概要
- Apache Camelを使うと簡単にDBアクセスできる
- Apache Camelのループ文の書き方が特殊なので見ていく。
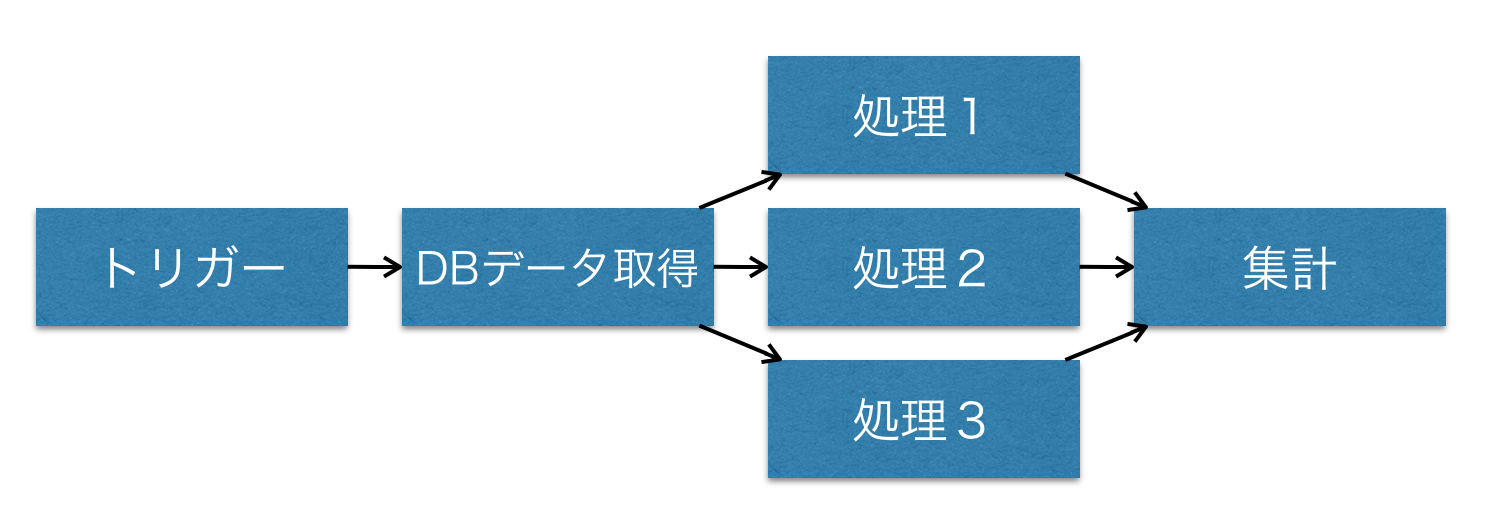
- 処理1,処理2、処理3はHTTP処理などの時間がかかる実装と想定して非同期で処理する。
- ついでにHTTPで投げるデータをjsonにしとく
- 非同期処理にタイムアウトをしかける
Hello world
簡単な実装から
package hellodb.route;
import org.apache.camel.builder.RouteBuilder;
import org.springframework.stereotype.Component;
@Component
public class MyRoute1 extends RouteBuilder {
@Override
public void configure() throws Exception {
from("timer:test?period=3s")
.process(exchange -> {
System.out.println("Hello World");
});
}
}
- 3秒ごとにHello Worldが出力される。
以上
次の目標
- DBアクセスする
- SELECTできた件数を標準出力する

これをCamelを使って実装すると、下記のようになるわけ。
(これだけでは動作せず設定は必要なので今までの投稿を参考)
package hellodb.route;
import org.apache.camel.builder.RouteBuilder;
import org.apache.camel.component.sql.SqlConstants;
import org.springframework.stereotype.Component;
@Component
public class MyRoute2 extends RouteBuilder {
@Override
public void configure() throws Exception {
from("timer:test?period=3s")
.to("sql:SELECT * FROM sites")
.process(exchange -> {
int count = exchange.getIn().getHeader(SqlConstants.SQL_ROW_COUNT, int.class);
System.out.println("cound:" + count);
});
}
}
以上。
簡単に解説すると、
- timer:test?period=3s で3秒おきに処理が開始され
- sql:SELECT * FROM sitesでDBにSELECTし
- 結果のレコード数がヘッダ
CamelSqlRowCountに格納されるので(http://camel.apache.org/sql-component.html のHeader values) - 実装部分で取り出して標準出力する
というコード
次の目標
- SELECTで取得できたレコードのデータを標準出力する
つまり、通常の実装では何らかのデータをfor文で回す感じ。
package hellodb.route;
import org.apache.camel.builder.RouteBuilder;
import org.springframework.stereotype.Component;
import java.util.List;
import java.util.Map;
@Component
public class MyRoute3 extends RouteBuilder {
@Override
public void configure() throws Exception {
from("timer:test?period=3s")
.to("sql:SELECT * FROM sites")
.process(exchange -> {
List<Map> rows = exchange.getIn().getBody(List.class);
for (Map row : rows ) {
