TL;DR
xgboost を用いて Feature Importanceを出力します。
object のメソッドから出すだけなので、よくご存知の方はブラウザバックしていただくことを推奨します。
この記事の内容
- 前回の記事
-
xgboost でトレーニングデータに CSVファイルを指定したらなんか相当つまづいた。
-
Feature Importance とは、(私の理解で言えば) 説明変数ごとに出力結果に与える影響の度合いを数値化したもの。
- 例えば、カレーを作るをときに、このカレーの味を決めているのはどの調味料の影響が大きいのか
(ターメリックなのか?, コリアンダーなのか? みたいなこと)
をスコアとして出力してくれるみたいな感じです。(たぶん)
- 例えば、カレーを作るをときに、このカレーの味を決めているのはどの調味料の影響が大きいのか
-
- 今回の内容
- 前回、学習をさせるには至ったので、いよいよ Feature Importance の算出をする。
そして、もはや毎度のことなのですが、
あまり説明などが正確ではありませんことをご承知おきください。
大変遅くなりました。
記事自体はほとんどできていたのですが、
最近は研究周りの作業が忙しく、なかなか投稿する時間が取れませんでした。
すみません。
まずは、出力の仕方を知る。
例によって例のごとく、既に確立されている方法において、Feature Importance はどのように出力されているのかを確認します。
プログラム
前回も参考にさせていただいた下記のサイトにまたお世話になります。
Python: XGBoost を使ってみる のうち、「特徴量の重要度を可視化する」
import xgboost as xgb
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from matplotlib import pyplot as plt
"""XGBoost で特徴量の重要度を可視化するサンプルコード"""
# sklearn にある Iris datasetを読み込む。
dataset = datasets.load_iris()
x, y = dataset.data, dataset.target
x_train, x_test, y_train, y_test = train_test_split(x, y,
test_size=0.3,
shuffle=True,
