はじめに
Pythonを使って、音声文字起こしをするプログラムをご紹介します。
変換するライブラリーはChatGPTで有名なOpenAI社のWhisperを使います。
その変換モデルとして、2023年11月に発表されたlarge-v3モデルを使って、その精度やその処理時間も測定しています。
さらに、Whisperのモデルをそのままに、処理を高速化したfaster-Whisperを使ったプログラムもご紹介しています。
環境
Windows10
Python3.10.0
VENV (仮想環境構築)
CPU Intel Corei5
GPU NVIDIA Geforece RTX-3060 (GPUは無くても動きます)
主な利用ライブラリー
openai-whisper 20231117
faster-whisper 0.10.0
torch 2.0.1+cu117
torch 2.0.1(GPUが無い場合)
pandas 2.1.0
openpyxl 3.1.2
pydub 0.25.1
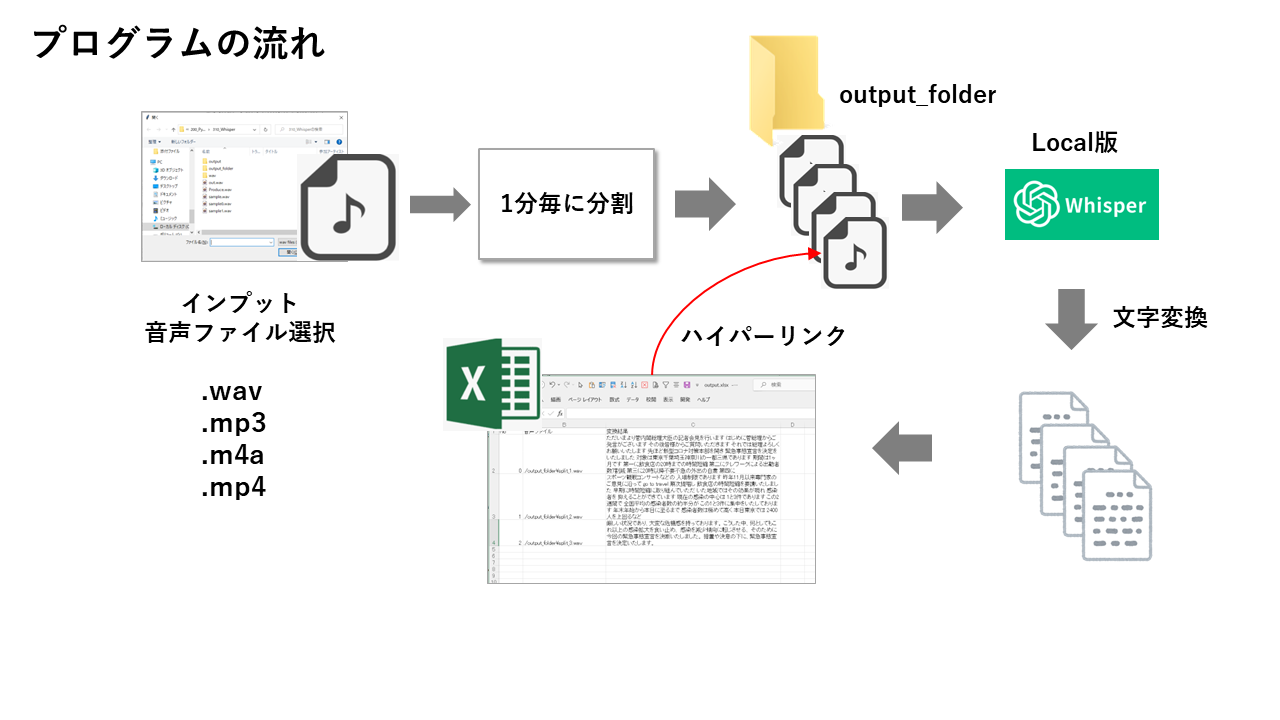
プログラムのイメージ
最終的に、以下のような音声文字認識アプリを作成しました。
YouTubeでの解説:
仮想環境の構築方法やGPUのセットアップ方法、各モデルの精度や処理速度の比較など、Youtubeで詳しく解説しています。
そのプログラムを使って、large-v3モデルの利用と、faster-Whisperへの変更を以下の動画で紹介しています。
サンプルソース1
YouTubeで紹介している、Whisperのlarge-v3を使ったプログラムソースです。
import whisper
import os
import tkinter.filedialog
from pydub import AudioSegment
import pandas as pd
from openpyxl import Workbook
from openpyxl.utils.dataframe import dataframe_to_rows
import datetime
def split_audio_file(file_path, output_folder):
# 入力ファイルの拡張子を取得
file_extension = os.path.splitext(file_path)[1].lower()
file_name = os.path.splitext(os.path.basename(file_path))[0]
# 音声形式に応じて読み込み方法を設定
if file_extension == ".wav":
audio = AudioSegment.from_wav(file_path)
elif file_extension == ".mp3":
audio = AudioSegment.from_mp3(file_path)
elif file_extension == ".m4a":
# .m4aファイルを読み込む
audio = AudioSegment.from_file(file_path, format="m4a")
# audio = AudioSegment.from_m4a(file_path)
elif file_extension == ".mp4":
# .mp4ファイルを読み込む
audio = AudioSegment.from_file(file_path, format="mp4")
else:
raise ValueError("サポートされていない音声形式です。")
# 分割する時間間隔(1分)を取得
split_interval = 1 * 60 * 1000 # ミリ秒単位
# 分割した音声ファイルを保存するフォルダを作成
os.makedirs(output_folder, exist_ok=True)
list1 = ["","",""]
df = pd.DataFrame([list1])
df.columns = ['No', '音声ファイル', '変換結果']
# 音声ファイルを分割する
for i, start_time in enumerate(range(0, len(audio), split_interval)):
# 分割開始位置と終了位置を計算
end_time = start_time + split_interval
# 音声を分割
split_audio = audio[start_time:end_time]
# 出力ファイル名を作成
output_file = os.path.join(output_folder, f"{file_name}_{i}{file_extension}")
# 分割した音声ファイルを保存
if file_extension == ".wav":
split_audio.export(output_file, format="wav")
elif file_extension == ".mp3":
split_audio.export(output_file, format="mp3")
elif file_extension == ".m4a":
split_audio.export(output_file, format="ma4")
elif file_extension == ".mp4":
split_audio.export(output_file, format="mp4")
print(f"分割ファイル {output_file} を保存しました。")
# 音声ファイルを文字変換
print("start:", datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
