検索サービスのオートコンプリートって便利だけど自前で作るのはなにかと大変。そんな時に便利なのがAzure Searchの Suggestions だ。これについて日本語のよいドキュメントが見当たらなかったのでポイントを解説する。 概要レベルの内容は ここを参考にしていただきたい。
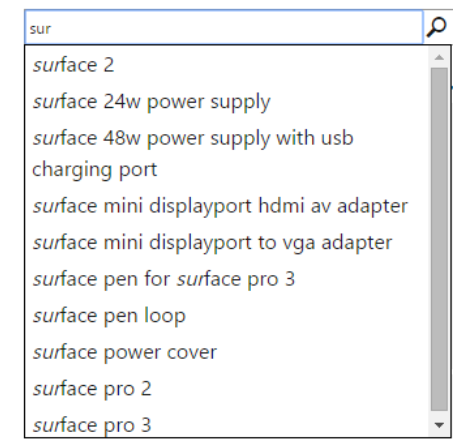
今回はAzure Blob Storage にPDF、DOCX等、様々なドキュメントを放り込んでインデックスを作成した。やり方はこちら。
下記画面の通りインデックスの作成は定期的に実行できる。またデータの削除をインデックスに反映させるためにはTrack deletionsのチェックが必要だ。なお、執筆時点(2017/10/5)ではAdvanced optionsの設定が動かなかった(開いてボタンを押すだけでインデックスが作成されなくなってしまった)ので開発チームにフィードバックしておいた。