Llamaについて
Metaの公式サイト↓
llamaをローカルに入れたくて最初に目にした公式のページ
ここで入れる物の使い方が分からなかった。githubやmetaにはllamaのインストール方法が書かれていても実際に使う方法が見つからない。ネットには素晴らしさの説明が溢れていても使う方法が書かれていなかった。
環境
os win11
llama sitackについて
公式の手順通りにやるとおそらく皆さんpythonで下の手順通りに進めることとなると思う。
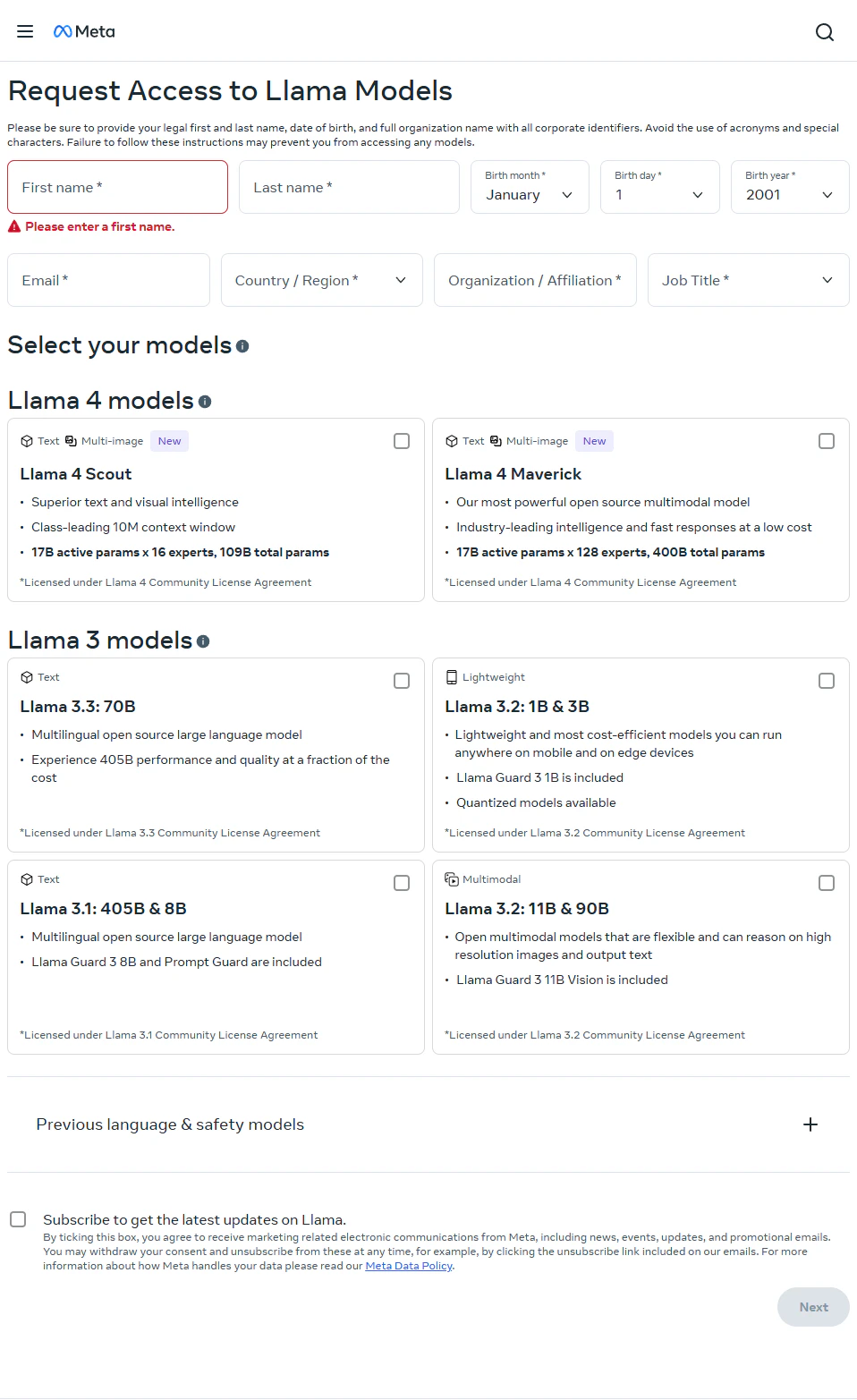
好きなモデルや情報を色々打ち込みサイトに到達。
pip install llama-stack
pip install llama-stack -U
下は利用できるモデルの一覧を見て、
llama model list
llama model list --show-all
--show-allでは2系も含めてすべてのモデル一覧が出るが、わざわざ古いモデルまで表示されてもこまるので
llama model listだけでいいと思う。
(llama) PS C:\Users\kug> llama model list
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┓
┃ Model Descriptor(ID) ┃ Hugging Face Repo ┃ Context Length ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━┩
│ Llama3.1-8B │ meta-llama/Llama-3.1-8B │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama3.1-70B │ meta-llama/Llama-3.1-70B │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama3.1-405B:bf16-mp8 │ meta-llama/Llama-3.1-405B │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama3.1-405B │ meta-llama/Llama-3.1-405B-FP8 │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama3.1-405B:bf16-mp16 │ meta-llama/Llama-3.1-405B │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama3.1-8B-Instruct │ meta-llama/Llama-3.1-8B-Instruct │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama3.1-70B-Instruct │ meta-llama/Llama-3.1-70B-Instruct │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama3.1-405B-Instruct:bf16-mp8 │ meta-llama/Llama-3.1-405B-Instruct │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama3.1-405B-Instruct │ meta-llama/Llama-3.1-405B-Instruct-FP8 │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama3.1-405B-Instruct:bf16-mp16 │ meta-llama/Llama-3.1-405B-Instruct │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama3.2-1B │ meta-llama/Llama-3.2-1B │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama3.2-3B │ meta-llama/Llama-3.2-3B │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama3.2-11B-Vision │ meta-llama/Llama-3.2-11B-Vision │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama3.2-90B-Vision │ meta-llama/Llama-3.2-90B-Vision │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama3.2-1B-Instruct │ meta-llama/Llama-3.2-1B-Instruct │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama3.2-3B-Instruct │ meta-llama/Llama-3.2-3B-Instruct │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama3.2-1B-Instruct:int4-qlora-eo8 │ meta-llama/Llama-3.2-1B-Instruct-QLORA… │ 8K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama3.2-1B-Instruct:int4-spinquant-eo8 │ meta-llama/Llama-3.2-1B-Instruct-SpinQ… │ 8K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama3.2-3B-Instruct:int4-qlora-eo8 │ meta-llama/Llama-3.2-3B-Instruct-QLORA… │ 8K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama3.2-3B-Instruct:int4-spinquant-eo8 │ meta-llama/Llama-3.2-3B-Instruct-SpinQ… │ 8K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama3.2-11B-Vision-Instruct │ meta-llama/Llama-3.2-11B-Vision-Instru… │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama3.2-90B-Vision-Instruct │ meta-llama/Llama-3.2-90B-Vision-Instru… │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama3.3-70B-Instruct │ meta-llama/Llama-3.3-70B-Instruct │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama-4-Scout-17B-16E │ meta-llama/Llama-4-Scout-17B-16E │ 256K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama-4-Maverick-17B-128E │ meta-llama/Llama-4-Maverick-17B-128E │ 256K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama-4-Scout-17B-16E-Instruct │ meta-llama/Llama-4-Scout-17B-16E-Instr… │ 10240K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama-4-Maverick-17B-128E-Instruct │ meta-llama/Llama-4-Maverick-17B-128E-I… │ 1024K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama-4-Maverick-17B-128E-Instruct:fp8 │ meta-llama/Llama-4-Maverick-17B-128E-I… │ 1024K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama-Guard-3-11B-Vision │ meta-llama/Llama-Guard-3-11B-Vision │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama-Guard-3-1B:int4 │ meta-llama/Llama-Guard-3-1B-INT4 │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama-Guard-3-1B │ meta-llama/Llama-Guard-3-1B │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama-Guard-3-8B │ meta-llama/Llama-Guard-3-8B │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama-Guard-3-8B:int8 │ meta-llama/Llama-Guard-3-8B-INT8 │ 128K │
