背景
最近音声認識に興味があり、調べるといろいろとできるようになってきているようなので、
わかりやすい例として、音声からテキスト化する自動議事録を作ってみました。
やってみてうまくいったところ、課題が見えたので備忘録も込めて残しておきます。
開発環境
macOS Mojave 10.14.5
MacBook Air (13-inch, Early 2015)
Python 3.6.8 :: Anaconda custom (64-bit)
環境構築
以下のサイトを参考にさせていただきました。
Pythonで音声入力に入門しよう(SpeechRecognition)
python + SpeechRecognitionでマイクの音声をテキストにする
参考サイトに沿ってそのままインストール。
# モジュールのインストール
$ pip install SpeechRecognition
# マイクロホンからの入力に必要
$ sudo apt-get install portaudio19-dev
$ sudo apt-get install python-pyaudio python3-pyaudio
$ pip install pyaudio
インストールの確認をするために以下のコマンドで確認。
$ python -m speech_recognition
そうすると、下記のような表示がされます。
A moment of silence, please...
Set minimum energy threshold to 284.54005417070454
Say something!
何か言えと聞かれるのであいさつ(これは英語じゃないといけないみたい)。
Got it! Now to recognize it...
You said how are you
認識されました!
これで環境構築はできていそう。
この手の環境構築は結構大変ですが、今回は簡単にできました。
音声認識
これを踏まえて、pythonでスクリプトを記述しました。
import speech_recognition as sr
r = sr.Recognizer()
mic = sr.Microphone()
while True:
print("Say something ...")
with mic as source:
r.adjust_for_ambient_noise(source) #雑音対策
audio = r.listen(source)
print ("Now to recognize it...")
try:
print(r.recognize_google(audio, language='ja-JP'))
# "ストップ" と言ったら音声認識を止める
if r.recognize_google(audio, language='ja-JP') == "ストップ" :
print("end")
break
# 以下は認識できなかったときに止まらないように。
except sr.UnknownValueError:
print("could not understand audio")
except sr.RequestError as e:
print("Could not request results from Google Speech Recognition service; {0}".format(e))
これを実行してmacに向かっていろいろと話してみました。
$ python3 test.py
Say something ...
Now to recognize it...
あいうえお
Say something ...
Now to recognize it...
フットボールクラブ バルセロナはカタルーニャ州のバルセロナをホームタウンとする スポーツクラブ
Say something ...
Now to recognize it...
could not understand audio
Say something ...
Now to recognize it...
さよなら
Say something ...
Now to recognize it...
ストップ ストップ
Say something ...
Now to recognize it...
ストップ
end
きちんと認識してテキスト化してくれました!
うまく聞き取れていないところもありましたが、
ちょっとした文章もきれいにテキスト化されています。
テキストデータ化
ここまではコマンドプロンプト上でのやりとりに過ぎなかったのですが、
これをきちんとテキスト保存するようにしたのが下記になります。
# coding:utf-8
import speech_recognition as sr
from datetime import datetime
# 文字起こしファイルのファイル名を日付のtxtファイルとする
filename = datetime.now().strftime('%Y%m%d_%H:%M:%S')
txt =filename +".txt"
with open(txt, 'w') as f: #txtファイルの新規作成
f.write(filename + "\n") #最初の一行目にはfilenameを記載する
r = sr.Recognizer()
mic = sr.Microphone()
while True:
print("Say something ...")
with mic as source:
r.adjust_for_ambient_noise(source) #雑音対策
audio = r.listen(source)
print ("Now to recognize it...")
try:
print(r.recognize_google(audio, language='ja-JP'))
# "ストップ" と言ったら音声認識を止める
if r.recognize_google(audio, language='ja-JP') == "ストップ" :
print("end")
break
with open(txt,'a') as f: #ファイルの末尾に追記していく
f.write("\n" + r.recognize_google(audio, language='ja-JP'))
# 以下は認識できなかったときに止まらないように。
except sr.UnknownValueError:
print("could not understand audio")
except sr.RequestError as e:
print("Could not request results from Google Speech Recognition service; {0}".format(e))
実行結果はこちら。テキストファイル作成のため、sudoでの実行が必要になる。
sudo python3 test3.py
Say something ...
Now to recognize it...
こんにちは
Say something ...
Now to recognize it...
お腹空いた
Say something ...
Now to recognize it...
レアルマドリードはスペインのマドリードをホームタウンにするバルセロナのライバルチームである
Say something ...
Now to recognize it...
両者の戦いは エルクラシコと言われ 伝統の一戦として世界中の人から注目される
Say something ...
Now to recognize it...
おしまい ストップ ストップ
Say something ...
Now to recognize it...
ストップ
end
音声認識は先ほどと同様にできていそう。
実際にテキストファイルとして吐き出されたのがこちら。
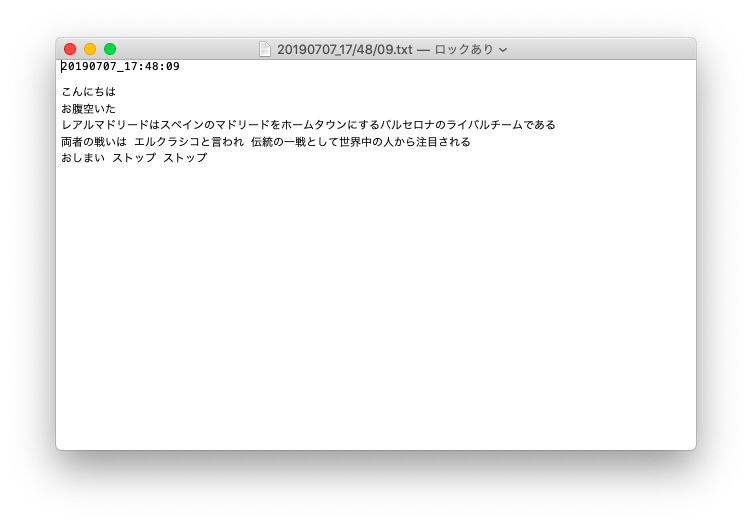
できた!!
ファイル名は20190707_17/48/09.txt
1行目にfilename(20190707_17:48:09)
3行目以降に認識された言葉のみテキスト化されている。
ちなみに、コマンド上で”could not understand audio”となって
認識できなかった言葉はテキスト化されておらず、
きちんと認識された言葉のみテキスト化されています。
今後の課題
普通に話しても認識してくれるのでとてもいいです。
ただし、聞き取り〜認識〜テキスト変換〜書き込みまでが時間かかっているので、
うまく高速化してあげないと、次の言葉を聞き逃してしまいそう。
その辺りが今後の課題です。