試していないがおそらくAPI経由であれば設定できるのではないかと思う。
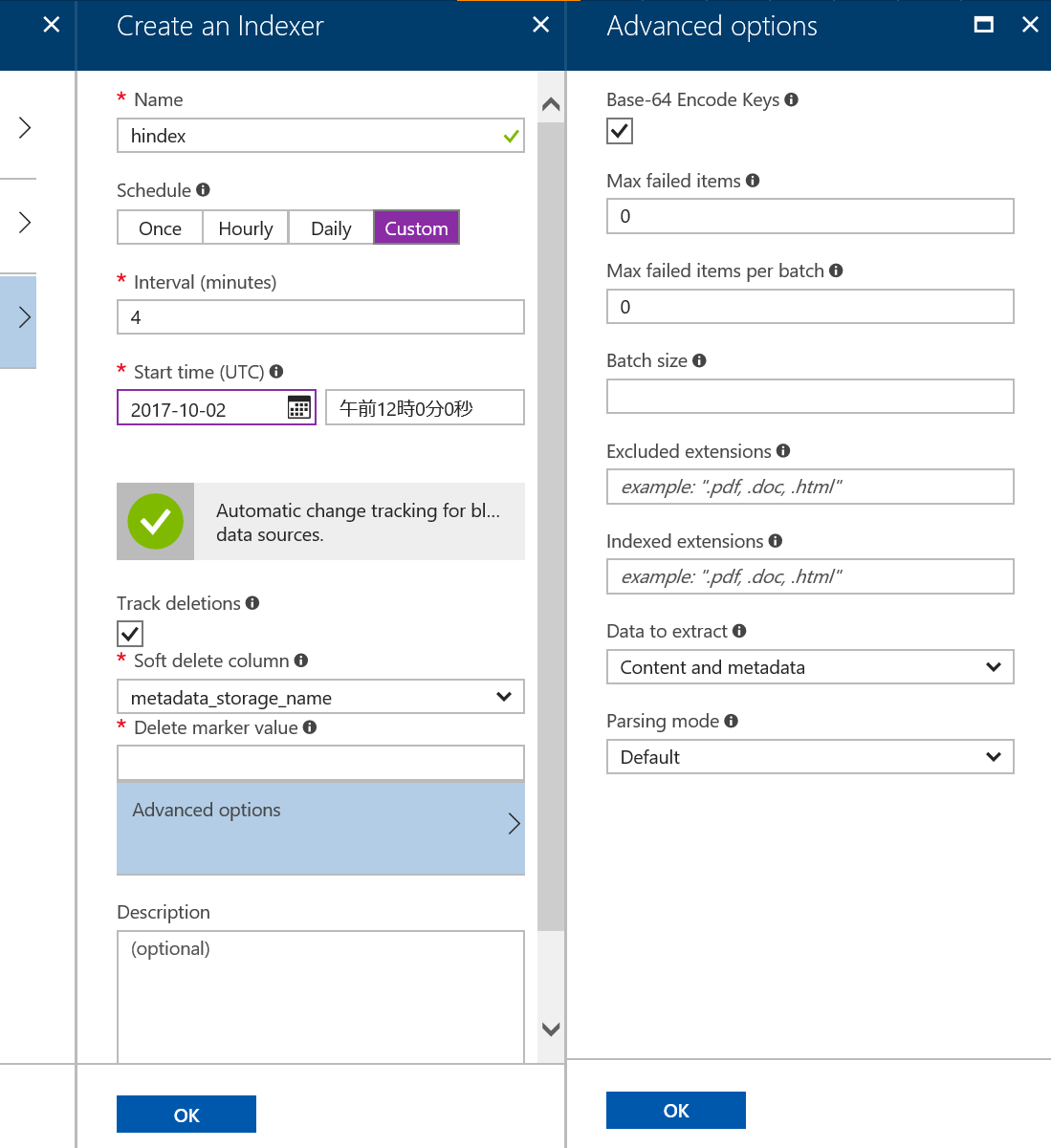
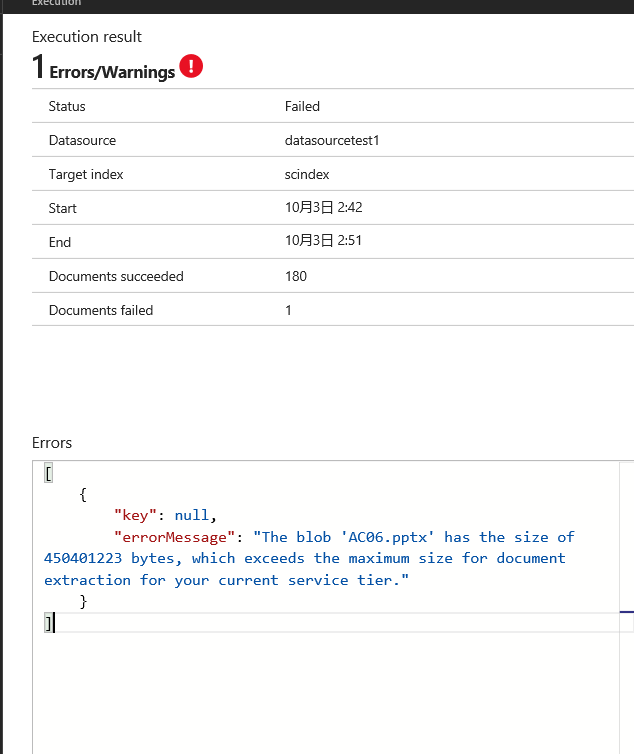
ちなみにAdvanced optionsを指定すればエラーを無視することができる。例えば今回は比較的大きなサイズのドキュメントを対象にしているのだが、以下のようなエラーが発生してしまった。エラーを無視できなければこのエラーが発生したタイミングでインデックスの作成が停止してしまう。Azure Search のLimitationについてはこちらに詳しく記載されているので参考にしていただきたい。
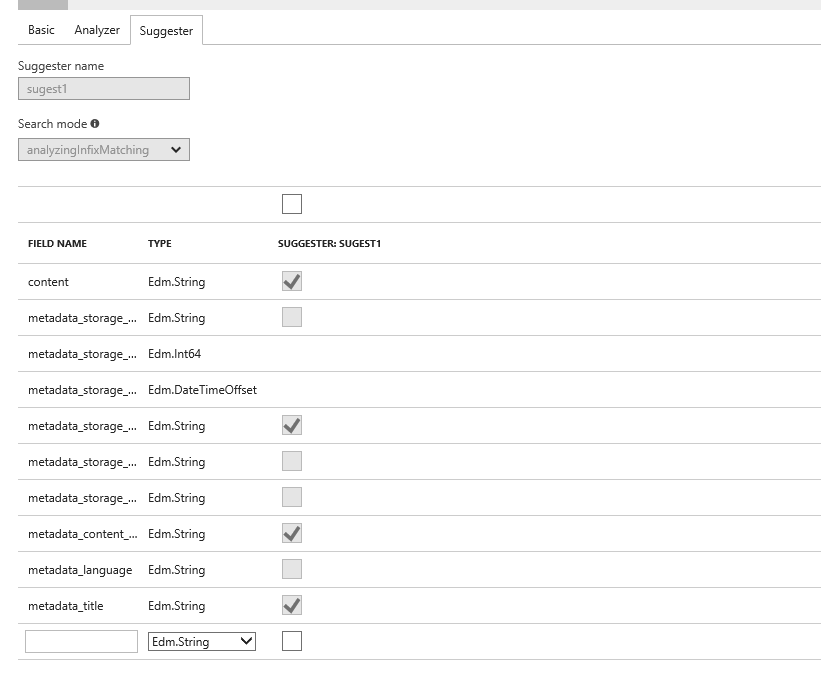