├─────────────────────────────────────────┼─────────────────────────────────────────┼────────────────┤
│ Llama-Guard-2-8B │ meta-llama/Llama-Guard-2-8B │ 4K │
└─────────────────────────────────────────┴─────────────────────────────────────────┴────────────────┘
今回はとりあえずLlama3.2-3B-Instruct。
llama model download --source meta --model-id Llama3.2-3B-Instruct
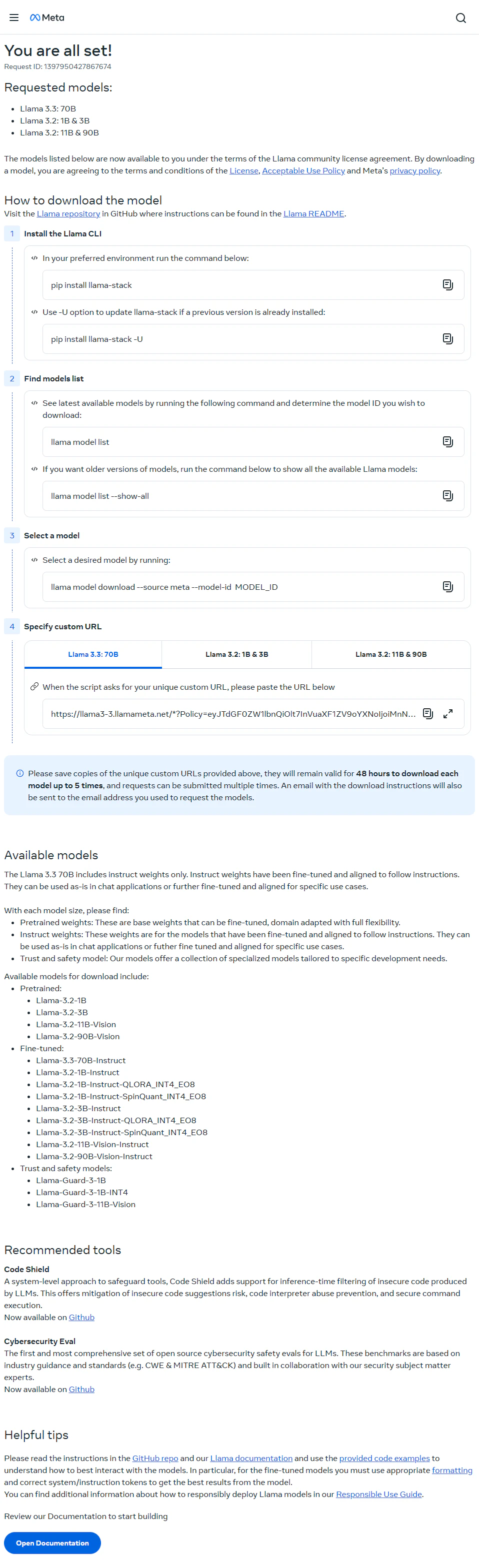
指示に従うとllama model download --source meta --model-id MODEL_IDを打ち込むことになるが、MODEL_IDは自分で変えて、
(llama) PS C:\Users\kug> llama model download --source meta --model-id Llama3.2-3B-Instruct
Please provide the signed URL for model Llama3.2-3B-Instruct you received via email after visiting https://www.llama.com/llama-downloads/ (e.g., https://llama3-1.llamameta.net/*?Policy...):
48時間以内かつ5回までこのurlを使い
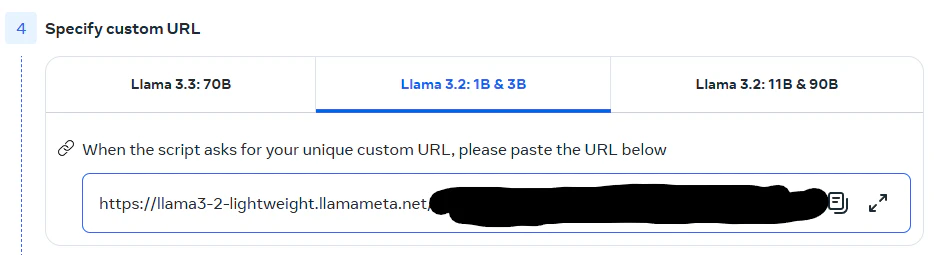
大事なものなのでメモを取るか、メールアドレスに送られてくるものを控えて、
インストールはこれで終わり。
正常にインストールされたか検証し、
正常にインストールできていればllamaでコマンドが通る。
(llama) PS C:\Users\kug> llama
usage: llama [-h] {model,stack,download,verify-download} ...
Welcome to the Llama CLI
options:
-h, --help show this help message and exit
subcommands:
{model,stack,download,verify-download}
model Work with llama models
stack Operations for the Llama Stack / Distributions
download Download a model from llama.meta.com or Hugging Face Hub
verify-download Verify integrity of downloaded model files
(ちなみにややこしいですが、今出てるLlama CLIとllama_cliは別物。
llama_cliはllama.cppからインストールすることにより使えるコマンドラインツールとかなんとか)
(llama) PS C:\Users\kug> llama model verify-download --model-id Llama3.2-3B-Instruct
Verification Results:
✓ consolidated.00.pth: Verified
❌ orig_params.json: File not found
✓ params.json: Verified
✓ tokenizer.model: Verified
指示通りにllama model verify-download --model-id Llama3.2-3B-Instructを実行すると何やらファイルが足りないため
上のサイトにファイルをダウンロード。※アカウントを作成する必要あり
C:\Users\kug\.llama\checkpoints\Llama3.2-3B-Instruct
適切な場所に入れる。
多分どこに入れていてもホームディレクトリに.llamaが入ることになるはず。
(llama) PS C:\Users\kug> llama model verify-download --model-id Llama3.2-3B-Instruct
Verification Results:
✓ consolidated.00.pth: Verified
✓ orig_params.json: Verified
✓ params.json: Verified
✓ tokenizer.model: Verified
All files verified successfully!
