学習の動機
以前ハッカソンで知り合ったメンターの方に勧めていただきました。
コンピュータの仕組みを一気通貫で学びたいので、学習しました。
GitHub見たらたくさんの人やってて有名なんだなあと
この本で学ぶトピック
- ハードウェア
- アーキテクチャ
- オペレーティングシステム
- プログラミング言語
- コンパイラ
- データ構造とアルゴリズム
- ソフトウェアエンジニアリング
1章 ブール論理
-
すべてのデジタル機器は論理ゲート(logic gate)で構成されており、その論理ゲートの振舞い、インターフェイスは基本的にすべて同じ。
-
本章は最も単純な論理ゲートのひとつであるNANDから始め、その他の論理ゲートをNANDから作成する。
論理回路参考資料/神戸女学院 -
真理値表・正規表現により、すべてのブール代数がNANDにより作成可能である。
-
HDL(Hardware Description Language)を用いて回路アーキテクチャを設計、最適化する。
このテストはハードウェアシミュレーターを用いる。
基礎論理ゲート作成の方法
- 前提知識:ドモルガンの法則、NAND = not(A*B)
- NOT = not(A) = not(A * A)
- AND = (A * B) = not(not(A * B))
- OR = (A + B) = notA * notB = not(notA * notB) = not(not(A * A) * not(B * B))
- XAND
| A | B | out |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
∴(A * B) + (notA * notB) = 以下略
- NORも同様
- Mux(マルチプレクサ) ...
select値に基づいた値を返す (例: sel=0 なら aの値, sel=1 なら bの値)
| A | 0 | 0 | 1 | 1 | |
|---|---|---|---|---|---|
| B | 0 | 1 | 1 | 0 | |
| S=0 | 0 | 0 | 1 | 1 | |
| S=2 | 0 | 1 | 1 | 0 |
簡略化すると
| sel | out | |
|---|---|---|
| 0 | a | |
| 1 | b |
∴(notS * A) + (S * B)
- DMux(デマルチプレクサ) ... select値に基づいた変数を出力(Muxの逆)
| sel | a | b | |
|---|---|---|---|
| 0 | in | 0 | |
| 1 | 0 | in |
∴ A = (notS * in) B = (S * in)
暗算せずにしっかり書いて論理式に落とし込もう(自戒)
本章の学習に6時間30分かかりました。
2章 ブール算術
b進数 -> 10進数の一般的な公式は
(x_nx_{n-1}\cdots x_0)_b = \sum_{i=0}^{n} x_ib^i
2進数処理については、基本情報などで勉強済みだから省略
算術論理演算器(Arithmetic Logical Unit,ALU)作成方法
半加算器(half adder) : ふたつのビットの和を求める
入力は2つ。
出力はそのビット出力(Sum)と桁上り(Carry)の2つ
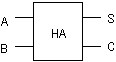
| 入力 | 出力 | |
|---|---|---|
| A, B | C, S | |
| 0, 0 | 0, 0 | |
| 0, 1 | 0, 1 | |
| 1, 0 | 0, 1 | |
| 1, 1 | 1, 0 |
考え方は単純で、
A,Bどちらか一方のみが1 -> Sum++
A,Bどちらも1 -> Carry++
全加算器(full adder) : 3つのビットの和を求める
入力が3つあります。3つ目の入力は、下の桁からの桁上り
出力はそのビット出力(Sum)と桁上り(Carry)の2つ
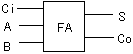
| 入力 | 出力 | |
|---|---|---|
| A, B, C | C, S | |
| 0 0 0 | 0 0 | |
| 0 0 1 | 0 1 | |
| 0 1 0 | 0 1 | |
| 0 1 1 | 1 0 | |
| 1 0 0 | 0 1 | |
| 1 0 1 | 1 0 | |
| 1 1 0 | 1 0 | |
