1. はじめに
こんにちは。Aidemy Premium Planデータ分析コースの鈴木です。
私は現在製造業で機械設計を行っています。日本の製造業はまだまだAI技術の導入が遅れていると言われており、今後も製造業での設計過程や製造過程にて機械学習や深層学習を取り込んだ技術が更に増えていくと想定しています。私自身、製造工程で不良解析を行った経験がありますが、その当時は自動化がされていなかったり、各工程でのデータ非常に少なく、とても解析に時間が掛かりました。よって不良率の原因を探るに当たって、ラインの自動化や各工程でのデータが得られてれば、何が起因の不良かを解析していくにあたり、効率良く進められると思いました。
そこで私は不良分類というテーマにて、機械学習を行っていきたいと思います。
#2. 学習データ
SIGNATEの練習コンペである、ステンレス板の欠陥分類データを使います。
予測する欠陥の種類は下記7種類あり、データから7種類に分類します。
(1=Pastry,2=Z_Scratch,3=K_Scatch,4=Stains,5=Dirtiness,6=Bumps,7=Other_Faults)
精度評価はAccuracyを使用します。

#3. 目的と進め方
####・目的
①上記SIGNATE練習問題内にて、リーダーボードにて1位を目指す。
(2022/02/10時点で1位の正解率は0.7816684)
②下記手順で進めることにより、データ調整無しの場合と比較してデータの前処理やハイパーパラメータチューニングによるAccuracyの精度が向上するか確認をする。
####・進め方
手順1:データを調整無しで分類し精度の高い分類方法Best3を選定
手順2:データクレンジングを行い、手順1のBest3の方法で分類
手順3:手順2で最も精度の高い分類方法でハイパーパラメータチューニングを行う
#4. 開発環境
Google Colaboratory
Pyton 3.7.12
Numpy 1.19.5
Pandas 1.3.5
seaborn 0.11.2
sklearn 1.0.2
Light GBM 2.2.3
#5. 学習モデルの構築
###5.1 今回検証する機械学習モデル
分類手法は下記で行う。
・Logistic回帰
・線形SVM
・非線形SVM
・k近傍法
・決定木
・ランダムフォレスト
・Light GBM
###5.2 ライブラリのインポート
#ライブラリのインポート
import numpy as np
import pandas as pd
from pandas import DataFrame
import seaborn as sns
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.svm import LinearSVC
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
###5.3 データの読み込み
#trainデータの読み込み
train_df = pd.read_csv("/~~/train_steel.csv")
###5.4 データの確認
欠損値が無いことはわかっていますが、データを確認します。
train_df.shape
#出力結果
(970, 29)
train_df.dtypes
#出力結果
#Unnamed: 0 int64
#X_Minimum int64
#X_Maximum int64
#Y_Minimum int64
#Y_Maximum int64
#Pixels_Areas int64
#X_Perimeter int64
#Y_Perimeter int64
#Sum_of_Luminosity int64
#Minimum_of_Luminosity int64
#Maximum_of_Luminosity int64
#Length_of_Conveyer int64
#TypeOfSteel_A300 int64
#TypeOfSteel_A400 int64
#Steel_Plate_Thickness int64
#Edges_Index float64
#Empty_Index float64
#Square_Index float64
#Outside_X_Index float64