手順通りにいけた。
llama stackを用いてapiを利用する
ここまでがサイト通りなのだが、ここからどうすれば良いのか書かれていない。
ここまで何をしていたのか分からなかったが、llamaのモデルをllama stackを用いてダウンロードしていたということ。この流れでllamaをローカル環境で使うにはllama stackを介してapiでやり取りを行うこととなる。
pythonを用いて行う。
色々試している人がいたので参考にしました。
llama stack buildを実行。
いくつか入力する必要があります。
Enter a name for your Llama Stack (e.g. my-local-stack):
(Optional) Enter a short description for your Llama Stack: my first time use llama stack
この2つは自由入力
他はよくわからないのでvenv、そのほかはmeta-referenceかinlineを選びました。tabキーを押すと選択肢が出てきます。
(llama) PS C:\Users\kug\OneDrive\Desktop\llamastacktest> llama stack build
> Enter a name for your Llama Stack (e.g. my-local-stack): myllama
> Enter the image type you want your Llama Stack to be built as (conda or container or venv): venv
Llama Stack is composed of several APIs working together. Let's select
the provider types (implementations) you want to use for these APIs.
Tip: use <TAB> to see options for the providers.
> Enter provider for API inference: inline::meta-reference
> Enter provider for API safety: inline::prompt-guard
> Enter provider for API agents: inline::meta-reference
> Enter provider for API vector_io: inline::meta-reference
> Enter provider for API datasetio: inline::localfs
> Enter provider for API scoring: inline::basic
> Enter provider for API eval: inline::meta-reference
> Enter provider for API post_training: inline::torchtune
> Enter provider for API tool_runtime: inline::rag-runtime
> Enter provider for API telemetry: inline::meta-reference
> (Optional) Enter a short description for your Llama Stack: my first time use llama stack
ERROR 2025-04-14 00:43:37,141 llama_stack.distribution.utils.exec:135 uncategorized: Unexpected error: [WinError 193]
%1 は有効な Win32 アプリケーションではありません。
╭───────────────────────────────────── Traceback (most recent call last) ─────────────────────────────────────╮
│ C:\Users\kug\llama\Lib\site-packages\llama_stack\distribution\utils\exec.py:125 in run_command │
│ │
│ 122 │ │ signal.signal(signal.SIGINT, sigint_handler) │
│ 123 │ │ │
│ 124 │ │ # Run the command with stdout/stderr piped directly to system streams │
│ ❱ 125 │ │ result = subprocess.run( │
│ 126 │ │ │ command, │
│ 127 │ │ │ text=True, │
│ 128 │ │ │ check=False, │
│ │
│ C:\Program │
│ Files\WindowsApps\PythonSoftwareFoundation.Python.3.12_3.12.2800.0_x64__qbz5n2kfra8p0\Lib\subprocess.py:548 │
│ in run │
│ │
│ 545 │ │ kwargs['stdout'] = PIPE │
│ 546 │ │ kwargs['stderr'] = PIPE │
│ 547 │ │
│ ❱ 548 │ with Popen(*popenargs, **kwargs) as process: │
│ 549 │ │ try: │
│ 550 │ │ │ stdout, stderr = process.communicate(input, timeout=timeout) │
│ 551 │ │ except TimeoutExpired as exc: │
│ │
│ C:\Program │
│ Files\WindowsApps\PythonSoftwareFoundation.Python.3.12_3.12.2800.0_x64__qbz5n2kfra8p0\Lib\subprocess.py:102 │
│ 6 in __init__ │
│ │
│ 1023 │ │ │ │ │ self.stderr = io.TextIOWrapper(self.stderr, │
│ 1024 │ │ │ │ │ │ │ encoding=encoding, errors=errors) │
│ 1025 │ │ │ │
│ ❱ 1026 │ │ │ self._execute_child(args, executable, preexec_fn, close_fds, │
│ 1027 │ │ │ │ │ │ │ │ pass_fds, cwd, env, │
│ 1028 │ │ │ │ │ │ │ │ startupinfo, creationflags, shell, │
│ 1029 │ │ │ │ │ │ │ │ p2cread, p2cwrite, │
│ │
│ C:\Program │
│ Files\WindowsApps\PythonSoftwareFoundation.Python.3.12_3.12.2800.0_x64__qbz5n2kfra8p0\Lib\subprocess.py:153 │
│ 8 in _execute_child │
│ │
│ 1535 │ │ │ │
│ 1536 │ │ │ # Start the process │
│ 1537 │ │ │ try: │
│ ❱ 1538 │ │ │ │ hp, ht, pid, tid = _winapi.CreateProcess(executable, args, │
│ 1539 │ │ │ │ │ │ │ │ │ │ # no special security │
│ 1540 │ │ │ │ │ │ │ │ │ │ None, None, │
│ 1541 │ │ │ │ │ │ │ │ │ │ int(not close_fds), │
╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
OSError: [WinError 193] %1 は有効な Win32 アプリケーションではありません。
ERROR 2025-04-14 00:43:37,331 llama_stack.distribution.build:128 uncategorized: Failed to build target
llamastack-myllama with return code 1
Error building stack: Failed to build image llamastack-myllama
windowsでの動かし方がわからないのでwslで使う事にしました。
wslの使い方や仮想環境作りなどは省きます。
(tllama) kug@jjjj:~/tllama$ llama stack build
> Enter a name for your Llama Stack (e.g. my-local-stack): myllama
> Enter the image type you want your Llama Stack to be built as (conda or container or venv): venv
Llama Stack is composed of several APIs working together. Let's select
the provider types (implementations) you want to use for these APIs.
