CRF再入門(推論編)
introduction
系列ラベリングといえば、最近はLSTMやTransformerがすぐに選択肢に上がりますが、
しかし、CRFもまだまだ使える場面があります。
例えばNamed-Entity-Recognitionでは
BERTにstate-of-the-artは譲ったものの、
ELMoなどでLSTMと組み合わせることで高い性能を実現しています。
実装例ではみんな大好き形態素解析ライブラリのMeCabにも使われています。
そんなCRFを今更ながら改めて入門してみます。
今回は推論のみを扱います。
問題設定
-
系列ラベリングの推論
ある系列に対しもっともらしいラベル列を見つける -
CRFでは以下のように問題を変換(ヒューリスティック)
観測された系列全体$X$が一度に与えられた時, 有りうるラベル列のうちもっともらしいものはどれか?
つまり観測された系列Xが与えられた時の条件付き確率が最も高いラベル列Yを見つける最適化問題になります。
数式で表すと以下のようになります。
$$\hat{Y} = \underset{Y}{arg~max}P(Y|X)$$
X = \left[
\begin{array}{rrr}
x_{01} &...& x_{0k} & ... & x_{0K} \\
... \\
x_{t1} &...& x_{tk} & ... & x_{tK} \\
... \\
x_{T1} &...& x_{Tk} & ... & x_{TK}
\end{array}
\right]
$$Y = [y_{1}...y_{t} ... y_{T}]$$
なお何が"Random"な変数かといいますと、観測された系列のことを指します。
CRFの推論は最短経路の探索とみなせる
最もそれらしいラベルの系列を探す問題は、
以下の要素からなる無向グラフから最短パス(スコアが最大となるパス)を探す問題とみなせます。
- ノード
あるラベルの候補と観測された変数xが割り当てられた頂点 - エッジ
あるxに対するラベルから次のxに対するラベルへの遷移 - 経路全体のスコア
$\hat{Y} = \underset{Y}{arg~max}P(Y|X)$
形態素解析の例ですと以下のようなグラフから検索することになります。

[図は文献9より引用]
まず問題となるのはスコアをどう計算するかという点です。
スコアの計算
分類器として表してみる
P(Y|X) はラベルYが系列であることを除くと通常の分類・回帰問題で求めたい確率と形が同じです。
これもしかしてロジスティック回帰やSVMで解けるのでは?
ということでロジスティック回帰で表してみます。
(実はSVMで表すこともできます。その場合は構造化SVMになります。)
$$ P(Y|X) = softmax(W\cdot\phi(X, Y))$$
$\phi$はスコアを計算するための特徴量を抽出する関数です。
通常の分類器だと入力値がそのまま特徴量と呼ばれることが多いので、混乱するかもしれません。
またXだけでなくYも入力としていることに注意が必要です。
合算値で1になるようにして、確率にするためsoftmax関数を適用しています。
softmax(b_{k}) = \frac{\exp(b_{k})}{\sum^{n}_{i=1}exp(b_{i})}
