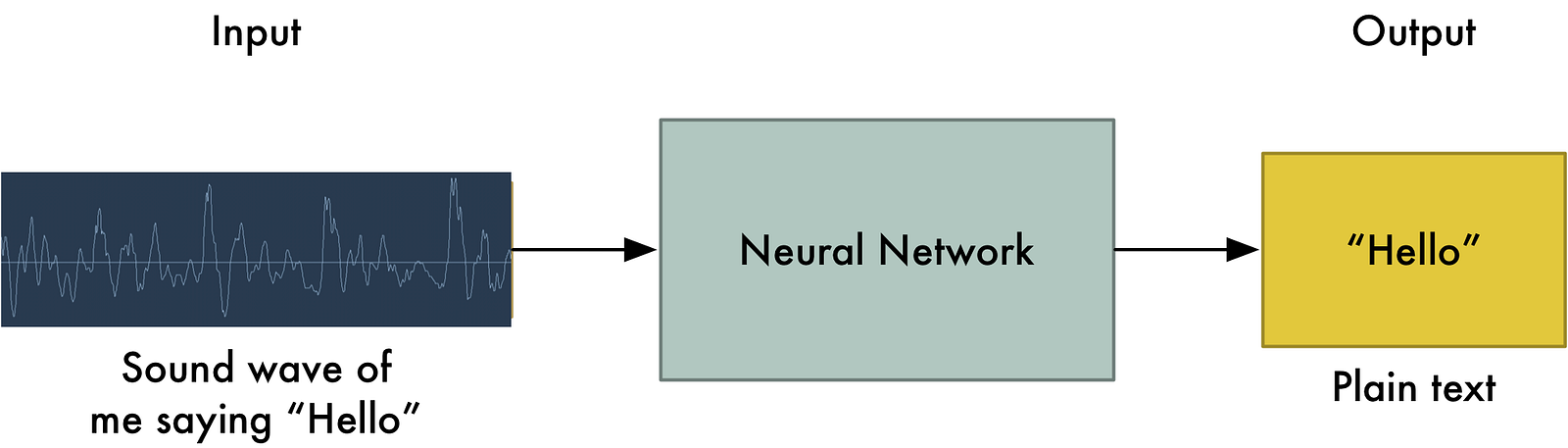
それこそ至高の目標ですが、まだ我々はそこまで到達していません。(少なくともこれを書いている時点では、数年で到達できると思いますが)
大きな問題は、発話のスピードが変わることです。ある人が「こんにちわ!」と早く発音したとして、もう一人は「こーーーんにーちーわー!」ととっても遅く発音して、とても長くて大きいファイルになることもあるでしょう。どちらも「こんにちわ!」というテキストに認識されるべきです。自動的に色々な長さのオーディオファイルを並べ、固定長のテキストに変換するのは、とてもむずかしいことなのです。
これを解決するため、ディープニューラルネットワークとは別に、特別なトリックや追加の処理を行います。では見ていきましょう。
音声をビットに変換
音声認識の第一歩は明白、まず音声波形をコンピューターに与えましょう。
Part 3で、私たちはニューラルネットワークでの画像認識のため、画像を数値の配列として取り扱う方法を学びました。
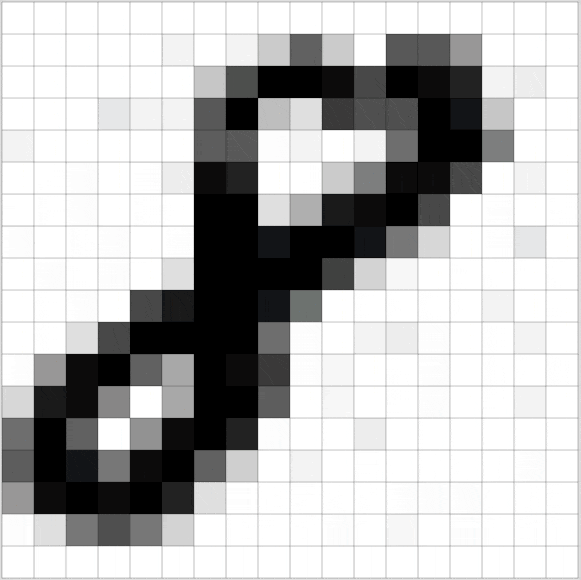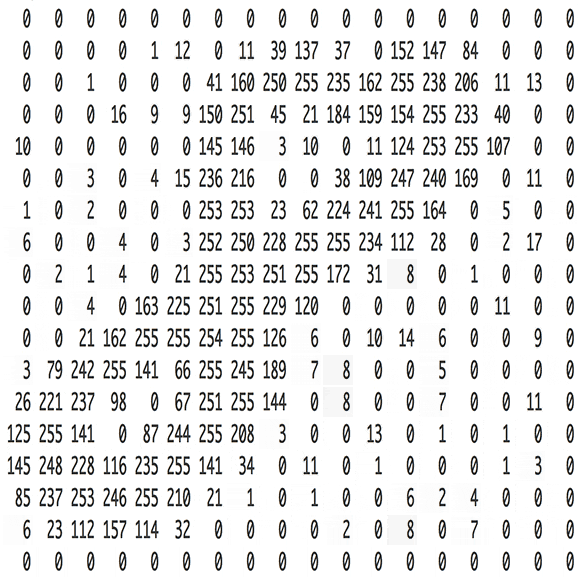
