はじめに
本記事はRUNTEQ Advent Calendar 2022の11日目の記事です。
当初は「今年のテーマは新しく挑戦した技術」という触れ込みだったので、自分のポートフォリオとかとは全く関係ないですが、前職のプロジェクトで間接の間接くらいでお世話になっていたOCR技術に今更ながら入門してみました!
もしもポートフォリオでOCRを何らかの形で利用してみたいという方の参考になれば幸いです。
(ソースコード自体はコントローラにロジックをベタ書きしていたりと汚いので参考程度で、、)
サンプルアプリのリポジトリ
※後述しますが環境変数としてS3やAPIキーを持っています。(.env.sampleファイル参照)また、Rails実行端末上にtesseractのインストールが必要です。
2つ並べて実行した結果
インプットにした画像と、TesseractとCloud Vision APIでのOCR実行結果を上下で並べています。
メタ文字のエスケープをミスっているのは置いておいて、こう見ると精度は雲泥の差があるなーと感じました。

使った技術一覧
Rails
Railsアプリケーション上で画像を投稿し、画面のボタンから各種OCRを実行するという仕組みにしています。
あまり影響はないと思いますが、後述のライブラリが動作するか不明であるため、一応Ruby3系やRails7系は注意してください。
- Ruby: 2.6.6
- Rails: 6.1.7
その他Gem
- carrierwave ※画像投稿用
- fog-aws ※S3に画像を投稿する用
- dotenv-rails ※.envファイルを取り扱う用
