紹介する論文
CornerNet: Detecting Objects as Paired Keypoints
ECCV 2018で発表されているようです
あ、基本的には僕の解釈なのでところどころ間違っているところがあるかもしれません
指摘している問題点
faster RCNNやSSD、YOLOは、「事前に決められたアンカー」があり、アンカー内の「クラス」や「アンカーと実際のバウンディングボックスに関する回帰」を行っている
つまり割とアンカー依存な部分があるのではって疑問
①anchor数が増えていく
DSSDでは40k以上、RetinaNetは100k以上のアンカーが用いられている。
単純な話「アンカー増やせばアンカーに正解bboxがハマりやすいから精度あがるやん?」
さらにアンカー増やすとnegative anchorが増えて学習速度が落ちるという問題もある
②anchorのハイパーパラメータ多い
・いくつのbboxか
・どんなサイズか
・どんなアスペクト比か
この設計は手間がかかるし、複雑で面倒である。
アンカーの使わない物体検出器は作れないのか?
というのがモチベーションです。
大体の構造
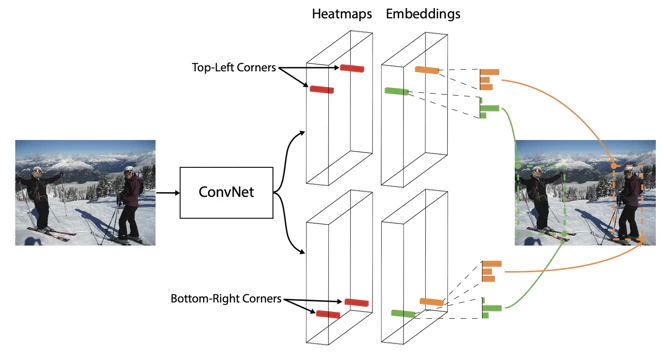
1番の特徴は、bbox座標や大きさなどを回帰しないこと。
では何をしているかというと、入力画像の左上の座標の確率、右上の座標の確率のヒートマップを出力する。全結合層を用いた回帰を行ってない
出力
基本の出力は3つ。
・座標の位置に関するヒートマップ(左上と右下それぞれ)
・同一クラスの物体をわけるエンベディング
・特徴抽出による解像度を戻すオフセットの出力
それぞれざっくりみてみます
ヒートマップ生成
正解バウンディングボックスの左上の座標は本来「点」であるため、予測するにはあまりにシビア
そこで、ガウシアンフィルタをかけて少し大きくします
あとはこのヒートマップをhourglassNetworkというencoder-decoder型ネットワークで予測させてあげるだけです。
損失関数はfocal lossを採用しています。

オフセット
ざっくりって観点でいえばそこまで重要ではないんですが、
特徴抽出をすると、解像度が落ちるので元の画像における正確な座標を回帰で求めています
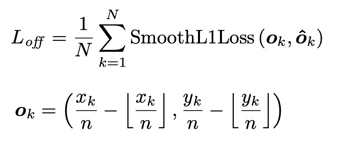
エンベディング
出力ヒートマップはクラス毎に作成されます。
そのため、一枚の画像から、同じクラスの物体が複数あった場合に、コーナーの点が複数でてきます。
例えば、人間が2人いる画像では、「人間クラスの出力ヒートマップ」には2つの左上の点が検出されます。
このあと、左上の点と右下の点の組み合わせを作って、バウンディングボックスとします。このときにどの左上とどの右下の組み合わせがペアがはっきりしません。
そこでエンベディングを用いて同じく組み合わせになる特徴量が類似するようなロスを掛け合わせます。
これにより組み合わせが簡単に見つけられるようになります。
Lpullは同じもの組み合わせの2点の特徴量を似たものにします
Lpushは違う組み合わせの2点の特徴量を異なったものにする性質を持ちます。
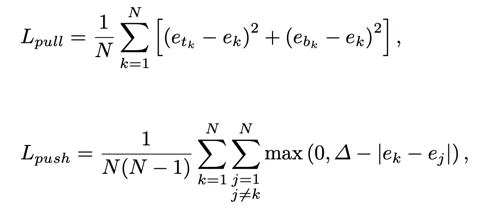

損失関数
検出ロス、エンベディングの2つのロス、オフセットのロスを組み合わせたものです。

corner pooling
「この左上の点と右下の点を予測する」という手法は、根本的に、そのクラスがないところを予測することが多いです。バウンディングボックスの端を予測するためですが、予測すべき点にそのクラスの情報がないというのは問題に思えます。
そこでcorner poolingという新しいpooling手法を用いています。
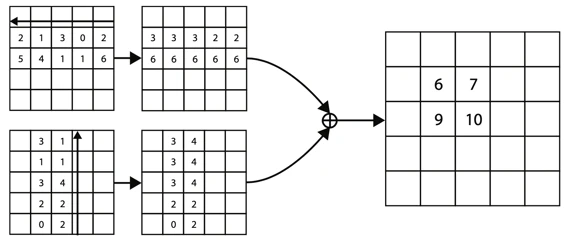
やっていることは図のような感じで、縦と横で最大値をずらしていく感じです。
「左上の座標の、右方向とした方向には人間がいる」という特徴をうまく考慮できそうな感じがあります。
結果
corner poolingの結果
図の上がcorner poolingなし、図の下がcorner poolingありのものです。正確なバウンディングボックスが提案されていることがわかります。

定量的には、少し精度がよくなっていることがわかります。なくても十分良いことも確認できます。

比較実験
他の手法との比較ですが、他のone stage detectorよりは非常に良い成績で、two stage detectorに匹敵するような成績を残しております。

成功例
重なっているキリンなどもきれいに検出できています。エンベディングがしっかり働いていることが確認できます。

失敗例
失敗例です。人物が検出できていなかったり、エンベディングがミスっているものもあります。

動作速度
1枚あたり244ms
遅い
まとめ
anchorを一切用いない新たな物体検出器を提案し、ある程度の結果がでていました。特に精度はかなり良いです。
一方で問題は244msと動作速度の遅さはピカイチです。ただヒートマップを用いた手法で最初の論文なので、今後改善されていく可能性はあります。
(個人的に)
corner poolingは多少結果がよくなっていますが、このアノテーション意外だとあんまり使えないかも
というわけでアンカーを用いない検出器CornerNetについてざっくり説明してみました。説明不足なところなどあればまた補足していきたいと思います
発展系
centerNet
https://arxiv.org/abs/1904.07850
Grid R-CNN
https://arxiv.org/abs/1811.12030