Suggestionsの対象となるフィールドにSEARCHABLEの設定をする。
Azure Search
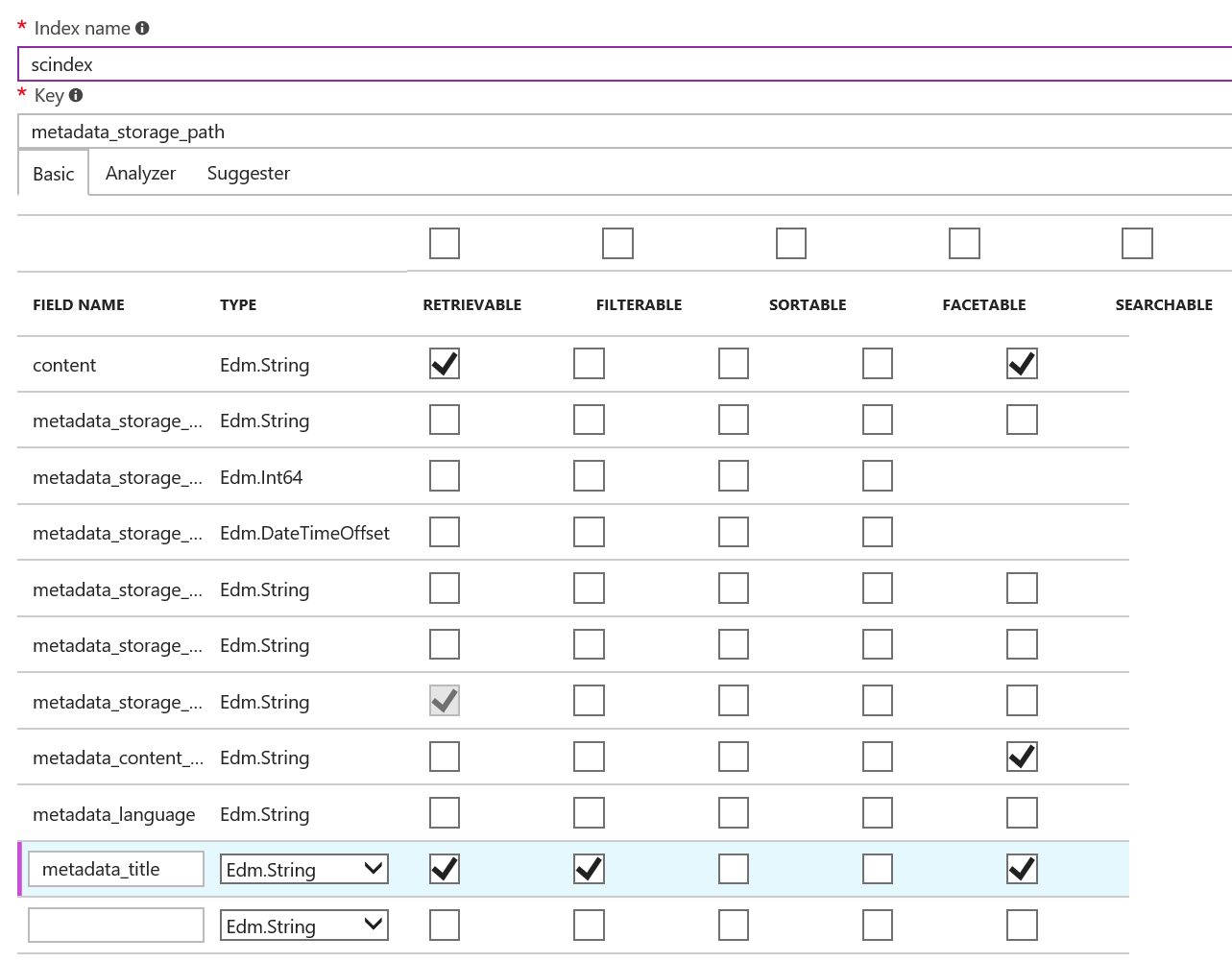
日本語を扱うときに重要なのがAnalyzerの設定だ。デフォルトはStandard LuceneにAnalyzerになっているので日本語検索が必要あればLucene JapaneaseかMicrosoft Japaneaseの設定をおこなう。Luceneには便利なクエリが多いので私はLuceneを選択した。
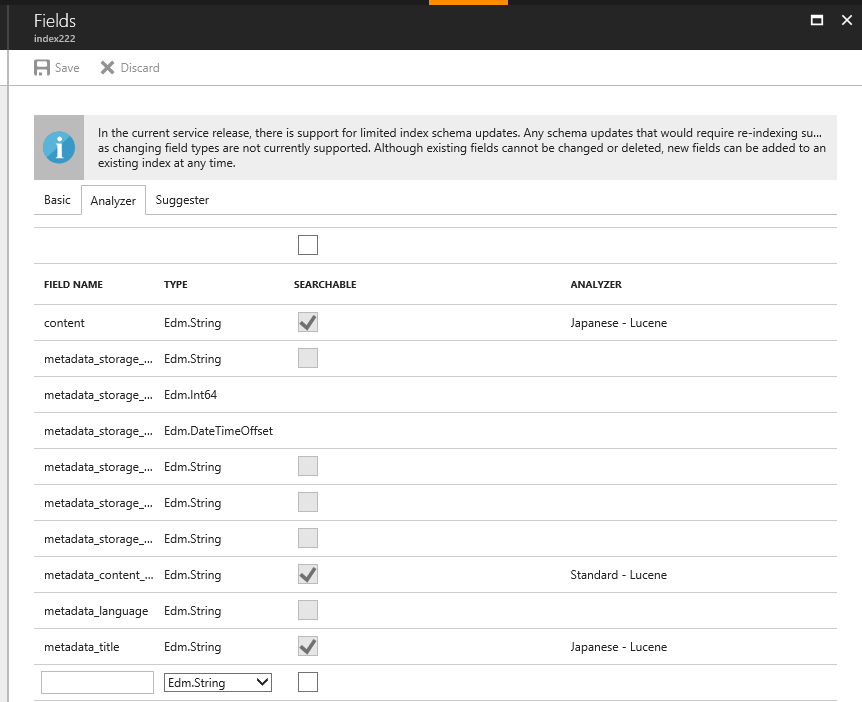
対象のフィールドにSuggesterの設定を行う。
あとはVisual Studioを使ってNuGetでAzure Searchのモジュールをインストールしたうえでコーディングすれば値を取得できるはずだ。
SearchServiceClient serviceClient = new SearchServiceClient(searchServiceName, new SearchCredentials(adminApiKey));
ISearchIndexClient indexClient = serviceClient.Indexes.GetClient(indexName);
DocumentSuggestResult suggestions = indexClient.Documents.Suggest(searchText, suggesterName);
foreach(SuggestResult r in suggestions.Results)
{
Console.WriteLine(r.Text);
}