- rtesseract ※後述のOCRソフトウェアを扱う用
- google-cloud-vision ※後述のVision APIのクライアント
OCR
今回利用したGem↓
また、ローカルのMacにインストールしたTesseract本体のバージョンは以下です。
$ tesseract -v
tesseract 5.2.0
OCR(Optical Character Recognition、光学的文字認識)とは、画像やスキャンした文書から文字を識別し、テキスト化する技術です。
日本ではまだまだ手書きの書類がたくさんあるため、書面の文書をテキストデータ化したいという要望は多いかなと思います。
上記のGemはTesseractと呼ばれるGoogleが開発しているOCRのOSSを、Rubyで利用できるようにしたラッパーライブラリになります。(そのため、実行端末上にTesseractをインストールする必要があります。。)
pythonやGoなど他の言語のラッパーライブラリも存在します。
参考記事:Tesseractの各言語のラッパーいろいろ(随時更新)
OSSということもあり実用的な精度なら、無料かつマシンのリソースが許す限り使い放題?と思って触ってみました。世の中そんなに甘くない。
また、上記ライブラリはRPA製品の内部でも利用されており、たとえばUiPathでは画面上で読み取った対象の文字列をクリックするなどが行えます。
AI-OCR
こちらは上記OCR技術に人工知能が使われていることを表す用語です。
流行りの人工知能による機械学習・画像認識技術を利用しており、一般的にはOCRと比べれば精度は良いとされています。