stratify=y)
# 可視化のために特徴量の名前を渡しておく
dtrain = xgb.DMatrix(x_train, label=y_train,
feature_names=dataset.feature_names)
dtest = xgb.DMatrix(x_test, label=y_test,
feature_names=dataset.feature_names)
xgb_params = {
'objective': 'multi:softmax',
'num_class': 3,
'eval_metric': 'mlogloss',
}
evals = [(dtrain, 'train'), (dtest, 'eval')]
evals_result = {}
bst = xgb.train(xgb_params,
dtrain,
num_boost_round=100,
early_stopping_rounds=10,
evals=evals,
evals_result=evals_result
)
y_pred = bst.predict(dtest)
acc = accuracy_score(y_test, y_pred)
print("Accuracy : ", acc)
# 性能向上に寄与する度合いで重要度をプロットする
_, ax = plt.subplots(figsize=(12, 4))
xgb.plot_importance(bst,
ax=ax,
importance_type='gain',
show_values=False)
plt.show()
出力された表について
そうして出力されたものがこちらになります。
(n分クッキング感)
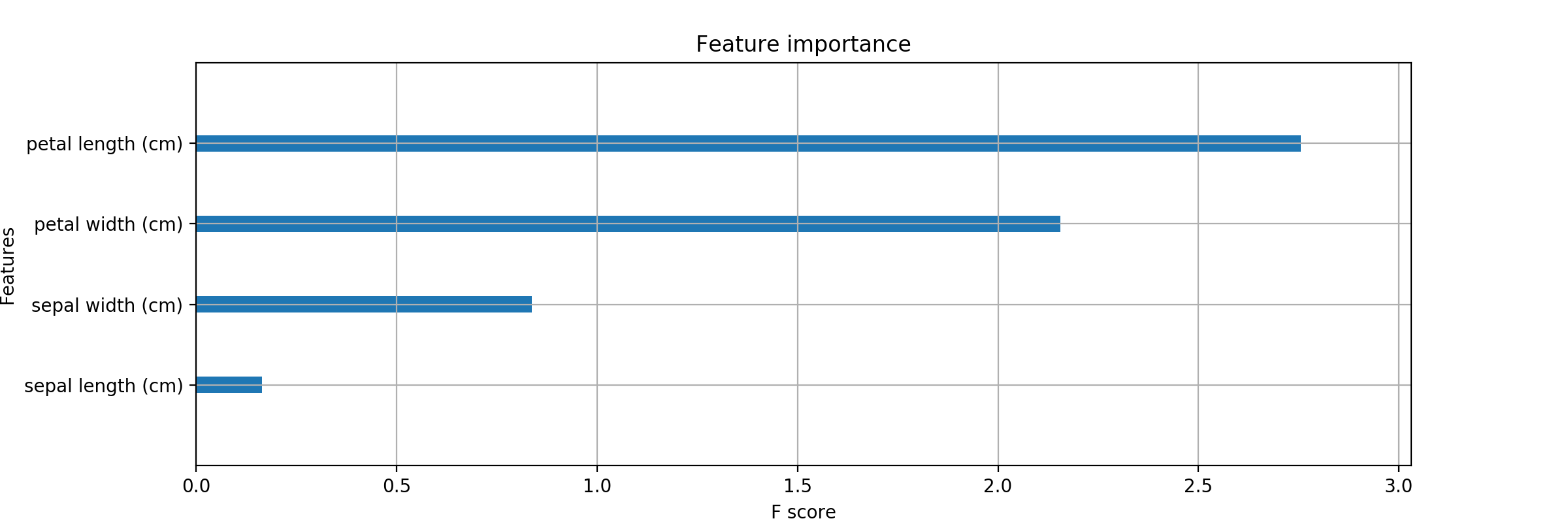
悪くない..が。棒グラフだけしかねえ。
数値でも欲しいなあ。
# よく見ると、最後の引数に show_values って書いてある。
xgb.plot_importance(bst,
ax=ax,
importance_type='gain'
#show_values=False
)
と、雑にコメントアウトして、実行。
(もちろん show_values=True と指定しても良いです。)
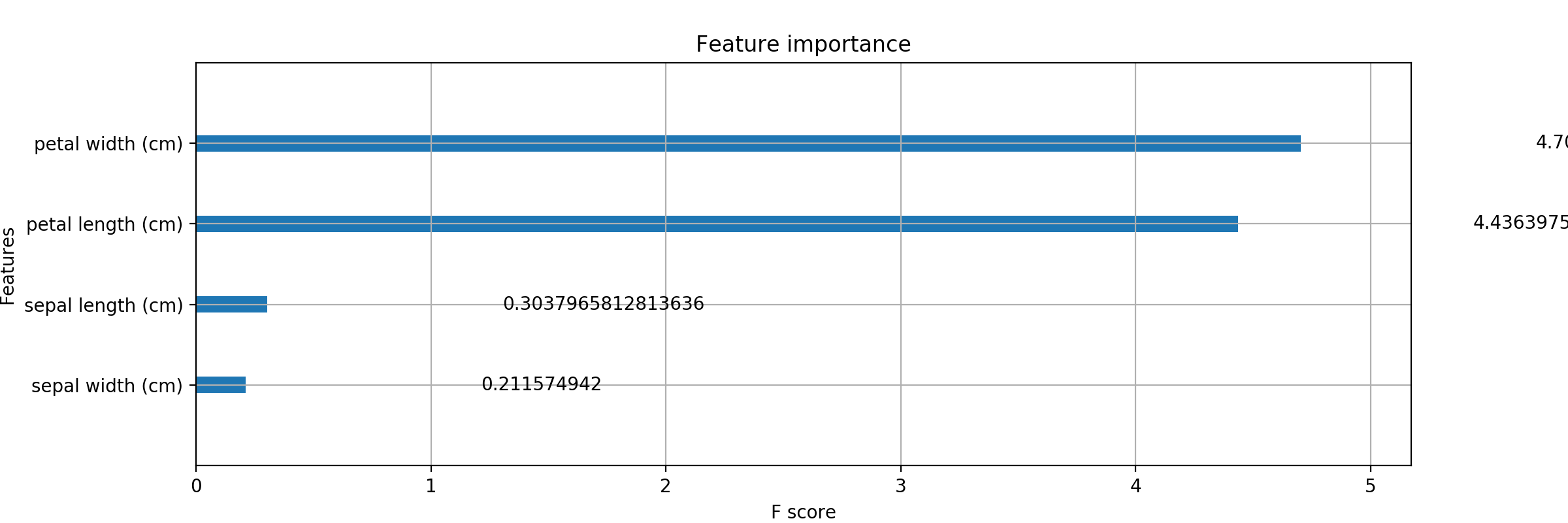
おおん? なんだこのきちゃない値..