Tip: use <TAB> to see options for the providers.
> Enter provider for API inference: inline::meta-reference
> Enter provider for API safety: inline::prompt-guard
> Enter provider for API agents: inline::meta-reference
> Enter provider for API vector_io: inline::meta-reference
> Enter provider for API datasetio: inline::localfs
> Enter provider for API scoring: inline::basic
> Enter provider for API eval: inline::meta-reference
> Enter provider for API post_training: inline::torchtune
> Enter provider for API tool_runtime: inline::rag-runtime
> Enter provider for API telemetry: inline::meta-reference
> (Optional) Enter a short description for your Llama Stack: my first time use llama
uv is not installed, trying to install it.
Collecting uv
Downloading uv-0.6.14-py3-none-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (11 kB)
Downloading uv-0.6.14-py3-none-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (16.9 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 16.9/16.9 MB 11.2 MB/s eta 0:00:00
Installing collected packages: uv
Successfully installed uv-0.6.14
Using virtual environment llamastack-myllama
Using CPython 3.12.3 interpreter at: /usr/bin/python3
Creating virtual environment at: llamastack-myllama
Activate with: source llamastack-myllama/bin/activate
Using Python 3.12.3 environment at: llamastack-myllama
Resolved 57 packages in 1.42s
Built fire==0.7.0
Prepared 56 packages in 4.98s
Installed 57 packages in 69ms
+ annotated-types==0.7.0
+ anyio==4.9.0
+ attrs==25.3.0
+ blobfile==3.0.0
+ certifi==2025.1.31
+ charset-normalizer==3.4.1
+ click==8.1.8
+ distro==1.9.0
+ filelock==3.18.0
+ fire==0.7.0
+ fsspec==2025.3.2
+ h11==0.14.0
+ httpcore==1.0.8
+ httpx==0.28.1
+ huggingface-hub==0.30.2
+ idna==3.10
+ jinja2==3.1.6
+ jiter==0.9.0
+ jsonschema==4.23.0
+ jsonschema-specifications==2024.10.1
+ llama-stack==0.2.2
+ llama-stack-client==0.2.2
+ lxml==5.3.2
+ markdown-it-py==3.0.0
+ markupsafe==3.0.2
+ mdurl==0.1.2
+ numpy==2.2.4
+ openai==1.73.0
+ packaging==24.2
+ pandas==2.2.3
+ pillow==11.2.1
+ prompt-toolkit==3.0.50
+ pyaml==25.1.0
+ pycryptodomex==3.22.0
+ pydantic==2.11.3
+ pydantic-core==2.33.1
+ pygments==2.19.1
+ python-dateutil==2.9.0.post0
+ python-dotenv==1.1.0
+ pytz==2025.2
+ pyyaml==6.0.2
+ referencing==0.36.2
+ regex==2024.11.6
+ requests==2.32.3
+ rich==14.0.0
+ rpds-py==0.24.0
+ setuptools==78.1.0
+ six==1.17.0
+ sniffio==1.3.1
+ termcolor==3.0.1
+ tiktoken==0.9.0
+ tqdm==4.67.1
+ typing-extensions==4.13.2
+ typing-inspection==0.4.0
+ tzdata==2025.2
+ urllib3==2.4.0
+ wcwidth==0.2.13
Installing pip dependencies
Using Python 3.12.3 environment at: llamastack-myllama
Resolved 128 packages in 1.77s
Built fairscale==0.4.13
Built antlr4-python3-runtime==4.9.3
Built zmq==0.0.0
Built langdetect==1.0.9
Prepared 89 packages in 5m 04s
Uninstalled 1 package in 2ms
Installed 89 packages in 314ms
+ accelerate==1.6.0
+ aiohappyeyeballs==2.6.1