調べてみると流行も相まってか、各社色んな製品やソリューションを展開しているようです。
スタートアップ界隈だと、何かと話題に上がることが多いLayerX社のプロダクトなどでも利用されている認識です。
参考記事(最近のプレスリリース):バクラク経費精算、軽減税率の自動仕訳生成機能を追加。AI-OCRが領収書の税率別の金額を読み取り、手入力をゼロへ
今回の記事では、こちらもGoogle製のCloud Vision APIをOCRの用途で利用します。
OCR用途だけではなく、タグ付けやロゴ判別機能などもあり、そちらの方が今っぽいかなと思います。
価格(参考)は、月で最初の1000回までは無料ですが、それ以降は1000回につき1.5ドルといった従量課金です。
本編
ここからはサクサクと、参考にした記事や詰まったところ中心に書いていきます。
画像投稿のRailsアプリ作成
これについてはRUNTEQのカリキュラムでもやったことを思い出しつつ、scaffoldでdocumentモデルに対して1つの画像を紐付けるような簡素な作りになっています。
大部分は以下の記事を参考にさせていただき、画像はS3に配置するようにしています。
参考記事:【Rails】 CarrierWaveチュートリアル
(サンプルアプリでは最初へのローカル保存として実装した後、保存先をS3に変更しています)
若干AWSの画面や設定内容が変更になっていますが、ググれば対処できる範囲かと思います。
注意するとしたら、記事中にもありますがAWSのシークレットキー周りの取り扱いはご注意ください。
TesseractによるOCR機能の実装
Tesseractのインストール
