概要
BoTorchを使った多目的ベイズ最適化の記事があまりなかったのでメモ程度にチュートリアルをまとめます.
BoTorchの説明自体はベイズ最適化ツールBoTorch入門が分かりやすいと思います.
多目的ベイズ最適化
パレート解
$k$個の目的変数からなる空間上において, 2点 $\boldsymbol{y} = (y_1, \ldots, y_k)^{\top}$ , $\boldsymbol{y}'=(y'_1, \ldots, y'_k)^{\top}$について
\boldsymbol{y} \succeq \boldsymbol{y}' \Leftrightarrow \forall i\, \,y_i \le y'_i
の関係を$\boldsymbol{y}$は$\boldsymbol{y}'$を支配していると言います. (最小化問題の場合)
目的変数空間上で$\boldsymbol{y}$がどの点にも支配されないとき, $\boldsymbol{y}$はパレート解と呼びます.
多目的ベイズ最適化の目的は, より少ない探索回数で全てのパレート解を見つけることです.
ベイズ最適化では, 活用と探索のトレードオフをうまく汲み取った獲得関数を設計し, 獲得関数に基づいて次の実験候補点を提案します.
ここでは, 多目的ベイズ最適化においてよく使われるEHVIを使います.
Expected Hyper-volume Improvement (EHVI)
[Michael Emmerich, et, al.,]
EHVIのアイデアは、パレート超体積の増加量の期待値が最大の点を獲得することです.
※ パレート超体積の厳密な説明は論文を参照してください.
現在の観測データ中のパレート解集合を$Y^*$としたときのパレート超体積を$I_H(Y^*)$としたとき, 新たな観測データ$(\boldsymbol{x}, \boldsymbol{y})$を加えたときのパレート超体積の増加量の期待値は以下で定義されます.
\begin{align}
EHVI_{Y^*}(\boldsymbol{x})
= \int
\underbrace{(I_H(Y^* \cup \boldsymbol{y}) - I_H(Y^*))}_{データを追加したときの超体積の増加量}p(\boldsymbol{y}|\boldsymbol{x})
d\boldsymbol{y}
\end{align}
ここで, $p(\boldsymbol{y}|\boldsymbol{x})$は一般的にはガウス過程を使って推定される分布になります.
$EHVI_{Y^*}(\boldsymbol{x})$を最大化する$\boldsymbol{x}$を次の探索点とします.
※ MOTPE [Yoshihiko Ozaki, et, al.,]でもこれと等価なことができます.
BoTorchでのデモ
BoTorchのサンプル関数であるBraninCurrinで実験します.
※ 目的変数2つ. 説明変数2つ
\begin{align}
f_1 &=
\left(
15x_1 - 5.1(15x_0-5)^{\frac{2}{4\pi^2}} + 5\frac{15x_0 - 5}{\pi}-5
\right)^2
+
\left(
10 - \frac{10}{8\pi}
\right)
\cos(15x_0 - 5)\\
f_2 &=
\left(
1 - e^{-\frac{1}{2x_1}}
\right)
\frac{2300x_0^3+1900x_0^2+2092x_0+60}{100}
\end{align}
目的関数を定義します.
import torch
from botorch.test_functions.multi_objective import BraninCurrin
tkwargs = {
"dtype": torch.double,
"device": torch.device("cuda" if torch.cuda.is_available() else "cpu"),
}
problem = BraninCurrin(negate=True).to(**tkwargs)
観測する際はノイズを乗せて観測しています.
botorch.test_functionsに目的関数のサンプルが複数用意されています.
初期観測データを生成する関数を準備します.
from botorch.utils.sampling import draw_sobol_samples
NOISE_SE = torch.tensor([15.19, 0.63]).to(**tkwargs)
def generate_initial_data(problem, n=5):
"""観測データの生成関数"""
train_x = draw_sobol_samples(bounds=problem.bounds,n=n, q=1).squeeze(1) #サンプリング
train_obj_true = problem(train_x)
train_obj = train_obj_true + torch.randn_like(train_obj_true) * NOISE_SE # ノイズを乗せて観測
return train_x, train_obj, train_obj_true
draw_sobol_samplesはboundで定義された区間からサンプルを任意の個数バッチで生成します.