なお、線形回帰ではなくロジスティック回帰を利用しているのは出力値が0以上であることを保証するためです。
よって解くべき最適化問題は
\hat{Y} = \underset{Y}{arg~max}P(Y|X)\\
= \underset{Y}{arg~max}(softmax(W\cdot\phi(X, Y))) \\
= \underset{Y}{arg~max}(W\cdot\phi(X, Y))
と変形できます。
問題点
でもこのままではラベルの組み合わせ分のクラスを持つ分類器となり、計算量が膨大になります
つまり、例えば系列の長さ3、ラベルの種類が5種類なら考慮すべきクラスは以下のように125クラスにもなります。
- クラス1: ラベル1->ラベル1->ラベル1
- クラス2: ラベル1->ラベル2->ラベル1
... - クラス27: ラベル5->ラベル5->ラベル5
系列の長さが大きくなるにつれ、クラス数は指数的に増加していきます。
また、125クラスぐらいならどうにかなるかと思いますが、
それぞれのクラスのサンプル数が均等に得られるとはとても思えないため、
学習が難しくなると想定されます。
さらに、可変長にできない点も系列ラベリングには致命的です。
CRFの仮定
ここで計算量・クラス数を減らすため仮定をします。
-
t点からはスコア算出の特徴量抽出器に以下の値が入力として得られます。
-
系列全体の観測された特徴量
LSTMやHMMと違い、t点以外の観測された変数を利用できるとしている点に注意が必要です。
ある意味その時点から未来の観測量も利用できるとしています。(現実の実装で使うかは別です)
特徴抽出の方法によりますが、推論時に系列全体の値がわかっている必要があるため、
この点はそのままCRFの応用範囲の制約になります。
(例えばリアルタイム異常検知に使いにくいなど。windowごとに適用していけば使えるかもしれませんが。) -
t点でのラベル
当たり前ですが、推論時には仮の値になります。 -
直前のt-1点でのラベル
後ろのラベルには依存せず、直前のラベルにのみ依存します。
なお、直前だけでなくそれより前のラベルも範囲を決めて考慮に入れることがあります。
ケースによっては性能が上がるようですが、計算量やモデルサイズと相談です。
図で表すと以下のようになります。
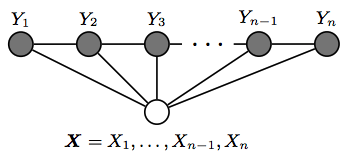
[文献2より引用]例えば$Y_{1}$から$Y_{3}$には依存がないことが分かります。
もちろんこの仮定は自然言語などの現実のデータを考えると、奇妙に思えます。
なぜなら、例えば文章内の単語ならばある単語はだいぶ離れた位置にある単語にも影響を与えているからです。
しかし、うまくいくケースは多いようです(なぜかは調べきれませんでした)。逆にうまくいかないケースはCRFには不向きです。 -
系列全体の観測された特徴量
-
系列全体全体の特徴量とそれぞれの部分で算出した抽出した特徴量の和が同じ
つまりは重みなしで線形で結合できるということです。(重みをつける場合もあります。)
数式で書くと以下のようになります。
$$\phi(X, Y) = \sum_{t}\phi(X, y_{t}, y_{t-1}) $$
この仮定もまた変な感じがします。