前述の通り、実行端末へのTesseractのインストールが必要です。
今回はMac上にHomebrewでインストールしました。
Linux
# 本体のインストール
$ brew install tesseract
# インストール時、各言語対応のパッケージも推奨されたため併せてインストール
$ brew install tesseract-lang
rtesseractのインストール
こちらはgemのため、Gemfileに記述し、bundle installでインストールします。
gem 'rtesseract'
使い方・その他
使い方自体は非常に楽で、以下のように画像のパスを指定して以下のようにto_sメソッドでテキスト化ができます。
image = RTesseract.new("my_image.jpg")
text = image.to_s # 画像内の文字列を取得
ただし、デフォルトの設定は英語のため、日本語が含まれた画像をOCRする際には第2引数に対象の言語を指定します。
image = RTesseract.new(image_url, lang: 'jpn') # 英語なら'eng'
※サンプルアプリではラジオボタンで英語か日本語か選択し、params[:language]のような形で動的に変えられるようにしています。
Carrierwaveを使っているため、画像のURLは@document.document_image.urlといった形で取得できます。
今回は使いませんでしたが、文字列にするto_sメソッド以外にも、以下のようなものがあるようです。
- 文字列が埋め込まれた形式のPDFに変換する
to_pdfメソッド - 画像内の各文字列の座標を取得する
