Python Resnetでファインチューニング
本記事はResnetを使用したファインチューニングを紹介します。
今回はファインチューニングがどれだけの効果が出るのかを検証するため、通常の
[CNNで作成したモデル]と[ファインチューニングしたモデル]で比較したいと思います。
開発環境
私はGoogle Colabで学習を行いましたが、ローカル前提でも可能なように記載します。
python : 3.7.0
keras : 2.4.3
tensorflow : 2.2.0
Resnetとは
ResnetとはImagenetというデータベースの100万枚を超える【学習済み】の畳み込みニューラルネットワーク(Convolutional Neural Network)のこと。
そしてこのネットワークはResnet50とも呼ばれ、深さが50層あり1000個のカテゴリニー分類できる。
ファインチューニングとは
学習済みネットワークの重みを初期値として、モデル全体の重みを再学習することです。
なので、上記Resnet50を用いたうえで、再学習させることでより良い判別機を作ることを目指します。
使用する画像
なんとなく面白そうだったので、日本のタバコ3種類を使用してみました
メビウス : 338枚
セブンスター : 552枚
ウィンストン : 436枚
今回はファインチューニングの検証ということなので、上記画像はインターネットから引っ張ってきました。
通常のCNN
構成は下記です。
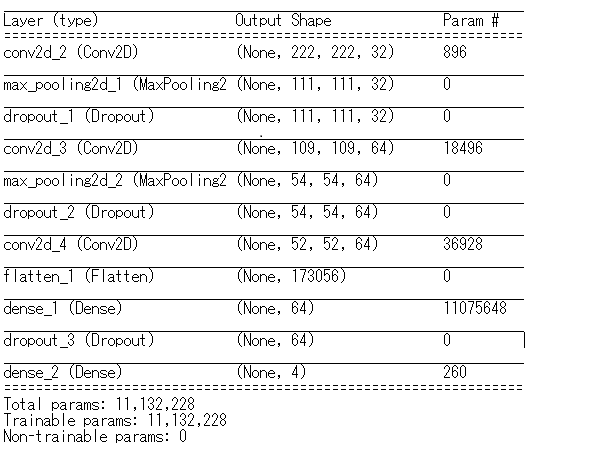
これを学習すると下記のような結果になりました。

画像の切り出しなど事前処理をしていないため、かなり悪いですね。
テストデータでは大体【60%】前後でしょうか。
ソース
from PIL import Image
import numpy as np
import glob
import os
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers.convolutional import MaxPooling2D
from keras.layers import Conv2D, Flatten, Dense, Dropout
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
root = "tobacco_dataset"
folder = os.listdir(root)
image_size = 224
dense_size = len(folder)
epochs = 30
batch_size = 16
X = []
Y = []
for index, name in enumerate(folder):
dir = "./" + root + "/" + name
print("dir : ", dir)
files = glob.glob(dir + "/*")
print("number : " + str(files.__len__()))
for i, file in enumerate(files):
try:
image = Image.open(file)
image = image.convert("RGB")
image = image.resize((image_size, image_size))
data = np.asarray(image)
X.append(data)
Y.append(index)
except :
print("read image error")
X = np.array(X)
Y = np.array(Y)
X = X.astype('float32')
X = X / 255.0
Y = np_utils.to_categorical(Y, dense_size)
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.15)
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(image_size, image_size, 3)))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(Flatten())
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(dense_size, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
result = model.fit(X_train, y_train, validation_split=0.15, epochs=epochs, batch_size=batch_size)
x = range(epochs)
plt.title('Model accuracy')
plt.plot(x, result.history['accuracy'], label='accuracy')
plt.plot(x, result.history['val_accuracy'], label='val_accuracy')
plt.xlabel('Epoch')
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5), borderaxespad=0, ncol=2)
name = 'tobacco_dataset_reslut.jpg'
plt.savefig(name, bbox_inches='tight')
plt.close()
Resnetによるファインチューニング
構成はかなり層が深くてQiitaに貼り切れないので、URLを記載します
https://github.com/daichimizuno/cnn_fine_tuning/blob/master/finetuning_layer.txt
さらに元来のResnetに加えて活性化関数Reluとドロップアウトを0.5いれてあります。
ちなみに下記ソースがResnetを使用する時のソースになります。Kerasの中にResnet用のライブラリが入っているようです。
ResNet50 = ResNet50(include_top=False, weights='imagenet',input_tensor=input_tensor)
これを学習すると下記のような結果になりました。

テストデータでは大体【85%】前後でしょうか。
ソース
from PIL import Image
import numpy as np
import glob
import os
from keras.utils import np_utils
from keras.models import Sequential, Model
from keras.layers import Flatten, Dense,Input, Dropout
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from keras.applications.resnet50 import ResNet50
from keras import optimizers
root = "tobacco_dataset"
folder = os.listdir(root)
image_size = 224
dense_size = len(folder)
epochs = 30
batch_size = 16
X = []
Y = []
for index, name in enumerate(folder):
dir = "./" + root + "/" + name
print("dir : ", dir)
files = glob.glob(dir + "/*")
print("number : " + str(files.__len__()))
for i, file in enumerate(files):
try:
image = Image.open(file)
image = image.convert("RGB")
image = image.resize((image_size, image_size))
data = np.asarray(image)
X.append(data)
Y.append(index)
except :
print("read image error")
X = np.array(X)
Y = np.array(Y)
X = X.astype('float32')
X = X / 255.0
Y = np_utils.to_categorical(Y, dense_size)
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.15)
input_tensor = Input(shape=(image_size, image_size, 3))
ResNet50 = ResNet50(include_top=False, weights='imagenet',input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=ResNet50.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(dense_size, activation='softmax'))
top_model = Model(input=ResNet50.input, output=top_model(ResNet50.output))
top_model.compile(loss='categorical_crossentropy',optimizer=optimizers.SGD(lr=1e-3, momentum=0.9),metrics=['accuracy'])
top_model.summary()
result = top_model.fit(X_train, y_train, validation_split=0.15, epochs=epochs, batch_size=batch_size)
x = range(epochs)
plt.title('Model accuracy')
plt.plot(x, result.history['accuracy'], label='accuracy')
plt.plot(x, result.history['val_accuracy'], label='val_accuracy')
plt.xlabel('Epoch')
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5), borderaxespad=0, ncol=2)
name = 'resnet_tobacco_dataset_reslut.jpg'
plt.savefig(name, bbox_inches='tight')
plt.close()
まとめ
通常のCNNとファインチューニングを比較すると、ファインチューニングの方がエポック10あたりから急激に良くなっているのが分かります。
これはResnetを使用した再学習なので、Resnetの正答率が高まってくる部分で伝搬してタバコ判別にも影響してくるということなんかなと、想像していますがさらに詳しく分析は必要ですね...
ただ、いずれにしてもタバコ判定という意味では通常のCNNよりもかなり高い結果が出ました。
画像の選定や事前処理を行えばさらに良い結果が出ると思いますので、できる方はやってみてください!
【Github】
https://github.com/daichimizuno/cnn_fine_tuning
何か間違いや不明点などあればご指摘ください。
以上です