現実にこれが無条件で成り立つ(=仮定しなくても成り立つ)特徴量抽出関数$\phi$を設計するのは難しいでしょうし、 あっても性能がいいとはちょっと思えません。
しかし、この仮定もうまくいくようです(これもなぜかは調べきれませんでした)。
この2点を仮定すると、
- ノードごとにラベルを比較するので、ラベルを組み合わせた大量のクラスが必要ない
- 可変長の推論が行える
と先ほどの問題をクリアできます。
仮定を考慮して目的関数を変形すると、
$$
\hat{Y} = \underset{Y}{arg~max}(W\cdot\sum_{t}\phi(X, y_{t}, y_{t-1})) \
= \underset{Y}{arg~max}(\sum_{t}W\cdot\phi(X, y_{t}, y_{t-1}))
$$
となります。
すると線形回帰やDeepLearningのDense Layerでおなじみの
$$W\cdot\phi(X, y_{t}, y_{t-1})$$
という形が得られます。これがそれぞれの時点の線形回帰モデルになります。
(LSTMと同様に、各時点で重み$W$は共有します。)
これが${t-1}$のあるノードから${t}$のあるノードへの移動によって得られるスコア=エッジのスコアに対応します。
スコア計算の高速化
Viterbiアルゴリズム
さてエッジのスコアをどう計算すればいいかはわかりました。
しかしパスのスコアの合算値を現実的な時間で計算するにはまだ少し工夫が要ります。
馬鹿正直にやると、ノードを次の時点に移るたびに最初からパスのスコアを始点しなおし、何度も同じパスの計算をすることになりからです。
そこで動的計画法を利用します。
動的計画法
対象となる問題を複数の部分問題に分割し、部分問題の計算結果を記録しながら解いていく手法です。
以下の2条件を満たします。
- 分割統治法:部分問題を解き、その結果を利用して、問題全体を解く
- メモ化:部分問題の計算結果を再利用する
効率のよいアルゴリズムの設計技法として知られる代表的な構造の一つです。
CRFの推論への適用
CRFへは以下のように適用します。
-
部分問題
あるノードに入力するパスのうちスコアが最大のものを見つけます。
これを終点まで繰り返すと、始点から終点までスコアが最大のパスが見つかります。 -
メモ化
あるノードに入力するパスのうち、合計スコアが最大のエッジとそのスコアを記憶します。
最大のスコアにノードから出力するエッジのスコアを加えることで次のノードに入力するパスのスコアが得られます。
図にすると以下のようになります。
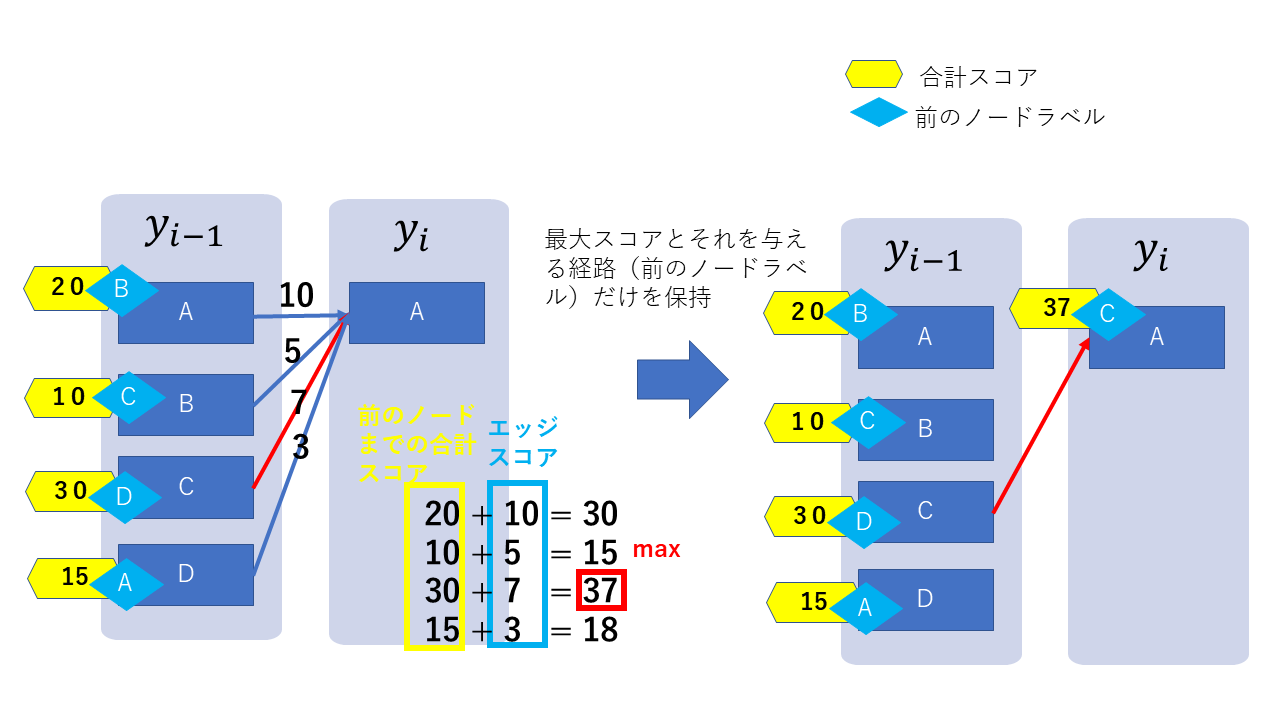
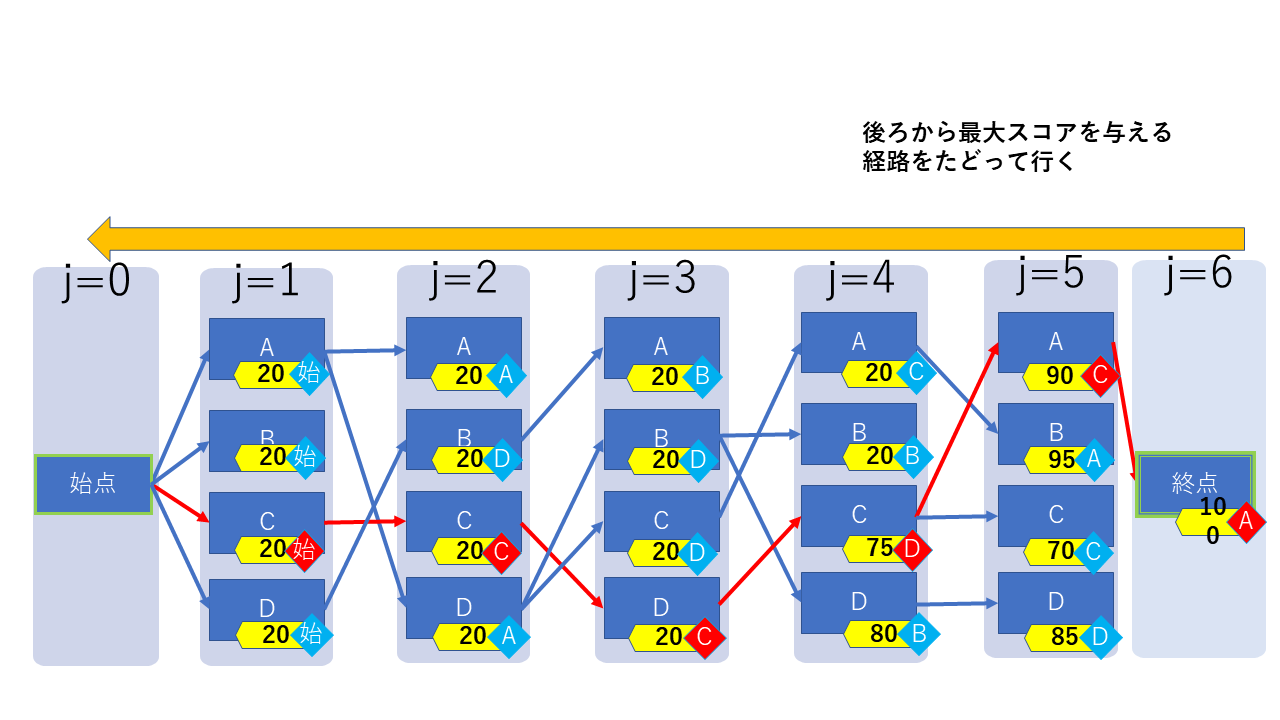
終点まで計算したら、残ったパスを逆にたどることで、最大のスコアを持つパスが得られます。
(赤の線がスコア最大のパス)
beam search
CRFに限った話ではありませんがラベルの種類が多かったり系列の長さが大きいと、
これでも推論に時間がかかることがあります。
ここでbeam searchにより探索範囲を狭めます。
といっても簡単な話で、その時点でのスコアが上位K個のノードから先のパスだけを検索するようにします。