to_boxメソッド
また、今回はTesseract本体についてはあまり調べませんでしたが、教師データを元に学習を行わせるようなこともできるようです。
参考記事:Tesseract OCR 5 の学習(Ubuntu 上)
Cloud Vision APIによるOCR機能の実装
Google Cloud関連
基本的に以下のページを参照して設定しました。
- プロジェクトの作成
- 課金の有効化の確認
- プロジェクトでCloud Vision APIを有効化
- サービスアカウントの作成、キー作成
→AWSで言うところのIAMでシステムアクセス用のユーザーを作成するようなもので、アカウント作成後にキーファイルを取得します
Rails側での設定
調べると割と実装方法はバラバラで、最終的には以下の記事に近い形になったかなと思います。
以下のクライアントのGemを利用しています。
gem 'google-cloud-vision'
発行したキーファイルを配置し、環境変数として以下の値を設定することで認証が行えました。
GOOGLE_CLOUD_KEYFILE_JSON = 'JSON形式のKeyファイルへのパス'
※権限は多くないと思いますが、Keyファイルの取り扱いには注意してください。(今回GitHubには上げてません)
APIのリファレンスは以下をご参照ください。
Google::Cloud::Vision::V1::ImageAnnotator::Clientのインスタンスを作成し、用意されたメソッドに引数を渡して実行することでOCRや画像のタグ認識、ロゴ判別などの機能が利用できます。
言語ヒント