ガウス過程のモデルを定義(初期化)するを準備します.
from botorch.models.gp_regression import FixedNoiseGP
from botorch.models.model_list_gp_regression import ModelListGP
from gpytorch.mlls.sum_marginal_log_likelihood import SumMarginalLogLikelihood
from botorch.utils.transforms import unnormalize, normalize
from botorch.models.transforms.outcome import Standardize
def initialize_model(problem, train_x, train_obj):
"""ガウス過程モデルを定義(初期化)"""
train_x = normalize(train_x, problem.bounds)
models = []
# 各目的変数ごとに独立したガウス過程モデルを定義
for i in range(train_obj.shape[-1]):
train_y = train_obj[..., i:i+1]
train_yvar = torch.full_like(train_y, NOISE_SE[i] ** 2)
models.append(
# カーネルはデフォルトのMatern Kernelを利用
FixedNoiseGP(train_x, train_y, train_yvar, outcome_transform=Standardize(m=1))
)
model = ModelListGP(*models)
mll = SumMarginalLogLikelihood(model.likelihood, model)
return mll, model
各出力に対し独立したガウス過程を仮定したモデルをModelListGPを使って定義しています.
独立なガウス過程を仮定しているので, モデル全体の周辺対数尤度は各モデルの周辺対数尤度の合計になります.
SumMarginalLogLikelihoodの内部では, デフォルトではgpytorch.mlls.ExactMarginalLogLikelihoodで各モデルの周辺対数尤度を取得し合計しています.
ここで計算した周辺対数尤度mllをbotorch.fit_gpytorch_mllに渡すことでモデルのフィッティングが行われます.
獲得関数(EHVI)を最大にする候補点を観測する関数を準備します.
from botorch.optim.optimize import optimize_acqf, optimize_acqf_list
from botorch.acquisition.objective import GenericMCObjective
from botorch.utils.multi_objective.scalarization import get_chebyshev_scalarization
from botorch.utils.multi_objective.box_decompositions.non_dominated import FastNondominatedPartitioning
from botorch.acquisition.multi_objective.monte_carlo import qExpectedHypervolumeImprovement, qNoisyExpectedHypervolumeImprovement
from botorch.utils.sampling import sample_simplex
BATCH_SIZE = 3
NUM_RESTARTS = 10
RAW_SAMPLES = 512
standard_bounds = torch.zeros(2, problem.dim, **tkwargs)
standard_bounds[1] = 1
def optimize_qehvi_and_get_observation(problem, model, train_x, train_obj, sampler):
"""EHVIを最大化する点を取得"""
# パレート超体積を計算するためのpartitionを計算
with torch.no_grad():
pred = model.posterior(normalize(train_x, problem.bounds)).mean
partitioning = FastNondominatedPartitioning(
ref_point=problem.ref_point,
Y=pred,
)
# 獲得関数(EHVI)を定義
acq_func = qExpectedHypervolumeImprovement(
model=model,
ref_point=problem.ref_point,
partitioning=partitioning,
sampler=sampler,
)
# 候補点を取得
candidates, _ = optimize_acqf(
acq_function=acq_func,
bounds=standard_bounds,
q=BATCH_SIZE, # 獲得する候補点数
num_restarts=NUM_RESTARTS,
raw_samples=RAW_SAMPLES, # 初期値探索に用いる乱数の数
options={"batch_limit": 5, "maxiter": 200},
sequential=True,
)
# 候補点の目的関数の値を観測
new_x = unnormalize(candidates.detach(), bounds=problem.bounds)
new_obj_true = problem(new_x)
new_obj = new_obj_true + torch.randn_like(new_obj_true) * NOISE_SE
return new_x, new_obj, new_obj_true
botorch.acquisition.multi_objectiveに多目的ベイズ最適化の獲得関数が準備されています.
BoTorchの獲得関数には, 解析的獲得関数(Analytic Acquisition Function)とモンテカルロ獲得関数(Monte-Carlo Acquisition Function)の2種類があり, モンテカルロ獲得関数にはqがついています.
ここでは, モンテカルロ獲得関数であるqExpectedHypervolumeImprovementを利用しています.
qExpectedHypervolumeImprovementでは, 非占有空間(どのパレート解にも支配されていない空間)をハイパーセルに分割するクラスであるpartitioningが必要であるため, まず定義域内の事後分布$p(\boldsymbol{y}|\boldsymbol{x})$の平均を学習済みのガウス過程で推定し, FastNondominatedPartitioningでハイパーセルに分割しています.
定義した獲得関数をbotorch.optim.optimize_acqfに渡して獲得関数の値を最大化する候補点を取得します.
以上で準備した関数を用いてシミュレレーションを行います.