model = whisper.load_model("large-v3")
# result = model.transcribe(output_file,word_timestamps=True)
result = model.transcribe(output_file)
transcription = str(result["text"])
print(transcription)
# 結果をdfにセット
df.loc[i] = [i,output_file,transcription]
# excelへ書き出し
print("end:", datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
output_file = f"./{file_name}_output.xlsx"
workbook = Workbook()
sheet = workbook.active
# DataFrameの値をシートに書き込む
for r in dataframe_to_rows(df, index=False, header=True):
sheet.append(r)
# ファイルへのリンクをセット
for row in sheet.iter_rows(min_row=2, min_col=2, max_col=2): # B列の値を処理
cell = row[0]
file_path = cell.value
if file_path:
cell.hyperlink = file_path
cell.value = f'{file_path}'
# Excelファイルを保存
workbook.save(output_file)
# 入力ファイルのパスと出力フォルダのパスを指定
filetypes = [("wav files","*.wav"),('MP3 Files', '*.mp3'),('M4A Files', '*.m4a'),('MP4 Files', '*.mp4')]
input_file_path = tkinter.filedialog.askopenfilename(filetypes = filetypes,initialdir = './')
if not input_file_path:
print("ファイルが選択されなかった")
exit()
output_folder_path = "./output_folder"
# 音声ファイルを分割&音声変換
split_audio_file(input_file_path, output_folder_path)
faster-whisper
上記のプログラムをfaster-whisperを使って高速化したサンプルです。
githubのfaster-whisperのページを参考にしてください。
サンプルソース2
YouTubeで紹介している、Whisperのlarge-v3を使ったプログラムソースです。
# import whisper
from faster_whisper import WhisperModel
import os
import tkinter.filedialog
from pydub import AudioSegment
import pandas as pd
from openpyxl import Workbook
from openpyxl.utils.dataframe import dataframe_to_rows
import datetime
def split_audio_file(file_path, output_folder):
# 入力ファイルの拡張子を取得
file_extension = os.path.splitext(file_path)[1].lower()
file_name = os.path.splitext(os.path.basename(file_path))[0]
# 音声形式に応じて読み込み方法を設定
if file_extension == ".wav":
audio = AudioSegment.from_wav(file_path)
elif file_extension == ".mp3":
audio = AudioSegment.from_mp3(file_path)
elif file_extension == ".m4a":
# .m4aファイルを読み込む
audio = AudioSegment.from_file(file_path, format="m4a")
# audio = AudioSegment.from_m4a(file_path)
elif file_extension == ".mp4":
# .mp4ファイルを読み込む
audio = AudioSegment.from_file(file_path, format="mp4")
else:
raise ValueError("サポートされていない音声形式です。")
# 分割する時間間隔(1分)を取得
split_interval = 1 * 60 * 1000 # ミリ秒単位
# 分割した音声ファイルを保存するフォルダを作成
os.makedirs(output_folder, exist_ok=True)
list1 = ["","",""]
df = pd.DataFrame([list1])
df.columns = ['No', '音声ファイル', '変換結果']
# 音声ファイルを分割する
for i, start_time in enumerate(range(0, len(audio), split_interval)):
# 分割開始位置と終了位置を計算
end_time = start_time + split_interval
