Grad-CAMとは
AI(CNN)がどこを見て判断したかを可視化しようとする(Explainable AI)手法のひとつで、勾配に注目した方法です。
個人的にはちょっと面倒くさそうだな...と触れないようにしてきたのですが、実際はそこまで複雑ではなかった話です。
この記事の目的
・GradCamを簡単に何となく理解する
・Mnistで実装を試みる
・数式はなし
Grad Camの方法
ここでは、クラス分類における方法について説明します。
基本的な分類器は以下の図のように、ワンホットベクトルのを予測しますが、このとき、畳み込み層で2次元の特徴を抽出し、全結合層では得られた画像特徴を分類しています。可視化の際に問題になるのが、全結合層にいれることにより、2次元方向の特徴でなくなることです。各ノードが画像のどこからきているかが、わからなくなってしまいます。
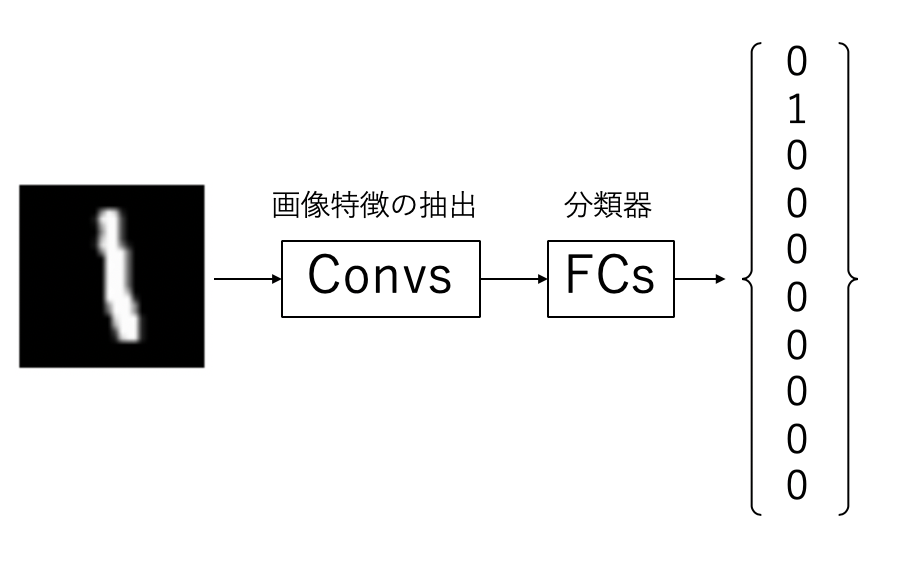
そこで、全結合層を使わなくしたのが、FCN(Fully Convolutional Network)です。これはシンプルに最後まで畳み込み層にすることで全結合層を使わない方法です。FCNを使うと、出力層の直前まで2次元の特徴を保つことができます。
Grad-CAMでは、最終層では画像サイズが(1×1)になるようにプーリングを行います。Global Average poolingと言われたりします。
また最終層ではチャネル数 = クラス数となっている必要があります。
つまり、あるチャネルとあるクラスが1対1で対応させることで、そのクラスがどこを見て判断したのかを明確にしようということです。
さて、正解がワンホットベクトルであることから、正解のチャネルでは画素値の平均が1、それ以外では画素値の平均が0になるように学習されます。
図だとこんな感じです。中間では、0~9なので10クラスあります。

というわけで、上の構造で実装してみました。
結果
全部つくるのは面倒なので4つだけ。


それぞれ、正解ラベルにおける画像において強く反応がでていることがわかります。
また、0の時は6にも少し反応してますね。逆に6の時はあまり0に反応してないです。
あと普通に数字以外のところも結構反応してますね。
「何もそこにはない」という特徴も存在するわけなのでなんとも言えないですね
また精度は...
| Accuracy | 91.34 % |
|---|
うん、(とても)低いです。
これは元々指摘されている問題で、全結合層を畳み込み層に置き換えると単純に精度が落ちます。
感想
・ネットワーク構造めんどくさい
特に、MaxPoolingを何も考えずにやると、CAMの画質が下がっていくので、どうしたもんかなぁと思いながらなんとなく妥協点を探しました。
・この方法ではやはりワンホットエンコードを予測しようとすることから、画像全体が赤くなるようなロス関数となっている気がする。必ずしも数字の部分だけがぼんやりと出る必要がない。もう少し複雑な問題だときちんとでるのかなぁ...。うーん。
・どこかで、Grad-CAMは機械学習でみているところではない的な論文も見た気がするので今回はお試しにしては上出来。