+ aiohttp==3.11.16
+ aiosignal==1.3.2
+ aiosqlite==0.21.0
+ antlr4-python3-runtime==4.9.3
+ chardet==5.2.0
+ contourpy==1.3.1
+ cycler==0.12.1
+ datasets==3.5.0
+ deprecated==1.2.18
+ dill==0.3.8
+ dnspython==2.7.0
+ emoji==2.14.1
+ fairscale==0.4.13
+ faiss-cpu==1.10.0
+ fastapi==0.115.12
+ fbgemm-gpu-genai==1.1.2
+ fonttools==4.57.0
+ frozenlist==1.5.0
- fsspec==2025.3.2
+ fsspec==2024.12.0
+ googleapis-common-protos==1.69.2
+ hf-transfer==0.1.9
+ importlib-metadata==8.6.1
+ interegular==0.3.3
+ joblib==1.4.2
+ kagglehub==0.3.11
+ kiwisolver==1.4.8
+ langdetect==1.0.9
+ lm-format-enforcer==0.10.11
+ matplotlib==3.10.1
+ mpmath==1.3.0
+ multidict==6.4.3
+ multiprocess==0.70.16
+ networkx==3.4.2
+ nltk==3.9.1
+ nvidia-cublas-cu12==12.4.5.8
+ nvidia-cuda-cupti-cu12==12.4.127
+ nvidia-cuda-nvrtc-cu12==12.4.127
+ nvidia-cuda-runtime-cu12==12.4.127
+ nvidia-cudnn-cu12==9.1.0.70
+ nvidia-cufft-cu12==11.2.1.3
+ nvidia-curand-cu12==10.3.5.147
+ nvidia-cusolver-cu12==11.6.1.9
+ nvidia-cusparse-cu12==12.3.1.170
+ nvidia-cusparselt-cu12==0.6.2
+ nvidia-nccl-cu12==2.21.5
+ nvidia-nvjitlink-cu12==12.4.127
+ nvidia-nvtx-cu12==12.4.127
+ omegaconf==2.3.0
+ opentelemetry-api==1.32.0
+ opentelemetry-exporter-otlp-proto-common==1.32.0
+ opentelemetry-exporter-otlp-proto-http==1.32.0
+ opentelemetry-proto==1.32.0
+ opentelemetry-sdk==1.32.0
+ opentelemetry-semantic-conventions==0.53b0
+ propcache==0.3.1
+ protobuf==5.29.4
+ psutil==7.0.0
+ psycopg2-binary==2.9.10
+ pyarrow==19.0.1
+ pymongo==4.12.0
+ pyparsing==3.2.3
+ pypdf==5.4.0
+ pythainlp==5.1.1
+ pyzmq==26.4.0
+ redis==5.2.1
+ safetensors==0.5.3
+ scikit-learn==1.6.1
+ scipy==1.15.2
+ sentence-transformers==4.0.2
+ sentencepiece==0.2.0
+ starlette==0.46.2
+ sympy==1.13.1
+ threadpoolctl==3.6.0
+ tokenizers==0.21.1
+ torch==2.6.0
+ torchao==0.8.0
+ torchtune==0.5.0
+ torchvision==0.21.0
+ transformers==4.51.2
+ tree-sitter==0.24.0
+ triton==3.2.0
+ uvicorn==0.34.1
+ wrapt==1.17.2
+ xxhash==3.5.0
+ yarl==1.19.0
+ zipp==3.21.0
+ zmq==0.0.0
torch --index-url https://download.pytorch.org/whl/cpu
Using Python 3.12.3 environment at: llamastack-myllama
Audited 1 package in 3ms
You can now run your stack with `llama stack run /home/kug/.llama/distributions/llamastack-myllama/llamastack-myllama-run.yaml`
これでyamlファイルを作れたようです。
コマンドラインの指示通りllama stack run /home/kug/.llama/distributions/llamastack-myllama/llamastack-myllama-run.yaml実行します。
このあと色々な関係ライブラリとhugging faceからファイルを取り寄せてエラーを消していきました。
(tllama) kug@jjjj:~/tllama$ llama stack run /home/kug/.llama/distributions/llamastack-myllama/llamastack-myllama-run.yaml
INFO 2025-04-14 14:18:32,702 llama_stack.cli.stack.run:125 server: Using run configuration:
/home/kug/.llama/distributions/llamastack-myllama/llamastack-myllama-run.yaml
INFO 2025-04-14 14:18:32,707 llama_stack.cli.stack.run:142 server: No image type or image name provided. Assuming
environment packages.