| 1 1 1 | 1 1 |
真理値表よりごり押しすると
\begin{align}
C_{out} &= \bar{A}\cdot B\cdot C_{in}+ {A}\cdot \bar{B}\cdot C_{in}+ {A}\cdot B\cdot \bar{C}_{in}+ {A}\cdot B\cdot C_{in}\\
&= A\cdot B+B\cdot C_{in}+C_{in}\cdot A\\
&=\cdots
\end{align}\\
となるのだが詳しくは 電子回路の組み立てと動作実験【設計編】/京都大学 _20p以降
最終的にはとても綺麗な形になるよ。
加算器(adder) : ふたつのnビットの和を求める
ビット数が増えただけなので、
1桁目は半加算器、それ以降は全加算器を使用
インクリメンタ(incrementer) : 与えられた数字に1を加算
1を加算するだけ。
ちなみにHDLで1を示したい場合以下のようにtrueとする
HalfAdder(a = in[0], b = true, sum = out[0], carry = carry0);
ALU (算術論理演算器): out = f(x,y)を計算
入力されたx, yに対する処理、そして出力outに対する処理をまとめたもの
それぞれの関数仕様に従えばスラスラかけました。
(例: if(zx) x = 0 を実装)
知ったこと
既存(内部)の変数(バス)に対してスライス処理はできないから、以下のように分解して、出力時にスライス処理をする
Mux16(a = AFXY, b = NAFXY, sel = no, out = out, out[0..7] = aout, out[8..15] = bout, out[15] = ng);
//if(out == 0) set zr
Or8Way(in = aout, out = zr1);
Or8Way(in = bout, out = zr2);
本章の学習に2時間30分かかりました。
3章 順序回路
ひとつ以上のDFF回路が、直接または間接的に組み込まれている回路である。
組み合わせ回路とは違い、DFFの時間遅延という特性によって、「データレース」を防止できる。...関連/データレースと競合状態
クロック
コンピュータにおいて、時間経過を表現するもの。
0/1, tick/tockのようなラベル付けをされたオシレーターによって、実装されている。
フリップフロップ
今回使用するD型フリップフロップ(data flip-flop, DFF)は1ビットのデータ入力、1ビットのデータ出力である。クロック入力と合わさることで、「時間に基づく振舞い」が可能。out(t)=in(t-1)

レジスタ
データを"格納","呼び出し"可能な記憶装置である。out(t)=out(t-1)
マルチプレクサへの「選択ビット(select bit)」はレジスタ回路への「読み込みビット(load bit)」の役割を担う。新しい値を保持させたい場合、loadに1を与える。
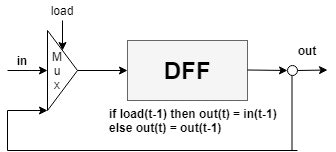
任意の幅(多ビット)レジスタを作成する場合は、1ビットレジスタを必要な数だけ配列上に並べて構築することができる。幅のことを一般的にワード(word)と言う。
メモリ
任意の長さのワードを記憶する媒体
レジスタを積み重ねるとRAM(Random Access Memory)ユニットを構築できる。RAMは「メモリ中すべてのワードに対し、同じ時間で直接アクセスできる」という語源通りの特徴がある。
データ入力、アドレス入力、ロードビットの3入力を受け取る。
RAM設計時にはサイズ(ワードの個数)と幅を指定する必要がある。
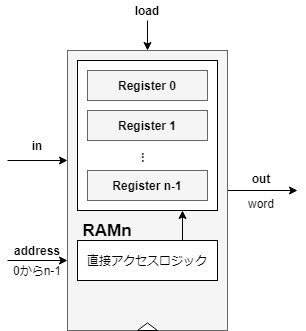
(RAMの図下部に白三角があるが、これは時間に依存することを示す記号。当然DFFやレジスタにも描くべきだが、忘れていた。)
カウンタ
タイムユニットが進むごとに、ある整数の値が加算される。out(t)=out(t-1)+c
CPUにはプログラムカウンタ(program counter)がある。出力は次に実行されるプログラム演算のアドレスとして解釈される。
順序回路作成方法
D型フリップフロップ(DFF)
本書ではDFFを構成要素として扱うため、作成不必要。
NANDゲートだけをベースとするものがあるらしい。
レジスタ(DFFを基礎とする)
1ビットレジスタ = 「ビット」「2値素子(binary cell)」と呼ぶ。