System.out.println("url:" + row.get("url"));
}
});
}
}
以上。
- sql:SELECT * FROM sitesの結果はデフォルトではbody部に入る(http://camel.apache.org/sql-component.html のResult of the query)
- 結果のデータは
List<Map<String, Object>>
もしくは、camelの機能でsplitというものがあるので使ってみる
package hellodb.route;
import org.apache.camel.builder.RouteBuilder;
import org.springframework.stereotype.Component;
import java.util.Map;
@Component
public class MyRoute4 extends RouteBuilder {
@Override
public void configure() throws Exception {
from("timer:test?period=3s")
.to("sql:SELECT * FROM sites")
.split(body())
.process(exchange -> {
Map row = exchange.getIn().getBody(Map.class);
System.out.println("url:" + row.get("url"));
})
.end();
}
}
- splitはListを分解して複数のexchangeを作成機能があるので、分解した内容がexchangeに渡される。
- splitはListの内容だけループする
次の目標
- SELECTで取得できたレコードのデータをマルチスレッドで標準出力する
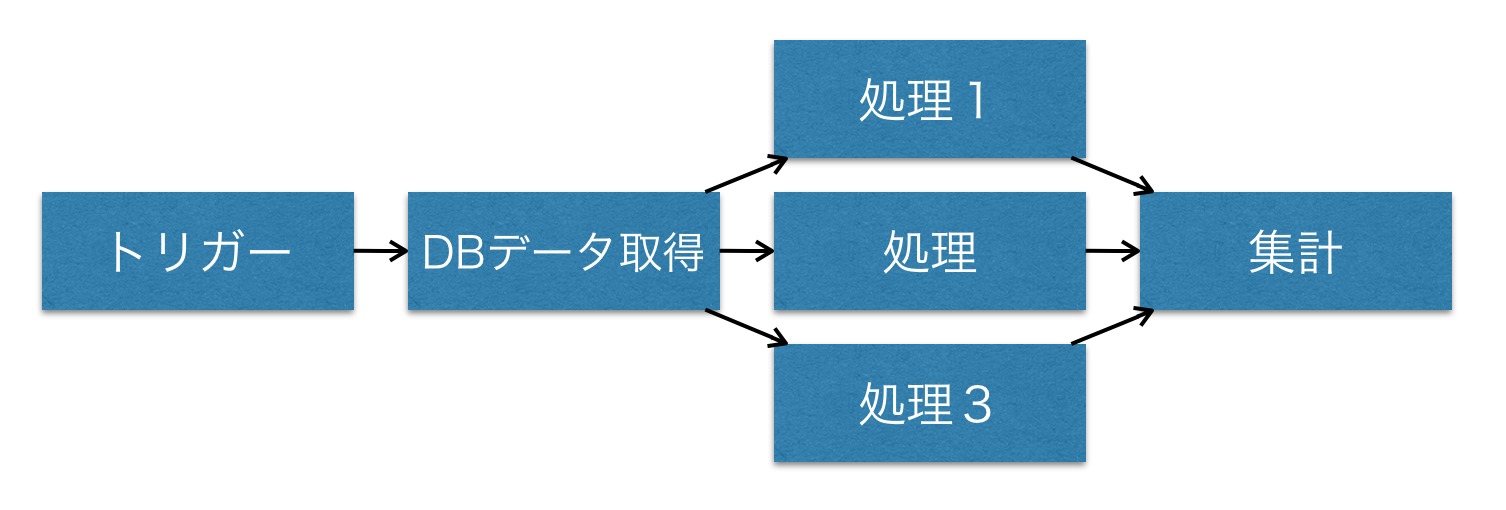
これは簡単で
package hellodb.route;
import org.apache.camel.builder.RouteBuilder;
import org.springframework.stereotype.Component;
import java.util.Map;
@Component
public class MyRoute5 extends RouteBuilder {
@Override
public void configure() throws Exception {
from("timer:test?period=3s")
.to("sql:SELECT * FROM sites")
.split(body()).parallelProcessing()
.process(exchange -> {
Map row = exchange.getIn().getBody(Map.class);
System.out.println("url:" + row.get("url"));
})
.end();
}
}
以上
つまり、parallelProcessing()が付いただけ。
実行してみると、複数のレコードが順番バラバラで出力されていることがわかる。
ついでにhttpで投げるデータをjsonにする(ちょっと寄り道)
- Mapをjsonに変換
- putでhttp送信
- もちろんマルチスレッド
package hellodb.route;
import org.apache.camel.builder.RouteBuilder;
import org.apache.camel.model.dataformat.JsonLibrary;
import org.springframework.stereotype.Component;
@Component
public class MyRoute6 extends RouteBuilder {
@Override
public void configure() throws Exception {
from("timer:test?period=3s")
.to("sql:SELECT * FROM sites")
.split(body()).parallelProcessing()