INFO 2025-04-14 14:18:32,877 llama_stack.distribution.server.server:385 server: Using config file:
/home/kug/.llama/distributions/llamastack-myllama/llamastack-myllama-run.yaml
INFO 2025-04-14 14:18:32,878 llama_stack.distribution.server.server:387 server: Run configuration:
INFO 2025-04-14 14:18:32,880 llama_stack.distribution.server.server:389 server: apis:
- inference
- safety
- agents
- vector_io
- datasetio
- scoring
- eval
- post_training
- tool_runtime
- telemetry
benchmarks: []
container_image: null
datasets: []
external_providers_dir: null
image_name: llamastack-myllama
logging: null
metadata_store: null
models: []
providers:
agents:
- config:
persistence_store:
db_path: /home/kug/.llama/distributions/llamastack-myllama/agents_store.db
namespace: null
type: sqlite
provider_id: meta-reference
provider_type: inline::meta-reference
datasetio:
- config:
kvstore:
db_path: /home/kug/.llama/distributions/llamastack-myllama/localfs_datasetio.db
namespace: null
type: sqlite
provider_id: localfs
provider_type: inline::localfs
eval:
- config:
kvstore:
db_path: /home/kug/.llama/distributions/llamastack-myllama/meta_reference_eval.db
namespace: null
type: sqlite
provider_id: meta-reference
provider_type: inline::meta-reference
inference:
- config:
checkpoint_dir: 'null'
max_batch_size: '1'
max_seq_len: '4096'
model: Llama3.2-3B-Instruct
model_parallel_size: '0'
quantization:
type: bf16
provider_id: meta-reference
provider_type: inline::meta-reference
post_training:
- config:
checkpoint_format: meta
provider_id: torchtune
provider_type: inline::torchtune
safety:
- config:
guard_type: injection
provider_id: prompt-guard
provider_type: inline::prompt-guard
scoring:
- config: {}
provider_id: basic
provider_type: inline::basic
telemetry:
- config:
service_name: "\u200B"
sinks: console,sqlite
sqlite_db_path: /home/kug/.llama/distributions/llamastack-myllama/trace_store.db
provider_id: meta-reference
provider_type: inline::meta-reference
tool_runtime:
- config: {}
provider_id: rag-runtime
provider_type: inline::rag-runtime
vector_io:
- config:
kvstore:
db_path: /home/kug/.llama/distributions/llamastack-myllama/faiss_store.db
namespace: null
type: sqlite
provider_id: meta-reference
provider_type: inline::meta-reference
scoring_fns: []
server:
auth: null
port: 8321
tls_certfile: null
tls_keyfile: null
shields: []
tool_groups: []
vector_dbs: []
version: '2'
WARNING 2025-04-14 14:18:32,890 llama_stack.distribution.resolver:220 core: Provider `inline::meta-reference` for API
`Api.vector_io` is deprecated and will be removed in a future release: Please use the `inline::faiss` provider
instead.
WARNING 2025-04-14 14:18:37,232 root:72 uncategorized: Warning: `bwrap` is not available. Code interpreter tool will
not work correctly.
INFO 2025-04-14 14:18:37,884 datasets:54 uncategorized: PyTorch version 2.6.0+cu126 available.
INFO 2025-04-14 14:18:38,165 llama_stack.distribution.server.server:478 server: Listening on ['::', '0.0.0.0']:8321
INFO: Started server process [601]
INFO: Waiting for application startup.
INFO 2025-04-14 14:18:38,206 llama_stack.distribution.server.server:148 server: Starting up
INFO: Application startup complete.
INFO: Uvicorn running on http://['::', '0.0.0.0']:8321 (Press CTRL+C to quit)
ローカルでサーバー起動出来ました。これでAPIが利用できるはずです。
また、ダウンロードしたモデルがちゃんと認識されいればllama-stack-client models listで何か表示されるはずです。
(tllama) kug@jjjj:~/tllama$ llama-stack-client models list
Available Models
┏━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┓
┃ model_type ┃ identifier ┃ provider_resource_id ┃ metadata ┃ provider_id ┃
┡━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━┩
│ llm │ Llama3.2-3B-Instruct │ Llama3.2-3B-Instruct │ │ meta-reference │
└───────────────┴────────────────────────────┴────────────────────────────┴────────────┴───────────────────┘
Total models: 1
自分の場合は素の状態では出てこなかったためyamlに書き足しました。
models:
- model_id: Llama3.2-3B-Instruct
provider_id: meta-reference #ここまで追記
from llama_stack_client import LlamaStackClient
client = LlamaStackClient(base_url="http://localhost:8321")
model_id = "Llama3.2-3B-Instruct"
prompt = "Write a haiku about coding"
response = client.inference.chat_completion(
model_id=model_id,
messages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt},],)
print(f"Assistant> {response.completion_message.content}")
出来た!
