MnistごときLightbgmで十分だ!
と大言をいってみましたが、よくNNなどのチュートリアルで用いられるMNISTデータセットをLightbgmで分類してみたいと思います。
ただ、普通にtrainすると、28×28 = 784次元の特徴量となり多すぎて学習が終わりません(笑)
そこで大体100次元くらいでどんくらい精度がでるか検証してみたいと思います。
0 データロード
面倒なのでpytorch使います。
import torchvision
import numpy as np
trainset = torchvision.datasets.MNIST(root='./data',
train=True,
download=True,)
testset = torchvision.datasets.MNIST(root='./data',
train=False,
download=True)
train_data = []
train_label = []
for i in trainset:
pic = np.array(i[0])
pic[pic >= 1] = 1
train_data.append(pic)
train_label.append(np.array(i[1]))
test_data = []
test_label = []
for i in testset:
pic = np.array(i[0])
pic[pic >= 1] = 1
test_data.append(pic)
test_label.append(np.array(i[1]))
・pytorchでMNISTデータセットのダウンロード
・画像は2値化
・ラベルとデータを分離し、データをPILimageからnumpyに変換
1 全体のうち白の画素数と黒の画素数特徴
適当な特徴量を作り、学習させてみましょう。
モデルは学習時間が短いLightBGM使います。
まず画像のうち、白(0)となっている部分と黒(1)の部分の数を特徴にいれて様子を見ます。
2次元の特徴です。
X_train = []
for i in range(len(train_data)):
x = []
data = train_data[i]
data1 = data.reshape(-1)
x.append(data1[data1 == 0].shape[0])
x.append(data1[data1 > 0].shape[0])
X_train.append(x)
X_test = []
for i in range(len(test_data)):
x = []
data = test_data[i]
data1 = data.reshape(-1)
x.append(data1[data1 == 0].shape[0])
x.append(data1[data1 > 0].shape[0])
X_test.append(x)
import lightgbm as lgb
model = lgb.LGBMClassifier()
model.fit(X_train,train_label)
pred = model.predict(X_test)
from sklearn.metrics import accuracy_score as acc
acc(pred, test_label)
結果
0.254
まぁこんなもんかって感じですね。
10クラスあってrandomで10%くらいなことを考えると意外と25%も出るんですね。
2 各列、行でsumをとる
次に、新しい特徴として各列、行でsumをとってみます。
これにより体感的にはどの辺に黒が多いかがわかる特徴になるかと思いました。
X_train = []
for i in range(len(train_data)):
x = []
data = train_data[i]
data1 = data.reshape(-1)
x.append(data1[data1 == 0].shape[0])
x.append(data1[data1 > 0].shape[0])
x.extend(np.sum(data,axis = 0))
x.extend(np.sum(data,axis = 1))
X_train.append(x)
X_test = []
for i in range(len(test_data)):
x = []
data = test_data[i]
data1 = data.reshape(-1)
x.append(data1[data1 == 0].shape[0])
x.append(data1[data1 > 0].shape[0])
x.extend(np.sum(data,axis = 0))
x.extend(np.sum(data,axis = 1))
X_test.append(x)
import lightgbm as lgb
model = lgb.LGBMClassifier()
model.fit(X_train,train_label)
pred = model.predict(X_test)
from sklearn.metrics import accuracy_score as acc
acc(pred, test_label)
結果
0.9212
おお!58次元で92%まで達成できました!
下手な全結合層くらいには勝つかもしれませんね笑
もうちょっと特徴を追加してみましょう。
3 分割してGridごとの和
画像を4分割し、それぞれのグリッドの和の特徴を足してみましょう。4次元追加して62次元になります。
def fea1(img):
x = []
x += [sum(sum(img[:14,:14]))]
x += [sum(sum(img[14:,:14]))]
x += [sum(sum(img[:14,14:]))]
x += [sum(sum(img[14:,14:]))]
return x
X_train = []
for i in range(len(train_data)):
x = []
data = train_data[i]
x.extend(fea1(data))
data1 = data.reshape(-1)
x.append(data1[data1 == 0].shape[0])
x.append(data1[data1 > 0].shape[0])
x.extend(np.sum(data,axis = 0))
x.extend(np.sum(data,axis = 1))
X_train.append(x)
X_test = []
for i in range(len(test_data)):
x = []
data = test_data[i]
x.extend(fea1(data))
data1 = data.reshape(-1)
x.append(data1[data1 == 0].shape[0])
x.append(data1[data1 > 0].shape[0])
x.extend(np.sum(data,axis = 0))
x.extend(np.sum(data,axis = 1))
X_test.append(x)
import lightgbm as lgb
model = lgb.LGBMClassifier()
model.fit(X_train,train_label)
pred = model.predict(X_test)
from sklearn.metrics import accuracy_score as acc
acc(pred, test_label)
結果
0.9289
少し改善しましたね。
調子に乗って(大体3分割も追加してみましょう)
def fea1(img):
x = []
x += [sum(sum(img[:14,:14]))]
x += [sum(sum(img[14:,:14]))]
x += [sum(sum(img[:14,14:]))]
x += [sum(sum(img[14:,14:]))]
return x
def fea2(img):
x = []
x += [sum(sum(img[:9,:9]))]
x += [sum(sum(img[9:18,:9]))]
x += [sum(sum(img[18:28,:9]))]
x += [sum(sum(img[:9,9:19]))]
x += [sum(sum(img[9:18,9:18]))]
x += [sum(sum(img[18:,9:18]))]
x += [sum(sum(img[:9,18:]))]
x += [sum(sum(img[9:18,18:]))]
x += [sum(sum(img[18:,18:]))]
return x
X_train = []
for i in range(len(train_data)):
x = []
data = train_data[i]
x.extend(fea1(data))
x.extend(fea2(data))
data1 = data.reshape(-1)
x.append(data1[data1 == 0].shape[0])
x.append(data1[data1 > 0].shape[0])
x.extend(np.sum(data,axis = 0))
x.extend(np.sum(data,axis = 1))
X_train.append(x)
X_test = []
for i in range(len(test_data)):
x = []
data = test_data[i]
x.extend(fea1(data))
x.extend(fea2(data))
data1 = data.reshape(-1)
x.append(data1[data1 == 0].shape[0])
x.append(data1[data1 > 0].shape[0])
x.extend(np.sum(data,axis = 0))
x.extend(np.sum(data,axis = 1))
X_test.append(x)
import lightgbm as lgb
model = lgb.LGBMClassifier()
model.fit(X_train,train_label)
pred = model.predict(X_test)
from sklearn.metrics import accuracy_score as acc
acc(pred, test_label)
結果
0.9488
おお!
