はじめに
こんにちは。今日はpythonとOCRを使ってウィングマンの命中率をだしてみます
デモはこんな感じ。スプラAIに引き続き、APEXでも画像処理で何かしたいと思ってこんなことしてみました。
大まかな内容
APEXにおいては敵に弾が当たると、敵の周りに数字がでるんですが、この位置はなかなか捉えられないんですよね。
そこで今回OCRかけるのは3つ。
(・現在の武器)
・現在の弾数(撃ったか撃ってないかがわかる)
・与ダメージ(与ダメージの増加により当たったかどうかがわかる)
・キル数(修正用)
取得する画像
元画像

ここから座標を指定して必要な画像の部分だけ切り抜きます。
武器名
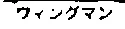
ダメージ
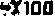
弾数
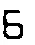
どれもいい感じに閾値きめて二値化したり大津の二値化を使って白黒にしてます。
余談ですが

人だと読めるし、画像内だと白文字って結構あるんですが、OCRだとこういうの読めないっぽいんですよね。これに気が付くの結構時間かかりました。
処理の内容
誤り補正
これがかなり大事。
特にダメージの認識はかなり小さい文字なのでちょいちょいご認識が起きるので適宜修正していく。例えばsとSは2に。iは1にといった感じ
どうしても解決できない問題として
デジタル表記だと0と8がそっくりなんですよね0の真ん中にスラッシュいれるなよ。。。
この辺はshoot_managerに補正させます。例えば、弾は減る一方なので4->3->8ってなってたらこれはリロードして4->3->0になったんだなみたいな感じです。
後は上の画像だとダメージ表記の横に変なヒットマークがあってこいつが邪魔なんですよね。でも、数字の桁数によって動くので、下手にクロップすると数字が見切れてしまうという。
そこでdigitで管理を行う。1個前の与ダメージが90なら次弾があたったら3桁になりそうなので3桁分右から見ようのような感じ。
こういった調整をこまごまと行う。
それでも問題は多い
動画のエンコーディング
H264形式(twitterで再生できる形式)の動画のエンコーディングがどうしてもopencvでできなかったので、今回は3段階で行く。
OPENCVで動画生成
↓
ffmpeg-pythonで動画を再エンコーディング
↓
moviepyで元々の動画と生成した動画で音をくっつける
コード
github(リファクタリング中)
https://github.com/daikiclimate/wingman_hitcounter
python main.py path-to-movie
でとりあえずは動く
notebook(初期、未整備)
https://colab.research.google.com/drive/1TNZM2arw_y2hK3AUIintzPpEH5mKpMc6?usp=sharing
残る問題
・まず武器1(左側)にウィングマンがないと認識できない(というよりしてない)
・同じ問題として、現在の武器が武器1がメインなのか、武器2がメインなのかがわからない
・ウィングマン以外で与ダメージを与えてしまった時にshoot_managerがバグる気がする
・その他もろもろ
この辺が起きないようにサンプルvideoが簡単めに調整されてる
感想
OCRって意外とめんどくさいな。。。