この記事を参考にさせていただくと
どうやら、Feature Importance には
3種類の指標が用意されているらしいことがわかりました。
[ちなみに、公式(?)ドキュメントにも同じようなことが書いてありました。]
(https://xgboost.readthedocs.io/en/latest/python/python_api.html)
xgboost.plot_importance(booster, ax=None, ..., importance_type='weight', ...)
Plot importance based on fitted trees.
Parameters
...
importance_type (str, default "weight") –
How the importance is calculated: either “weight”, “gain”, or “cover”
”weight” is the number of times a feature appears in a tree
”gain” is the average gain of splits which use the feature
”cover” is the average coverage of splits which use the feature where coverage is defined as the number of samples affected by the split
ということで、ですね。
# この第3引数の importance_type を
xgb.plot_importance(bst,
ax=ax,
importance_type='gain'
#show_values=False
)
# このようにコメントアウトするか、
xgb.plot_importance(bst,
ax=ax
#importance_type='gain'
#show_values=False
)
# weight の指定にすると
xgb.plot_importance(bst,
ax=ax,
importance_type='weight'
#show_values=False
)
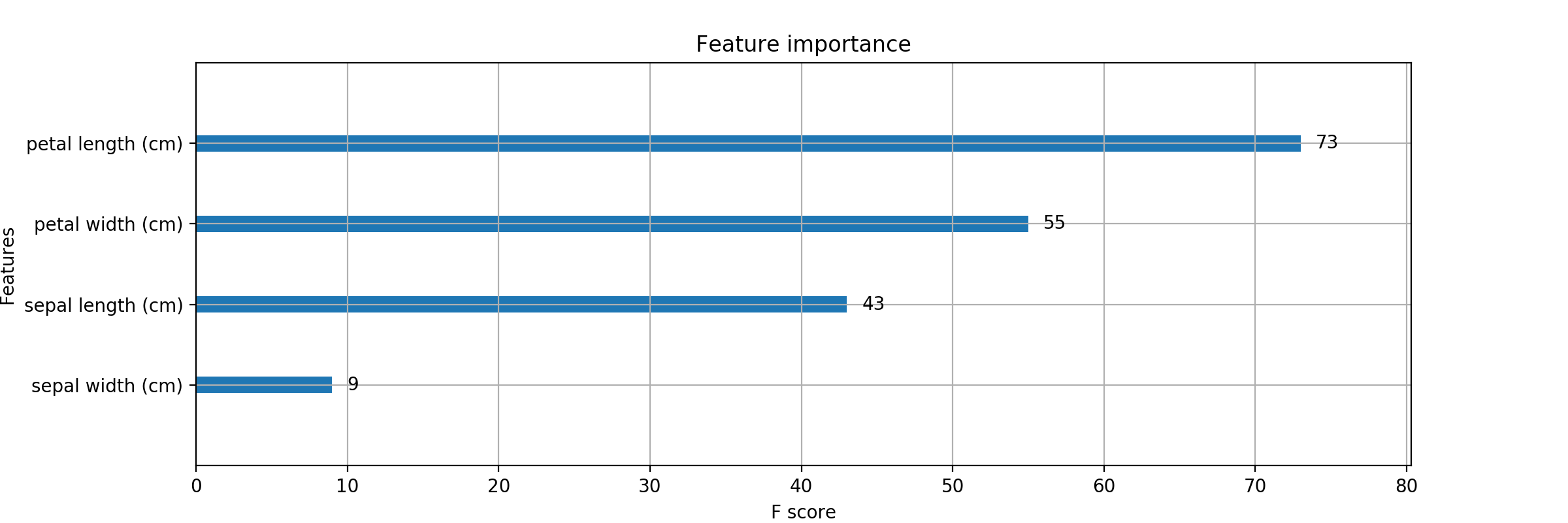
こんな風に、いい感じで表示できます。
余談ですが、
参考サイトでは「default の指定が gain になった」とのことでしたが
コメントアウトしたときと、weightで指定したときで同様の結果がでるということは、
さっきの公式っぽいDocument にあるように
importance_type (str, default "weight") –
デフォは weight なのですかね。
辞書もほしい。
それはさておき。
もう1つ欲しいものがあります。
Feature Importanceの情報を持っている辞書です。
どうしたものか.. と思い、色々雑に print してみたり、検索かけていたら
ここでいいものを見つけました。
bst.get_fscore()
{'f0': 17, 'f1': 16, 'f2': 95, 'f3': 59}
これじゃね? 早速 print します。
(入れる場所は print(Accuracy..) の下あたりに..)