他の機能説明は前文参照
メモリ(レジスタを基礎とする)
- RAM8: メモリを説明する際に載せた図の通り、レジスタを重ねて8WayのMux,DMuxを利用すると完成。
-
nレジスタメモリ: より小さいメモリを利用することにより、実装可能。(RAM64=RAM8*8つ)
RAM64ではaddress[6]となる。[0..2]=RAM8検索用, [3..5]=RAM8内検索用とすれば容易である。 - カウンタ回路(レジスタを基礎とする)
- reset: カウンタを0にするか否か
load: 情報を更新するか否か
inc: インクリメントをするか否か
これら優先順位は上から順番。
参考記事を見て、通したのだが、実のところ完全に理解はできていない。
「1クロック前のデータに対する処理」というものに対して、脳が追い付いていません。
本章の学習に4時間30分かかりました。
4章 機械語
機械
-
メモリ
コンピュータでデータや命令を保存するハードウェアデバイスのこと。
詳しくは前章にて説明済み -
プロセッサ,中央演算装置(CPU-Central Processing Unit)
メモリやレジスタからオペランド(被演算子)を受け取り、算術演算等後に演算結果をメモリやレジスタに格納する。 -
レジスタ
メモリへのアクセスは比較的時間がかかるため、CPUに近い場所にあるレジスタへの高速アクセスを行う。プログラムコマンド数も減らせるため、より高速になる。
言語
機械語のプログラミングはバイナリコードだと
1010001100011001
のようなものだが、ニーモニック(mnemonic)だと、
ADD R3, R1, R9
のように、数字や英単語で表記され、内容の把握がしやすい。
こういった、記号による表記はアセンブリ言語(assembly language)または、アセンブリ(assembly)と呼ばれ、機械語からバイナリへ変換するものはアセンブラ(assembler)と呼ばれる。
コマンド
-
算術演算と論理演算
一般的なシンタックスで書かれた例
ADD R",R1,R3
AND R1,R1,R2 -
メモリアクセス
メモリアクセスを行うコマンドは算術・論理演算の場合か、メモリに対して明示的に読み込み(load),格納(store)を行う場合。以下では後者の中のアドレッシングモード(addressing mode)を紹介する。-
直接アドレッシング(direct addressing)
最も一般的な方法である。直接アドレスを指定、もしくはシンボルを用いて特定のアドレスを参照することによって行う。
LOAD R1,67 //R1 <- Memory[67]
LOAD R1,bar //if(bar==Memory[67]) -
イミディエイトアドレッシング(immediate addressing)
定数を読み込む。命令中の数字領域をアドレスとして扱わず、そのままレジスタに読み込む。
LOADI R1,67 //R1 <- 67 -
間接アドレッシング(indirect addressing)
たとえば
x = foo[j]という高水準コマンドでは、foo[j]という配列のベースアドレス(base adderss)からjだけ離れた要素を参照する。
-
直接アドレッシング(direct addressing)
// x=foo[j] もしくはx=*(foo+j)の変換
ADD R1,foo,j // R1 <- foo+j
LOAD R2,R1 // R2 <- Memory[R1]
STR R2,x //x <- R2
分岐命令
//while loop
while (R1>=0){
code segment 1
}
code segment 2
高水準はC言語などのような記法
//一般的な変換
beginWhile:
JNG R1,endWhile //もしR1<0であればendWhileへ移動
// 「code segment 1」の変換コード
JMP beginWhile //beginWhileへ移動
endWhile:
//「code segment 2」 の変換コード
JMP:無条件分岐, JNG:条件分岐
プログラム作成方法
- 乗算プログラム
基本的には躓かなかったが、デクリメントをする際以下のようにする。
Mはメモリ指定例) sample[M]であり、数値を入力する場合はA or 数値。
@1 //R1--
D=M
@R1
M=M-D
@R1 //R1--
M=M-1
塗りつぶし作業をループさせておき、ボタンが押された場合のみ黒色を設定