.marshal().json(JsonLibrary.Jackson)
.to("http://localhost/myservice")
.end();
}
}
httpの結果はbodyに入ってくるので、それを処理。
httpの結果がjson形式だったらhttpの下の行に
.unmarshal().json(JsonLibrary.Jackson)
って書いて、json --> Object にしちゃえばいい。
- marshal().json() は Object --> json
- unmarshal().json() は json --> Object
ログ出力は下記のような感じ
.to("log:http-send")
.to("http://xxxx")
.to("log:http-result")
最後!
最後はちょー面倒くさいことするよ
- マルチスレッドで処理
- マルチスレッドで処理した結果を集計する(今回は文字列を足し込むだけ)
- タイムアウトを設定して、タイムアウトした結果は集計しない
- 集計結果を出力する
package hellodb.route;
import org.apache.camel.builder.RouteBuilder;
import org.springframework.stereotype.Component;
import java.util.Map;
import java.util.Random;
@Component
public class MyRoute7 extends RouteBuilder {
@Override
public void configure() throws Exception {
from("timer:test?period=3s")
.to("sql:SELECT * FROM sites")
.split(body())
// マルチスレッド処理が全部完了したら結果をリストの順番に集計する
// 今回はurlの文字を足し込むだけ
.aggregationStrategy((oldExchange, newExchange) -> {
// 初回の集計は古いデータが無いのでnullになる
if (oldExchange == null) return newExchange;
String oldData = oldExchange.getIn().getBody(String.class);
String newData = newExchange.getIn().getBody(String.class);
String s = oldData + newData;
oldExchange.getIn().setBody(s);
return oldExchange;
})
.parallelProcessing().timeout(2000)
// これ以下はマルチスレッド処理
.process(exchange -> {
// urlだけを取り出してbodyに入れる
Map<String, Object> map = exchange.getIn().getBody(Map.class);
exchange.getIn().setBody(map.get("url"));
// 乱数で処理時間を変える
Thread.sleep(new Random().nextInt(5) * 1000);
})
.end()
// マルチスレッドな処理が全て終わった後の処理はこれ以降
// bodyにはurlの文字列が全て足し込まれた文字列データが入っているはず
.process(exchange -> {
String body = exchange.getIn().getBody(String.class);
System.out.println(body);
})
;
}
}
- aggregationStrategyは処理結果の集計実装を定義
- timeout(ミリ秒)でタイムアウトを指定できる
- なんだか面倒くさそうに見えるけど、「クエリ結果処理実装」「集計実装」「集計結果実装」がバラバラになっていて、別々の人が担当して作ってもいいような疎結合な設計になっている。 (今回のプログラムは簡単なので1ファイル。通常は個々の実装はそうとうデカイはずなので、別々のクラスに分ければいい)