初期点としてランダムに5点観測したところから開始します.
import time
import warnings
from botorch import fit_gpytorch_mll
from botorch.exceptions import BadInitialCandidatesWarning
from botorch.sampling.normal import SobolQMCNormalSampler
from botorch.utils.multi_objective.box_decompositions.dominated import (
DominatedPartitioning,
)
from botorch.utils.multi_objective.pareto import is_non_dominated
warnings.filterwarnings("ignore", category=BadInitialCandidatesWarning)
warnings.filterwarnings("ignore", category=RuntimeWarning)
N_BATCH = 20
MC_SAMPLES = 128
verbose = True
# 初期観測データを5点生成
train_x, train_obj, train_obj_true = generate_initial_data(problem, n=5)
train_x_qehvi, train_obj_qehvi, train_obj_true_qehvi = (
train_x,
train_obj,
train_obj_true,
)
train_x_random, train_obj_random, train_obj_true_random = (
train_x,
train_obj,
train_obj_true,
)
# ガウス過程モデル初期化
mll_qehvi, model_qehvi = initialize_model(problem, train_x_qehvi, train_obj_qehvi)
# 初期のパレート超体積計算
hvs_qehvi, hvs_random = [], []
bd = DominatedPartitioning(ref_point=problem.ref_point, Y=train_obj_true)
volume = bd.compute_hypervolume().item()
hvs_qehvi.append(volume)
hvs_random.append(volume)
# シミュレーション開始
for iteration in range(1, N_BATCH + 1):
# ガウス過程のfitting
fit_gpytorch_mll(mll_qehvi)
# EHVIの数値積分のsampler定義(Quasi Monte Calro Method)
qehvi_sampler = SobolQMCNormalSampler(sample_shape=torch.Size([MC_SAMPLES]))
# 獲得関数を最大化する候補点取得
new_x_qehvi, new_obj_qehvi, new_obj_true_qehvi = optimize_qehvi_and_get_observation(
problem, model_qehvi, train_x_qehvi, train_obj_qehvi, qehvi_sampler
)
# 比較用にランダムで観測点取得
new_x_random, new_obj_random, new_obj_true_random = generate_initial_data(
problem, n=BATCH_SIZE
)
# 観測データを追加
train_x_qehvi = torch.cat([train_x_qehvi, new_x_qehvi])
train_obj_qehvi = torch.cat([train_obj_qehvi, new_obj_qehvi])
train_obj_true_qehvi = torch.cat([train_obj_true_qehvi, new_obj_true_qehvi])
train_x_random = torch.cat([train_x_random, new_x_random])
train_obj_random = torch.cat([train_obj_random, new_obj_random])
train_obj_true_random = torch.cat([train_obj_true_random, new_obj_true_random])
# 経過更新
for hvs_list, train_obj in zip(
(hvs_random, hvs_qehvi),
(
train_obj_true_random,
train_obj_true_qehvi,
),
):
# パレート超体積再計算
bd = DominatedPartitioning(ref_point=problem.ref_point, Y=train_obj)
volume = bd.compute_hypervolume().item()
hvs_list.append(volume)
# 観測データを加えて新たにガウス過程モデルを初期化
mll_qehvi, model_qehvi = initialize_model(problem, train_x_qehvi, train_obj_qehvi)
# 経過表示
print(f'Batch {iteration}: Hypervolume (random, qEHVI)=({hvs_random[-1]:>4.2f}, {hvs_qehvi[-1]:>4.2f})')
Batch 1: Hypervolume (random, qEHVI)=(0.10, 0.10)
Batch 2: Hypervolume (random, qEHVI)=(0.10, 2.37)
Batch 3: Hypervolume (random, qEHVI)=(0.10, 2.37)
Batch 4: Hypervolume (random, qEHVI)=(0.10, 18.62)
Batch 5: Hypervolume (random, qEHVI)=(0.10, 23.15)
Batch 6: Hypervolume (random, qEHVI)=(0.10, 35.00)
Batch 7: Hypervolume (random, qEHVI)=(0.10, 46.87)
Batch 8: Hypervolume (random, qEHVI)=(0.10, 50.50)
Batch 9: Hypervolume (random, qEHVI)=(0.10, 52.73)
Batch 10: Hypervolume (random, qEHVI)=(0.10, 53.91)
Batch 11: Hypervolume (random, qEHVI)=(0.10, 53.96)
Batch 12: Hypervolume (random, qEHVI)=(0.10, 54.17)
Batch 13: Hypervolume (random, qEHVI)=(0.10, 54.17)
Batch 14: Hypervolume (random, qEHVI)=(0.10, 54.30)
Batch 15: Hypervolume (random, qEHVI)=(0.10, 54.36)
Batch 16: Hypervolume (random, qEHVI)=(0.10, 54.47)
Batch 17: Hypervolume (random, qEHVI)=(0.10, 55.20)
Batch 18: Hypervolume (random, qEHVI)=(0.10, 55.41)
Batch 19: Hypervolume (random, qEHVI)=(0.10, 55.56)
Batch 20: Hypervolume (random, qEHVI)=(0.10, 55.89)
ランダム探索と比較し, EHVI最大化の方が早い段階からパレート超体積が増加していることがわかります.