print(bst.get_fscore())
{'petal length (cm)': 84, 'petal width (cm)': 42, 'sepal length (cm)': 22, 'sepal width (cm)': 19}
いい感じ! これが知りたかったのよ。
一旦まとめます。
ここまででできたプログラム
import xgboost as xgb
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from matplotlib import pyplot as plt
"""XGBoost で特徴量の重要度を可視化するサンプルコード"""
# sklearn にある Iris datasetを読み込む。
dataset = datasets.load_iris()
x, y = dataset.data, dataset.target
x_train, x_test, y_train, y_test = train_test_split(x, y,
test_size=0.3,
shuffle=True,
stratify=y)
# 可視化のために特徴量の名前を渡しておく
dtrain = xgb.DMatrix(x_train, label=y_train,
feature_names=dataset.feature_names)
dtest = xgb.DMatrix(x_test, label=y_test,
feature_names=dataset.feature_names)
xgb_params = {
'objective': 'multi:softmax',
'num_class': 3,
'eval_metric': 'mlogloss',
}
evals = [(dtrain, 'train'), (dtest, 'eval')]
evals_result = {}
bst = xgb.train(xgb_params,
dtrain,
num_boost_round=100,
early_stopping_rounds=10,
evals=evals,
evals_result=evals_result
)
y_pred = bst.predict(dtest)
acc = accuracy_score(y_test, y_pred)
print("Accuracy : ", acc)
# Feature Importance の情報を持つ辞書を出力
print(bst.get_fscore())
# 性能向上に寄与する度合いで重要度をプロットする
_, ax = plt.subplots(figsize=(12, 4))
xgb.plot_importance(bst, ax=ax)
plt.show()
これで、Feature Importance に関しては
棒グラフとそれに対応する辞書の形で取得することができるようになりました。
任意のファイル(特にCSVファイル)に対して出力できるようにしたい。
さて、欲しいものの出力の仕方はわかったのですが、前回同様、データには sklearn の datasets から読んだものを使用しています。
今後、自分で勝手なデータを持ってきて、出力したいときのために、
sklearn の datasets でなくともできるようにしたいのです。
お気付きの方も多いと思いますが
こんなコードが出てきていました。
# 可視化のために特徴量の名前を渡しておく
dtrain = xgb.DMatrix(x_train, label=y_train,
feature_names=dataset.feature_names)
dtest = xgb.DMatrix(x_test, label=y_test,
feature_names=dataset.feature_names)
=> feature_names=dataset.feature_names
ここで datasets のメソッドを用いているのですよね。
(ちなみに、dataset とは dataset = datasets.load_iris() でした。)
この中身をみてみます。
print(dataset.feature_names)
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
あ、ヘッダのリストか。いけそう(罠)
Pandas で columnを得る
失敗例
長くなってもあれなので、一気に行きます。
概ね実行スクリプトの後ろにある #の後が出力結果という見た目になります。
お急ぎの方は次の見出しまで飛ばしてください。
使用したCSVファイルは Iris dataset の
1行欠けたものをCSV形式にしてあるものになります。
(ファイル名 : Fishers_Irises_train.csv)
# read_csv
import pandas as pd
file_pass = '(pardir)/Fishers_Irises_train.csv'
iris_csv = pd.read_csv(data)
# print(iris_csv)
# この辺りは前回の記事から持ってきています..
## iloc[1:]指定しているのはヘッダを読まないため。
x = iris_csv.iloc[1:, :3]
x = x.values.astype(float)
# print('Feature data :', x)
y = iris_csv.iloc[1:, 3]
y = y.values.astype(int)
y = y -1
# print('answer :', y_pd)
# カラム名をリスト型で取得する
# --- 失敗例 ---
print(iris_csv.columns)
# >> Index(['PetalLength', 'SepalLength', 'SepalWidth', 'Species'], dtype='object')
また objectかいな..