デフォルトで実行するとなかなか精度は出なかったのですが、今回のように日本語と英語くらいに絞るのであれば、以下のようにlanguage_hints(ドキュメント)を設定することで精度が上がりました。
response = image_annotator_client.document_text_detection(
image: image, max_results: 1, image_context: { language_hints: %i[ja en] }
)
詰まったところ
S3の画像のURLを直接設定したところ、APIから開けないと言う旨のエラーメッセージが返ってきたため、ネットの記事を参考にごにょごにょしたのですが、データサイズが大きい(体感1MB以上くらい?)と正常に動作しません。。
色々試す
さて、これでライブラリでのOCRとAI-OCRを試す環境が整いました。
以下では色々な画像とそのOCR結果を示します。
冒頭の結果の再掲
手書き文字っぽいフォントの画像を作ってOCRをかけると以下のようになりました。
やはりCloud Vision APIの結果が正確だなと感じました。
ただし、明朝フォントなら
上は比較のために大袈裟な例を示しましたが、明朝フォントならこのような結果でした。

「吾輩」以外はちゃんとテキスト化できていることから、プリントアウトされたワープロで作成された文章であれば、Tesseractでもある程度はテキスト化できるかもしれません。
これ以降は記事が長くなりそうなので折りたたみで省略しておきます。
その他の結果
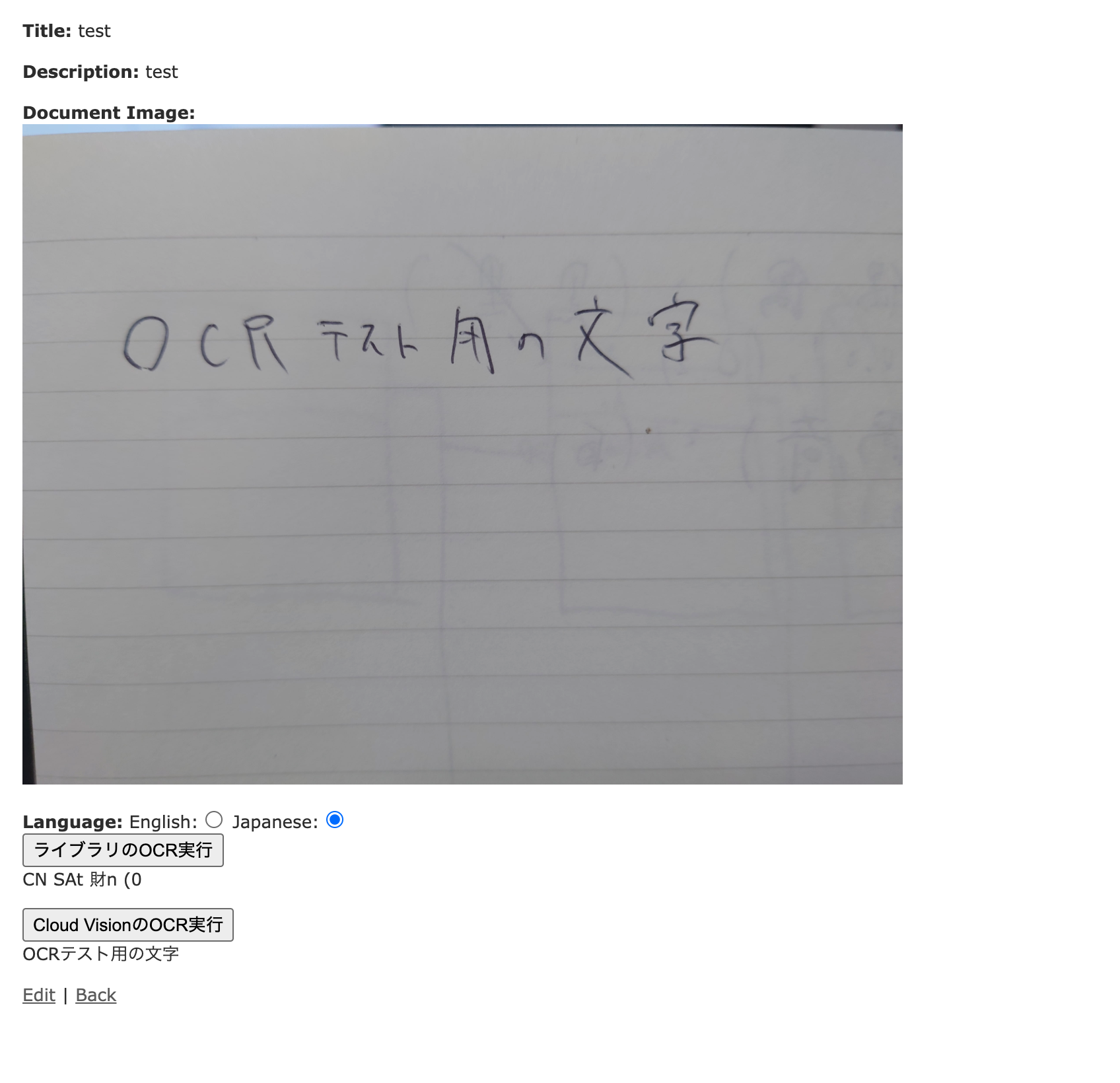