しかし音声は波として伝わります。どうやって数値化するのでしょうか。
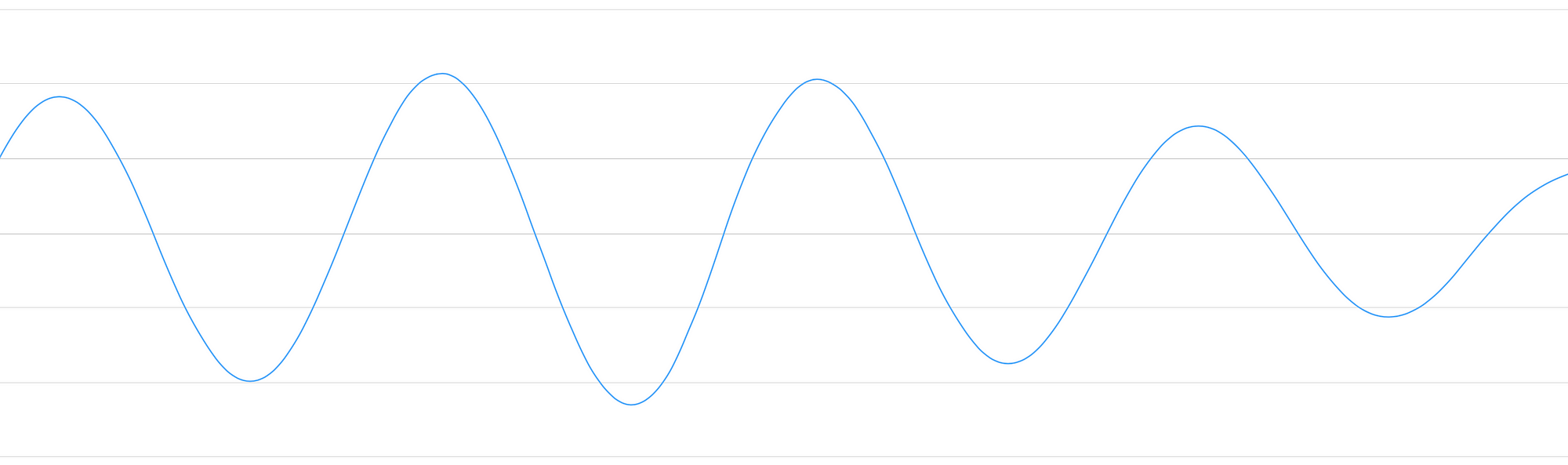
"Hello!"の波形を見てみましょう。
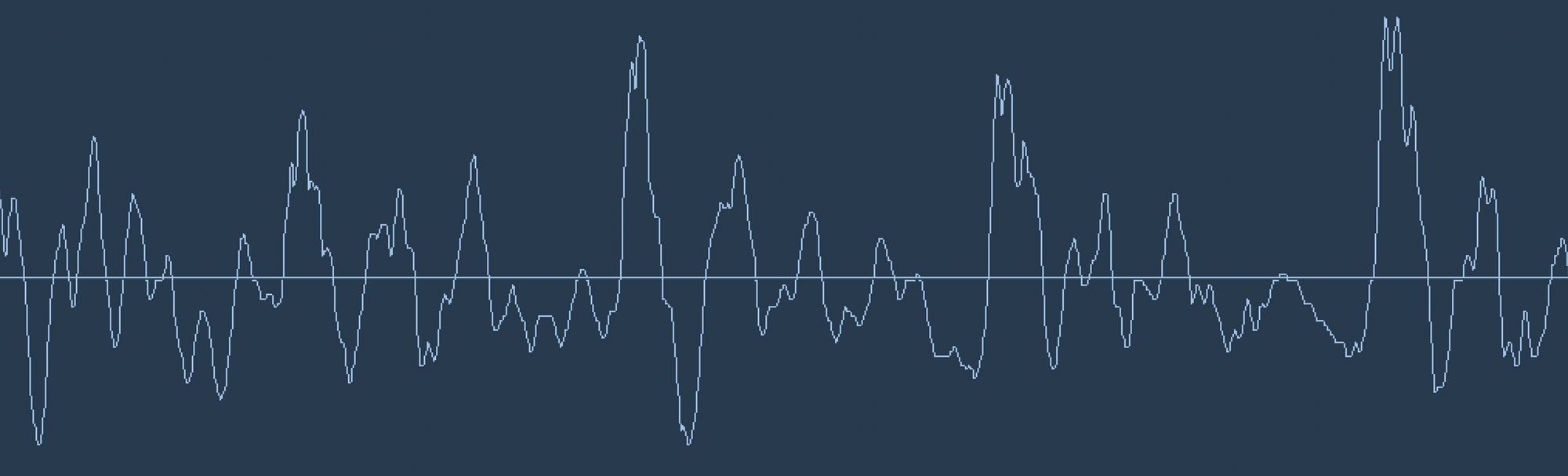
音声波形は一次元です。全ての時点で波の高さを表す一つの数値を持ちます。とても短い区間の音声波形を切り出してみます。
これらの音声波形を数値化すると、私たちはただ波の高さを等間隔の時間間隔で記録しているだけです。

これがサンプリングです。一秒間に何千回と読み取り、それぞれの地点の波の高さを数値として記録するのです。無圧縮 .wav 音声ファイルはほぼこれが全てです。
"CD音質"オーディオはサンプリングレート44.1kHzです。しかし音声認識には、サンプリングレート16kHzもあれば人間の音声の周波数域をカバーするのに十分です。
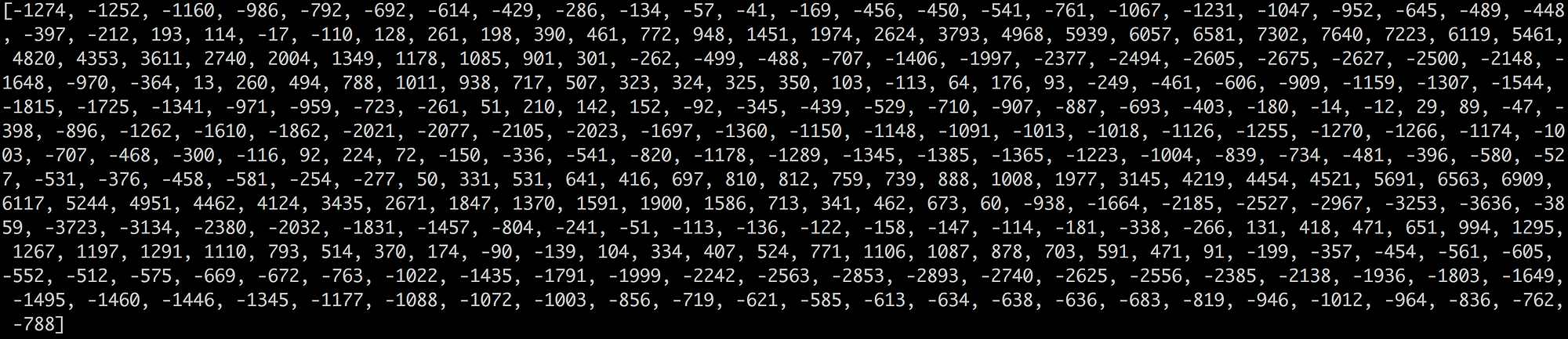
ここで"Hello!"を一秒16,000回でサンプリングしましょう。はじめの100個はこうなります。