(tllama) kug@jjjj:~/tllama$ python3
Python 3.12.3 (main, Feb 4 2025, 14:48:35) [GCC 13.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from llama_stack_client import LlamaStackClient
>>> client = LlamaStackClient(base_url="http://localhost:8321")
>>> model_id = "Llama3.2-3B-Instruct"
= client.inference.chat_completion(
model_i>>> prompt = "Write a haiku about coding"
": "system", "co>>> response = client.inference.chat_completion(
tant."},{"role":... model_id=model_id,
... messages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt},],)
>>> print(f"Assistant> {response.completion_message.content}")
Assistant> Here is a haiku about coding:
Lines of code descend
Logic flows through digital
Mind in perfect sync
>>> prompt = "where is the capital of Japan, and discrive about that"
>>> response = client.inference.chat_completion(
=[{"role": "system", "content": "You are a helpf... model_id=model_id,
... messages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt},],)
onse.completion_message.content}")
>>> print(f"Assistant> {response.completion_message.content}")
Assistant> The capital of Japan is Tokyo!
Located on the eastern coast of Honshu, the largest island of Japan, Tokyo is a vibrant and bustling metropolis that is home to over 38 million people. It's a city that seamlessly blends traditional and modern culture, with a unique blend of ancient temples, shrines, and gardens alongside cutting-edge technology and innovative architecture.
**Must-see attractions:**
1. **Shibuya Crossing**: One of the busiest intersections in the world, known for its neon lights and giant video screens.
2. **Tokyo Tower**: A iconic communications tower that offers stunning views of the city.
3. **Meiji Shrine**: A serene Shinto shrine dedicated to the deified spirits of Emperor Meiji and his wife, Empress Shoken.
4. **Tsukiji Outer Market**: A bustling marketplace famous for its fresh sushi and seafood.
5. **Asakusa**: A historic district with ancient temples, traditional shops, and street food stalls.
**Neighborhoods to explore:**
1. **Shimokitazawa**: A trendy neighborhood known for its fashionable boutiques, cafes, and vintage shops.
2. **Harajuku**: A fashion-forward district famous for its unique styles, crepe shops, and shopping streets.
3. **Akihabara**: Tokyo's electronics and anime hub, with numerous shops, arcades, and restaurants.
4. **Roppongi**: A cosmopolitan district with upscale shopping, dining, and entertainment options.
**Food and drink:**
1. **Sushi**: Fresh, delicious, and varied, with many restaurants serving high-quality sushi.
2. **Ramen**: A popular noodle soup dish that's both comforting and flavorful.
3. **Tonkatsu**: A breaded and deep-fried pork cutlet that's a Japanese favorite.
4. **Matcha**: A traditional green tea that's perfect for hot summer days.
**Tips and insights:**
1. **Language**: While many Tokyo residents speak some English, it's still a good idea to learn basic Japanese phrases, such as "konnichiwa" (hello) and "arigatou" (thank you).
2. **Transportation**: Tokyo has an efficient public transportation system, including the famous Tokyo Metro and JR trains.
3. **Safety**: Tokyo is generally a very safe city, but be mindful of pickpocketing and petty theft in crowded areas.
4. **Respect for tradition**: Japan is a country with a rich cultural heritage, so be respectful of temples, shrines, and traditional customs.
I hope this gives you a good introduction to Tokyo, the vibrant capital of Japan!
llama公式サイトの方法に従ったやり方で出来ましたが、少しややこしかったです。APIなので、Pythonでなくても使えるのがllama stackの目玉なようです。
おまけ
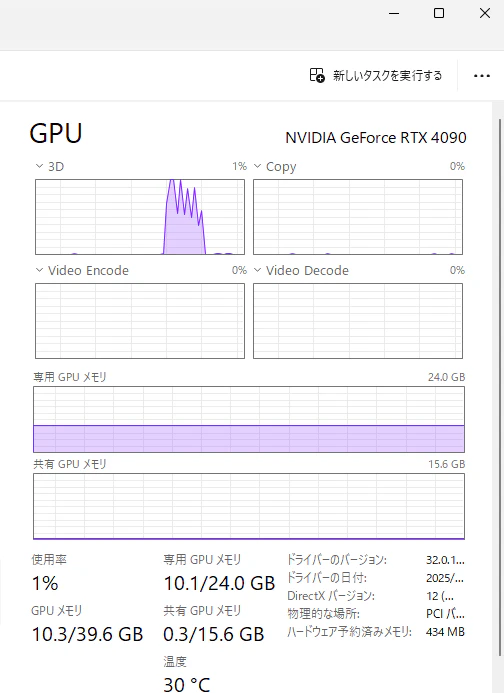
GPUの性能次第で結果生成にかかる時間が変わる。長めの回答になればなるほどGPU使用率が跳ね上がる。3Dが跳ね上がっているのは推論させたタイミング。
また、VRAMは常時10GB程度食っている。比較的軽い3.2-3b-instructでもハイエンド帯のグラボ以外では量子化しない限り動かすのがしんどくなると思われる。