#Edges_X_Index float64
#Edges_Y_Index float64
#Outside_Global_Index float64
#LogOfAreas float64
#Log_X_Index float64
#Log_Y_Index float64
#Orientation_Index float64
#Luminosity_Index float64
#SigmoidOfAreas float64
#Class int64
#dtype: object
train_df.head()
出力結果


train_df.describe()
出力結果


COUNTがそれぞれ970より欠損値は無いことが確認できる。
###5.5 訓練データを7:3に分割
#訓練データとテストデータに7:3に分割する
target = train_df["Class"]
#"Unnamed: 0","Class"列は削除
drop_col = ["Unnamed: 0","Class"]
train_df = train_df.drop(drop_col,axis=1)
X_train, X_val,y_train,y_val = train_test_split(
train_df,target,
test_size=0.3,shuffle=False,random_state=0)
###5.6 手順1での分類と結果
#Logistic回帰
model_Log = LogisticRegression()
model_Log.fit(X_train,y_train)
y_pred_Log = model_Log.predict(X_val)
print(accuracy_score(y_val,y_pred_Log))
#出力結果
0.4570446735395189
#線形SVM
model_SVM = LinearSVC()
model_SVM.fit(X_train,y_train)
y_pred_SVM = model_SVM.predict(X_val)
print(accuracy_score(y_val,y_pred_SVM))
#出力結果
0.371134020618556
#非線形SVM
model_SVM_1 = SVC()
model_SVM_1.fit(X_train,y_train)
y_pred_SVM_1 = model_SVM_1.predict(X_val)
print(accuracy_score(y_val,y_pred_SVM_1))
#出力結果
0.481099656357388
#k近傍法
model_k_NN = KNeighborsClassifier()
model_k_NN.fit(X_train,y_train)
y_pred_k_NN = model_k_NN.predict(X_val)
print(accuracy_score(y_val,y_pred_k_NN))
#出力結果
0.436426116838488
#決定木
model_Dec = DecisionTreeClassifier()
model_Dec.fit(X_train,y_train)
y_pred_Dec = model_Dec.predict(X_val)
print(accuracy_score(y_val,y_pred_Dec))
#出力結果
0.656357388
#ランダムフォレスト
model_Ran = RandomForestClassifier()
model_Ran.fit(X_train,y_train)
y_pred_Ran = model_Ran.predict(X_val)
print(accuracy_score(y_val,y_pred_Ran))
#出力結果
0.718213058
#Light GBM
model_LGB = lgb.LGBMClassifier()
model_LGB.fit(X_train, y_train)
y_pred_lgb = model_LGB.predict(X_val)
print(accuracy_score(y_val,y_pred_lgb))
#出力結果
0.7525773195876289
下表が手順1、Accuracy ScoreのBest3となります。