目的変数の観測結果を可視化
from matplotlib import pyplot as plt
from matplotlib.cm import ScalarMappable
fig, axes = plt.subplots(1, 2, figsize=(20, 7), sharex=True, sharey=True)
algos = ["Random", "qEHVI"]
cm = plt.cm.get_cmap('viridis')
batch_number = torch.cat([torch.zeros(5), torch.arange(1, N_BATCH+1).repeat(BATCH_SIZE, 1).t().reshape(-1)]).numpy()
for i, train_obj in enumerate((train_obj_true_random, train_obj_true_qehvi)):
sc = axes[i].scatter(
train_obj[:, 0].cpu().numpy(), train_obj[:,1].cpu().numpy(), c=batch_number, alpha=0.8,
)
axes[i].set_title(algos[i])
axes[i].set_xlabel(r"$f_1$")
axes[0].set_ylabel(r"$f_2$")
norm = plt.Normalize(batch_number.min(), batch_number.max())
sm = ScalarMappable(norm=norm, cmap=cm)
sm.set_array([])
fig.subplots_adjust(right=0.9)
cbar_ax = fig.add_axes([0.93, 0.15, 0.01, 0.7])
cbar = fig.colorbar(sm, cax=cbar_ax)
cbar.ax.set_title("Iteration")
plt.show()
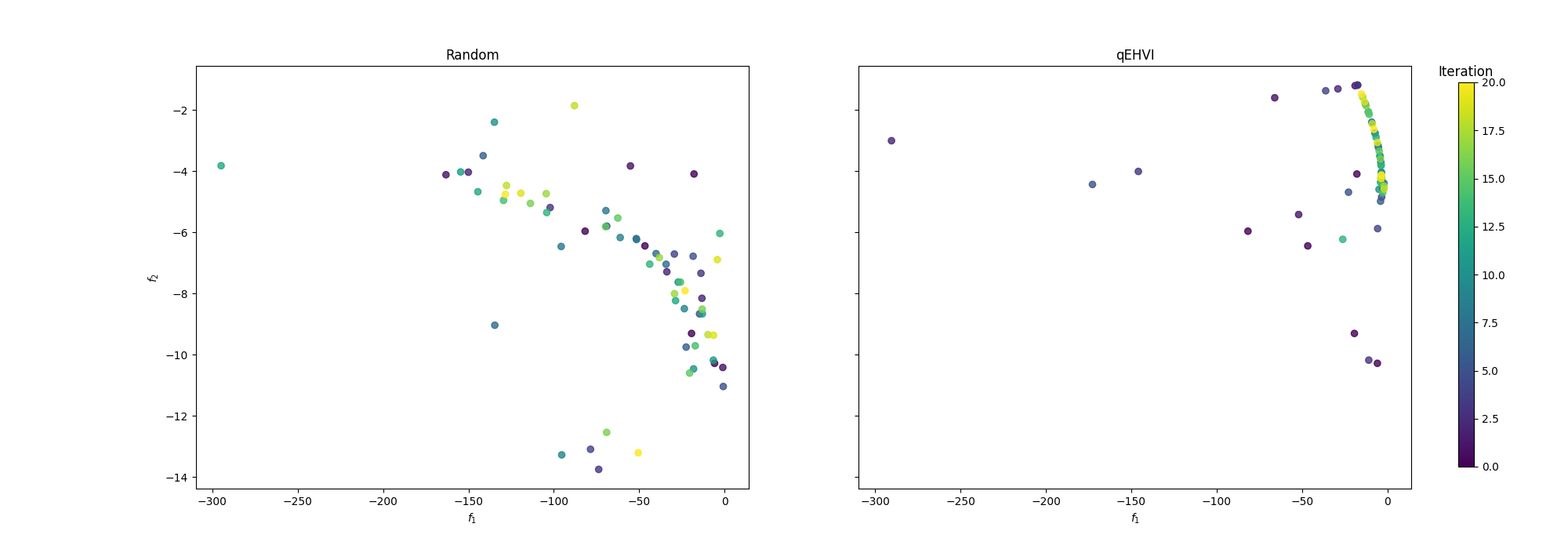
※ プロットの際は, パレートフロントを取得できているかわかりやすくするためにノイズなしの観測データをプロットしています.