背景
自分はゲーマーなので、ゲームのAI作りたいなと日々考えています。
今回は思いつきでスプラトゥーンの選手向け動画解析AIを作ってみました。
この記事では
・おおよその内容
・画像分類による結果
・そのデモ動画
まで、
次の記事では
・動画分類モデルによる結果を載せる予定です
#やりたいこと
タスク的には、「アクションセグメンテーション」が近いです。
アクションセグメンテーションとは、動画に対して行う分類モデルで、各フレームが行動クラスのどれに所属しているかを予測します。
例えば、ゴルフのスイングで
1F ~ 30F「バックスイング」
31F ~ 45F「ダウンスイング」
46F ~ 65F「フォロースルー」
とする感じです。
これをゲームデータでやります。
端的に言うとこれの左下のラベルを出力します
スプラトゥーンの行動認識(左下が出力ラベル)を機械学習でやってみたサンプル pic.twitter.com/eNTT5PHNoT
— itdk (@itdk1996) December 26, 2020
分類クラス
| ラベル | 行動 |
|---|---|
| 塗り(painting) | 周りを塗っている。牽制もこっちに含める |
| 攻撃(atack) | 対面している。相手を攻撃している。塗りを行動は同じ |
| 移動(moving) | イカ、あるいはヒト状態で移動する。塗りながらの移動を含める |
| 潜伏(hidden) | 索敵や回復も含む。移動と同じ状態 |
| マップ(map) | 生きている状態でマップを開いた状態 |
| スペシャル(special) | スペシャルの使用 |
| スーパージャンプ(super jump) | スーパージャンプ |
| オブジェクト(object) | ルール関与。エリア、ホコ、アサリ、ヤグラに関わるプレーイング。重複しやすいが対戦では大事な要素 |
| リスポーン(respawn) | デス中は一意。 |
| オープニング(opening) | オープニング |
| エンディング(ending) | エンディング |
です。
これ、何が難しいかと言うと入力上は重複したクラスが存在します。
以下の図のような感じで、「インクを出す」という行為は、「攻撃している」「塗っている」「オブジェクト関与している」のどれかの目的を持ってやっています。その、「目的を当ててね」ということで、アクションパーパスセグメンテーションです。
重複があるので、クラスの優先順位はあらかじめ決めてあります。
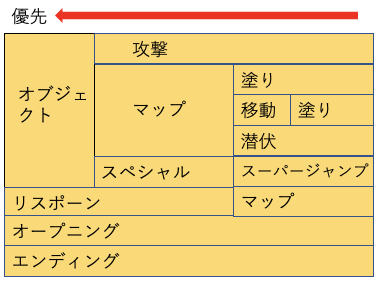
左側が優先。例えば、オブジェクト関与しならがマップみながら移動するってできてしまうので、その場合はオブジェクトラベルが優先して付与されます。
また、こういった性質から、画像単体で分類するには若干限界があります。画像が遷移しているから「移動している」になりますが、「隠れている」と状態は同じです。
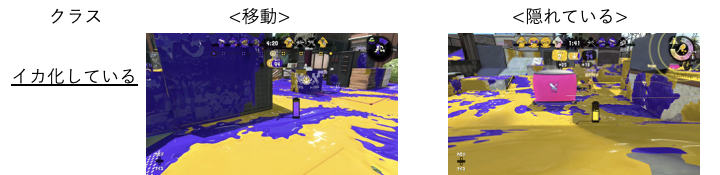
敵がいるから「攻撃している」になりますが、「塗っている」とかなり似ています。

なので、画像ベースの手法だと限界があります。
そこで、アクションセグメンテーションというタスクにおけるモデルを利用することを想定しつつ作業を始めました。
これができると何が嬉しいか
これ自体はあまり意味が無いんですが、動画全体で見ると以下の表が作れます。
1本の動画--->アクションの分布
に出来て、これができると、
・上手い人とそうでない人の比較
・同じ人のルールごとの立ち回りの比較
・同じ人の調子の善し悪しの比較
などいろいろ出来るわけですね。
プレイの内容の動画から数値の情報が抜けるといろいろな分析に使えるんじゃないかと思います
データセット
1.キャプチャーボード購入
2.スプラトゥーンをプレイ(26試合)
3.ELANというアクションセグメンテーションのアノテーションツールを使ってアノテーション
1個あたり最大6分くらいなんですが、見直すのでかなり時間かかりましたねぇ...
