Faker2.0 を使用したダミーデータの作り方
Fakerとは
Flaker is a Snowflake External Functions wrapper for the popular Faker python library. It means you can generate a vast array of fake data right from within Snowflake, in large quantities, very quickly and easily.
-
ダミーデータが簡単に作成できる pythonライブラリ
-
SnowflakeがPythonをネイティブサポートしたため, これまで以上に簡単にダミーデータを使用できるようになった模様
-
今回はサンプルにあるSQLをリリースし確認する
-
他のデータソースは公式ドキュメントを参照のこと
使用方法
1. 以下のクエリを実行する
--関数の作成
create or replace function FAKE(locale varchar,provider varchar,parameters variant)
returns variant
language python
-- キャッシュに残らないようにする
volatile
runtime_version = '3.8'
-- Anacondaパッケージ
packages = ('faker','simplejson')
-- Fake関数を呼び出す
handler = 'fake'
as
$$
import simplejson as json
from faker import Faker
def fake(locale,provider,parameters):
if type(parameters).__name__=='sqlNullWrapper':
parameters = {}
fake = Faker(locale=locale)
# 型があいまいの場合は文字型で統一する
return json.loads(json.dumps(fake.format(formatter=provider,**parameters), default=str))
$$
;
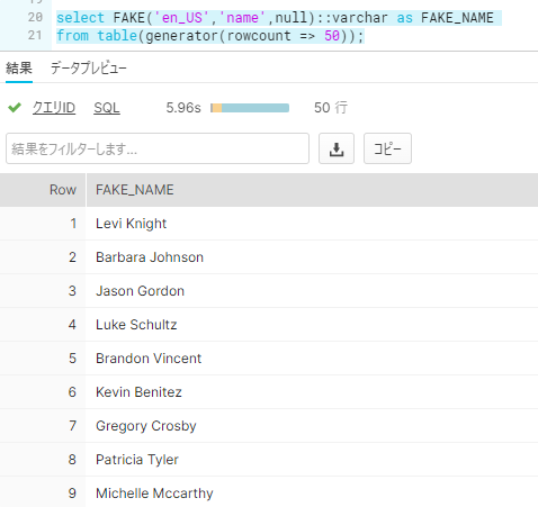
2. ダミーデータを出力する
- 50人のダミー個人名
select
FAKE('en_US','name',null)::varchar as FAKE_NAME
from
table(generator(rowcount => 50));
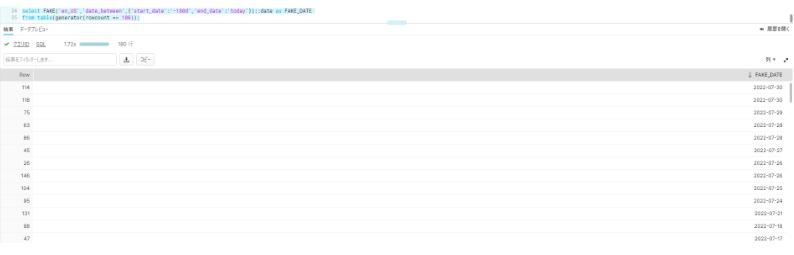
- 今日から180日前までの180個のダミー日にち
select
FAKE('en_US','date_between',{'start_date':'-180d','end_date':'today'})::date as FAKE_DATE
from
table(generator(rowcount => 180));
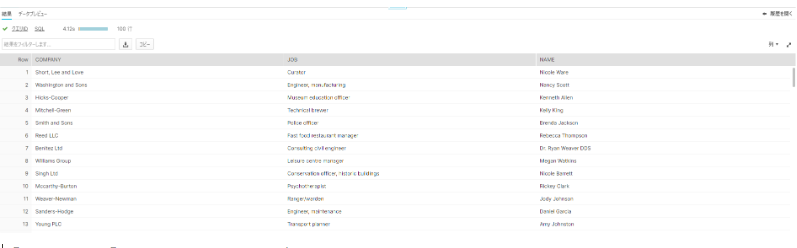
- 100人分の企業、職種、名前のダミーデータ
with FAKE_PROFILES as (
select
FAKE('en_AU','profile',{'fields':'name,job,company'}) as FAKE_PROFILE
from
table(generator(rowcount => 100))
)
select
FAKE_PROFILE:company::varchar as company,
FAKE_PROFILE:job::varchar as job,
FAKE_PROFILE:name::varchar as name
from
FAKE_PROFILES;