手書きの文字
エンジニア特有の汚文字でもこの通り。
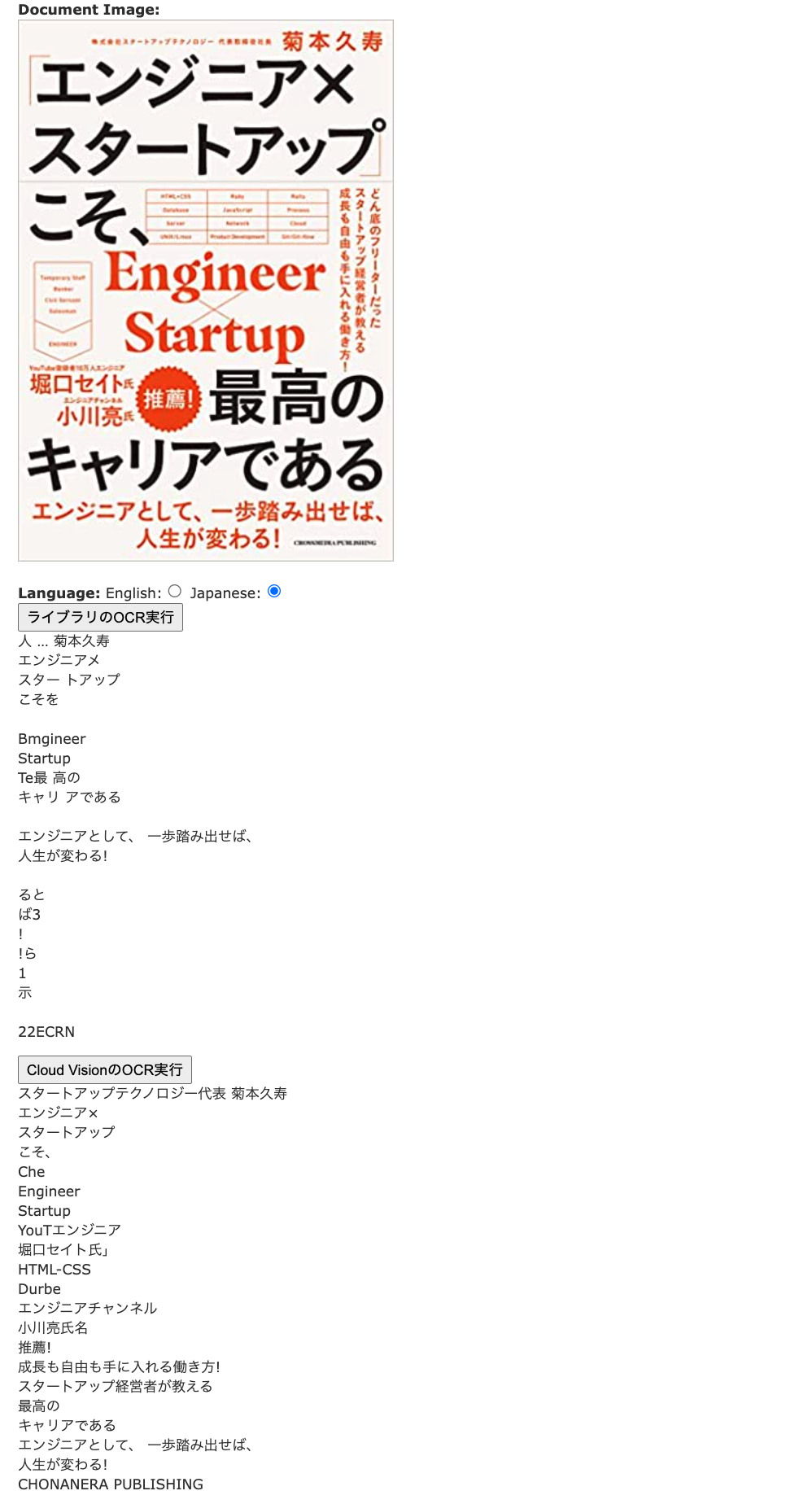
話題のあの本
Amazonの荒い画像を利用しましたが、それなりに文字を取得できているように見えます。
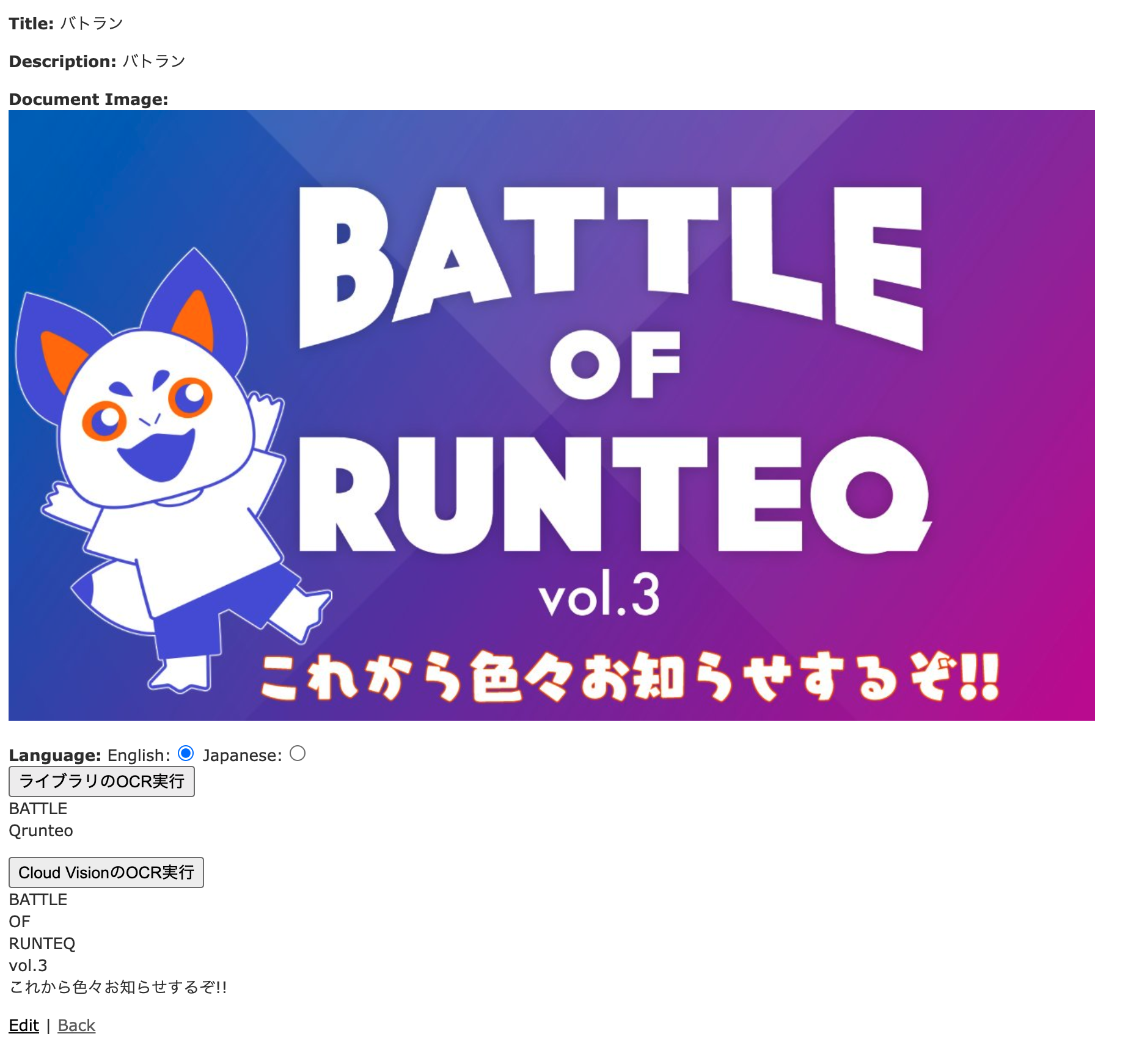
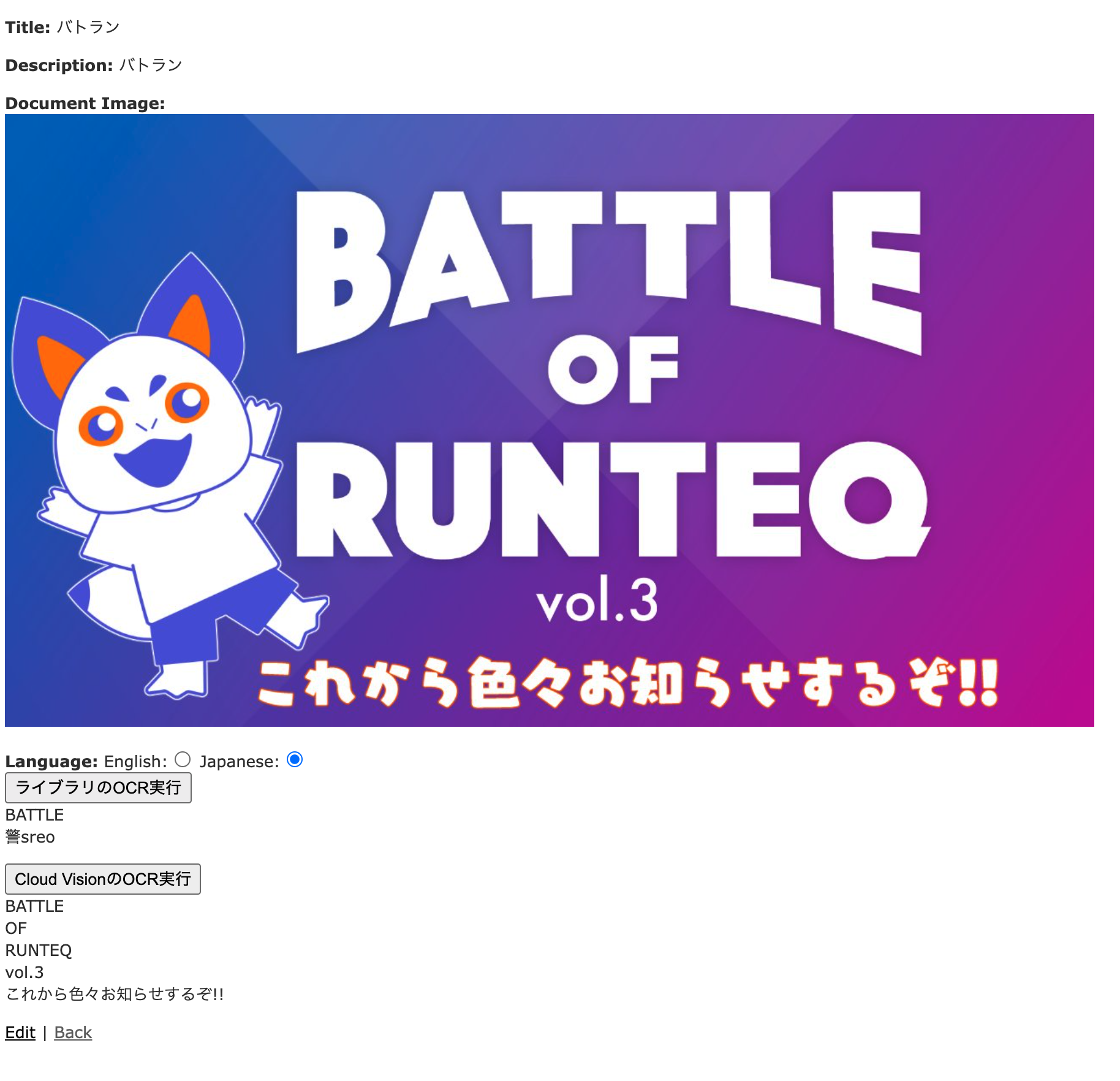
バトラン告知
やはりロゴっぽい丸みのあるフォントなどは苦手なように見えます。
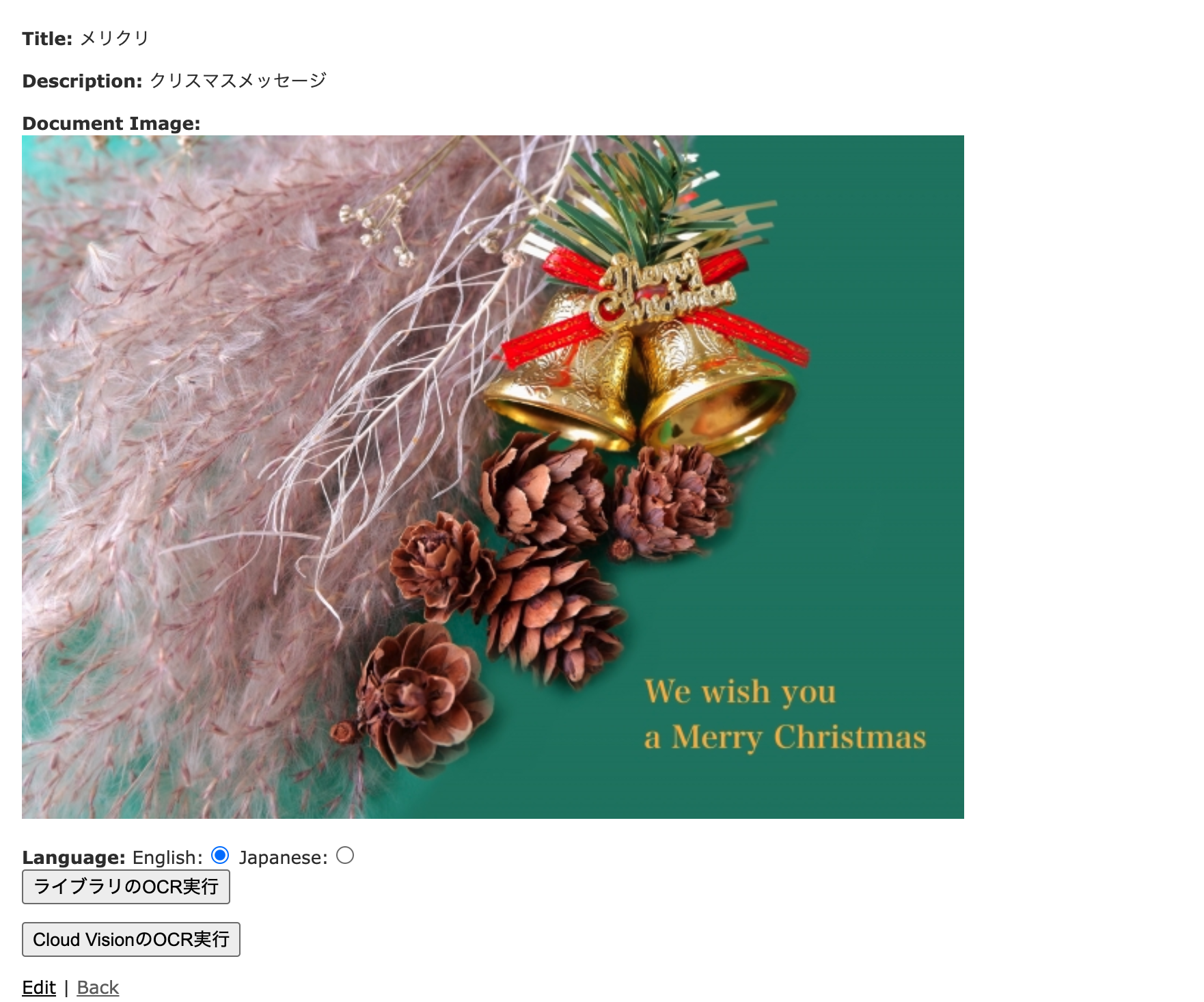
-
Tesseractの対象言語として英語を選択
-
Tesseractの対象言語として日本語を選択
終わりに
今回はn番煎じ感がありますが、初めてちゃんとOCRを触ってみてやっぱりAI-OCRはすごいなーと再認識しました。
もしくは学習やパラメータチューニング、best版の利用などTesseractを活かしきれていない可能性はあるかもしれません。
正直どちらも楽に利用できるGemがあったためOCR自体は簡単にでき、OCR以外の基本的なコーディングを思い出す機会になりました、、
GoogleレンズやAdobe Scanなど普段使いでも感動するOCRのアプリなども出てきており、何となく関連技術も追ってみたいです。
個人としては今回アドベントカレンダーに初参加して、ここを目掛けて締切駆動で準備したのも良い経験になりました。
明日は@shutooorm02さんによるご自身のポートフォリオ紹介記事になります。
「三つ星ホテル級のトイレ」を探すためのサービスとのことで、お楽しみに!