| 順位 | 分類方法 | 手順1 (調整無し) |
|---|---|---|
| 1 | Light GBM | 0.7525773 |
| 2 | ランダムフォレスト | 0.7182131 |
| 3 | 決定木 | 0.6563574 |
###5.7 手順2の実施
手順2ではデータクレンジングを行い、手順1のBest3の方法で分類していく。
まずは特徴量それぞれの相関を確認していく。
####5.7.1相関確認
#相関を見ていく
sns.heatmap(
train_df[['X_Minimum','X_Maximum','Y_Minimum','Y_Maximum','Pixels_Areas','X_Perimeter','Y_Perimeter','Sum_of_Luminosity','Minimum_of_Luminosity','Maximum_of_Luminosity','Length_of_Conveyer','TypeOfSteel_A300','TypeOfSteel_A400','Steel_Plate_Thickness','Edges_Index','Empty_Index','Square_Index','Outside_X_Index','Edges_X_Index','Edges_Y_Index','Outside_Global_Index','LogOfAreas','Log_X_Index','Log_Y_Index','Orientation_Index','Luminosity_Index','SigmoidOfAreas','Class']].corr(),
vmax=1,vmin=-1,annot=True,annot_kws = {'size':15}
)
plt.gcf().set_size_inches(70,20)
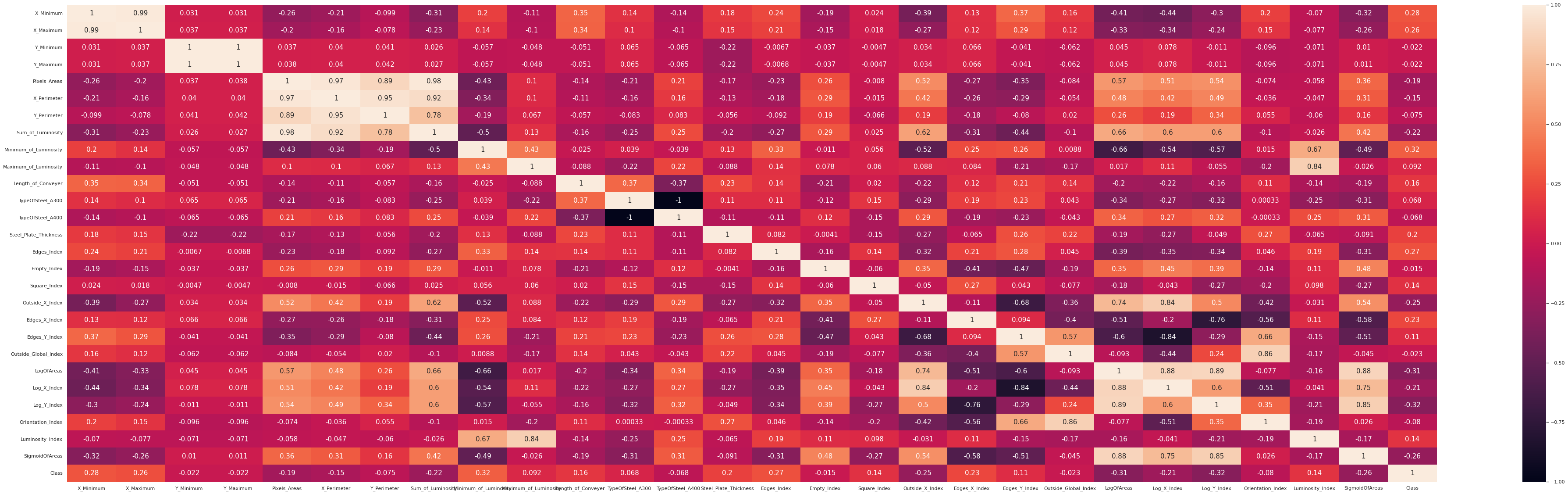
相関ヒートマップより説明変数の中に、相関係数が高い組み合わせが見られ、多重共線性の可能性がある。それによって過学習による精度低下が起こる可能性があるため、それらは特徴量を削除する。今回削除対象とするものは
相関係数 <= -0.88 AND 0.88 <= 相関係数
とする。
よって削除対象の下記7つを訓練データから削除。
#7つの特徴量を削除
drop_col=["X_Maximum","Y_Maximum","X_Perimeter","Sum_of_Luminosity","TypeOfSteel_A300","Y_Perimeter","LogOfAreas"]
train_df=train_df.drop(drop_col,axis=1)
####5.7.2 外れ値の確認と対策
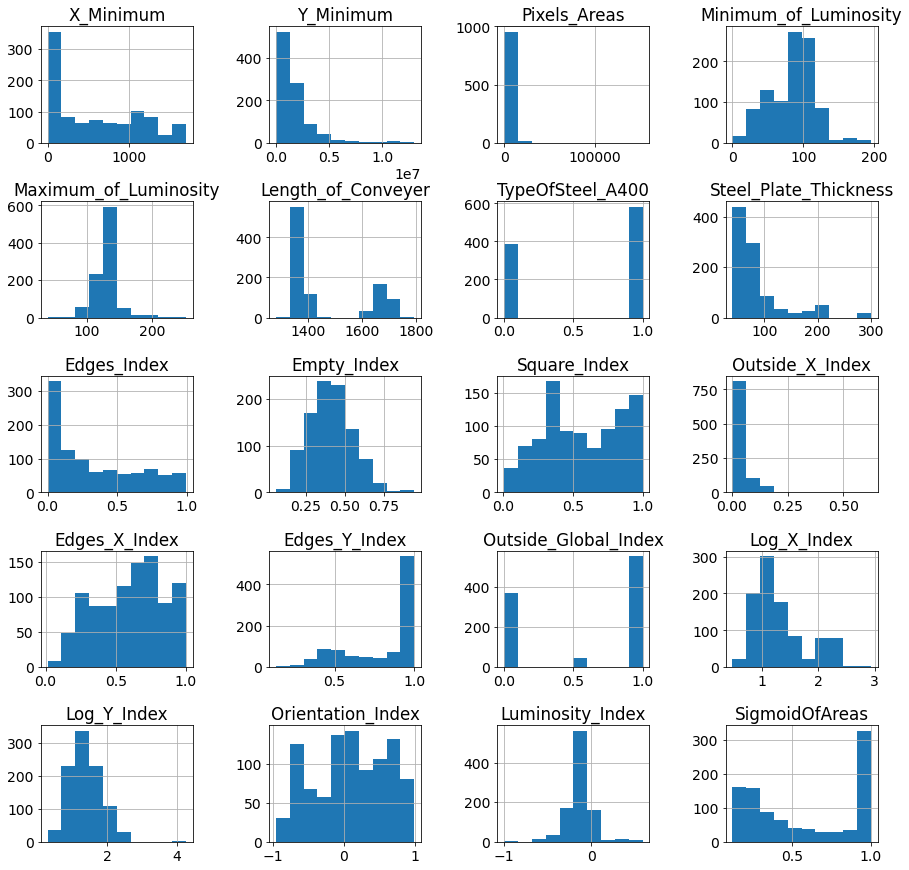
続いてヒストグラムとボックスプロットを用いて外れ値を確認する。
#ヒストグラム作成
train_df.hist(figsize=(15,15))
plt.subplots_adjust(wspace=0.5, hspace=0.5)
plt.show()
#Box plot作成
train_df.plot(kind='box', layout=(5,5),
subplots=True,sharex=False, sharey=False, figsize=(15,15) )
plt.subplots_adjust(wspace=0.5, hspace=0.5)
plt.show()

上記結果より、"Pixels_Areas","Log_Y_Index"に外れ値が存在する。外れ値が存在するとモデルの学習に悪影響を及ぼす可能性がある為、対策として数値データを特定の区間で分類し、カテゴリカル変数に変化させることにより、外れ値の影響を減らすことにする。今回は"Pixels_Areas","Log_Y_Index"それぞれ4つの区間に分類してカテゴリカル変数に変換する。
#カテゴリカル変数に変換
train_df['Pixels_Areas_qcut'] = pd.qcut(train_df['Pixels_Areas'], 4)
train_df['Log_Y_Index_qcut'] = pd.qcut(train_df['Log_Y_Index'], 4)