print(iris_csv.iloc[0])
""" 出力結果
>> PetalLength 1.4
SepalLength 5.1
SepalWidth 3.5
Species 1.0
Name: 0, dtype: float64
# 違うそうじゃない..
"""
print(iris_csv.iloc[0].dtype)
# >> float64 (そうでもない)
# 考えてみた。
# # astype で型変換できるんじゃ..? (アホ)
feature_cloumns = iris_csv.columns.astype(list)
# >> Index(['PetalLength', 'SepalLength', 'SepalWidth', 'Species'], dtype='object') (できへんで。)
# 調べたら values で 変換できるとか..
feature_cloumns = iris_csv.columns.values
print(feature_cloumns)
# ['PetalLength' 'SepalLength' 'SepalWidth' 'Species'] お。
print(type(feature_cloumns))
# <class 'numpy.ndarray'> え。
print(type(feature_cloumns) == list)
# False おうふ。
やっとできた。
# pandas で読み込んだ csv data から column 情報を取得
columns = iris_csv.columns
# columns を values で (npdarrayの)リストに変換
cloumns_ndarray = columns.values
# numpy の型変換を用いて、 ndarray を python 標準の list に変換
feature_cloumns = cloumns_ndarray.tolist()
# 結果観察
print(feature_cloumns)
# >> ['PetalLength' 'SepalLength' 'SepalWidth' 'Species'] お。
print(type(feature_cloumns))
# >> <class 'list'> お。
print(type(feature_cloumns) == list)
# >> True っしゃあ。 (めんどくさくね??)
やっていること
結局、pandasで読み込んだ CSVのカラム名を dataframe.columns で取得し
これが objectなので、dataframe.values を用いて ndarray に変換し
ndarray.tolist() を用いて NumPy配列を Python標準のリスト型に直しています。
愚かですね。
そうして Feature Importance の出力へ。
import numpy as np
import xgboost as xgb
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
plt.style.use('ggplot')
file_pass = '(pardir)/Fishers_Irises_train.csv'
iris_csv = pd.read_csv(file_pass)
# print(iris_csv)
## iloc[1:]指定しているのはヘッダを読まないため。
x = iris_csv.iloc[1:, :3]
x = x.values.astype(float)
# print('Feature data :', X_pd)
y = iris_csv.iloc[1:, 3]
y = y.values.astype(int)
y = y -1
# print('answer :', y)
# --- fearure columns の取得 ---
# pandas で読み込んだ csv data から column 情報を取得
columns = iris_csv.columns
# columns を values で (npdarrayの)リストに変換
cloumns_ndarray = columns.values