事前に検討した結果、ある程度環境はしぼって試してみることにしました
・ルール(ガチホコ、ガチエリアなど)は適度分散
・ステージは適当。その時にあったやつ。偏りをつけている
・武器はヒーローローラー、ローラーベッチュー
・イカニンジャをつけている
・自分のウデマエはオールX
・学習21件、テスト5件(エリア、ホコ、アサリ、ヤグラ、ナワバリひとつずつ)
・動画の平均は大体4分くらいとおもう
な感じです。
武器を散らそうかなと思ってたんですが、ギアも変わるし、スピナーチャージャーのチャージ時間ってどのクラスなんだとか複雑になるので、とりあえず持ち武器で行くことにしました。
あと、遊びだから許されるかもしれないですが、最初の方(r1,mp4)と最後の方(r20.mp4)でアノテーションのクオリティや基準が微妙に変わってます笑
例えば
・相手を見つける
・移動する
・攻撃する
に対して
隠れている→移動する→攻撃する
とするか、攻撃のための移動であるわけなので
隠れている→攻撃している
としている場合があります。
(なお、ローラーベッチューはスペシャルが着地だけだとあれかなと思い、ほぼ初めて使った)
データセットのリンク
公開するか検討中
画像ベースの手法
まず、転移学習で行くか、fine tuningで行くかの選択があります。
考えられることとしては
・スプラトゥーンドメイン、あまりにも尖っている。転移学習しても、分散表現に上手くならない?
・動画の数は多くないので、fine tuningするとoverfit気味かも
なので、この2つのどっちがマシかを検証します
ネットワーク構造はこんな感じ
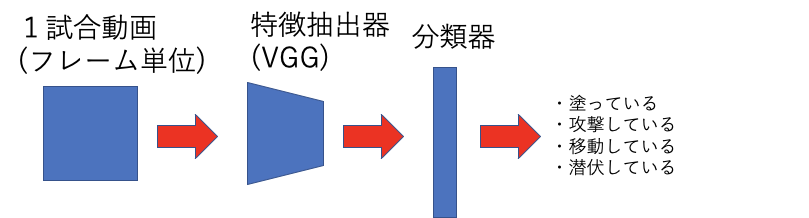
評価は、面倒なので、Accuracyを使います。アクションセグメンテーションだと色々評価方法はあるのですが、その辺はあとから考えます。
試して見た結果はこんな感じ
| モデル | モード | 精度 |
|---|---|---|
| VGG | 転移学習 | 64.7 |
| mibileNet | 転移学習 | 61.6 |
| VGG | fine tuning | 62.7 |
| mobileNet | fine tuning | 59.7 |
ちなみにfine tuningの方はそれなりに時間かかります。
VGGの転移学習がいちばん良かったですね。少し意外
あと、fine tuningの方が良くなるかと思ったけどそうでもなかったですね
| クラス | 精度 |
|---|---|
| total_accuracy | 0.64768 |
| opening | 0.97024 |
| moving | 0.57446 |
| hidden | 0.12668 |
| painting | 0.53247 |
| battle | 0.68719 |
| respawn | 0.93855 |
| superjump | 0.45745 |
| object | 0.22072 |
| special | 0.76923 |
| map | 0.38922 |
| ending | 0.98046 |
ある程度想定されていたクラスがやはり分類が難しいようです。
所感
機械学習をデータセットから作って色々するのは楽しいですね
動画モデルはこれから取り組みます
ただ、現状分かったこととしては、見たことあるステージ(テストデータでいうアロワナモール)は定性的ににかなり当たってそう。
なので、全ステージでとりあえず学習データ作ってもいいかもしれない
GitHub
https://github.com/daikiclimate/action_segmentation
重みとdemo用のコードは置いてあるので、動画と環境があれば実行はできると思います。
未検証