次に、カテゴリカル変数に対しOne-Hot Encodingを施し、モデルが扱えるよう変換する。One-Hot Encodingとは、各カテゴリカル変数に対して該当するカテゴリかどうかを0,1で表現したベクトルに変換する処理。
#One-Hot Encoding
train_df = pd.get_dummies(train_df, columns=['Log_Y_Index_qcut','Pixels_Areas_qcut'])
####5.7.3 手順2での分類と結果
特徴量作成が完了したので、予測モデルに学習させるために訓練データと検証データを作成後、手順1、Best3の手法で分類し、スコアを確認する。
#今回学習に用いないカラムを削除
drop_col_2 = ["Pixels_Areas","Log_Y_Index"]
train_df=train_df.drop(drop_col_2,axis=1)
#今回は訓練データとテストデータを9:1に分割する
X_train, X_val,y_train,y_val = train_test_split(
train_df,target,
test_size=0.1,shuffle=False,random_state=42)
#決定木
model_Dec = DecisionTreeClassifier()
model_Dec.fit(X_train,y_train)
y_pred_Dec = model_Dec.predict(X_val)
print(accuracy_score(y_val,y_pred_Dec))
#出力結果
0.6688659793814433
#ランダムフォレスト
model_Ran = RandomForestClassifier()
model_Ran.fit(X_train,y_train)
y_pred_Ran = model_Ran.predict(X_val)
print(accuracy_score(y_val,y_pred_Ran))
#出力結果
0.7422680412371134
#Light GBM
model_LGB = lgb.LGBMClassifier()
model_LGB.fit(X_train, y_train)
y_pred_lgb = model_LGB.predict(X_val)
print(accuracy_score(y_val,y_pred_lgb))
#出力結果
0.7731958762886598
下表が手順2でのAccuracy Scoreである。手順1よりも各分類方法で精度は上がっていることが分かる。
| 順位 | 分類方法 | 手順1 (調整無し) |
手順2 (データクレンジング) |
|---|---|---|---|
| 1 | Light GBM | 0.7525773 | 0.7731959 |
| 2 | ランダムフォレスト | 0.7182131 | 0.7182131 |
| 3 | 決定木 | 0.6563574 | 0.6688660 |
###5.8 手順3の分類と結果
手順3では手順2で最も精度の高い分類方法でハイパーパラメータチューニングを行う。
手順2よりLight GBMでのAccuracy Scoreが最も高いことが分かっている。よって、Light GBMのハイパーパラメータを調整することにより、更に精度を高めていくことする。今回はグリッドサーチにて調整したいハイパーパラメーターの値の候補を、明示的に複数指定してパラメーターセットを作成する。
# Light GBMのハイパーパラメーター候補値
paramG = {'num_leaves':[31, 50, 100],
'bagging_fraction':[0.1, 0.5, 1],
'min_child_samples':[0,5,100],
'max_depth':[4,5,6]
}
model_LGB = lgb.LGBMClassifier() #Light GBM
grid_search = GridSearchCV(model_LGB, param_grid=paramG, cv=3) #グリッドサーチ
grid_search.fit(X_train, y_train) #モデルの学習
print(grid_search.best_params_)
#出力結果