デジタルサンプリングについて補足
もしかするとサンプリングは時々読み取った値なので単に粗い近似値でしかないのでは、とお考えでしょう。読み取りと読み取りの間のデータを失っているのでは、と。
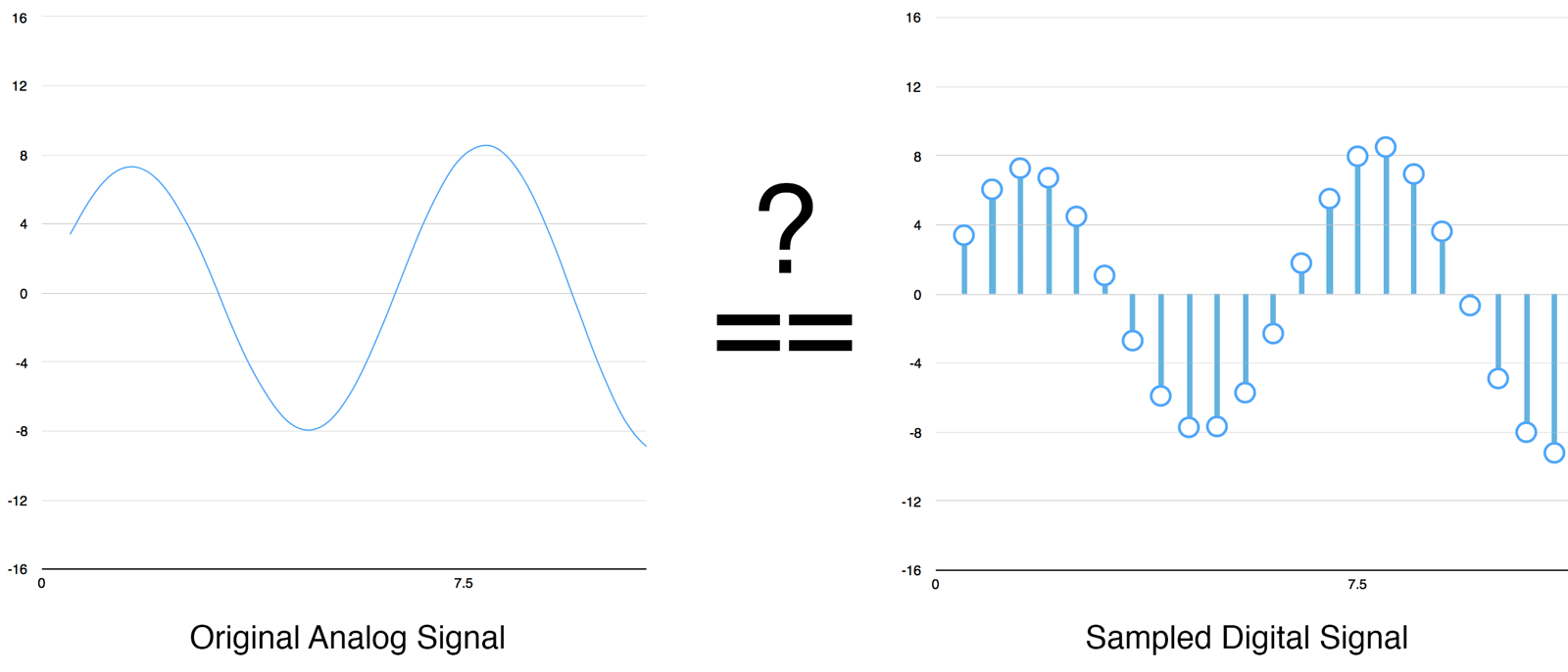
しかしナイキスト定理のおかげで、合間のサンプルも完全に復元できることが数学的に知られています。ただし保存したい最高周波数の2倍の周波数でサンプリングする必要があります。
このことを説明するのは、ほとんどみなさんこれを誤解して、周波数が高ければいいだろうと考えるからです。そうではないのです。
サンプリングされたデータの前処理
音声波形の高さを1/16,000秒ごとに示す数値の配列データが出来ました。
このデータをそのままニューラルネットワークに入力することも出来ます。しかしこのサンプルをそのまま処理して音声パターンを認識するのは困難なのです。代わりに、いくつかオーディオデータに前処理を施して、問題を簡単にします。
まず音声を20ms単位でまとめて扱います。これがはじめの20msのオーディオです。