ここまでくるんですね笑
9次元追加して71次元です。
4 2分割を追加するの忘れていた...
左右のコントラストなどもあると思うので、上下分割で黒の和、左右分割で黒の和をそれぞれ追加します。
コードが長くなってきたので、関数だけ載せます。
def fea3(img):
x = []
x += [sum(sum(img[:,:14]))]
x += [sum(sum(img[:,14:]))]
x += [sum(sum(img[:14,:]))]
x += [sum(sum(img[14:,:]))]
return x
結果
0.9472
性能少し落ちちゃいましたね。
汎化性能が下がってきているのかもしれません。
ここまではパラメーターはデフォルトでやっていたので、少しチューニングしてみました
import lightgbm as lgb
param_grid = {"max_depth": 10,
"learning_rate" : 0.3,
"num_leaves": 100,
}
model = lgb.LGBMClassifier(**param_grid)
model.fit(X_train,train_label)
pred = model.predict(X_test)
from sklearn.metrics import accuracy_score as acc
print(acc(pred, test_label))
結果
0.96
だいぶ上がりました。
5 Confusion Matrixを確認
混同行列の可視化はこのサイトからもらってきました。
import numpy
def error_rate(predictions, labels):
"""Return the error rate and confusions."""
correct = numpy.sum(predictions == labels)
total = predictions.shape[0]
error = 100.0 - (100 * float(correct) / float(total))
confusions = numpy.zeros([10, 10], numpy.int32)
bundled = zip(predictions, labels)
for predicted, actual in bundled:
confusions[int(predicted), int(actual)] += 1
return error, confusions
import matplotlib.pyplot as plt
%matplotlib inline
NUM_LABELS = 10 # change it according to num_class in your dataset
test_error, confusions = error_rate(numpy.asarray(pred), numpy.asarray(test_label))
print('Test error: %.1f%%' % test_error)
plt.figure(figsize = (8,8))
plt.xlabel('Actual')
plt.ylabel('Predicted')
plt.grid(False)
plt.xticks(numpy.arange(NUM_LABELS))
plt.yticks(numpy.arange(NUM_LABELS))
plt.imshow(confusions, cmap=plt.cm.jet, interpolation='nearest');
for i, cas in enumerate(confusions):
for j, count in enumerate(cas):
if count > 0:
xoff = .07 * len(str(count))
plt.text(j-xoff, i+.2, int(count), fontsize=9, color='white')
plt.savefig("confusion_matrix.png")
出力画像はこちらです。
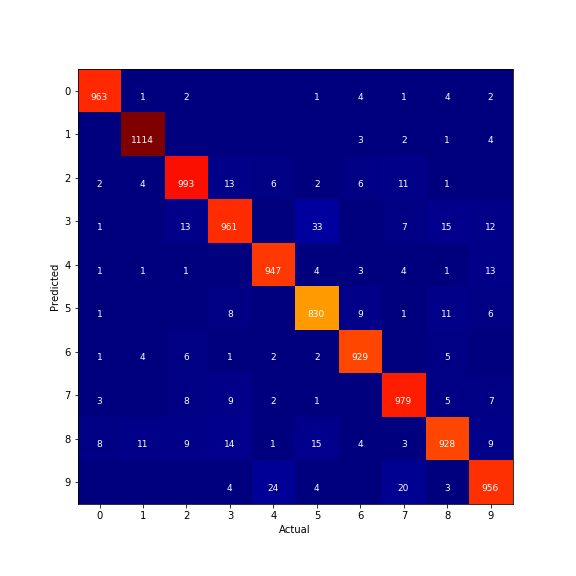
よくある考察ですが、4と9がやはり間違えやすいみたいですね。
まぁまぁの精度がでたのでこの辺で終わりにしたいと思います。
6 まとめ
75次元の特徴量でLightgbmで精度96%まで達成できます!
(もうちょっと頑張るともう少し精度がでそうですね)