はじめに
こんにちは、Daishiroです。前回の記事、
では、Widnows11にDockerを入れて、Difyを使えるようにするまでの手順を書きました。簡単でしたね!これで手元のPCで自由にDifyを使えるようになりましたが、OpenAIやClaudeのAPIキーを使用すると、費用がどんどんかさんでいきます(使った分だけ費用がかかるので当然です)。
超大きいなデータや、長いワークフローでも、費用を気にせずLLMを使えたらとても便利です。あれやこれや、生成AIで自動化することができますね。ということで、ここでは前回の環境から、ローカルのLM Studioを使う環境構築手順を書いてみます。
前提条件
- 前回までの手順で、Windows+Docker、の環境に加え
- LM Studioも、併せてインストール
している環境を用意してください。デフォルトインストールして、好きなモデルが動作するようにしておきましょう。ちなみに、LM Studioはここから手に入ります。
1. ローカルLLMのサーバーを起動
早速、LM Studioのサーバーを起動しましょう。左メニューのLocal Serverをクリックし、画面上部でモデルを選択し(今回は、ELYZAを設定しました)、「Start Server」ボタンを押下します。うまくいくと、以下の画面のように、ローカルの1234ポートで待ち受けるサーバーが起動します。
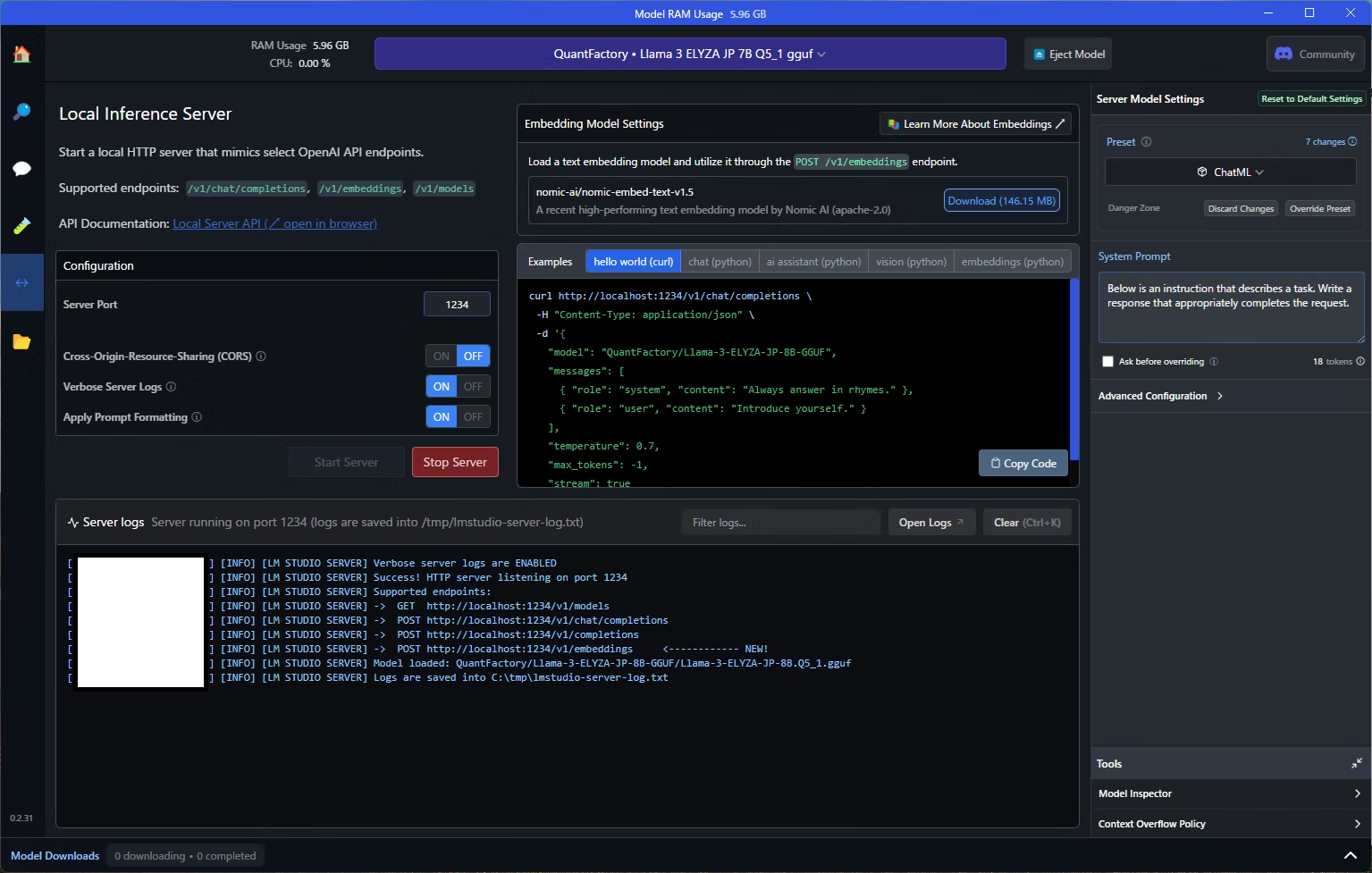
画面下のServer logsに http://localhost:1234/v1/~ の形式でエンドポイントが提示されていますね。これでOKです。
ついでに、DockerからLM StudioにアクセスするためのIPアドレスも調べておきましょう。Windowsのコマンドプロンプトでipconfigを実行します。
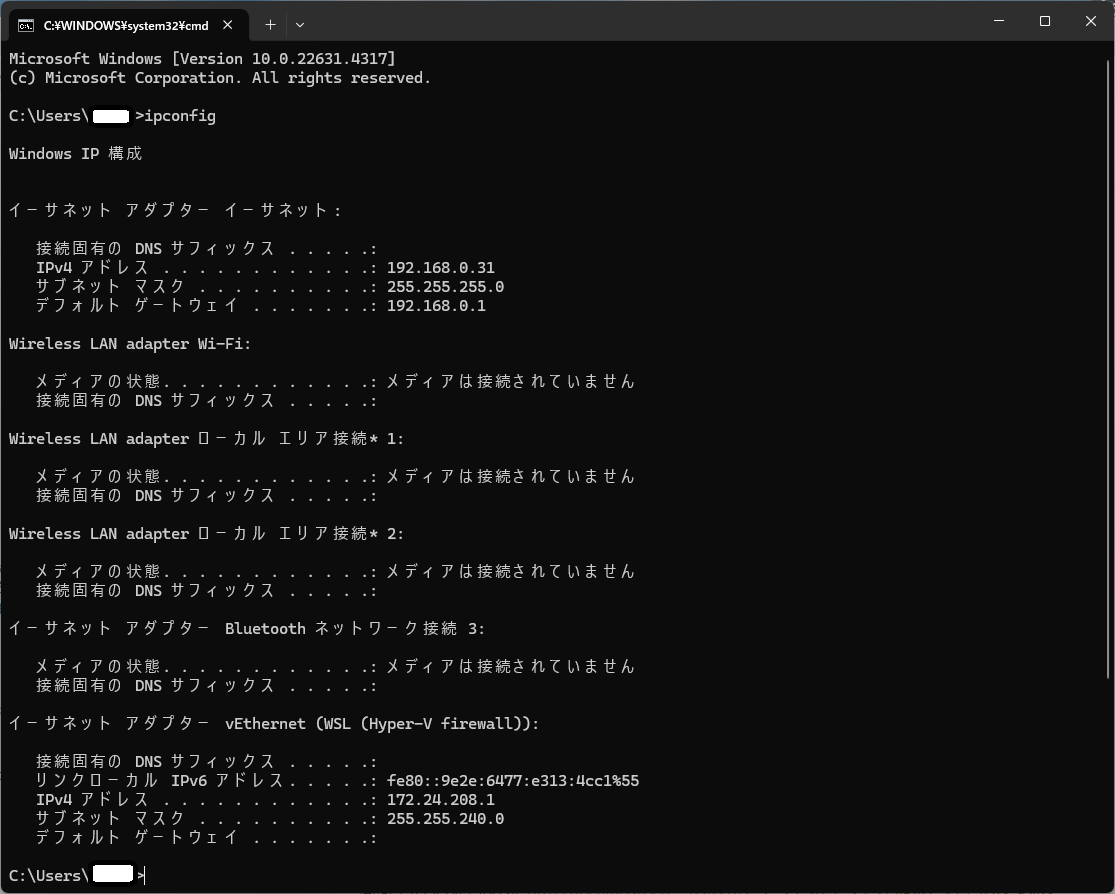
最後の方のネットワークアダプタに、172.24.208.1が見つかりますね。これが大切です。DockerからLM Studioにアクセスするためのネットワークを踏まえてのエンドポイントは、
となります。(大切なので、メモ)
2. DifyにロカールLLMを登録
設定>モデル>モデルプロバイダー、の中にあるOpen-AI-compatibleを選択して設定しましょう。ここにありますね。

クリックをして、先ほどメモったエンドポイントを入れておきましょう。

これで保存ボタンを押して登録が出来れば完了です。おめでとうございます。
ちなみに、保存の際には、LM Studioに以下のログが出ています。ちゃんと接続ができているようです。
[xxxx-xx-xx xx:xx:xx.xxx] [INFO] [LM STUDIO SERVER] Processing queued request...