数字では理解できないので、単純な線グラフで図示しましょう。
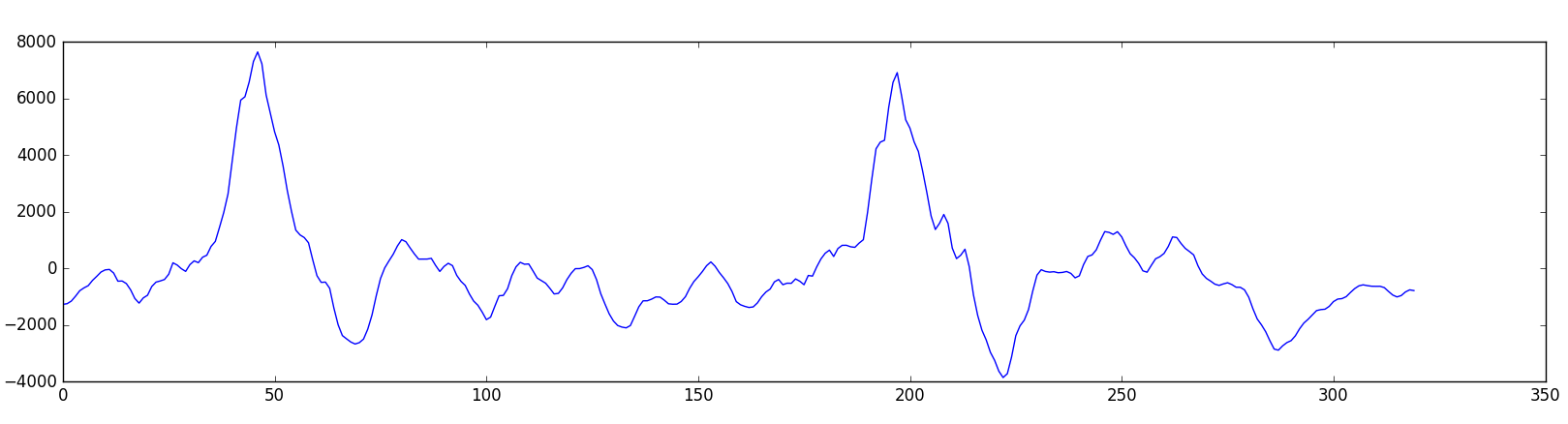
この録音部分は1/50秒の長さです。しかしこの短い録音ですら、いろいろな周波数の音を複雑に寄せ集めたものなのです。低域、中域、いくつか高域の音も散りばめられています。しかしそれらがまとまり、色んな周波数の音が混ざることで、複雑な人間の音声になります。
ニューラルネットワークでの処理を簡単にするため、この複雑な音を要素ごとに分解します。最も低域の音、次に低域な音、という具合に。そして各周波数帯ごとにどれだけのエネルギーを持つかを積み重ねることで、この音声片の声紋を作り上げるのです。
誰かがCメジャーコードをピアノで弾いた録音を持っているとしましょう。その時の音は3つの音C、E、Gを混ぜた複雑な一つの音になっています。この複雑な音を分解して、それぞれC、E、Gの音を取り出したいのです。このことと同じ考え方です。
これをするにはフーリエ変換という数学的演算を行います。これで複雑な音を複数のシンプルな音に分解します。一旦それぞれの音に変換されると、それぞれのエネルギーを集めます。