無限ループで塗りつぶしを行う場合、上から順番に塗るマスをインクリメントする。
本章の学習に2時間40分かかりました。
5章 コンピュータアーキテクチャ
作成方法
メモリ
アドレスによって、操作対象を変える。
~1638 (0x4000) :RAM
~24575(0x5FFF) :Screen
=24576 (0x6000):Keyboard
それぞれアドレスを2進数表記に変換すると以下のことが分かる。
- RAMのアドレスでは
address[14]が必ず0となる。 - Screenのアドレスは
address[13]が必ず0となる。 - Keyboardのアドレスは
address[13]が必ず1となる。
よって、以上で出力に関する場合分けを行う
3つの関数あるがloadという引数は共通している。例えばScreenを変更する際にRAMの内容が書き換わる恐れがある。よって、それぞれloadを独立させる必要がある。
CPU
CPU実装において、Hack命令を実行することができる制御回路が本書で用意されていた。
- Aレジスターに格納する条件(すべて満たす必要なし)
- A命令である = 16ビットの実行命令[15]が0
- C命令で 16ビット実行命令[5] = dビットコードの1番目が1
- Dレジスターに格納する条件(すべて満たす必要あり)
- C命令である = 16ビットの実行命令[15]が1
- C命令で 16ビット実行命令[4] = dビットコードの2番目が1
ALUはこの機械用に作られていたので、ピンを合わせるだけでした。
Computer
CPU, ROM32K, Memoryを指定されたとおりにピンを合わせれば完成するだけです。
本章の学習に6時間かかりました。
6章 アセンブラ
ここから本書の後半。
前半はハードウェアだったが、後半はソフトウェアらしいです。
コメントアウトで感想みたいなの書いてます。少しだけ。
constructorというのを__init__だと認識するまで1時間はかかったんじゃないかなあ。。。
クラスを作るという概念に気づくのも少し時間かかりました。
しばらくこういうコード書いてなかったので、
基本的なコードも思い出せなかったので結構
「Python 文字列 置き換え」 みたいに検索してました。
input("plz_input:", filename)
みたいに変なこともしてました。Pythonなのにね。
シンボル
アセンブリの世界ではLOAD, R3, 7, GOTO, 250というコマンドの代わりに、シンボルを用いてLOAD, R3, weight, GOTO, LOOPと表記することができる。しかしLOOPが何を示すかが設定されている必要がある。
設定方法
-
変数
変換器が自動で設定するため、実際のメモリアドレスを気にしなくてよい。 -
ラベル
LOOPなどのラベルを用いて、コード領域の最初を設定可能。
/*1+2+3+...+100*/
i = 1
sum = 0
LOOP:
if i = 101 goto END
sum = sum + i
goto LOOP
END:
goto END //コンピュータを無限ループさせ実行終了させる
| シンボル名 | アドレス名 |
|---|---|
| i | 1024 |
| sum | 1025 |
| LOOP | 2 |
| END | 6 |
これらを、シンボルを含まないコードへと変換するには
M[1024] = 1
M[1025] = 0
if M[1024] = 101 goto 6
M[1025] = M[1025] + M[1024]
M[1024] = M[1024] + 1
goto 2
goto 6
この方法は以下を注意しなければならない
- プログラムコード最大1024個までしか格納できない
- ソースコマンド, 変数のメモリ領域をすべて1ワードによって表現してしまう。変換器の場合も変数のワード幅を考慮した設計をする必要がある。
アセンブラ
機械語仕様を参考にして以下の処理を行うプログラムを書く
- アセンブリコマンドを構文解析し、基本となる領域へと分割
- 各領域において、対応する機械語のビットを生成
- (必要なら)シンボルによる参照を数字によるメモリアドレスに置き換える
- 領域ごとのバイナリコードを組み合わせる
本章の学習に11時間30分かかりました。
参考
全体的に参考にしました。クソ雑魚エンジニアのメモ帳/もりっちょ
ALU作成で参考にしました。ひとりNand2Tetris/Hiraku
PC(カウンタ)を作成する際に参考にしました。ひとりNand2Tetris/Hiraku