[xxxx-xx-xx xx:xx:xx.xxx] [INFO] Received POST request to /v1/chat/completions with body: {
"model": "LM Studio",
"max_tokens": 5,
"messages": [
{
"role": "user",
"content": "ping"
}
]
}
[xxxx-xx-xx xx:xx:xx.xxx] [INFO] [LM STUDIO SERVER] Context Overflow Policy is: Rolling Window
[xxxx-xx-xx xx:xx:xx.xxx] [INFO] [LM STUDIO SERVER] Last message: { role: 'user', content: 'ping' } (total messages = 1)
[xxxx-xx-xx xx:xx:xx.xxx] [INFO] [LM STUDIO SERVER] Accumulating tokens ... (stream = false)
[xxxx-xx-xx xx:xx:xx.xxx] [INFO] [QuantFactory/Llama-3-ELYZA-JP-8B-GGUF/Llama-3-ELYZA-JP-8B.Q5_1.gguf] Accumulated 1 tokens: Hello
[xxxx-xx-xx xx:xx:xx.xxx] [INFO] [QuantFactory/Llama-3-ELYZA-JP-8B-GGUF/Llama-3-ELYZA-JP-8B.Q5_1.gguf] Accumulated 2 tokens: Hello from
[xxxx-xx-xx xx:xx:xx.xxx] [INFO] [QuantFactory/Llama-3-ELYZA-JP-8B-GGUF/Llama-3-ELYZA-JP-8B.Q5_1.gguf] Accumulated 3 tokens: Hello from your
[xxxx-xx-xx xx:xx:xx.xxx] [INFO] [QuantFactory/Llama-3-ELYZA-JP-8B-GGUF/Llama-3-ELYZA-JP-8B.Q5_1.gguf] Accumulated 4 tokens: Hello from your server
[xxxx-xx-xx xx:xx:xx.xxx] [INFO] [LM STUDIO SERVER] [QuantFactory/Llama-3-ELYZA-JP-8B-GGUF/Llama-3-ELYZA-JP-8B.Q5_1.gguf] Generated prediction: {
"id": "chatcmpl-ys2my99r1kjgn601ea8lu",
"object": "chat.completion",
"created": 1729661222,
"model": "QuantFactory/Llama-3-ELYZA-JP-8B-GGUF/Llama-3-ELYZA-JP-8B.Q5_1.gguf",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hello from your server"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 27,
"completion_tokens": 4,
"total_tokens": 31
}
}
3.動作確認
さて、無事設定できましたので、動作確認をしてみましょう。
「こんにちは!元気してる!?」
って問いかけたら、元気よく自己紹介をして、会話をする簡単なワークフローを作りました。以下です。

そして、まさかの、1回目で正常動作。Dify素晴らしいですね!以下の回答が見当たります。
「わーーーい!こんにちは!元気100%です!ELYZAと申します。私は大型の言語モデルで、膨大な知識を持っています!自然言語処理や生成AIの技術を活用して、ユーザーの質問に答えたり、会話したりすることができます。友達のようにお話しできるので、是非仲良くしましょう!」
元気いいじゃーん!合格!
おまけ
LM Studio側のログにはこんな風に出力されています。
まとめ
Widnows11にDockerを入れて、Difyを使えるようにするまでの手順でした。これでいくらでも生成AIを回し放題ですね!人の役に立てる価値あるものを!これからもいろいろとDify周りを探っていきたく思います!