# 音声を分割
split_audio = audio[start_time:end_time]
# 出力ファイル名を作成
output_file = os.path.join(output_folder, f"{file_name}_{i}{file_extension}")
# 分割した音声ファイルを保存
if file_extension == ".wav":
split_audio.export(output_file, format="wav")
elif file_extension == ".mp3":
split_audio.export(output_file, format="mp3")
elif file_extension == ".m4a":
split_audio.export(output_file, format="ma4")
elif file_extension == ".mp4":
split_audio.export(output_file, format="mp4")
print(f"分割ファイル {output_file} を保存しました。")
# 音声ファイルを文字変換
print("start:", datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
# model = whisper.load_model("large-v3")
# result = model.transcribe(output_file,word_timestamps=True)
segments, _ = model.transcribe(output_file, beam_size=5)
# result = model.transcribe(output_file)
transcription = ''
for segment in segments:
transcription = transcription + str(segment.text) + '\n'
print(transcription)
# 結果をdfにセット
df.loc[i] = [i,output_file,transcription]
# excelへ書き出し
print("end:", datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
output_file = f"./{file_name}_output.xlsx"
workbook = Workbook()
sheet = workbook.active
# DataFrameの値をシートに書き込む
for r in dataframe_to_rows(df, index=False, header=True):
sheet.append(r)
# ファイルへのリンクをセット
for row in sheet.iter_rows(min_row=2, min_col=2, max_col=2): # B列の値を処理
cell = row[0]
file_path = cell.value
if file_path:
cell.hyperlink = file_path
cell.value = f'{file_path}'
# Excelファイルを保存
workbook.save(output_file)
# 入力ファイルのパスと出力フォルダのパスを指定
filetypes = [("wav files","*.wav"),('MP3 Files', '*.mp3'),('M4A Files', '*.m4a'),('MP4 Files', '*.mp4')]
input_file_path = tkinter.filedialog.askopenfilename(filetypes = filetypes,initialdir = './')
if not input_file_path:
print("ファイルが選択されなかった")
exit()
output_folder_path = "./output_folder"
model_size = "large-v3"
# Run on GPU with FP16
model = WhisperModel(model_size, device="cuda", compute_type="float16")
# or run on GPU with INT8
# model = WhisperModel(model_size, device="cuda", compute_type="int8_float16")
# or run on CPU with INT8
# model = WhisperModel(model_size, device="cpu", compute_type="int8")
# 音声ファイルを分割&音声変換
split_audio_file(input_file_path, output_folder_path)
最後に:
今回は、音声文字変換のWhisperの最新モデルのlarge-v3を使って、音声ファイルをエクセルに出力するPythonプログラムを作成しました。
また、処理速度を高速化する為の、faster-Whisperも使いました。
高速、超高精度な音声認識が無料で出来ますのでもしよかったら、参考にしてみてください。
詳しくは、Youtubeでご紹介していますので、ご覧ください。
【Python】音声文字起こしWhisperの最新モデルLarge-v3と高速処理のfaster Whisperを試してみた!~ついに精度xxx%!~
今後も、良さそうなプログラムが出来たら、ご紹介したいと思います。