最終的には、低域から高域までそれぞれの周波数帯がどれだけ重要か数値化されます。以下の数字はそれぞれの50Hzが20msのオーディオ片にどれだけエネルギーを持つかを表します。
図で表すと分かりやすくなります。

20msごとの処理を繰り返すと、このスペクトログラムになります。
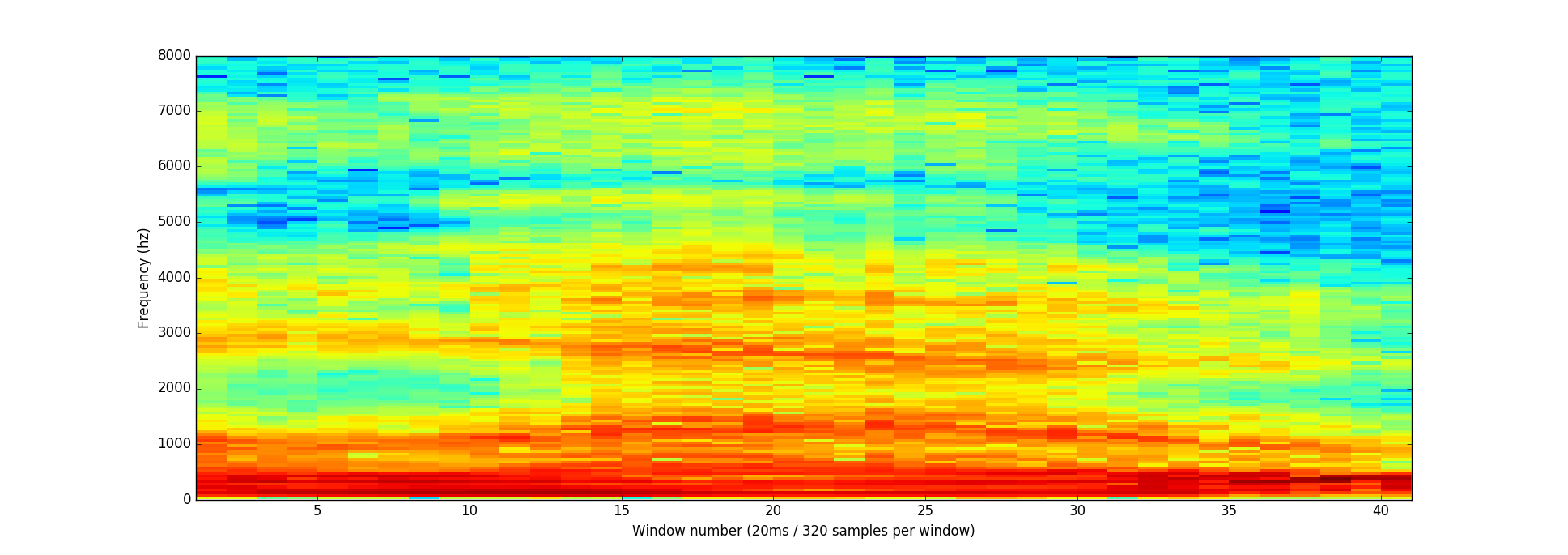
スペクトログラムは音や音程のパターンを視覚的に確認できるので便利です。ニューラルネットワークはこのようなデータからパターンを見つけるほうが、元の音声波形よりずっと簡単です。ニューラルネットワークには、このデータ形式で与えます。
短い音声から文字を認識する
処理しやすい形式でオーディオを用意できました。ディープニューラルネットワークにこれを与えます。入力するのは20msのオーディオ片です。それぞれのオーディオ片ごと、そのとき話された音に対応する文字を認識しましょう。
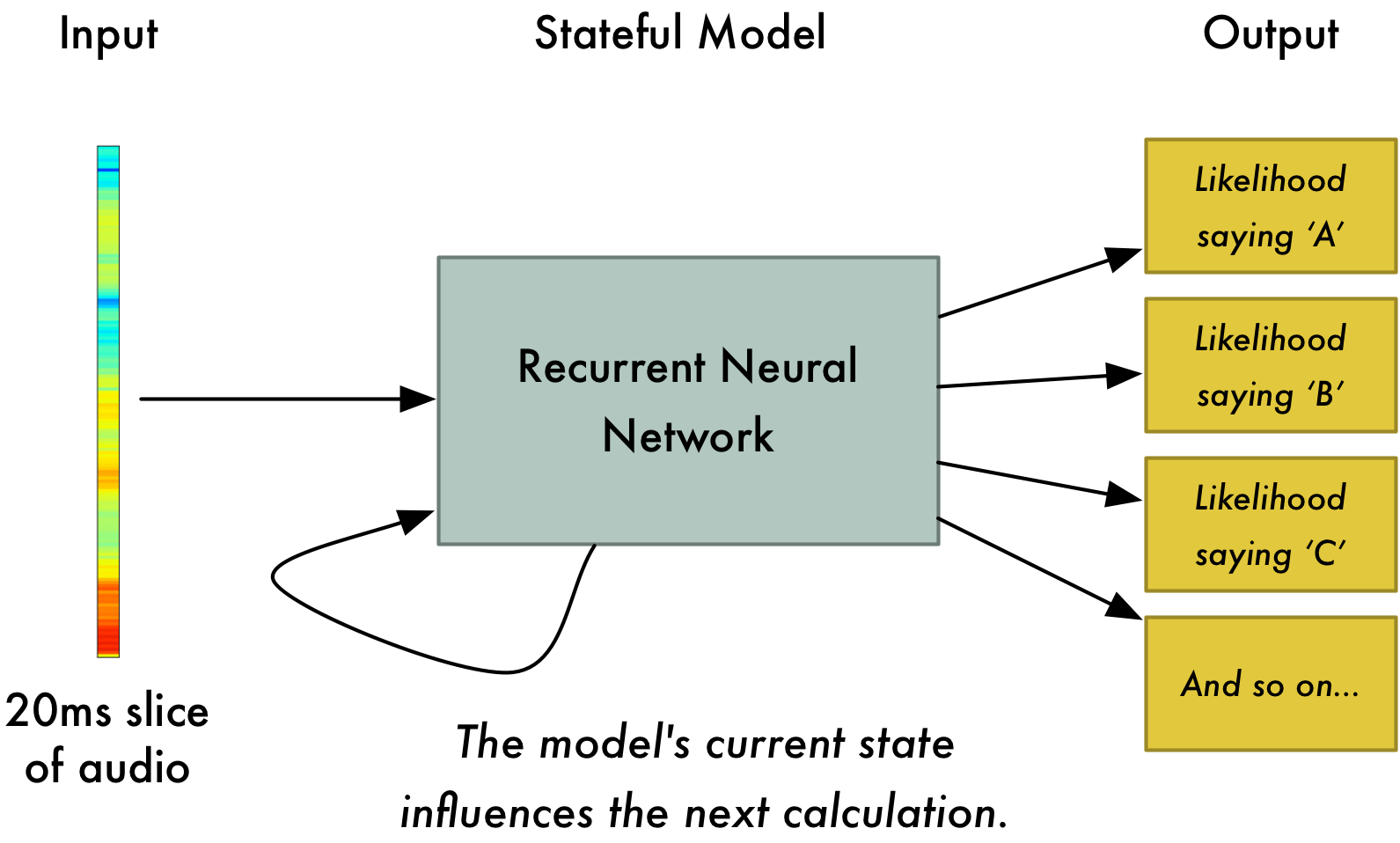