近似的な探索になりますが、K個の大きさをうまく調整すれば実用上は問題ありません。
LSTMとの違い
LSTMとCRFではどちらもノードが状態を持つ点や前の状態を受け取る点が似ています。
しかし例えば以下のような違いがあります。
- LSTMではHidden Stateが分からないが、CRFではラベルとして明示的に与えられる
- LSTMは正解ラベルとの誤差からBackpropagationにより勾配を算出しパラメータを更新する。
つまり、勾配を算出する際の経路は一本道である。
一方、CRFは全てのありうる経路のスコア(条件付き確率)を計算してパラメータを更新する。 - LSTMのcellはある程度決まった内部構造になっているが、
CRFの場合ノードの入力から特徴をどうとるかはタスクによって変える。
もしかしたらCRFもHMMのように色々制約を加えたDeep Learningと解釈できるのかもしれませんが・・・
だれかいい文献教えてください。
まとめ
CRFの推論を改めて振り返ってみました。
実は推論だけでも触れられていないトピックがまだまだあります。
例えば形態素解析のようにパスによって通るノードの数が違う場合、
ノードが多いパスがどうしてもスコアが高くなりがちなのでスコアに工夫がいります。
また、具体的にスコアにどのような特徴量を使うのかの例も示せていません。
いずれ追記できればと思います。
また、CRFの学習編の記事も近いうちに書ければ(汗)と思います。
参考文献
- Collins, M. (n.d.). Log-Linear Models, MEMMs, and CRFs. Retrieved from http://www.cs.columbia.edu/~mcollins/crf.pdf
- Wallach, H. M. (2004). Conditional Random Fields: An Introduction * 1 Labeling Sequential Data. Retrieved from http://dirichlet.net/pdf/wallach04conditional.pdf
- 言語処理のための機械学習入門 (自然言語処理シリーズ) 高村 大也 (著), 奥村 学 (2010/7/1)
- Cookpad 開発者ブログ 日本語形態素解析の裏側を覗く!MeCab はどのように形態素解析しているか
- Pattern Recognition and Machine Learning Christopher Bishop (著), Springer(2010/2/15)
- 自然言語処理 (放送大学教材) 黒橋 禎夫 (著),放送大学教育振興会 (2015/03)
- 日本語入力を支える技術 ~変わり続けるコンピュータと言葉の世界 徳永 拓之 (著),技術評論社 (2012/2/8)
- Beam Search - YouTube by Udacity
- 授業資料/形態素解析 - OGI-Wiki
- Is Conditional Random Field a type of Recurrent Neural Network? - Quora
- 条件付き確率場(Linear Chain CRF)を導出してみた - Qiita (偉大なるQiitaにおけるCRFの前駆者様)