# numpy の型変換を用いて、 ndarray を python 標準の list に変換
feature_cloumns = cloumns_ndarray.tolist()
# print(feature_cloumns) # ['PetalLength' 'SepalLength' 'SepalWidth' 'Species']
# print(type(feature_cloumns))
# print(type(feature_cloumns) == list)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, shuffle=True, stratify=y)
# 可視化のためにこの時点で特徴量の名前を渡しておく
dtrain = xgb.DMatrix(x_train, label=y_train,
feature_names=feature_cloumns[0:3])
dtest = xgb.DMatrix(x_test, label=y_test,
feature_names=feature_cloumns[0:3])
# feature_columns = ['PetalLength' 'SepalLength' 'SepalWidth' 'Species']
# 'Species' を指定しないように [0:3] ([0] ~ [2])で指定。
""" # これでもよい。('Species' を先に削っておくスタイル。)
# 正解ラベルのカラム名 'Species' を含んでしまっているので、これを popする。
feature_cloumns.pop()
dtrain = xgb.DMatrix(x_train, label=y_train,
feature_names=feature_cloumns)
dtest = xgb.DMatrix(x_test, label=y_test,
feature_names=feature_cloumns)
"""
xgb_params = {
'objective': 'multi:softmax',
'num_class': 3,
'eval_metric': 'mlogloss'
}
evals = [(dtrain, 'train'), (dtest, 'eval')]
evals_result = {}
bst = xgb.train(xgb_params,
dtrain,
num_boost_round=100,
early_stopping_rounds=10,
evals=evals,
evals_result=evals_result
)
y_pred = bst.predict(dtest)
acc = accuracy_score(y_test, y_pred)
print("Accuracy : ", acc)
print(bst.get_fscore())
# 性能向上に寄与する度合いで重要度をプロットする
_, ax = plt.subplots(figsize=(12, 4))
xgb.plot_importance(bst, ax=ax)
plt.show()
これを実行しますと $ python xgb_fi.py
{'PetalLength': 145, 'SepalLength': 93, 'SepalWidth': 58}
このような Feature Importance の情報を持つ辞書と
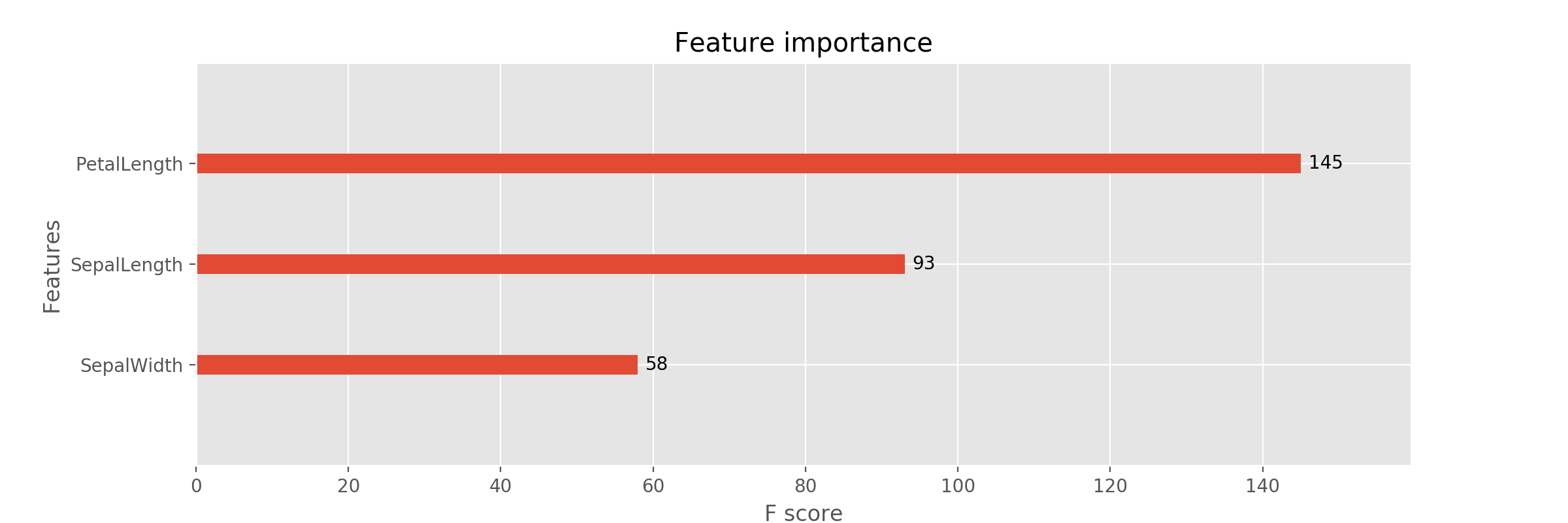
それに対応した棒グラフ (スコア入り)が出力されます。
まとめ
こんな感じでややつまづきながらも、
Feature Importanceを所望のファイルに対して出力する方法を
知ることができたかなと思います。
それにしても xgboost は結構完成された(機能もりもりの、という意味の)
ライブラリであることがわかってびっくりしています。
いろんなメソッドを持たせることって、予知能力というか、先見の明というか、
ニーズを察する力が必要だなあと感じるので、すごいなあという感じですね。
今回は使い方の勉強と、「出力をすること」に重きをおいていたので、
パラメータだとか正しさだとかいう点で保証ができないのですが
そのうち、何か目的を持って使うときにここで学んだことが活きればいいなと思います。
ここまで読んでいただきありがとうございました。
それでは。