再帰的ニューラルネットワークを用います。これは、将来に影響する記憶を持つニューラルネットワークです。予測されるそれぞれの文字は、次に来る文字に影響すると考えられるからです。例えばもし"HEL"と来た場合、次に"LO"ときて全体で"Hello"と完成することが期待されます。また、"XYZ"の次のような発音できないものはありえにくいのです。前回までの予測の記憶を持つことで、ニューラルネットワークがより正確に予測を進めていくことが出来るのです。
全てのオーディオ片をニューラルネットワークに予測させることで、それぞれのオーディオ片が最もありえそうな文字に対応付けることが出来るのです。これは"Hello"と言っている音声を処理したものです。
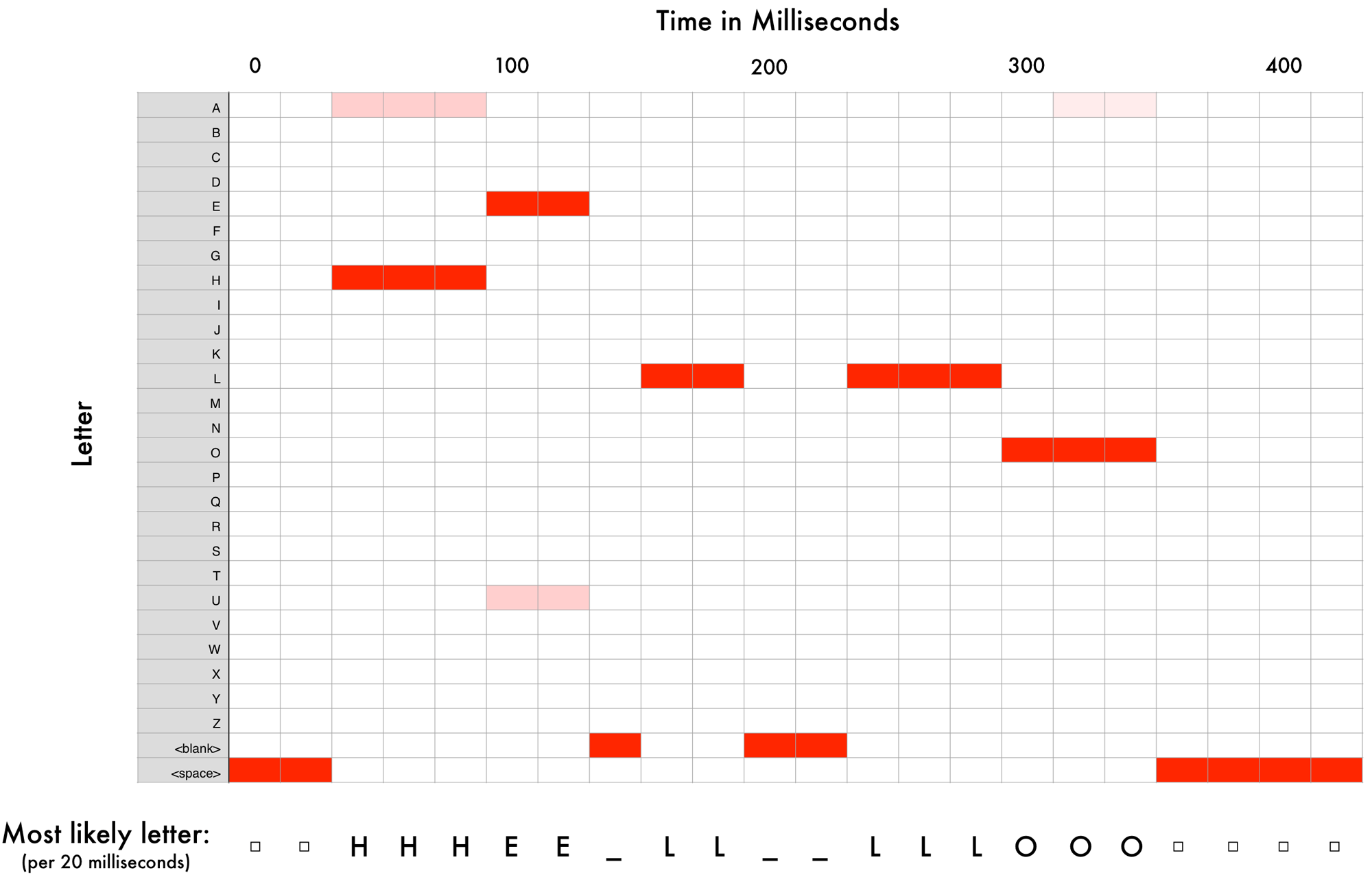
ニューラルネットワークは私が"HHHEE_LL_LLLOOO"と言ったと予測しました。また他にも、"HHHUU_LL_LLLOOO"や"AAAUU_LL_LLLOOO"もあり得ると考えました。
結果をきれいにするために幾つかのステップを踏みます。まず、繰り返している文字を一つにまとめます。
- HHHEE_LL_LLLOOO は HE_L_LO
- HHHUU_LL_LLLOOO は HU_L_LO
- AAAUU_LL_LLLOOO は AU_L_LO
そして空白を除きます。
- HE_L_LO は HELLO
- HU_L_LO は HULLO
- AU_L_LO は AULLO
これで3つの書き起こし候補になりました。もしこの3つを大声で発音したら、どれも"Hello"と似たようになるでしょう。さてこのニューラルネットワークは一文字ずつ予測するので、結果的に一文字ずつ発音したときのような書き起こしになってしまいます。例えば“He would not go”は“He wud net go”になってもおかしくありません。
解決策は、この発音ベースの予測に、書き言葉(本やニュース記事など)の大規模データベースを元にした尤もらしさのスコアを組み合わせることです。あり得ない書き起こしを捨て、最もありえるものだけを残します。
予測候補の“Hello”、“Hullo”、“Aullo”からは、明らかに“Hello”がデータベースのテキスト(言うまでもなく元の音声ベースの教師データ)で最も頻度が高く現れるでしょう。そしておそらく正しいでしょう。そして、最終的に"Hello"を書き起こしとして選ぶことになります。できました!