#{'bagging_fraction': 0.1, 'max_depth': 6, 'min_data_in_leaf': 5, 'num_leaves': 31}
上記結果から、LightGBMのハイパーパラメータを設定した場合のテストデータの結果を確認する。
# モデルの学習
model_LGB_grid = lgb.LGBMClassifier(num_leaves=31,bagging_fraction=0.1,min_child_sample=5,max_depth=6)
model_LGB_grid.fit(X_train, y_train) # モデルの学習
y_pred_lgb_test_grid = model_LGB_OK.predict(X_val)
print(accuracy_score(y_val,y_pred_lgb_test_grid))
#出力結果
0.7938144329896907
ハイパーパラメータを調整することにより更に精度の高い正解率となった。
5.9.テストデータの予測と結果の保存
SIGNATEへ投票するにあたり、testデータを予測し、提出用ファイルに保存します。
#testデータの読み込みと前処理
test_df = pd.read_csv("/~~//test_steel.csv")
test_df = test_df.drop(drop_col,axis=1)
test_df['Pixels_Areas_qcut'] = pd.qcut(test_df['Pixels_Areas'], 4)
test_df['Log_Y_Index_qcut'] = pd.qcut(test_df['Log_Y_Index'], 4)
test_df = pd.get_dummies(test_df, columns=['Log_Y_Index_qcut','Pixels_Areas_qcut'])
test_df = test_df.drop(drop_col_2,axis=1)
test_df = test_df.drop("Unnamed: 0",axis=1)
#testデータの予測
y_pred_lgb_test = model_LGB.predict(test_df)
#提出データの読み込み
submit_df = pd.read_csv("/~~/sample_submit.csv",header=None)
#提出データの編集と書き込み
data_df = pd.DataFrame(y_pred_lgb_test)
data_df.reset_index(drop=True, inplace=True)
submit_df[1]=data_df[0]
submit_df.to_csv("/~~/sample_submit.csv",index=False,header=None)
#6. 結果
手順1,2,3より、データの調整無しから、データクレンジング後、ハイパーパラメータを調整することにより、LightGBMではAccuracy Scoreを0.7525→0.7938まで上げることができ、精度を高めることができました。
| 分類方法 | 手順1 (調整無し) |
手順2 (データクレンジング) |
手順3 (ハイパーパラメータ調整) |
|---|---|---|---|
| Light GBM | 0.7525773 | 0.7731959 | 0.7938144 |
| ランダムフォレスト | 0.7182131 | 0.7422680 | -------------------- |
| 決定木 | 0.6563574 | 0.6688660 | -------------------- |
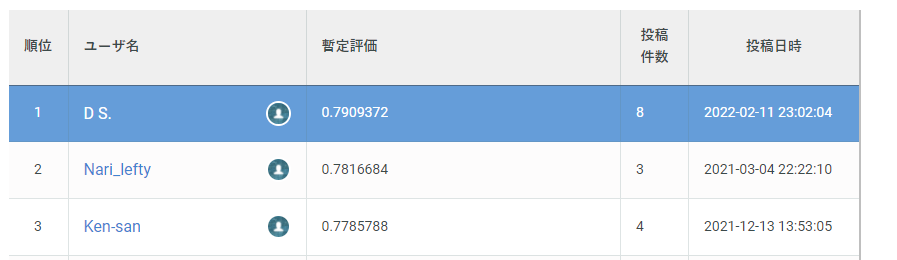
また下図よりSIGNATEへの投票結果は0.7909372より、目標通り1位を獲得することができました。(2022/02/11時点)
#7. 終わりに
今回ステンレス板の欠陥分類を行い、データ分析における精度を高めていくために、適切なデータの前処理、分類方法の適切な選定、またハイパーパラメータの適切な設定がそれぞれ非常に重要であることが分かりました。それが一つでも欠けることにより、精度が低くなってしまうため、今後も上記に気を付けて解析をしていきます。