ちょっと待って!
「でも誰かが本当に"Hullo"と正しく言ったとしたら、"Hello"は間違った書き起こしになるのでは?」
もちろん本当に"Hello"ではなく"Hullo"といった可能性はあるでしょう。今回のような音声認識システムは、"Hullo"と書き起こすことはありません。"Hello"に比べて有り得そうにない発音を聞かせても、いくら'U'を強調したとしても"Hello"と認識するでしょう。
すぐ試せます。お使いのスマホの言語をAmerican Englishにセットして、デジタルアシスタントに"Hullo"と認識させようとして下さい。出来ないでしょう。常に"Hello"と認識されるはずです。
"Hullo"と認識しないのは妥当な振る舞いですが、時々実際に正しく話しているのに認識されなくてイライラする事があるでしょう。だから音声認識モデルはいつもそういう特別な場合を修正するために再学習が必要になります。
自分で音声認識システムを作れる?
機械学習のいいところの一つは、ときどきとてもシンプルに見えることです。たくさんデータを用意して、機械学習アルゴリズムに与えたら、なんと世界クラスのAIシステムがゲーミングラップトップのビデオカードに出来上がり…?
幾つかできることもあるでしょう、音声以外は。音声認識は難しい課題です。ほとんど無制限の問題を乗り越える必要があります: 品質の悪いマイク、背景雑音、残響やエコー、アクセントの違い、などなど。これら全てのケースを全て含んだ学習データを用意しなければ、ニューラルネットワークは対応できません。
他にも例があります: うるさい部屋で話す時、負けないよう無意識に声の音程が少し上がります。人間には問題ないのですが、ニューラルネットワークはこの特別な例を扱うために学習する必要があります。つまりノイズの中で人々が叫ぶデータを学習させる必要があるということです!
Siri、Google Now!、Alexaレベルの音声認識システムを作るとしたら、何百人モノ人を雇わずに出来ることを遥かに上回るデータが必要になります。そしてできの悪い音声認識システムにユーザーは寛容ではないので、ここは疎かにできないのです。誰も80%しか認識しないシステムなど要りません。
GoogleやAmazonのような企業にとって、何百何千時間の実生活空間で録音された会話音声は金に等しいのです。これが世界クラスの音声認識システムとあなたのホビーシステムを隔てる唯一最も大きな障害です。Google Now!やSiriを無料で全ての携帯電話に搭載したり、$50のAlexaが契約料なしに使えるのも、出来るだ使ってほしいという、全てはそこにあります。あなたのどんな一言も永遠に録音され、将来の音声認識システムの学習データとして使われるのです。これがゲームの全容です!
信じられませんか? Android端末をお持ちでGoogle Now!をお使いなら、ここをクリックしてあなたが話しかけたこと全てが実際に録音されているのを聞いてみることです。
ですからもし起業しようとお考えの場合、Googleと競合するような音声認識システムを作るのはお勧めしません。代わりに、ユーザーが何時間も自分で音声を録音してくれるような方法を考え出すことです。そうすればデータがあなたの製品になるでしょう。
もっと知りたい
- 可変長の音声を扱うためのここで紹介したアルゴリズムはConnectionist Temporal Classification略してCTCです。2006年の論文はこちらです。
- BaiduのAdam Coatesがディープラーニングでの音声認識についてとても良いプレゼンをベイエリアのディープラーニングスクールで行っています。YouTubeで見ることが出来ます(3:51:00付近から)。非常にお薦めです。
〜〜
以上気に入ったら、著者Adam Geitgeyさんの
- Machine Learning is Fun! メールリストに登録してみて下さい。
- Twitter は @ageitgey
- メールやLinkedinでも連絡してみて下さい!